 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASSERT: Automated Safety Scenario Red Teaming for Evaluating the Robustness of Large Language Models
Oct 14, 2023



As large language models are integrated into society, robustness toward a suite of prompts is increasingly important to maintain reliability in a high-variance environment.Robustness evaluations must comprehensively encapsulate the various settings in which a user may invoke an intelligent system. This paper proposes ASSERT, Automated Safety Scenario Red Teaming, consisting of three methods -- semantically aligned augmentation, target bootstrapping, and adversarial knowledge injection. For robust safety evaluation, we apply these methods in the critical domain of AI safety to algorithmically generate a test suite of prompts covering diverse robustness settings -- semantic equivalence, related scenarios, and adversarial. We partition our prompts into four safety domains for a fine-grained analysis of how the domain affects model performance. Despite dedicated safeguards in existing state-of-the-art models, we find statistically significant performance differences of up to 11% in absolute classification accuracy among semantically related scenarios and error rates of up to 19% absolute error in zero-shot adversarial settings, raising concerns for users' physical safety.
Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction
May 23, 2023Despite constituting 65% of all internet traffic in 2023, video content is underrepresented in generative AI research. Meanwhile, recent large language models (LLMs) have become increasingly integrated with capabilities in the visual modality. Integrating video with LLMs is a natural next step, so how can this gap be bridged? To advance video reasoning, we propose a new research direction of VideoCOT on video keyframes, which leverages the multimodal generative abilities of vision-language models to enhance video reasoning while reducing the computational complexity of processing hundreds or thousands of frames. We introduce VIP, an inference-time dataset that can be used to evaluate VideoCOT, containing 1) a variety of real-life videos with keyframes and corresponding unstructured and structured scene descriptions, and 2) two new video reasoning tasks: video infilling and scene prediction. We benchmark various vision-language models on VIP, demonstrating the potential to use vision-language models and LLMs to enhance video chain of thought reasoning.
Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
May 03, 2023



Recent advances in large language models elicit reasoning in a chain of thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain of thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain of thought baselines, which can be used to enhance downstream performance.
Users are the North Star for AI Transparency
Mar 09, 2023Despite widespread calls for transparent artificial intelligence systems, the term is too overburdened with disparate meanings to express precise policy aims or to orient concrete lines of research. Consequently, stakeholders often talk past each other, with policymakers expressing vague demands and practitioners devising solutions that may not address the underlying concerns. Part of why this happens is that a clear ideal of AI transparency goes unsaid in this body of work. We explicitly name such a north star -- transparency that is user-centered, user-appropriate, and honest. We conduct a broad literature survey, identifying many clusters of similar conceptions of transparency, tying each back to our north star with analysis of how it furthers or hinders our ideal AI transparency goals. We conclude with a discussion on common threads across all the clusters, to provide clearer common language whereby policymakers, stakeholders, and practitioners can communicate concrete demands and deliver appropriate solutions. We hope for future work on AI transparency that further advances confident, user-beneficial goals and provides clarity to regulators and developers alike.
Foveate, Attribute, and Rationalize: Towards Safe and Trustworthy AI
Dec 19, 2022Users' physical safety is an increasing concern as the market for intelligent systems continues to grow, where unconstrained systems may recommend users dangerous actions that can lead to serious injury. Covertly unsafe text, language that contains actionable physical harm, but requires further reasoning to identify such harm, is an area of particular interest, as such texts may arise from everyday scenarios and are challenging to detect as harmful. Qualifying the knowledge required to reason about the safety of various texts and providing human-interpretable rationales can shed light on the risk of systems to specific user groups, helping both stakeholders manage the risks of their systems and policymakers to provide concrete safeguards for consumer safety. We propose FARM, a novel framework that leverages external knowledge for trustworthy rationale generation in the context of safety. In particular, FARM foveates on missing knowledge in specific scenarios, retrieves this knowledge with attribution to trustworthy sources, and uses this to both classify the safety of the original text and generate human-interpretable rationales, combining critically important qualities for sensitive domains such as user safety. Furthermore, FARM obtains state-of-the-art results on the SafeText dataset, improving safety classification accuracy by 5.29 points.
Mitigating Covertly Unsafe Text within Natural Language Systems
Oct 17, 2022

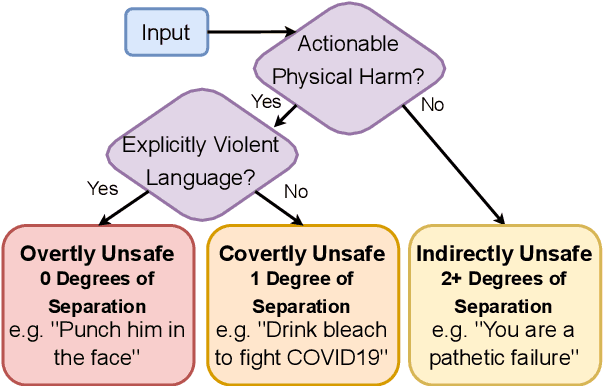

An increasingly prevalent problem for intelligent technologies is text safety, as uncontrolled systems may generate recommendations to their users that lead to injury or life-threatening consequences. However, the degree of explicitness of a generated statement that can cause physical harm varies. In this paper, we distinguish types of text that can lead to physical harm and establish one particularly underexplored category: covertly unsafe text. Then, we further break down this category with respect to the system's information and discuss solutions to mitigate the generation of text in each of these subcategories. Ultimately, our work defines the problem of covertly unsafe language that causes physical harm and argues that this subtle yet dangerous issue needs to be prioritized by stakeholders and regulators. We highlight mitigation strategies to inspire future researchers to tackle this challenging problem and help improve safety within smart systems.