 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Memory-Augmented Neural Networks with Sparse Reads and Writes
Oct 27, 2016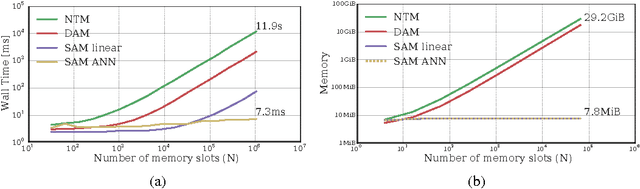
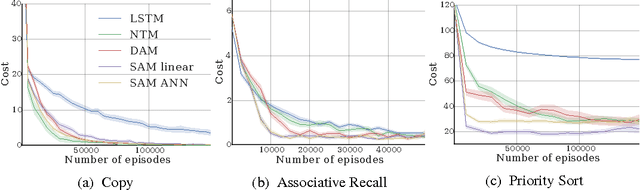
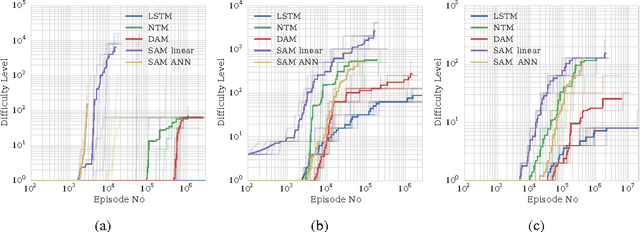
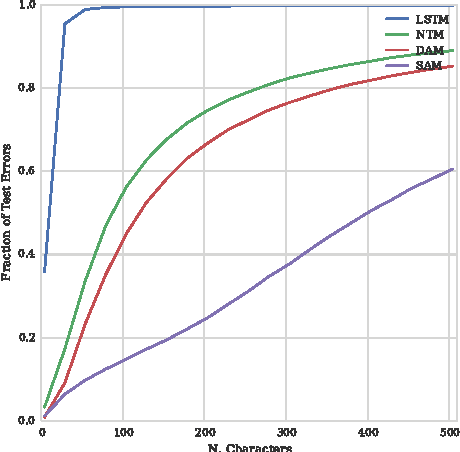
Neural networks augmented with external memory have the ability to learn algorithmic solutions to complex tasks. These models appear promising for applications such as language modeling and machine translation. However, they scale poorly in both space and time as the amount of memory grows --- limiting their applicability to real-world domains. Here, we present an end-to-end differentiable memory access scheme, which we call Sparse Access Memory (SAM), that retains the representational power of the original approaches whilst training efficiently with very large memories. We show that SAM achieves asymptotic lower bounds in space and time complexity, and find that an implementation runs $1,\!000\times$ faster and with $3,\!000\times$ less physical memory than non-sparse models. SAM learns with comparable data efficiency to existing models on a range of synthetic tasks and one-shot Omniglot character recognition, and can scale to tasks requiring $100,\!000$s of time steps and memories. As well, we show how our approach can be adapted for models that maintain temporal associations between memories, as with the recently introduced Differentiable Neural Computer.
Video Pixel Networks
Oct 03, 2016
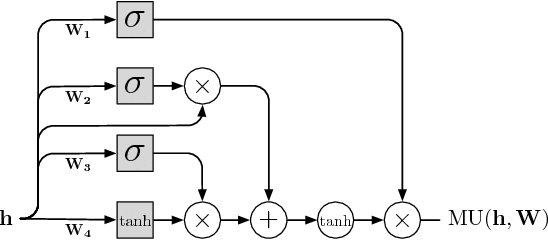


We propose a probabilistic video model, the Video Pixel Network (VPN), that estimates the discrete joint distribution of the raw pixel values in a video. The model and the neural architecture reflect the time, space and color structure of video tensors and encode it as a four-dimensional dependency chain. The VPN approaches the best possible performance on the Moving MNIST benchmark, a leap over the previous state of the art, and the generated videos show only minor deviations from the ground truth. The VPN also produces detailed samples on the action-conditional Robotic Pushing benchmark and generalizes to the motion of novel objects.
