 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Performance Guarantees for Multi-Task Reinforcement Learning
Feb 02, 2026Multi-task reinforcement learning trains generalist policies that can execute multiple tasks. While recent years have seen significant progress, existing approaches rarely provide formal performance guarantees, which are indispensable when deploying policies in safety-critical settings. We present an approach for computing high-confidence guarantees on the performance of a multi-task policy on tasks not seen during training. Concretely, we introduce a new generalisation bound that composes (i) per-task lower confidence bounds from finitely many rollouts with (ii) task-level generalisation from finitely many sampled tasks, yielding a high-confidence guarantee for new tasks drawn from the same arbitrary and unknown distribution. Across state-of-the-art multi-task RL methods, we show that the guarantees are theoretically sound and informative at realistic sample sizes.
PlatoLTL: Learning to Generalize Across Symbols in LTL Instructions for Multi-Task RL
Jan 30, 2026A central challenge in multi-task reinforcement learning (RL) is to train generalist policies capable of performing tasks not seen during training. To facilitate such generalization, linear temporal logic (LTL) has recently emerged as a powerful formalism for specifying structured, temporally extended tasks to RL agents. While existing approaches to LTL-guided multi-task RL demonstrate successful generalization across LTL specifications, they are unable to generalize to unseen vocabularies of propositions (or "symbols"), which describe high-level events in LTL. We present PlatoLTL, a novel approach that enables policies to zero-shot generalize not only compositionally across LTL formula structures, but also parametrically across propositions. We achieve this by treating propositions as instances of parameterized predicates rather than discrete symbols, allowing policies to learn shared structure across related propositions. We propose a novel architecture that embeds and composes predicates to represent LTL specifications, and demonstrate successful zero-shot generalization to novel propositions and tasks across challenging environments.
Multi-Property Synthesis
Jan 15, 2026We study LTLf synthesis with multiple properties, where satisfying all properties may be impossible. Instead of enumerating subsets of properties, we compute in one fixed-point computation the relation between product-game states and the goal sets that are realizable from them, and we synthesize strategies achieving maximal realizable sets. We develop a fully symbolic algorithm that introduces Boolean goal variables and exploits monotonicity to represent exponentially many goal combinations compactly. Our approach substantially outperforms enumeration-based baselines, with speedups of up to two orders of magnitude.
Neural Proofs for Sound Verification and Control of Complex Systems
Dec 20, 2025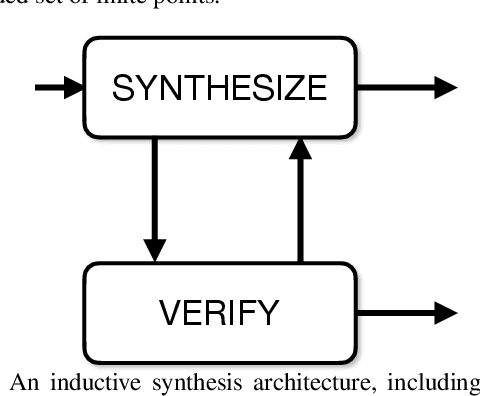
This informal contribution presents an ongoing line of research that is pursuing a new approach to the construction of sound proofs for the formal verification and control of complex stochastic models of dynamical systems, of reactive programs and, more generally, of models of Cyber-Physical Systems. Neural proofs are made up of two key components: 1) proof rules encode requirements entailing the verification of general temporal specifications over the models of interest; and 2) certificates that discharge such rules, namely they are constructed from said proof rules with an inductive (that is, cyclic, repetitive) approach; this inductive approach involves: 2a) accessing samples from the model's dynamics and accordingly training neural networks, whilst 2b) generalising such networks via SAT-modulo-theory (SMT) queries that leverage the full knowledge of the models. In the context of sequential decision making problems over complex stochastic models, it is possible to additionally generate provably-correct policies/strategies/controllers, namely state-feedback functions that, in conjunction with neural certificates, formally attain the given specifications for the models of interest.
Scalable Verification of Neural Control Barrier Functions Using Linear Bound Propagation
Nov 09, 2025



Control barrier functions (CBFs) are a popular tool for safety certification of nonlinear dynamical control systems. Recently, CBFs represented as neural networks have shown great promise due to their expressiveness and applicability to a broad class of dynamics and safety constraints. However, verifying that a trained neural network is indeed a valid CBF is a computational bottleneck that limits the size of the networks that can be used. To overcome this limitation, we present a novel framework for verifying neural CBFs based on piecewise linear upper and lower bounds on the conditions required for a neural network to be a CBF. Our approach is rooted in linear bound propagation (LBP) for neural networks, which we extend to compute bounds on the gradients of the network. Combined with McCormick relaxation, we derive linear upper and lower bounds on the CBF conditions, thereby eliminating the need for computationally expensive verification procedures. Our approach applies to arbitrary control-affine systems and a broad range of nonlinear activation functions. To reduce conservatism, we develop a parallelizable refinement strategy that adaptively refines the regions over which these bounds are computed. Our approach scales to larger neural networks than state-of-the-art verification procedures for CBFs, as demonstrated by our numerical experiments.
