 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElliCE: Efficient and Provably Robust Algorithmic Recourse via the Rashomon Sets
Feb 07, 2026Machine learning models now influence decisions that directly affect people's lives, making it important to understand not only their predictions, but also how individuals could act to obtain better results. Algorithmic recourse provides actionable input modifications to achieve more favorable outcomes, typically relying on counterfactual explanations to suggest such changes. However, when the Rashomon set - the set of near-optimal models - is large, standard counterfactual explanations can become unreliable, as a recourse action valid for one model may fail under another. We introduce ElliCE, a novel framework for robust algorithmic recourse that optimizes counterfactuals over an ellipsoidal approximation of the Rashomon set. The resulting explanations are provably valid over this ellipsoid, with theoretical guarantees on uniqueness, stability, and alignment with key feature directions. Empirically, ElliCE generates counterfactuals that are not only more robust but also more flexible, adapting to user-specified feature constraints while being substantially faster than existing baselines. This provides a principled and practical solution for reliable recourse under model uncertainty, ensuring stable recommendations for users even as models evolve.
Amazing Things Come From Having Many Good Models
Jul 10, 2024



The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
Fast and Interpretable Mortality Risk Scores for Critical Care Patients
Nov 21, 2023



Prediction of mortality in intensive care unit (ICU) patients is an important task in critical care medicine. Prior work in creating mortality risk models falls into two major categories: domain-expert-created scoring systems, and black box machine learning (ML) models. Both of these have disadvantages: black box models are unacceptable for use in hospitals, whereas manual creation of models (including hand-tuning of logistic regression parameters) relies on humans to perform high-dimensional constrained optimization, which leads to a loss in performance. In this work, we bridge the gap between accurate black box models and hand-tuned interpretable models. We build on modern interpretable ML techniques to design accurate and interpretable mortality risk scores. We leverage the largest existing public ICU monitoring datasets, namely the MIMIC III and eICU datasets. By evaluating risk across medical centers, we are able to study generalization across domains. In order to customize our risk score models, we develop a new algorithm, GroupFasterRisk, which has several important benefits: (1) it uses hard sparsity constraint, allowing users to directly control the number of features; (2) it incorporates group sparsity to allow more cohesive models; (3) it allows for monotonicity correction on models for including domain knowledge; (4) it produces many equally-good models at once, which allows domain experts to choose among them. GroupFasterRisk creates its risk scores within hours, even on the large datasets we study here. GroupFasterRisk's risk scores perform better than risk scores currently used in hospitals, and have similar prediction performance to black box ML models (despite being much sparser). Because GroupFasterRisk produces a variety of risk scores and handles constraints, it allows design flexibility, which is the key enabler of practical and trustworthy model creation.
A Path to Simpler Models Starts With Noise
Oct 30, 2023



The Rashomon set is the set of models that perform approximately equally well on a given dataset, and the Rashomon ratio is the fraction of all models in a given hypothesis space that are in the Rashomon set. Rashomon ratios are often large for tabular datasets in criminal justice, healthcare, lending, education, and in other areas, which has practical implications about whether simpler models can attain the same level of accuracy as more complex models. An open question is why Rashomon ratios often tend to be large. In this work, we propose and study a mechanism of the data generation process, coupled with choices usually made by the analyst during the learning process, that determines the size of the Rashomon ratio. Specifically, we demonstrate that noisier datasets lead to larger Rashomon ratios through the way that practitioners train models. Additionally, we introduce a measure called pattern diversity, which captures the average difference in predictions between distinct classification patterns in the Rashomon set, and motivate why it tends to increase with label noise. Our results explain a key aspect of why simpler models often tend to perform as well as black box models on complex, noisier datasets.
