 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust AI Evaluation through Maximal Lotteries
Feb 24, 2026The standard way to evaluate language models on subjective tasks is through pairwise comparisons: an annotator chooses the "better" of two responses to a prompt. Leaderboards aggregate these comparisons into a single Bradley-Terry (BT) ranking, forcing heterogeneous preferences into a total order and violating basic social-choice desiderata. In contrast, social choice theory provides an alternative approach called maximal lotteries, which aggregates pairwise preferences without imposing any assumptions on their structure. However, we show that maximal lotteries are highly sensitive to preference heterogeneity and can favor models that severely underperform on specific tasks or user subpopulations. We introduce robust lotteries that optimize worst-case performance under plausible shifts in the preference data. On large-scale preference datasets, robust lotteries provide more reliable win rate guarantees across the annotator distribution and recover a stable set of top-performing models. By moving from rankings to pluralistic sets of winners, robust lotteries offer a principled step toward an ecosystem of complementary AI systems that serve the full spectrum of human preferences.
Inference-Time Reward Hacking in Large Language Models
Jun 24, 2025


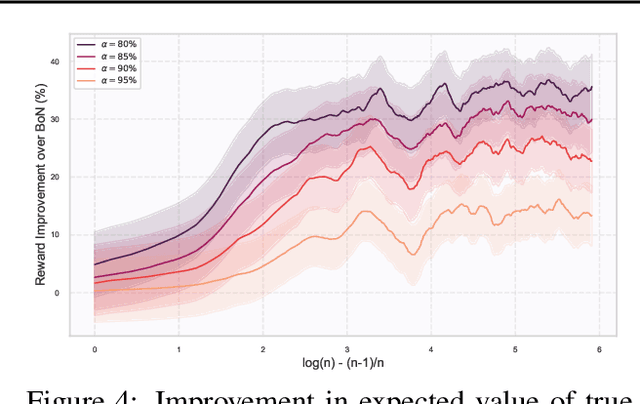
A common paradigm to improve the performance of large language models is optimizing for a reward model. Reward models assign a numerical score to LLM outputs indicating, for example, which response would likely be preferred by a user or is most aligned with safety goals. However, reward models are never perfect. They inevitably function as proxies for complex desiderata such as correctness, helpfulness, and safety. By overoptimizing for a misspecified reward, we can subvert intended alignment goals and reduce overall performance -- a phenomenon commonly referred to as reward hacking. In this work, we characterize reward hacking in inference-time alignment and demonstrate when and how we can mitigate it by hedging on the proxy reward. We study this phenomenon under Best-of-$n$ (BoN) and Soft-Best-of-$n$ (SBoN), and we introduce Best-of-Poisson (BoP) that provides an efficient, near-exact approximation of the optimal reward-KL divergence policy at inference time. We show that the characteristic pattern of hacking as observed in practice (where the true reward first increases before declining) is an inevitable property of a broad class of inference-time mechanisms, including BoN and BoP. To counter this effect, hedging offers a tactical choice to avoid placing undue confidence in high but potentially misleading proxy reward signals. We introduce HedgeTune, an efficient algorithm to find the optimal inference-time parameter and avoid reward hacking. We demonstrate through experiments that hedging mitigates reward hacking and achieves superior distortion-reward tradeoffs with minimal computational overhead.