 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Exploration Strategies in Dynamic Environments Through Informed Policy Regularization
May 06, 2020

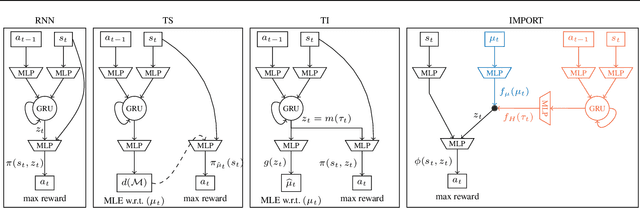
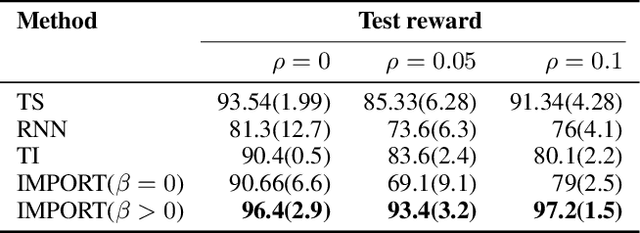
We study the problem of learning exploration-exploitation strategies that effectively adapt to dynamic environments, where the task may change over time. While RNN-based policies could in principle represent such strategies, in practice their training time is prohibitive and the learning process often converges to poor solutions. In this paper, we consider the case where the agent has access to a description of the task (e.g., a task id or task parameters) at training time, but not at test time. We propose a novel algorithm that regularizes the training of an RNN-based policy using informed policies trained to maximize the reward in each task. This dramatically reduces the sample complexity of training RNN-based policies, without losing their representational power. As a result, our method learns exploration strategies that efficiently balance between gathering information about the unknown and changing task and maximizing the reward over time. We test the performance of our algorithm in a variety of environments where tasks may vary within each episode.
Active Model Estimation in Markov Decision Processes
Mar 06, 2020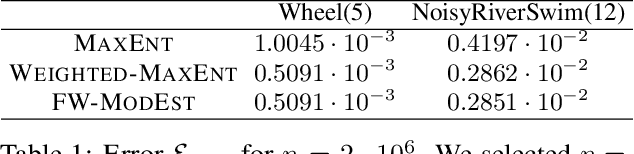
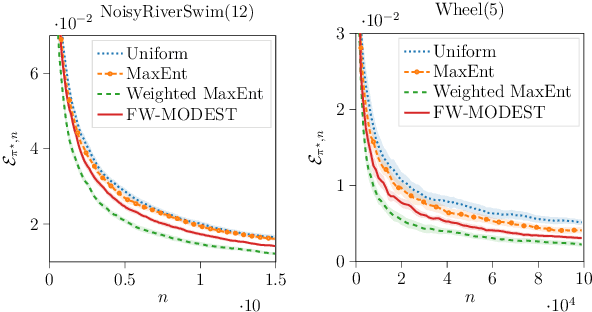
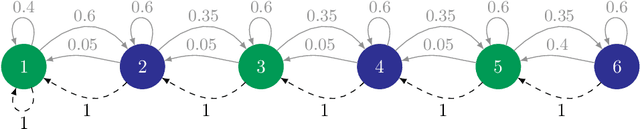
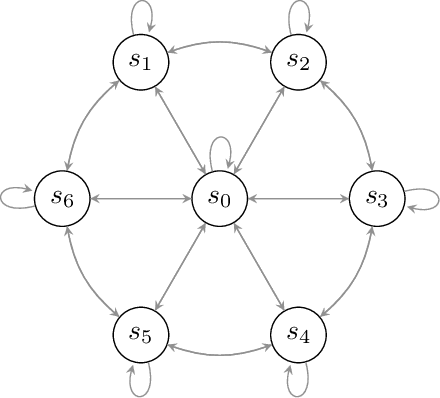
We study the problem of efficient exploration in order to learn an accurate model of an environment, modeled as a Markov decision process (MDP). Efficient exploration in this problem requires the agent to identify the regions in which estimating the model is more difficult and then exploit this knowledge to collect more samples there. In this paper, we formalize this problem, introduce the first algorithm to learn an $\epsilon$-accurate estimate of the dynamics, and provide its sample complexity analysis. While this algorithm enjoys strong guarantees in the large-sample regime, it tends to have a poor performance in early stages of exploration. To address this issue, we propose an algorithm that is based on maximum weighted entropy, a heuristic that stems from common sense and our theoretical analysis. The main idea here is cover the entire state-action space with the weight proportional to the noise in the transitions. Using a number of simple domains with heterogeneous noise in their transitions, we show that our heuristic-based algorithm outperforms both our original algorithm and the maximum entropy algorithm in the small sample regime, while achieving similar asymptotic performance as that of the original algorithm.
