 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaoKore: A Pre-modern Japanese Art Facial Expression Dataset
Feb 20, 2020
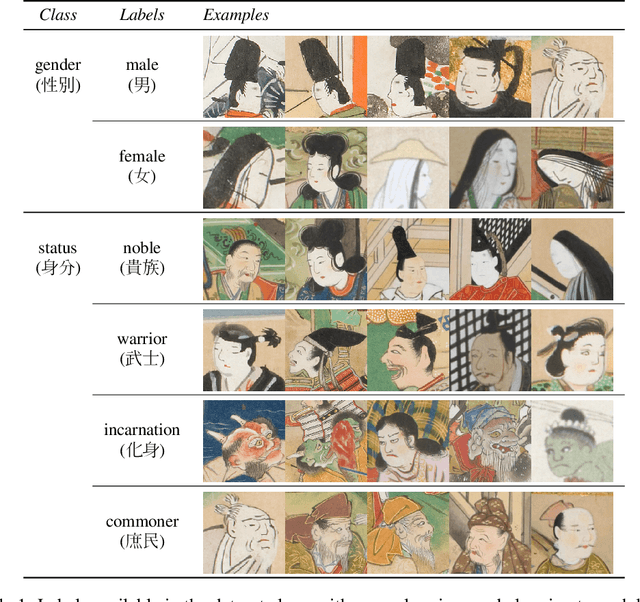

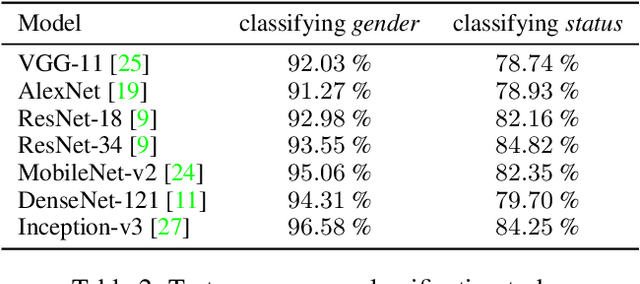
From classifying handwritten digits to generating strings of text, the datasets which have received long-time focus from the machine learning community vary greatly in their subject matter. This has motivated a renewed interest in building datasets which are socially and culturally relevant, so that algorithmic research may have a more direct and immediate impact on society. One such area is in history and the humanities, where better and relevant machine learning models can accelerate research across various fields. To this end, newly released benchmarks and models have been proposed for transcribing historical Japanese cursive writing, yet for the field as a whole using machine learning for historical Japanese artworks still remains largely uncharted. To bridge this gap, in this work we propose a new dataset KaoKore which consists of faces extracted from pre-modern Japanese artwork. We demonstrate its value as both a dataset for image classification as well as a creative and artistic dataset, which we explore using generative models. Dataset available at https://github.com/rois-codh/kaokore
SketchTransfer: A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks
Dec 25, 2019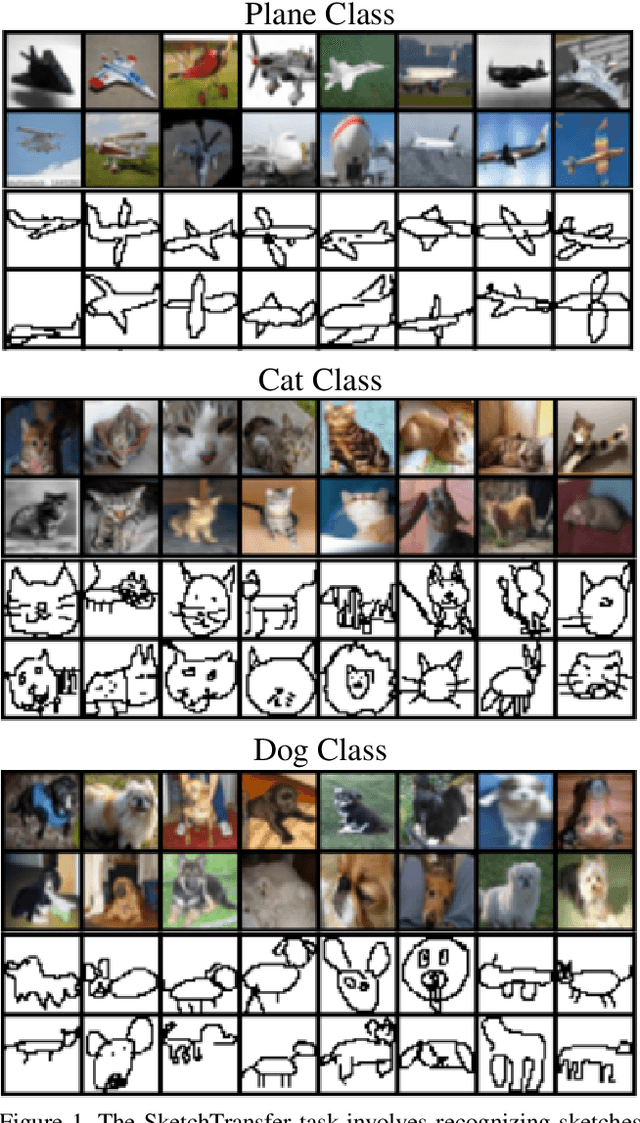

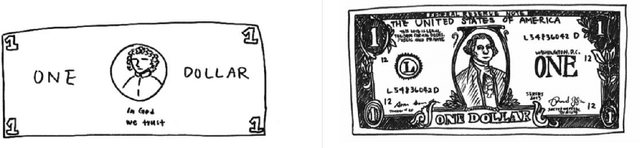
