 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing a Broken ELBO
Feb 13, 2018
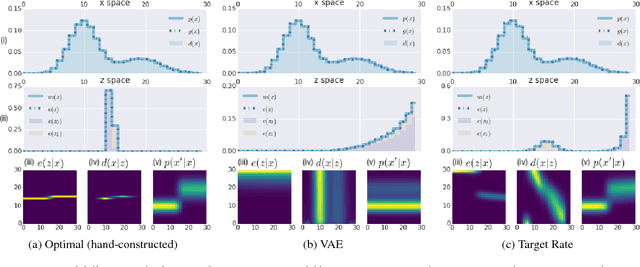
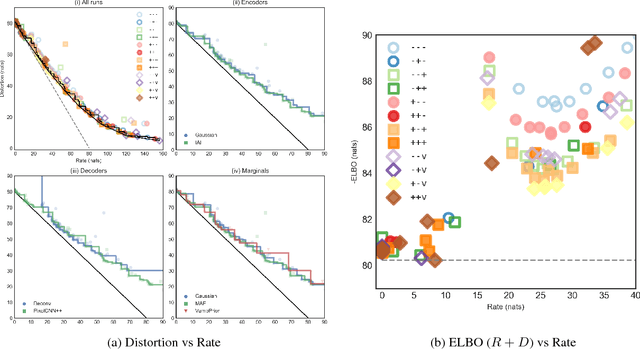
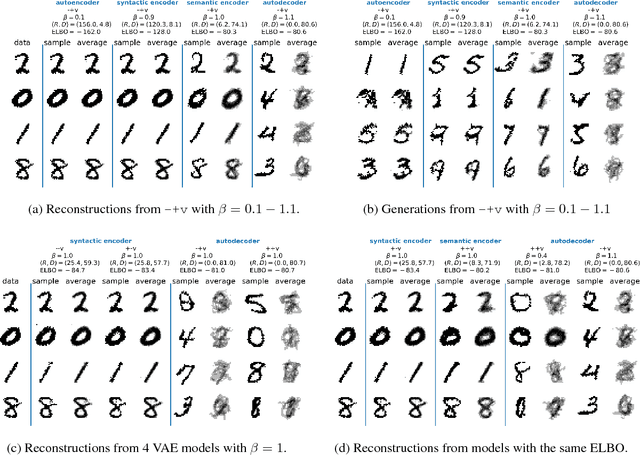
Recent work in unsupervised representation learning has focused on learning deep directed latent-variable models. Fitting these models by maximizing the marginal likelihood or evidence is typically intractable, thus a common approximation is to maximize the evidence lower bound (ELBO) instead. However, maximum likelihood training (whether exact or approximate) does not necessarily result in a good latent representation, as we demonstrate both theoretically and empirically. In particular, we derive variational lower and upper bounds on the mutual information between the input and the latent variable, and use these bounds to derive a rate-distortion curve that characterizes the tradeoff between compression and reconstruction accuracy. Using this framework, we demonstrate that there is a family of models with identical ELBO, but different quantitative and qualitative characteristics. Our framework also suggests a simple new method to ensure that latent variable models with powerful stochastic decoders do not ignore their latent code.
Deep Variational Information Bottleneck
Jul 17, 2017
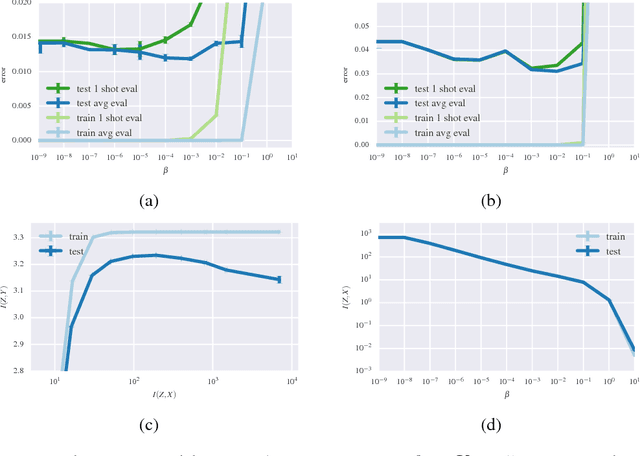
We present a variational approximation to the information bottleneck of Tishby et al. (1999). This variational approach allows us to parameterize the information bottleneck model using a neural network and leverage the reparameterization trick for efficient training. We call this method "Deep Variational Information Bottleneck", or Deep VIB. We show that models trained with the VIB objective outperform those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.
