 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSACo: Multimodal Subject-Specific Selection and Adaptation for Expression Recognition with Co-Training
Aug 17, 2025Personalized expression recognition (ER) involves adapting a machine learning model to subject-specific data for improved recognition of expressions with considerable interpersonal variability. Subject-specific ER can benefit significantly from multi-source domain adaptation (MSDA) methods, where each domain corresponds to a specific subject, to improve model accuracy and robustness. Despite promising results, state-of-the-art MSDA approaches often overlook multimodal information or blend sources into a single domain, limiting subject diversity and failing to explicitly capture unique subject-specific characteristics. To address these limitations, we introduce MuSACo, a multi-modal subject-specific selection and adaptation method for ER based on co-training. It leverages complementary information across multiple modalities and multiple source domains for subject-specific adaptation. This makes MuSACo particularly relevant for affective computing applications in digital health, such as patient-specific assessment for stress or pain, where subject-level nuances are crucial. MuSACo selects source subjects relevant to the target and generates pseudo-labels using the dominant modality for class-aware learning, in conjunction with a class-agnostic loss to learn from less confident target samples. Finally, source features from each modality are aligned, while only confident target features are combined. Our experimental results on challenging multimodal ER datasets: BioVid and StressID, show that MuSACo can outperform UDA (blending) and state-of-the-art MSDA methods.
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.
Automatic Proficiency Assessment in L2 English Learners
May 05, 2025Second language proficiency (L2) in English is usually perceptually evaluated by English teachers or expert evaluators, with the inherent intra- and inter-rater variability. This paper explores deep learning techniques for comprehensive L2 proficiency assessment, addressing both the speech signal and its correspondent transcription. We analyze spoken proficiency classification prediction using diverse architectures, including 2D CNN, frequency-based CNN, ResNet, and a pretrained wav2vec 2.0 model. Additionally, we examine text-based proficiency assessment by fine-tuning a BERT language model within resource constraints. Finally, we tackle the complex task of spontaneous dialogue assessment, managing long-form audio and speaker interactions through separate applications of wav2vec 2.0 and BERT models. Results from experiments on EFCamDat and ANGLISH datasets and a private dataset highlight the potential of deep learning, especially the pretrained wav2vec 2.0 model, for robust automated L2 proficiency evaluation.
Progressive Multi-Source Domain Adaptation for Personalized Facial Expression Recognition
Apr 05, 2025Personalized facial expression recognition (FER) involves adapting a machine learning model using samples from labeled sources and unlabeled target domains. Given the challenges of recognizing subtle expressions with considerable interpersonal variability, state-of-the-art unsupervised domain adaptation (UDA) methods focus on the multi-source UDA (MSDA) setting, where each domain corresponds to a specific subject, and improve model accuracy and robustness. However, when adapting to a specific target, the diverse nature of multiple source domains translates to a large shift between source and target data. State-of-the-art MSDA methods for FER address this domain shift by considering all the sources to adapt to the target representations. Nevertheless, adapting to a target subject presents significant challenges due to large distributional differences between source and target domains, often resulting in negative transfer. In addition, integrating all sources simultaneously increases computational costs and causes misalignment with the target. To address these issues, we propose a progressive MSDA approach that gradually introduces information from subjects based on their similarity to the target subject. This will ensure that only the most relevant sources from the target are selected, which helps avoid the negative transfer caused by dissimilar sources. We first exploit the closest sources to reduce the distribution shift with the target and then move towards the furthest while only considering the most relevant sources based on the predetermined threshold. Furthermore, to mitigate catastrophic forgetting caused by the incremental introduction of source subjects, we implemented a density-based memory mechanism that preserves the most relevant historical source samples for adaptation. Our experiments show the effectiveness of our proposed method on pain datasets: Biovid and UNBC-McMaster.
Disentangled Source-Free Personalization for Facial Expression Recognition with Neutral Target Data
Mar 26, 2025



Facial Expression Recognition (FER) from videos is a crucial task in various application areas, such as human-computer interaction and health monitoring (e.g., pain, depression, fatigue, and stress). Beyond the challenges of recognizing subtle emotional or health states, the effectiveness of deep FER models is often hindered by the considerable variability of expressions among subjects. Source-free domain adaptation (SFDA) methods are employed to adapt a pre-trained source model using only unlabeled target domain data, thereby avoiding data privacy and storage issues. Typically, SFDA methods adapt to a target domain dataset corresponding to an entire population and assume it includes data from all recognition classes. However, collecting such comprehensive target data can be difficult or even impossible for FER in healthcare applications. In many real-world scenarios, it may be feasible to collect a short neutral control video (displaying only neutral expressions) for target subjects before deployment. These videos can be used to adapt a model to better handle the variability of expressions among subjects. This paper introduces the Disentangled Source-Free Domain Adaptation (DSFDA) method to address the SFDA challenge posed by missing target expression data. DSFDA leverages data from a neutral target control video for end-to-end generation and adaptation of target data with missing non-neutral data. Our method learns to disentangle features related to expressions and identity while generating the missing non-neutral target data, thereby enhancing model accuracy. Additionally, our self-supervision strategy improves model adaptation by reconstructing target images that maintain the same identity and source expression.
Music Genre Classification using Large Language Models
Oct 10, 2024