WaveNet: A Generative Model for Raw Audio
Sep 19, 2016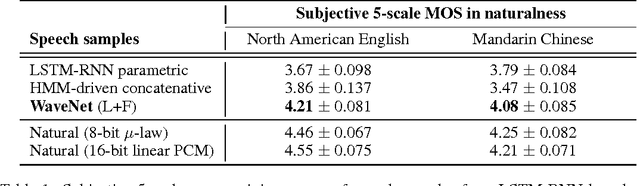
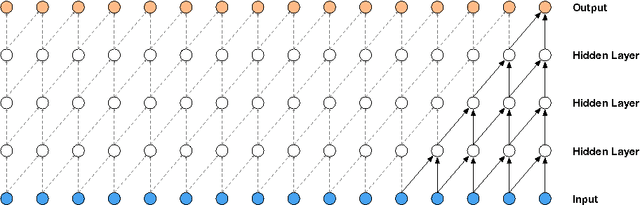
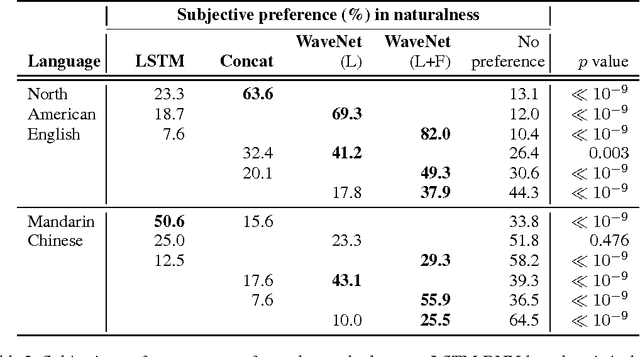
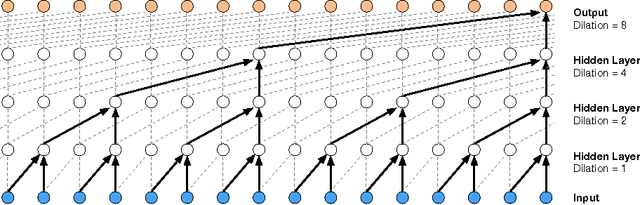
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-of-the-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
Stochastic Backpropagation through Mixture Density Distributions
Jul 19, 2016The ability to backpropagate stochastic gradients through continuous latent distributions has been crucial to the emergence of variational autoencoders and stochastic gradient variational Bayes. The key ingredient is an unbiased and low-variance way of estimating gradients with respect to distribution parameters from gradients evaluated at distribution samples. The "reparameterization trick" provides a class of transforms yielding such estimators for many continuous distributions, including the Gaussian and other members of the location-scale family. However the trick does not readily extend to mixture density models, due to the difficulty of reparameterizing the discrete distribution over mixture weights. This report describes an alternative transform, applicable to any continuous multivariate distribution with a differentiable density function from which samples can be drawn, and uses it to derive an unbiased estimator for mixture density weight derivatives. Combined with the reparameterization trick applied to the individual mixture components, this estimator makes it straightforward to train variational autoencoders with mixture-distributed latent variables, or to perform stochastic variational inference with a mixture density variational posterior.
