 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuGAN: Unsupervised forward modeling and optimal design of a LIDAR Camera
Dec 16, 2020
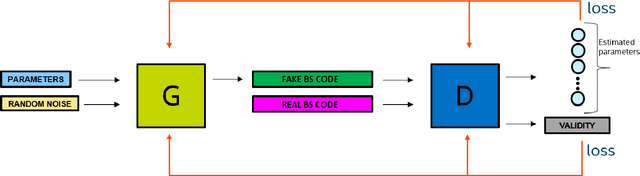
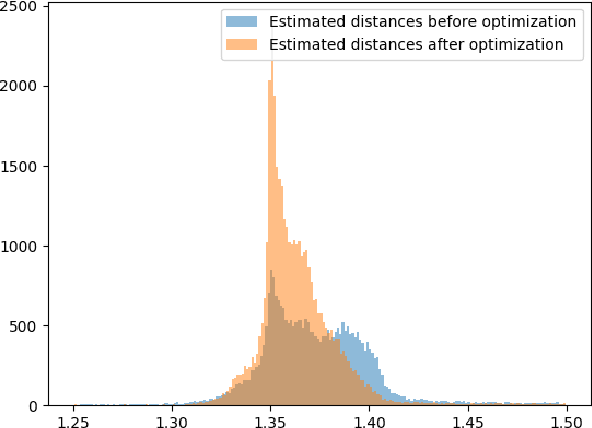
Energy-saving LIDAR camera for short distances estimates an object's distance using temporally intensity-coded laser light pulses and calculates the maximum correlation with the back-scattered pulse. Though on low power, the backs-scattered pulse is noisy and unstable, which leads to inaccurate and unreliable depth estimation. To address this problem, we use GANs (Generative Adversarial Networks), which are two neural networks that can learn complicated class distributions through an adversarial process. We learn the LIDAR camera's hidden properties and behavior, creating a novel, fully unsupervised forward model that simulates the camera. Then, we use the model's differentiability to explore the camera parameter space and optimize those parameters in terms of depth, accuracy, and stability. To achieve this goal, we also propose a new custom loss function designated to the back-scattered code distribution's weaknesses and its circular behavior. The results are demonstrated on both synthetic and real data.
Digital Gimbal: End-to-end Deep Image Stabilization with Learnable Exposure Times
Dec 08, 2020
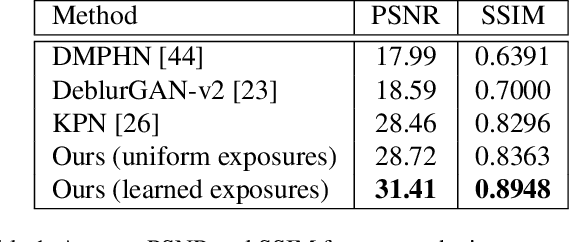

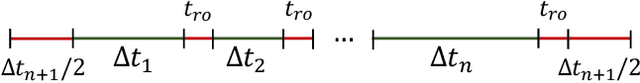
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work, we propose to digitally emulate a mechanically stabilized system from the input of a fast unstabilized camera. To exploit the trade-off between motion blur at long exposures and low SNR at short exposures, we train a CNN that estimates a sharp high-SNR image by aggregating a burst of noisy short-exposure frames, related by unknown motion. We further suggest learning the burst's exposure times in an end-to-end manner, thus balancing the noise and blur across the frames. We demonstrate this method's advantage over the traditional approach of deblurring a single image or denoising a fixed-exposure burst.