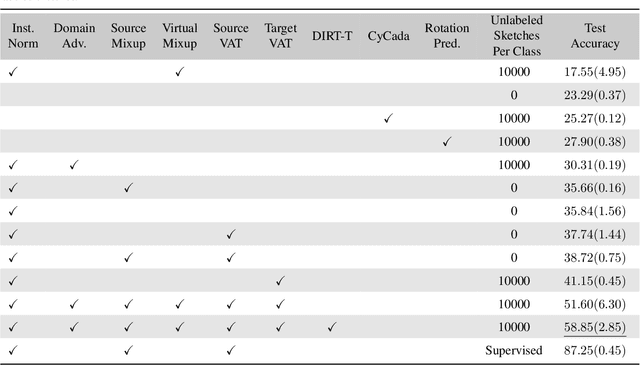
Deep networks have achieved excellent results in perceptual tasks, yet their ability to generalize to variations not seen during training has come under increasing scrutiny. In this work we focus on their ability to have invariance towards the presence or absence of details. For example, humans are able to watch cartoons, which are missing many visual details, without being explicitly trained to do so. As another example, 3D rendering software is a relatively recent development, yet people are able to understand such rendered scenes even though they are missing details (consider a film like Toy Story). The failure of machine learning algorithms to do this indicates a significant gap in generalization between human abilities and the abilities of deep networks. We propose a dataset that will make it easier to study the detail-invariance problem concretely. We produce a concrete task for this: SketchTransfer, and we show that state-of-the-art domain transfer algorithms still struggle with this task. The state-of-the-art technique which achieves over 95\% on MNIST $\xrightarrow{}$ SVHN transfer only achieves 59\% accuracy on the SketchTransfer task, which is much better than random (11\% accuracy) but falls short of the 87\% accuracy of a classifier trained directly on labeled sketches. This indicates that this task is approachable with today's best methods but has substantial room for improvement.
KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning
Oct 21, 2019


Kuzushiji, a cursive writing style, had been used in Japan for over a thousand years starting from the 8th century. Over 3 millions books on a diverse array of topics, such as literature, science, mathematics and even cooking are preserved. However, following a change to the Japanese writing system in 1900, Kuzushiji has not been included in regular school curricula. Therefore, most Japanese natives nowadays cannot read books written or printed just 150 years ago. Museums and libraries have invested a great deal of effort into creating digital copies of these historical documents as a safeguard against fires, earthquakes and tsunamis. The result has been datasets with hundreds of millions of photographs of historical documents which can only be read by a small number of specially trained experts. Thus there has been a great deal of interest in using Machine Learning to automatically recognize these historical texts and transcribe them into modern Japanese characters. Nevertheless, several challenges in Kuzushiji recognition have made the performance of existing systems extremely poor. To tackle these challenges, we propose KuroNet, a new end-to-end model which jointly recognizes an entire page of text by using a residual U-Net architecture which predicts the location and identity of all characters given a page of text (without any pre-processing). This allows the model to handle long range context, large vocabularies, and non-standardized character layouts. We demonstrate that our system is able to successfully recognize a large fraction of pre-modern Japanese documents, but also explore areas where our system is limited and suggest directions for future work.
Recurrent Independent Mechanisms
Sep 26, 2019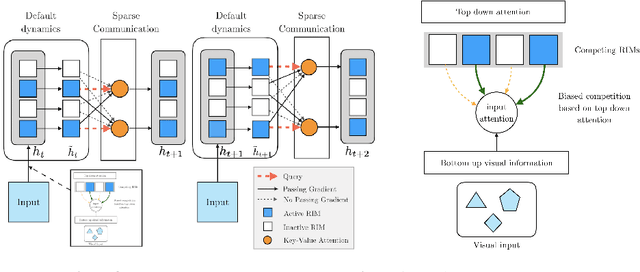
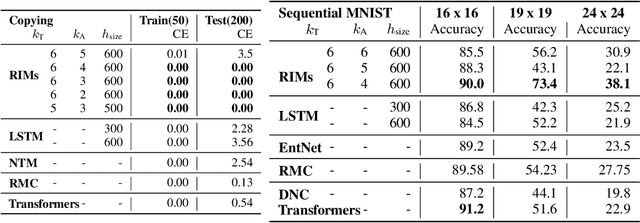
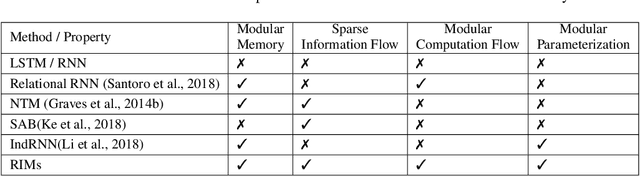

Learning modular structures which reflect the dynamics of the environment can lead to better generalization and robustness to changes which only affect a few of the underlying causes. We propose Recurrent Independent Mechanisms (RIMs), a new recurrent architecture in which multiple groups of recurrent cells operate with nearly independent transition dynamics, communicate only sparingly through the bottleneck of attention, and are only updated at time steps where they are most relevant. We show that this leads to specialization amongst the RIMs, which in turn allows for dramatically improved generalization on tasks where some factors of variation differ systematically between training and evaluation.