Stabilizing Policy Gradients for Sample-Efficient Reinforcement Learning in LLM Reasoning
Oct 01, 2025Reinforcement Learning, particularly through policy gradient methods, has played a central role in enabling reasoning capabilities of Large Language Models. However, the optimization stability of policy gradients in this setting remains understudied. As a result, existing implementations often resort to conservative hyperparameter choices to ensure stability, which requires more training samples and increases computational costs. Hence, developing models for reliably tracking the underlying optimization dynamics and leveraging them into training enables more sample-efficient regimes and further unleashes scalable post-training. We address this gap by formalizing the stochastic optimization problem of policy gradients with explicit consideration of second-order geometry. We propose a tractable computational framework that tracks and leverages curvature information during policy updates. We further employ this framework to design interventions in the optimization process through data selection. The resultant algorithm, Curvature-Aware Policy Optimization (CAPO), identifies samples that contribute to unstable updates and masks them out. Theoretically, we establish monotonic improvement guarantees under realistic assumptions. On standard math reasoning benchmarks, we empirically show that CAPO ensures stable updates under aggressive learning regimes where baselines catastrophically fail. With minimal intervention (rejecting fewer than 8% of tokens), CAPO achieves up to 30x improvement in sample efficiency over standard GRPO for LLM reasoning.
Best-Effort Policies for Robust Markov Decision Processes
Aug 11, 2025We study the common generalization of Markov decision processes (MDPs) with sets of transition probabilities, known as robust MDPs (RMDPs). A standard goal in RMDPs is to compute a policy that maximizes the expected return under an adversarial choice of the transition probabilities. If the uncertainty in the probabilities is independent between the states, known as s-rectangularity, such optimal robust policies can be computed efficiently using robust value iteration. However, there might still be multiple optimal robust policies, which, while equivalent with respect to the worst-case, reflect different expected returns under non-adversarial choices of the transition probabilities. Hence, we propose a refined policy selection criterion for RMDPs, drawing inspiration from the notions of dominance and best-effort in game theory. Instead of seeking a policy that only maximizes the worst-case expected return, we additionally require the policy to achieve a maximal expected return under different (i.e., not fully adversarial) transition probabilities. We call such a policy an optimal robust best-effort (ORBE) policy. We prove that ORBE policies always exist, characterize their structure, and present an algorithm to compute them with a small overhead compared to standard robust value iteration. ORBE policies offer a principled tie-breaker among optimal robust policies. Numerical experiments show the feasibility of our approach.
Efficient Solution and Learning of Robust Factored MDPs
Aug 01, 2025Robust Markov decision processes (r-MDPs) extend MDPs by explicitly modelling epistemic uncertainty about transition dynamics. Learning r-MDPs from interactions with an unknown environment enables the synthesis of robust policies with provable (PAC) guarantees on performance, but this can require a large number of sample interactions. We propose novel methods for solving and learning r-MDPs based on factored state-space representations that leverage the independence between model uncertainty across system components. Although policy synthesis for factored r-MDPs leads to hard, non-convex optimisation problems, we show how to reformulate these into tractable linear programs. Building on these, we also propose methods to learn factored model representations directly. Our experimental results show that exploiting factored structure can yield dimensional gains in sample efficiency, producing more effective robust policies with tighter performance guarantees than state-of-the-art methods.
Certified Neural Approximations of Nonlinear Dynamics
May 21, 2025Neural networks hold great potential to act as approximate models of nonlinear dynamical systems, with the resulting neural approximations enabling verification and control of such systems. However, in safety-critical contexts, the use of neural approximations requires formal bounds on their closeness to the underlying system. To address this fundamental challenge, we propose a novel, adaptive, and parallelizable verification method based on certified first-order models. Our approach provides formal error bounds on the neural approximations of dynamical systems, allowing them to be safely employed as surrogates by interpreting the error bound as bounded disturbances acting on the approximated dynamics. We demonstrate the effectiveness and scalability of our method on a range of established benchmarks from the literature, showing that it outperforms the state-of-the-art. Furthermore, we highlight the flexibility of our framework by applying it to two novel scenarios not previously explored in this context: neural network compression and an autoencoder-based deep learning architecture for learning Koopman operators, both yielding compelling results.
SPoRt -- Safe Policy Ratio: Certified Training and Deployment of Task Policies in Model-Free RL
Apr 08, 2025To apply reinforcement learning to safety-critical applications, we ought to provide safety guarantees during both policy training and deployment. In this work we present novel theoretical results that provide a bound on the probability of violating a safety property for a new task-specific policy in a model-free, episodic setup: the bound, based on a `maximum policy ratio' that is computed with respect to a `safe' base policy, can also be more generally applied to temporally-extended properties (beyond safety) and to robust control problems. We thus present SPoRt, which also provides a data-driven approach for obtaining such a bound for the base policy, based on scenario theory, and which includes Projected PPO, a new projection-based approach for training the task-specific policy while maintaining a user-specified bound on property violation. Hence, SPoRt enables the user to trade off safety guarantees in exchange for task-specific performance. Accordingly, we present experimental results demonstrating this trade-off, as well as a comparison of the theoretical bound to posterior bounds based on empirical violation rates.