Self-Supervised Learning for Large-Scale Unsupervised Image Clustering
Aug 24, 2020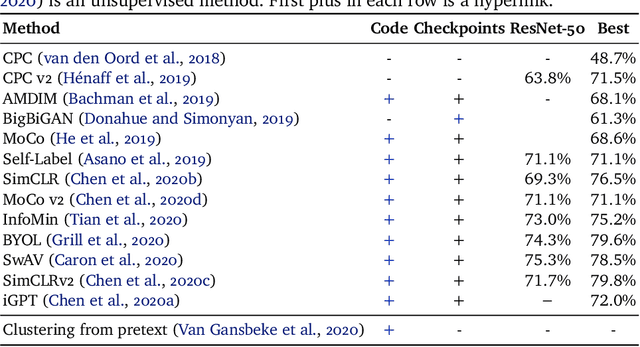
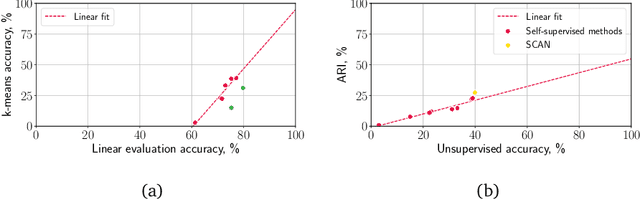
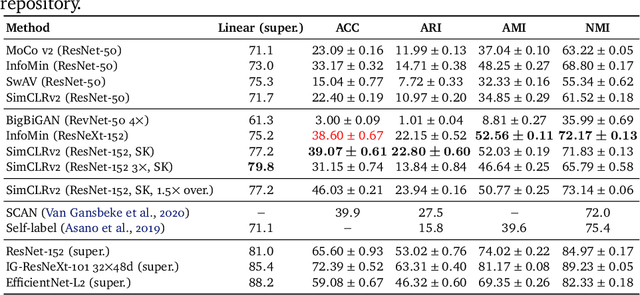
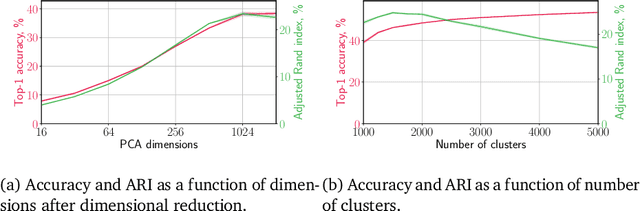
Unsupervised learning has always been appealing to machine learning researchers and practitioners, allowing them to avoid an expensive and complicated process of labeling the data. However, unsupervised learning of complex data is challenging, and even the best approaches show much weaker performance than their supervised counterparts. Self-supervised deep learning has become a strong instrument for representation learning in computer vision. However, those methods have not been evaluated in a fully unsupervised setting. In this paper, we propose a simple scheme for unsupervised classification based on self-supervised representations. We evaluate the proposed approach with several recent self-supervised methods showing that it achieves competitive results for ImageNet classification (39% accuracy on ImageNet with 1000 clusters and 46% with overclustering). We suggest adding the unsupervised evaluation to a set of standard benchmarks for self-supervised learning. The code is available at https://github.com/Randl/kmeans_selfsuper
Data-Driven Prediction of Embryo Implantation Probability Using IVF Time-lapse Imaging
Jun 02, 2020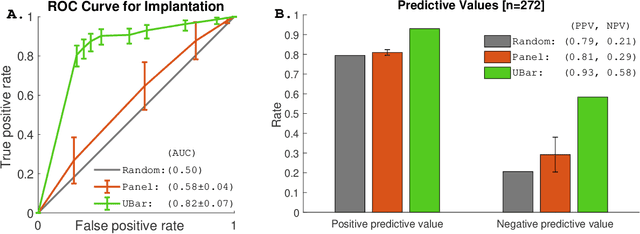
The process of fertilizing a human egg outside the body in order to help those suffering from infertility to conceive is known as in vitro fertilization (IVF). Despite being the most effective method of assisted reproductive technology (ART), the average success rate of IVF is a mere 20-40%. One step that is critical to the success of the procedure is selecting which embryo to transfer to the patient, a process typically conducted manually and without any universally accepted and standardized criteria. In this paper we describe a novel data-driven system trained to directly predict embryo implantation probability from embryogenesis time-lapse imaging videos. Using retrospectively collected videos from 272 embryos, we demonstrate that, when compared to an external panel of embryologists, our algorithm results in a 12% increase of positive predictive value and a 29% increase of negative predictive value.