GraphMix: Regularized Training of Graph Neural Networks for Semi-Supervised Learning
Sep 25, 2019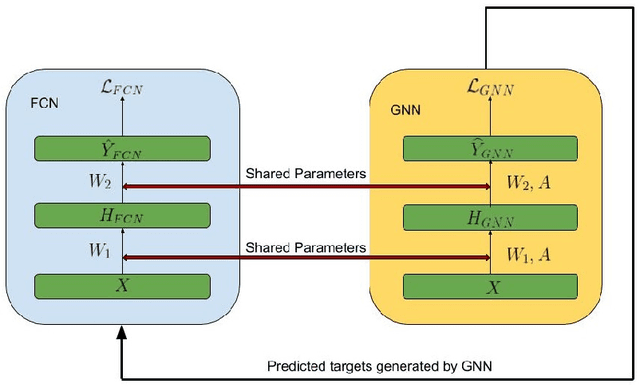
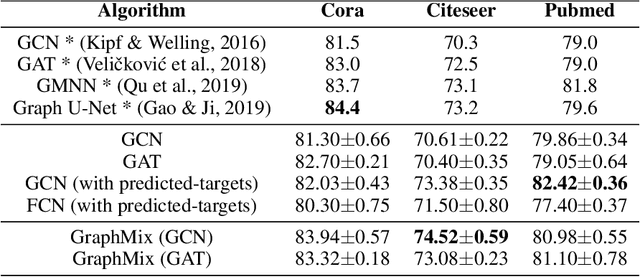

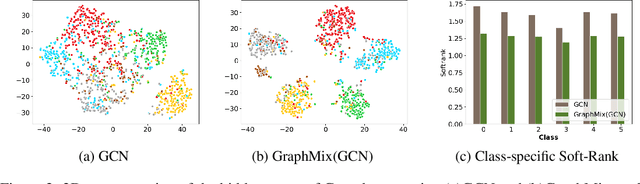
We present GraphMix, a regularization technique for Graph Neural Network based semi-supervised object classification, leveraging the recent advances in the regularization of classical deep neural networks. Specifically, we propose a unified approach in which we train a fully-connected network jointly with the graph neural network via parameter sharing, interpolation-based regularization, and self-predicted-targets. Our proposed method is architecture agnostic in the sense that it can be applied to any variant of graph neural networks which applies a parametric transformation to the features of the graph nodes. Despite its simplicity, with GraphMix we can consistently improve results and achieve or closely match state-of-the-art performance using even simpler architectures such as Graph Convolutional Networks, across three established graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as three newly proposed datasets : Cora-Full, Co-author-CS and Co-author-Physics.
Interpolated Adversarial Training: Achieving Robust Neural Networks without Sacrificing Too Much Accuracy
Jun 29, 2019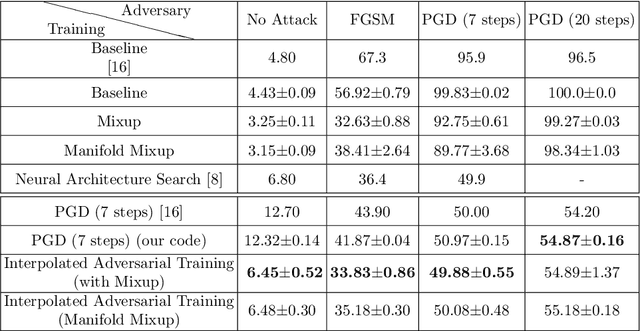
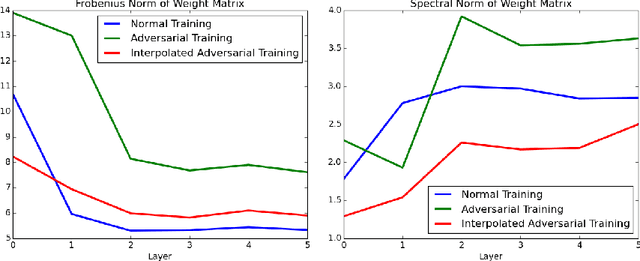
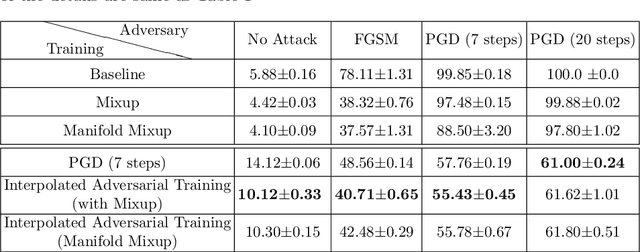
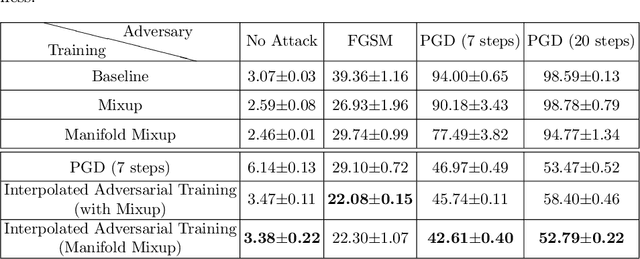
Adversarial robustness has become a central goal in deep learning, both in the theory and the practice. However, successful methods to improve the adversarial robustness (such as adversarial training) greatly hurt generalization performance on the unperturbed data. This could have a major impact on how the adversarial robustness affects real world systems (i.e. many may opt to forgo robustness if it can improve accuracy on the unperturbed data). We propose Interpolated Adversarial Training, which employs recently proposed interpolation based training methods in the framework of adversarial training. On CIFAR-10, adversarial training increases the standard test error ( when there is no adversary) from 4.43% to 12.32%, whereas with our Interpolated adversarial training we retain the adversarial robustness while achieving a standard test error of only 6.45%. With our technique, the relative increase in the standard error for the robust model is reduced from 178.1% to just 45.5%.
