 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbivalence/Hesitancy Recognition in Videos for Personalized Digital Health Interventions
Apr 14, 2026Using behavioural science, health interventions focus on behaviour change by providing a framework to help patients acquire and maintain healthy habits that improve medical outcomes. In-person interventions are costly and difficult to scale, especially in resource-limited regions. Digital health interventions offer a cost-effective approach, potentially supporting independent living and self-management. Automating such interventions, especially through machine learning, has gained considerable attention recently. Ambivalence and hesitancy (A/H) play a primary role for individuals to delay, avoid, or abandon health interventions. A/H are subtle and conflicting emotions that place a person in a state between positive and negative evaluations of a behaviour, or between acceptance and refusal to engage in it. They manifest as affective inconsistency across modalities or within a modality, such as language, facial, vocal expressions, and body language. While experts can be trained to recognize A/H, integrating them into digital health interventions is costly and less effective. Automatic A/H recognition is therefore critical for the personalization and cost-effectiveness of digital health interventions. Here, we explore the application of deep learning models for A/H recognition in videos, a multi-modal task by nature. In particular, this paper covers three learning setups: supervised learning, unsupervised domain adaptation for personalization, and zero-shot inference via large language models (LLMs). Our experiments are conducted on the unique and recently published BAH video dataset for A/H recognition. Our results show limited performance, suggesting that more adapted multi-modal models are required for accurate A/H recognition. Better methods for modeling spatio-temporal and multimodal fusion are necessary to leverage conflicts within/across modalities.
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.
Text- and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild
Jul 17, 2024
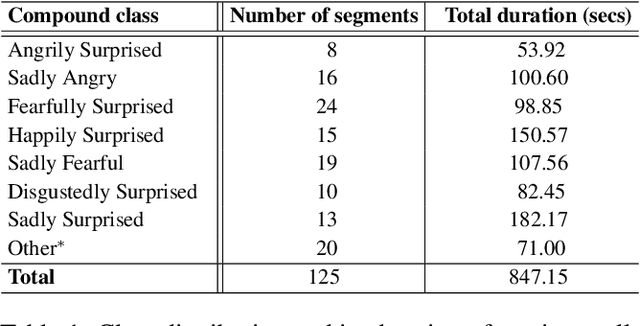


Systems for multimodal Emotion Recognition (ER) commonly rely on features extracted from different modalities (e.g., visual, audio, and textual) to predict the seven basic emotions. However, compound emotions often occur in real-world scenarios and are more difficult to predict. Compound multimodal ER becomes more challenging in videos due to the added uncertainty of diverse modalities. In addition, standard features-based models may not fully capture the complex and subtle cues needed to understand compound emotions. %%%% Since relevant cues can be extracted in the form of text, we advocate for textualizing all modalities, such as visual and audio, to harness the capacity of large language models (LLMs). These models may understand the complex interaction between modalities and the subtleties of complex emotions. Although training an LLM requires large-scale datasets, a recent surge of pre-trained LLMs, such as BERT and LLaMA, can be easily fine-tuned for downstream tasks like compound ER. This paper compares two multimodal modeling approaches for compound ER in videos -- standard feature-based vs. text-based. Experiments were conducted on the challenging C-EXPR-DB dataset for compound ER, and contrasted with results on the MELD dataset for basic ER. Our code is available