HCM: Hardware-Aware Complexity Metric for Neural Network Architectures
Apr 26, 2020

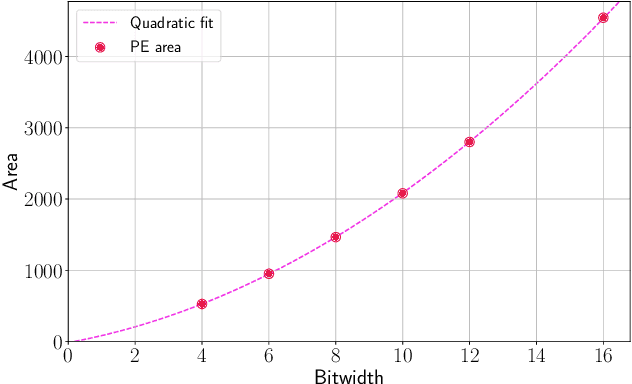
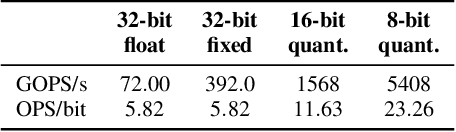
Convolutional Neural Networks (CNNs) have become common in many fields including computer vision, speech recognition, and natural language processing. Although CNN hardware accelerators are already included as part of many SoC architectures, the task of achieving high accuracy on resource-restricted devices is still considered challenging, mainly due to the vast number of design parameters that need to be balanced to achieve an efficient solution. Quantization techniques, when applied to the network parameters, lead to a reduction of power and area and may also change the ratio between communication and computation. As a result, some algorithmic solutions may suffer from lack of memory bandwidth or computational resources and fail to achieve the expected performance due to hardware constraints. Thus, the system designer and the micro-architect need to understand at early development stages the impact of their high-level decisions (e.g., the architecture of the CNN and the amount of bits used to represent its parameters) on the final product (e.g., the expected power saving, area, and accuracy). Unfortunately, existing tools fall short of supporting such decisions. This paper introduces a hardware-aware complexity metric that aims to assist the system designer of the neural network architectures, through the entire project lifetime (especially at its early stages) by predicting the impact of architectural and micro-architectural decisions on the final product. We demonstrate how the proposed metric can help evaluate different design alternatives of neural network models on resource-restricted devices such as real-time embedded systems, and to avoid making design mistakes at early stages.
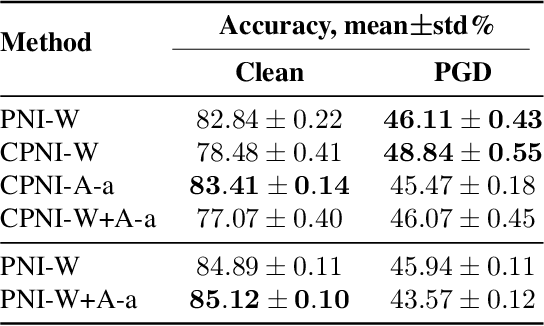
Colored Noise Injection for Training Adversarially Robust Neural Networks
Mar 20, 2020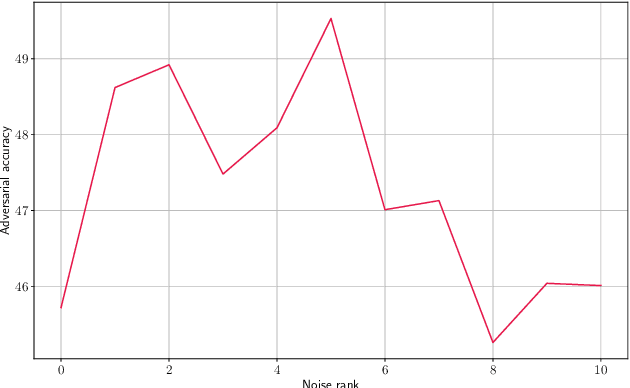
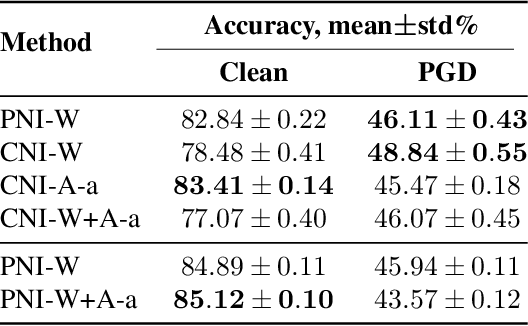
Even though deep learning has shown unmatched performance on various tasks, neural networks have been shown to be vulnerable to small adversarial perturbations of the input that lead to significant performance degradation. In this work we extend the idea of adding white Gaussian noise to the network weights and activations during adversarial training (PNI) to the injection of colored noise for defense against common white-box and black-box attacks. We show that our approach outperforms PNI and various previous approaches in terms of adversarial accuracy on CIFAR-10 and CIFAR-100 datasets. In addition, we provide an extensive ablation study of the proposed method justifying the chosen configurations.