State-Reification Networks: Improving Generalization by Modeling the Distribution of Hidden Representations
May 26, 2019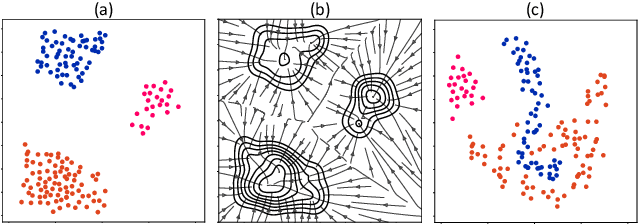
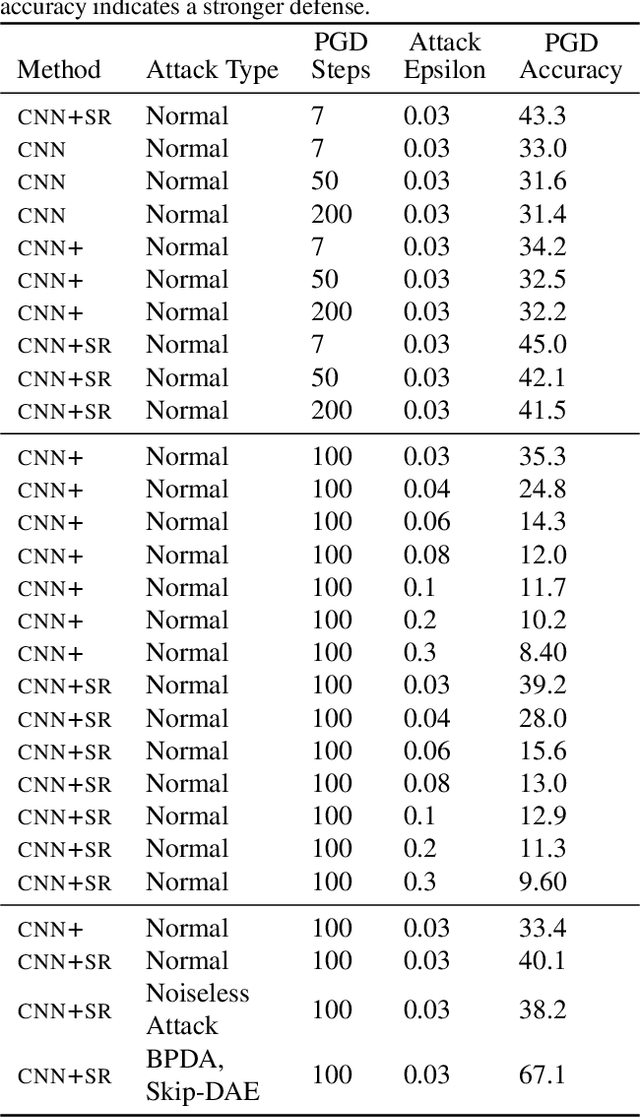
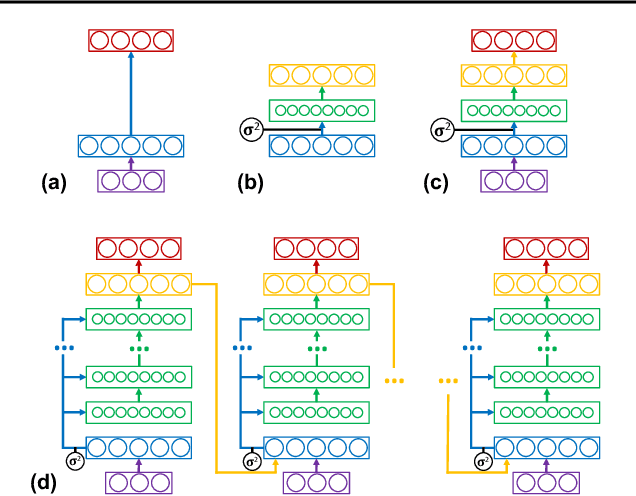
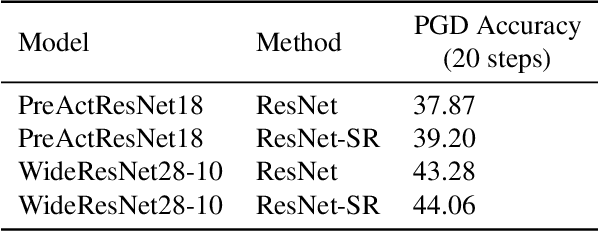
Machine learning promises methods that generalize well from finite labeled data. However, the brittleness of existing neural net approaches is revealed by notable failures, such as the existence of adversarial examples that are misclassified despite being nearly identical to a training example, or the inability of recurrent sequence-processing nets to stay on track without teacher forcing. We introduce a method, which we refer to as \emph{state reification}, that involves