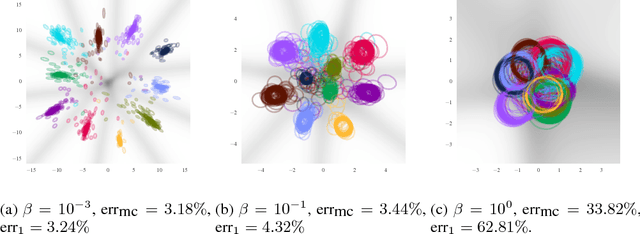
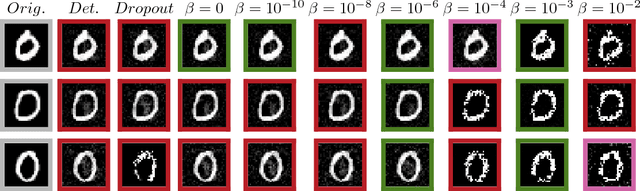
Jeffrey's prior sampling of deep sigmoidal networks
May 25, 2017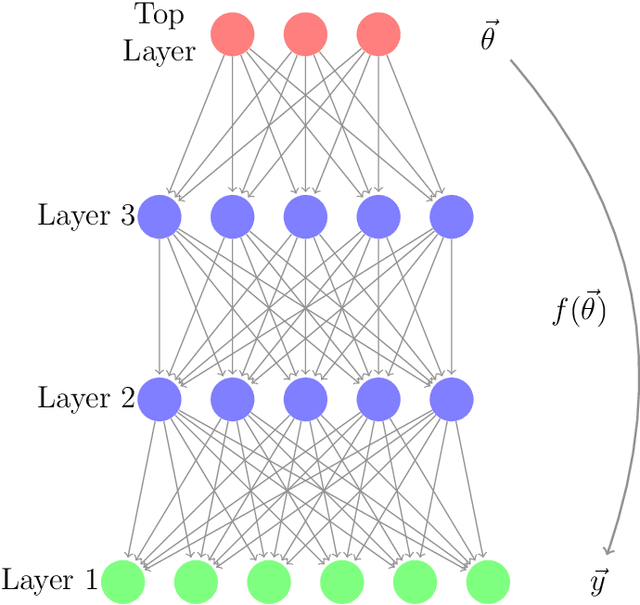
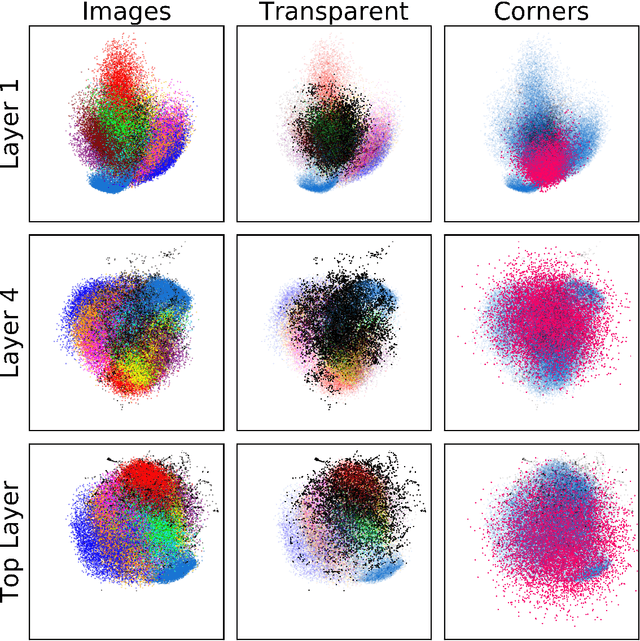

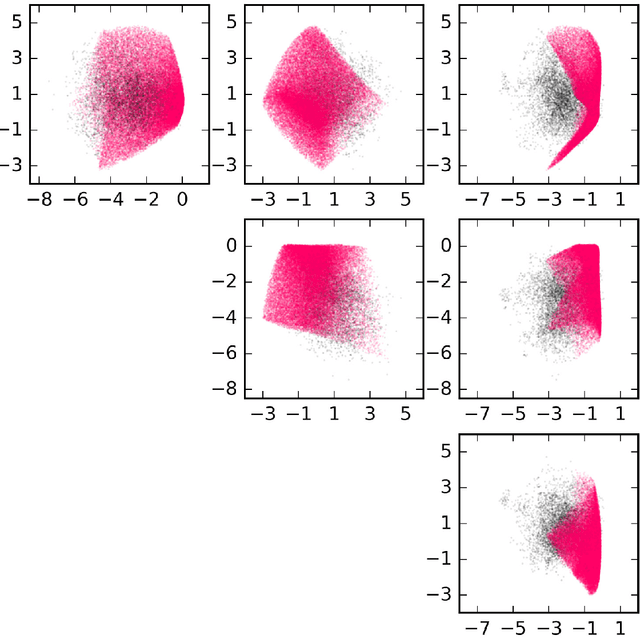
Neural networks have been shown to have a remarkable ability to uncover low dimensional structure in data: the space of possible reconstructed images form a reduced model manifold in image space. We explore this idea directly by analyzing the manifold learned by Deep Belief Networks and Stacked Denoising Autoencoders using Monte Carlo sampling. The model manifold forms an only slightly elongated hyperball with actual reconstructed data appearing predominantly on the boundaries of the manifold. In connection with the results we present, we discuss problems of sampling high-dimensional manifolds as well as recent work [M. Transtrum, G. Hart, and P. Qiu, Submitted (2014)] discussing the relation between high dimensional geometry and model reduction.