Smoothed Inference for Adversarially-Trained Models
Nov 17, 2019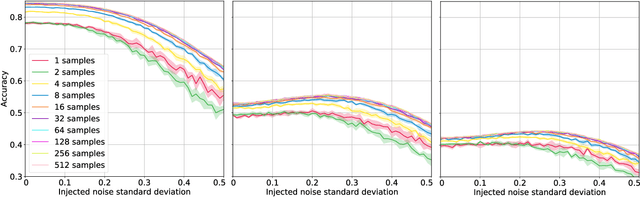
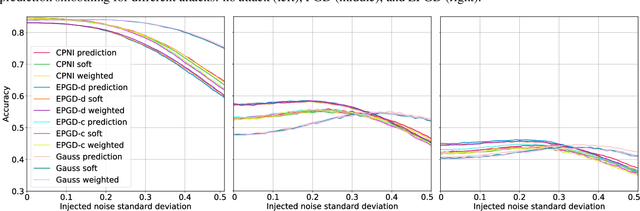
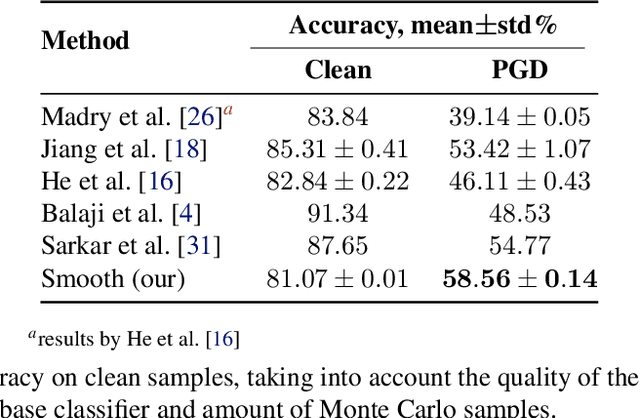
Deep neural networks are known to be vulnerable to inputs with maliciously constructed adversarial perturbations aimed at forcing misclassification. We study randomized smoothing as a way to both improve performance on unperturbed data as well as increase robustness to adversarial attacks. Moreover, we extend the method proposed by arXiv:1811.09310 by adding low-rank multivariate noise, which we then use as a base model for smoothing. The proposed method achieves 58.5% top-1 accuracy on CIFAR-10 under PGD attack and outperforms previous works by 4%. In addition, we consider a family of attacks, which were previously used for training purposes in the certified robustness scheme. We demonstrate that the proposed attacks are more effective than PGD against both smoothed and non-smoothed models. Since our method is based on sampling, it lends itself well for trading-off between the model inference complexity and its performance. A reference implementation of the proposed techniques is provided at https://github.com/yanemcovsky/SIAM.