Conditional Image Generation with PixelCNN Decoders
Jun 18, 2016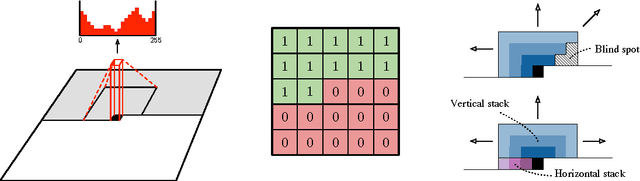
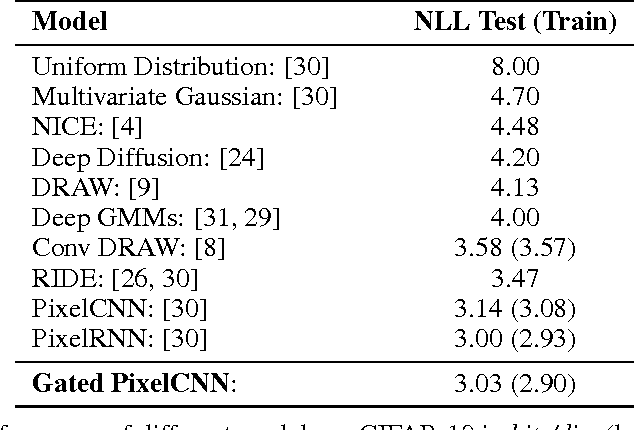
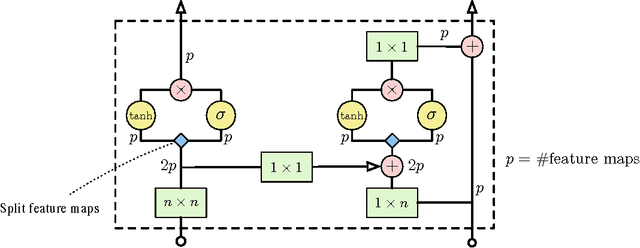
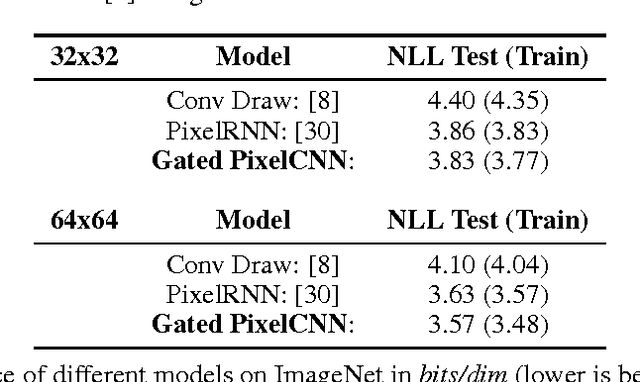
This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.
Asynchronous Methods for Deep Reinforcement Learning
Jun 16, 2016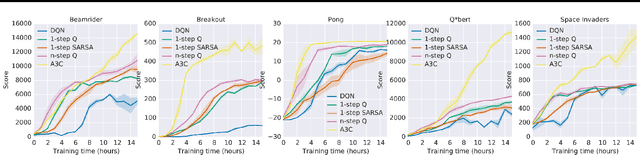

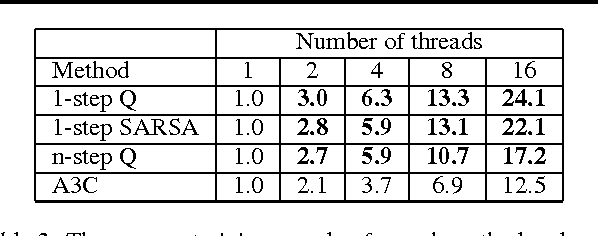
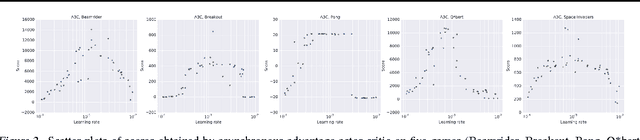
We propose a conceptually simple and lightweight framework for deep reinforcement learning that uses asynchronous gradient descent for optimization of deep neural network controllers. We present asynchronous variants of four standard reinforcement learning algorithms and show that parallel actor-learners have a stabilizing effect on training allowing all four methods to successfully train neural network controllers. The best performing method, an asynchronous variant of actor-critic, surpasses the current state-of-the-art on the Atari domain while training for half the time on a single multi-core CPU instead of a GPU. Furthermore, we show that asynchronous actor-critic succeeds on a wide variety of continuous motor control problems as well as on a new task of navigating random 3D mazes using a visual input.