Improved generator objectives for GANs
Dec 08, 2016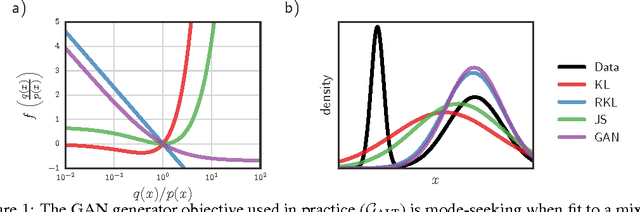
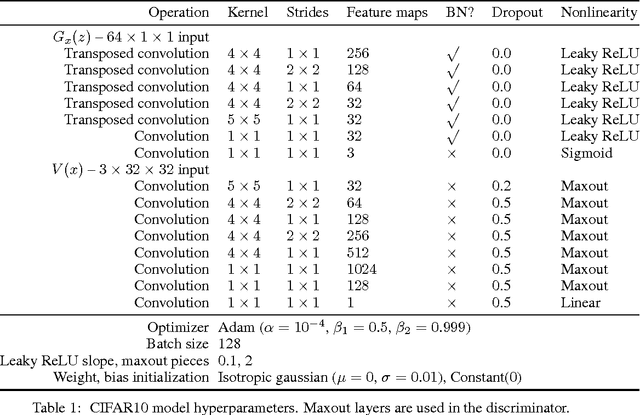

We present a framework to understand GAN training as alternating density ratio estimation and approximate divergence minimization. This provides an interpretation for the mismatched GAN generator and discriminator objectives often used in practice, and explains the problem of poor sample diversity. We also derive a family of generator objectives that target arbitrary $f$-divergences without minimizing a lower bound, and use them to train generative image models that target either improved sample quality or greater sample diversity.
Clustering via Content-Augmented Stochastic Blockmodels
May 25, 2015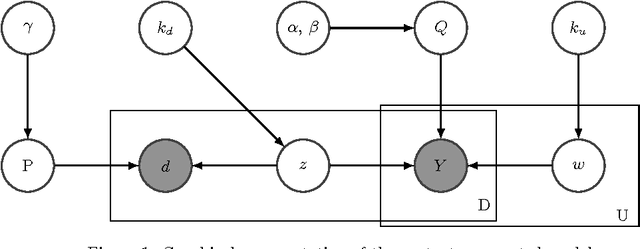

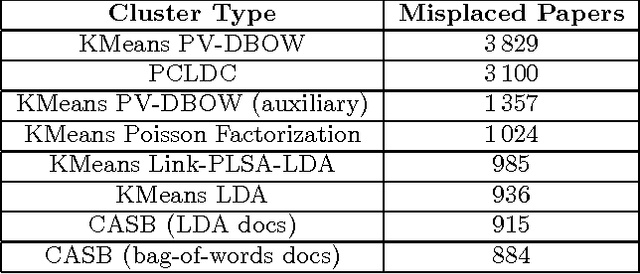

Much of the data being created on the web contains interactions between users and items. Stochastic blockmodels, and other methods for community detection and clustering of bipartite graphs, can infer latent user communities and latent item clusters from this interaction data. These methods, however, typically ignore the items' contents and the information they provide about item clusters, despite the tendency of items in the same latent cluster to share commonalities in content. We introduce content-augmented stochastic blockmodels (CASB), which use item content together with user-item interaction data to enhance the user communities and item clusters learned. Comparisons to several state-of-the-art benchmark methods, on datasets arising from scientists interacting with scientific articles, show that content-augmented stochastic blockmodels provide highly accurate clusters with respect to metrics representative of the underlying community structure.