Loss Aware Post-training Quantization
Nov 17, 2019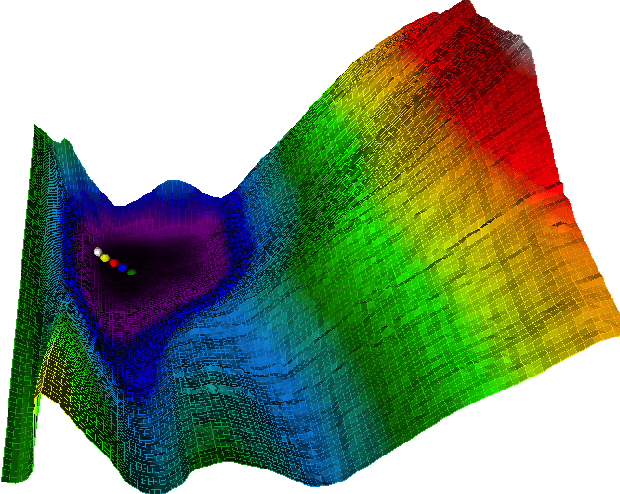
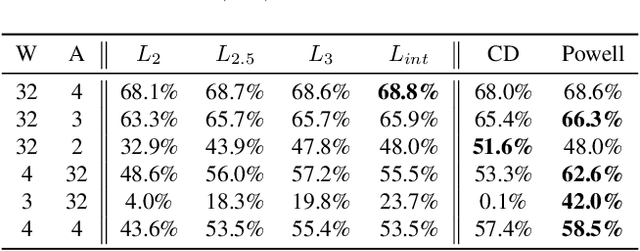
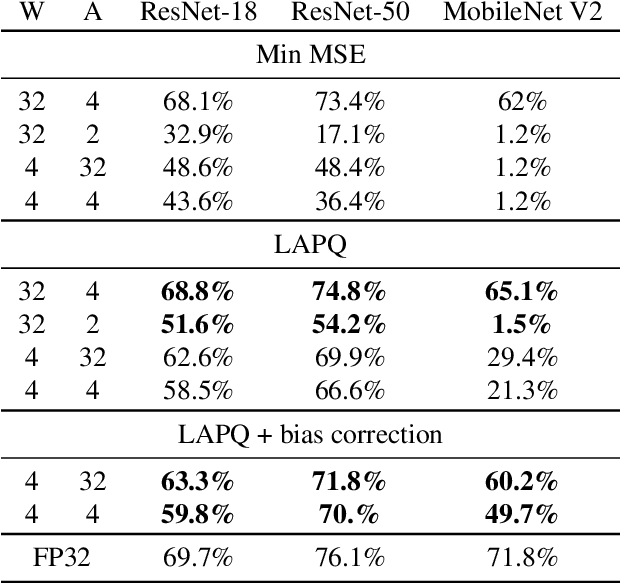
Neural network quantization enables the deployment of large models on resource-constrained devices. Current post-training quantization methods fall short in terms of accuracy for INT4 (or lower) but provide reasonable accuracy for INT8 (or above). In this work, we study the effect of quantization on the structure of the loss landscape. We show that the structure is flat and separable for mild quantization, enabling straightforward post-training quantization methods to achieve good results. On the other hand, we show that with more aggressive quantization, the loss landscape becomes highly non-separable with sharp minima points, making the selection of quantization parameters more challenging. Armed with this understanding, we design a method that quantizes the layer parameters jointly, enabling significant accuracy improvement over current post-training quantization methods. Reference implementation accompanies the paper at https://github.com/ynahshan/nn-quantization-pytorch/tree/master/lapq
CAT: Compression-Aware Training for bandwidth reduction
Sep 25, 2019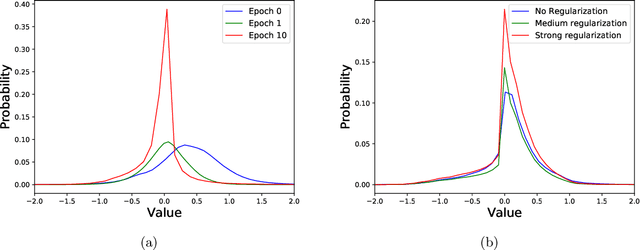
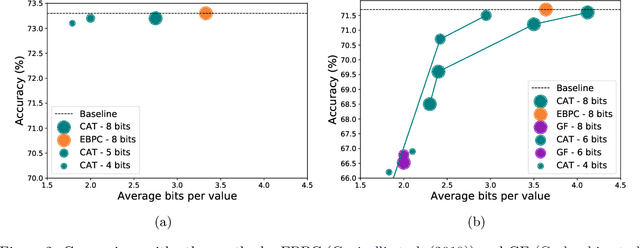

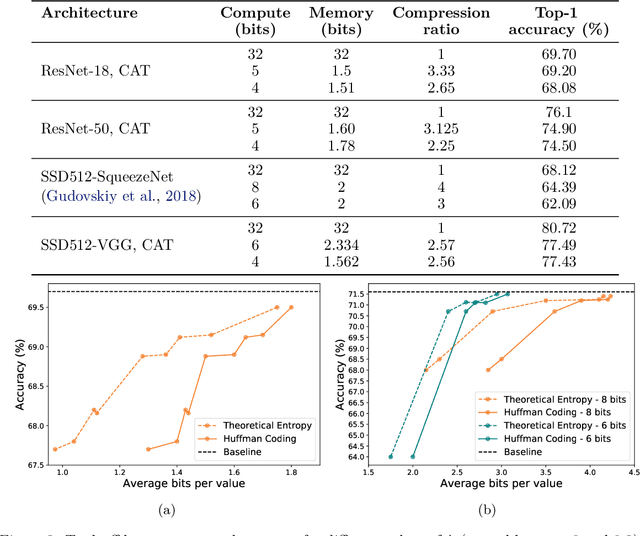
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving visual processing tasks. One of the major obstacles hindering the ubiquitous use of CNNs for inference is their relatively high memory bandwidth requirements, which can be a main energy consumer and throughput bottleneck in hardware accelerators. Accordingly, an efficient feature map compression method can result in substantial performance gains. Inspired by quantization-aware training approaches, we propose