modeling the distribution of hidden states over the training data and then projecting hidden states observed during testing toward this distribution. Our intuition is that if the network can remain in a familiar manifold of hidden space, subsequent layers of the net should be well trained to respond appropriately. We show that this state-reification method helps neural nets to generalize better, especially when labeled data are sparse, and also helps overcome the challenge of achieving robust generalization with adversarial training.
Adversarial Mixup Resynthesizers
Apr 04, 2019
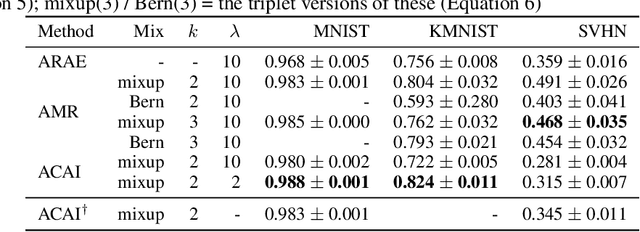
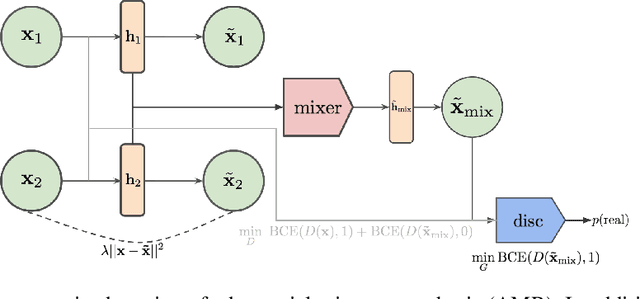
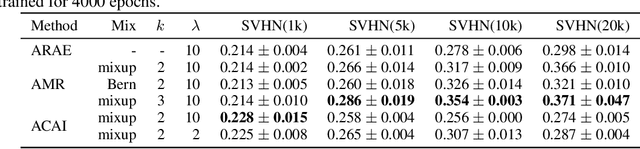
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.