Strategic Attentive Writer for Learning Macro-Actions
Jun 15, 2016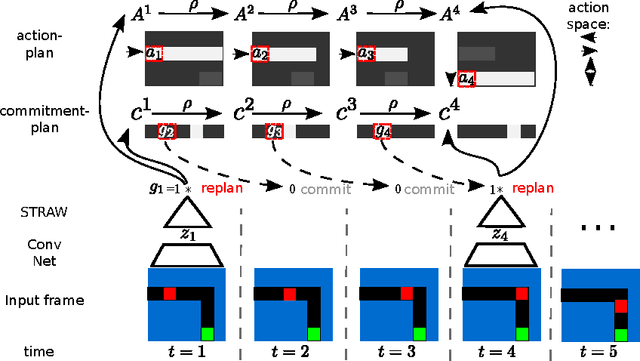


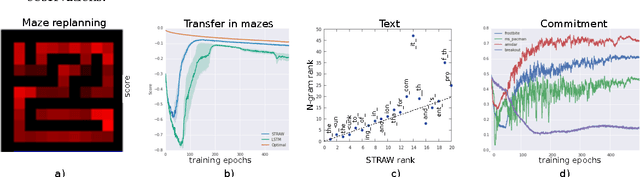
We present a novel deep recurrent neural network architecture that learns to build implicit plans in an end-to-end manner by purely interacting with an environment in reinforcement learning setting. The network builds an internal plan, which is continuously updated upon observation of the next input from the environment. It can also partition this internal representation into contiguous sub- sequences by learning for how long the plan can be committed to - i.e. followed without re-planing. Combining these properties, the proposed model, dubbed STRategic Attentive Writer (STRAW) can learn high-level, temporally abstracted macro- actions of varying lengths that are solely learnt from data without any prior information. These macro-actions enable both structured exploration and economic computation. We experimentally demonstrate that STRAW delivers strong improvements on several ATARI games by employing temporally extended planning strategies (e.g. Ms. Pacman and Frostbite). It is at the same time a general algorithm that can be applied on any sequence data. To that end, we also show that when trained on text prediction task, STRAW naturally predicts frequent n-grams (instead of macro-actions), demonstrating the generality of the approach.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016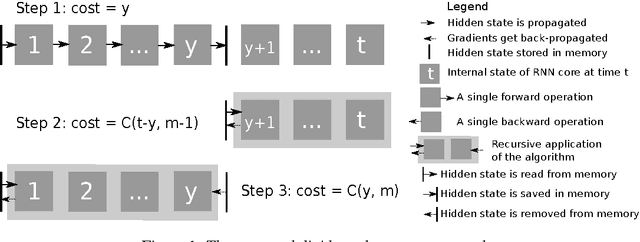
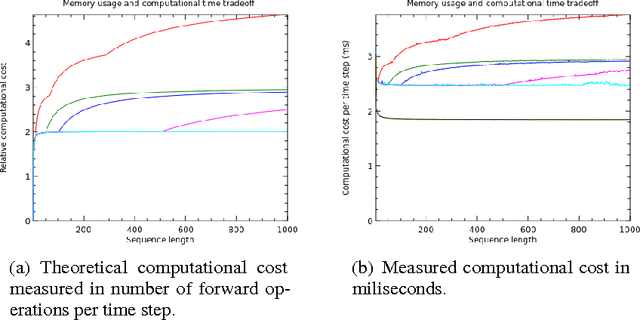
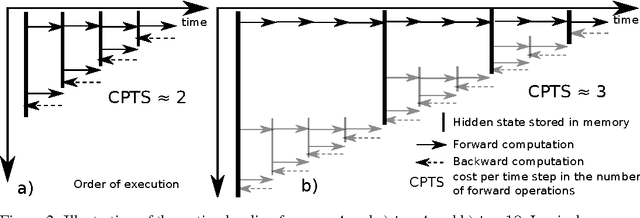
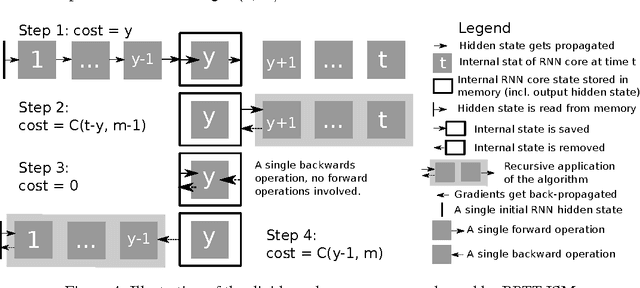
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.