Multitask Learning for Citation Purpose Classification
Jun 24, 2021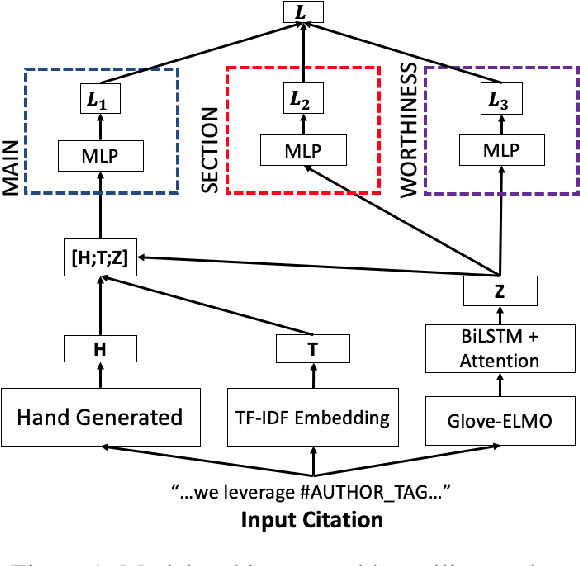
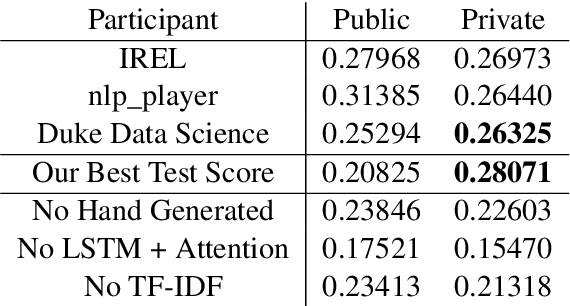
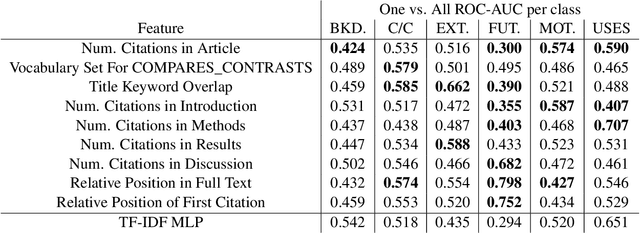
We present our entry into the 2021 3C Shared Task Citation Context Classification based on Purpose competition. The goal of the competition is to classify a citation in a scientific article based on its purpose. This task is important because it could potentially lead to more comprehensive ways of summarizing the purpose and uses of scientific articles, but it is also difficult, mainly due to the limited amount of available training data in which the purposes of each citation have been hand-labeled, along with the subjectivity of these labels. Our entry in the competition is a multi-task model that combines multiple modules designed to handle the problem from different perspectives, including hand-generated linguistic features, TF-IDF features, and an LSTM-with-attention model. We also provide an ablation study and feature analysis whose insights could lead to future work.
Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges
Mar 20, 2021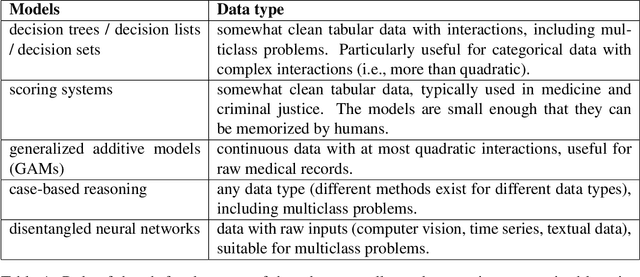
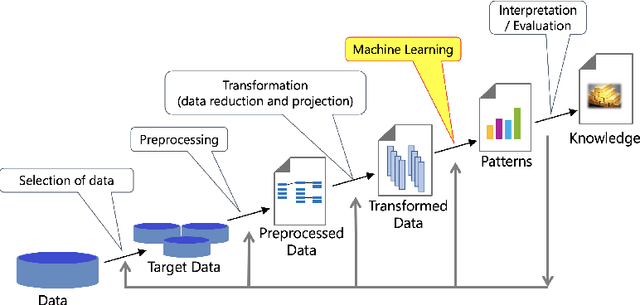
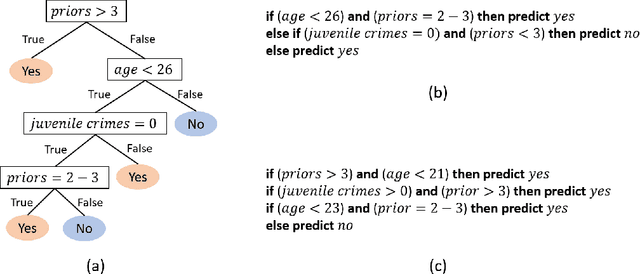
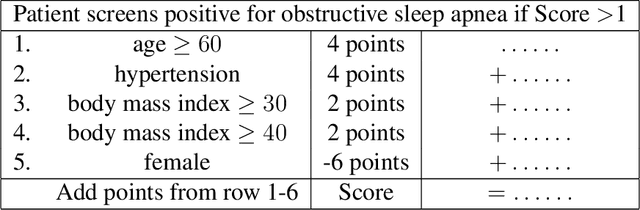
Interpretability in machine learning (ML) is crucial for high stakes decisions and troubleshooting. In this work, we provide fundamental principles for interpretable ML, and dispel common misunderstandings that dilute the importance of this crucial topic. We also identify 10 technical challenge areas in interpretable machine learning and provide history and background on each problem. Some of these problems are classically important, and some are recent problems that have arisen in the last few years. These problems are: (1) Optimizing sparse logical models such as decision trees; (2) Optimization of scoring systems; (3) Placing constraints into generalized additive models to encourage sparsity and better interpretability; (4) Modern case-based reasoning, including neural networks and matching for causal inference; (5) Complete supervised disentanglement of neural networks; (6) Complete