This paper exploits the zero-shot capabilities of pre-trained large language models (LLMs) for music genre classification. The proposed approach splits audio signals into 20 ms chunks and processes them through convolutional feature encoders, a transformer encoder, and additional layers for coding audio units and generating feature vectors. The extracted feature vectors are used to train a classification head. During inference, predictions on individual chunks are aggregated for a final genre classification. We conducted a comprehensive comparison of LLMs, including WavLM, HuBERT, and wav2vec 2.0, with traditional deep learning architectures like 1D and 2D convolutional neural networks (CNNs) and the audio spectrogram transformer (AST). Our findings demonstrate the superior performance of the AST model, achieving an overall accuracy of 85.5%, surpassing all other models evaluated. These results highlight the potential of LLMs and transformer-based architectures for advancing music information retrieval tasks, even in zero-shot scenarios.
Multi Teacher Privileged Knowledge Distillation for Multimodal Expression Recognition
Aug 16, 2024



Human emotion is a complex phenomenon conveyed and perceived through facial expressions, vocal tones, body language, and physiological signals. Multimodal emotion recognition systems can perform well because they can learn complementary and redundant semantic information from diverse sensors. In real-world scenarios, only a subset of the modalities employed for training may be available at test time. Learning privileged information allows a model to exploit data from additional modalities that are only available during training. SOTA methods for PKD have been proposed to distill information from a teacher model (with privileged modalities) to a student model (without privileged modalities). However, such PKD methods utilize point-to-point matching and do not explicitly capture the relational information. Recently, methods have been proposed to distill the structural information. However, PKD methods based on structural similarity are primarily confined to learning from a single joint teacher representation, which limits their robustness, accuracy, and ability to learn from diverse multimodal sources. In this paper, a multi-teacher PKD (MT-PKDOT) method with self-distillation is introduced to align diverse teacher representations before distilling them to the student. MT-PKDOT employs a structural similarity KD mechanism based on a regularized optimal transport (OT) for distillation. The proposed MT-PKDOT method was validated on the Affwild2 and Biovid datasets. Results indicate that our proposed method can outperform SOTA PKD methods. It improves the visual-only baseline on Biovid data by 5.5%. On the Affwild2 dataset, the proposed method improves 3% and 5% over the visual-only baseline for valence and arousal respectively. Allowing the student to learn from multiple diverse sources is shown to increase the accuracy and implicitly avoids negative transfer to the student model.
Text- and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild
Jul 17, 2024
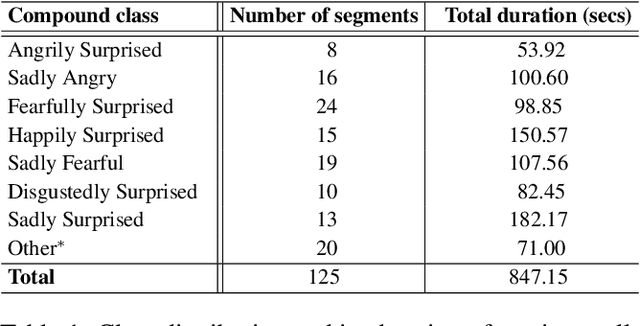


Systems for multimodal Emotion Recognition (ER) commonly rely on features extracted from different modalities (e.g., visual, audio, and textual) to predict the seven basic emotions. However, compound emotions often occur in real-world scenarios and are more difficult to predict. Compound multimodal ER becomes more challenging in videos due to the added uncertainty of diverse modalities. In addition, standard features-based models may not fully capture the complex and subtle cues needed to understand compound emotions. %%%% Since relevant cues can be extracted in the form of text, we advocate for textualizing all modalities, such as visual and audio, to harness the capacity of large language models (LLMs). These models may understand the complex interaction between modalities and the subtleties of complex emotions. Although training an LLM requires large-scale datasets, a recent surge of pre-trained LLMs, such as BERT and LLaMA, can be easily fine-tuned for downstream tasks like compound ER. This paper compares two multimodal modeling approaches for compound ER in videos -- standard feature-based vs. text-based. Experiments were conducted on the challenging C-EXPR-DB dataset for compound ER, and contrasted with results on the MELD dataset for basic ER. Our code is available
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Apr 18, 2024



The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
Alleviating Catastrophic Forgetting in Facial Expression Recognition with Emotion-Centered Models
Apr 18, 2024Facial expression recognition is a pivotal component in machine learning, facilitating various applications. However, convolutional neural networks (CNNs) are often plagued by catastrophic forgetting, impeding their adaptability. The proposed method, emotion-centered generative replay (ECgr), tackles this challenge by integrating synthetic images from generative adversarial networks. Moreover, ECgr incorporates a quality assurance algorithm to ensure the fidelity of generated images. This dual approach enables CNNs to retain past knowledge while learning new tasks, enhancing their performance in emotion recognition. The experimental results on four diverse facial expression datasets demonstrate that incorporating images generated by our pseudo-rehearsal method enhances training on the targeted dataset and the source dataset while making the CNN retain previously learned knowledge.