a compression-aware training (CAT) method that involves training the model in a way that allows better compression of feature maps during inference. Our method trains the model to achieve low-entropy feature maps, which enables efficient compression at inference time using classical transform coding methods. CAT significantly improves the state-of-the-art results reported for quantization. For example, on ResNet-34 we achieve 73.1% accuracy (0.2% degradation from the baseline) with an average representation of only 1.79 bits per value. Reference implementation accompanies the paper at https://github.com/CAT-teams/CAT
Baby steps towards few-shot learning with multiple semantics
Jun 05, 2019

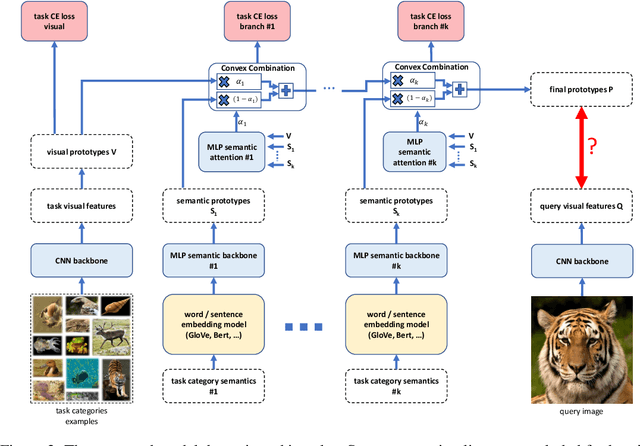
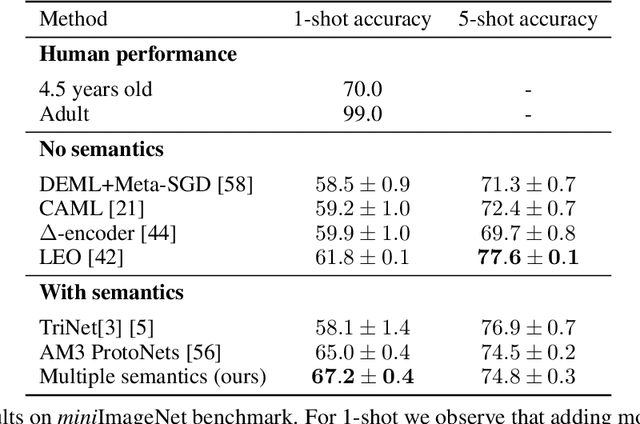
Learning from one or few visual examples is one of the key capabilities of humans since early infancy, but is still a significant challenge for modern AI systems. While considerable progress has been achieved in few-shot learning from a few image examples, much less attention has been given to the verbal descriptions that are usually provided to infants when they are presented with a new object. In this paper, we focus on the role of additional semantics that can significantly facilitate few-shot visual learning. Building upon recent advances in few-shot learning with additional semantic information, we demonstrate that further improvements are possible using richer semantics and multiple semantic sources. Using these ideas, we offer the community a new result on the one-shot test of the popular miniImageNet benchmark, comparing favorably to the previous state-of-the-art results for both visual only and visual plus semantics-based approaches. We also performed an ablation study investigating the components and design choices of our approach.