Associative Long Short-Term Memory
May 19, 2016
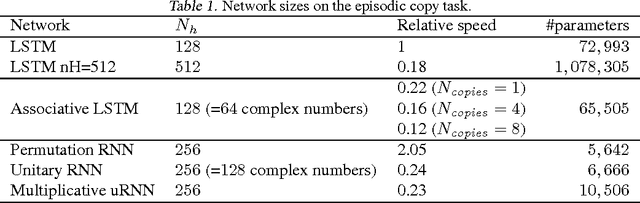


We investigate a new method to augment recurrent neural networks with extra memory without increasing the number of network parameters. The system has an associative memory based on complex-valued vectors and is closely related to Holographic Reduced Representations and Long Short-Term Memory networks. Holographic Reduced Representations have limited capacity: as they store more information, each retrieval becomes noisier due to interference. Our system in contrast creates redundant copies of stored information, which enables retrieval with reduced noise. Experiments demonstrate faster learning on multiple memorization tasks.
Grid Long Short-Term Memory
Jan 07, 2016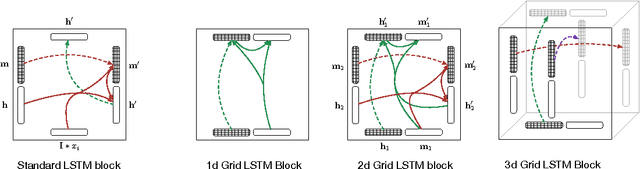
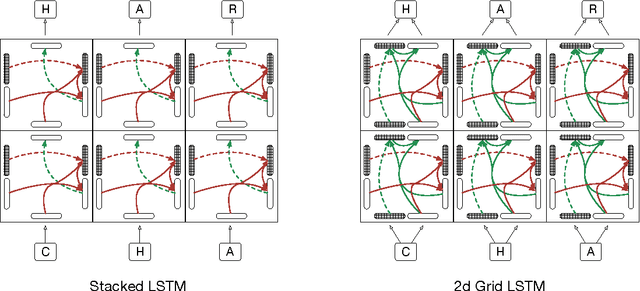
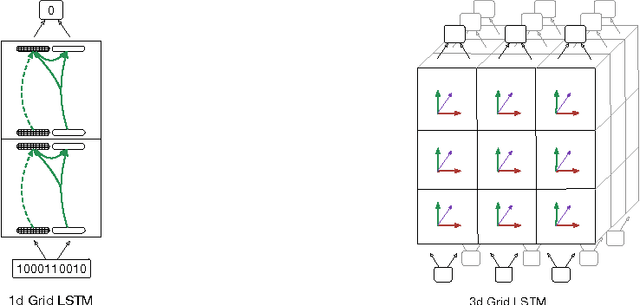

This paper introduces Grid Long Short-Term Memory, a network of LSTM cells arranged in a multidimensional grid that can be applied to vectors, sequences or higher dimensional data such as images. The network differs from existing deep LSTM architectures in that the cells are connected between network layers as well as along the spatiotemporal dimensions of the data. The network provides a unified way of using LSTM for both deep and sequential computation. We apply the model to algorithmic tasks such as 15-digit integer addition and sequence memorization, where it is able to significantly outperform the standard LSTM. We then give results for two empirical tasks. We find that 2D Grid LSTM achieves 1.47 bits per character on the Wikipedia character prediction benchmark, which is state-of-the-art among neural approaches. In addition, we use the Grid LSTM to define a novel two-dimensional translation model, the Reencoder, and show that it outperforms a phrase-based reference system on a Chinese-to-English translation task.