Interpolation Consistency Training for Semi-Supervised Learning
Mar 09, 2019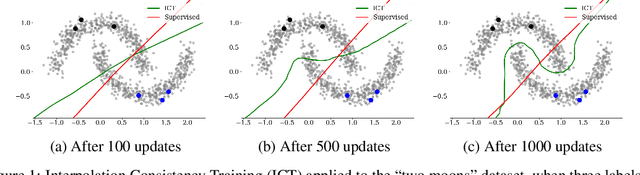
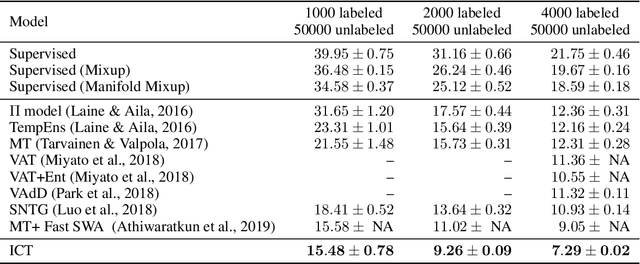
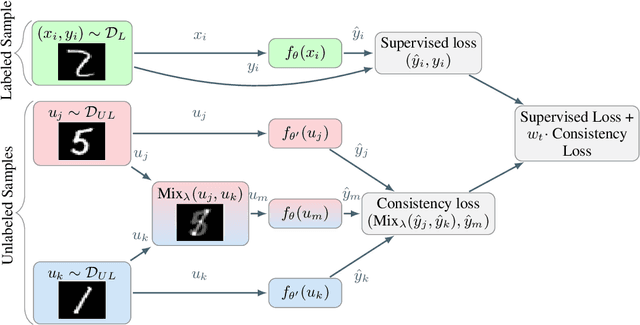
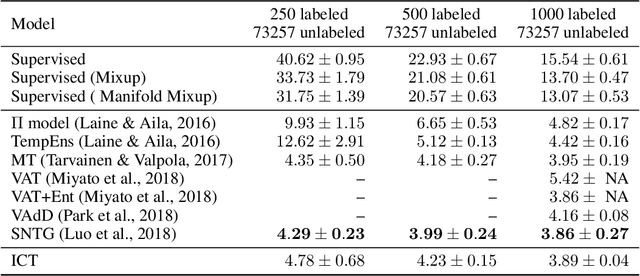
We introduce Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for training Deep Neural Networks in the semi-supervised learning paradigm. ICT encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points. In classification problems, ICT moves the decision boundary to low-density regions of the data distribution. Our experiments show that ICT achieves state-of-the-art performance when applied to standard neural network architectures on the CIFAR-10 and SVHN benchmark datasets.
Deep Learning for Classical Japanese Literature
Dec 03, 2018
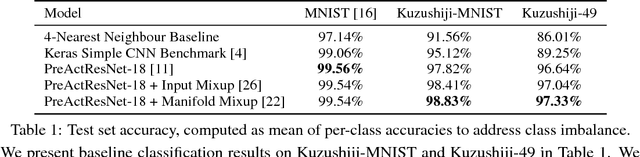


Much of machine learning research focuses on producing models which perform well on benchmark tasks, in turn improving our understanding of the challenges associated with those tasks. From the perspective of ML researchers, the content of the task itself is largely irrelevant, and thus there have increasingly been calls for benchmark tasks to more heavily focus on problems which are of social or cultural relevance. In this work, we introduce Kuzushiji-MNIST, a dataset which focuses on Kuzushiji (cursive Japanese), as well as two larger, more challenging datasets, Kuzushiji-49 and Kuzushiji-Kanji. Through these datasets, we wish to engage the machine learning community into the world of classical Japanese literature. Dataset available at https://github.com/rois-codh/kmnist