or even partial unsupervised disentanglement of neural networks; (7) Dimensionality reduction for data visualization; (8) Machine learning models that can incorporate physics and other generative or causal constraints; (9) Characterization of the "Rashomon set" of good models; and (10) Interpretable reinforcement learning. This survey is suitable as a starting point for statisticians and computer scientists interested in working in interpretable machine learning.
A study in Rashomon curves and volumes: A new perspective on generalization and model simplicity in machine learning
Aug 05, 2019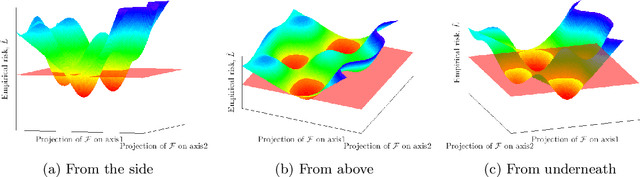


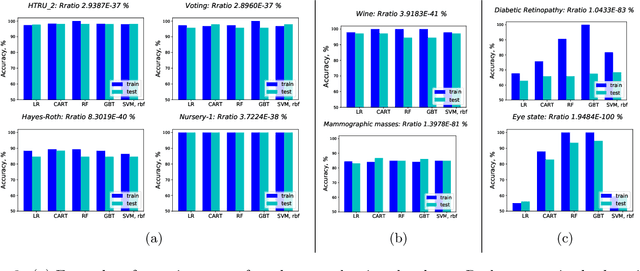
The Rashomon effect occurs when many different explanations exist for the same phenomenon. In machine learning, Leo Breiman used this term to describe problems where many accurate-but-different models exist to describe the same data. In this work, we study how the Rashomon effect can be useful for understanding the relationship between training and test performance, and the possibility that simple-yet-accurate models exist for many problems. We introduce the Rashomon set as the set of almost-equally-accurate models for a given problem, and study its properties and the types of models it could contain. We present the Rashomon ratio as a new measure related to simplicity of model classes, which is the ratio of the volume of the set of accurate models to the volume of the hypothesis space; the Rashomon ratio is different from standard complexity measures from statistical learning theory. For a hierarchy of hypothesis spaces, the Rashomon ratio can help modelers to navigate the trade-off between simplicity and accuracy in a surprising way. In particular, we find empirically that a plot of empirical risk vs. Rashomon ratio forms a characteristic $\Gamma$-shaped Rashomon curve, whose elbow seems to be a reliable model selection criterion. When the Rashomon set is large, models that are accurate - but that also have various other useful properties - can often be obtained. These models might obey various constraints such as interpretability, fairness, monotonicity, and computational benefits.