Learning Near Optimal Policies with Low Inherent Bellman Error
Mar 05, 2020
We study the exploration problem with approximate linear action-value functions in episodic reinforcement learning under the notion of low inherent Bellman error, a condition normally employed to show convergence of approximate value iteration. First we relate this condition to other common frameworks and show that it is strictly more general than the low rank (or linear) MDP assumption of prior work. Second we provide an algorithm with a high probability regret bound $\widetilde O(\sum_{t=1}^H d_t \sqrt{K} + \sum_{t=1}^H \sqrt{d_t} \IBE K)$ where $H$ is the horizon, $K$ is the number of episodes, $\IBE$ is the value if the inherent Bellman error and $d_t$ is the feature dimension at timestep $t$. In addition, we show that the result is unimprovable beyond constants and logs by showing a matching lower bound. This has two important consequences: 1) the algorithm has the optimal statistical rate for this setting which is more general than prior work on low-rank MDPs 2) the lack of closedness (measured by the inherent Bellman error) is only amplified by $\sqrt{d_t}$ despite working in the online setting. Finally, the algorithm reduces to the celebrated \textsc{LinUCB} when $H=1$ but with a different choice of the exploration parameter that allows handling misspecified contextual linear bandits. While computational tractability questions remain open for the MDP setting, this enriches the class of MDPs with a linear representation for the action-value function where statistically efficient reinforcement learning is possible.
Near-linear Time Gaussian Process Optimization with Adaptive Batching and Resparsification
Feb 26, 2020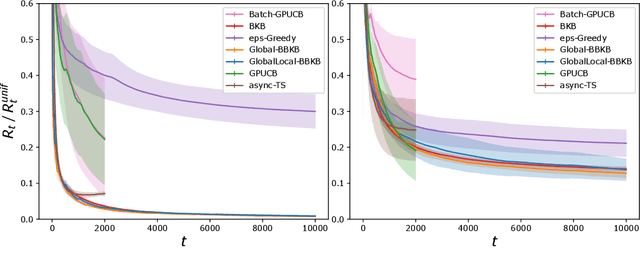
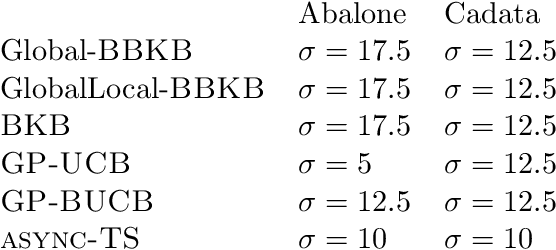
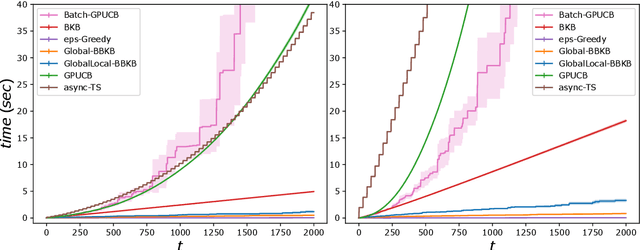
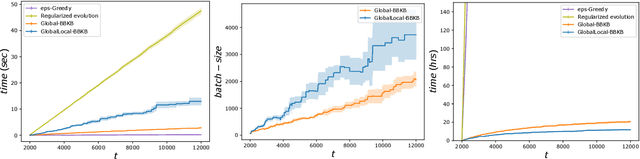
Gaussian processes (GP) are one of the most successful frameworks to model uncertainty. However, GP optimization (e.g., GP-UCB) suffers from major scalability issues. Experimental time grows linearly with the number of evaluations, unless candidates are selected in batches (e.g., using GP-BUCB) and evaluated in parallel. Furthermore, computational cost is often prohibitive since algorithms such as GP-BUCB require a time at least quadratic in the number of dimensions and iterations to select each batch. In this paper, we introduce BBKB (Batch Budgeted Kernel Bandits), the first no-regret GP optimization algorithm that provably runs in near-linear time and selects candidates in batches. This is obtained with a new guarantee for the tracking of the posterior variances that allows BBKB to choose increasingly larger batches, improving over GP-BUCB. Moreover, we show that the same bound can be used to adaptively delay costly updates to the sparse GP approximation used by BBKB, achieving a near-constant per-step amortized cost. These findings are then confirmed in several experiments, where BBKB is much faster than state-of-the-art methods.
Adversarial Attacks on Linear Contextual Bandits
Feb 11, 2020
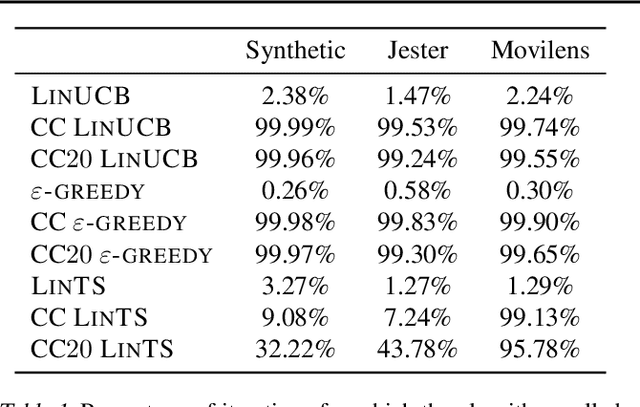
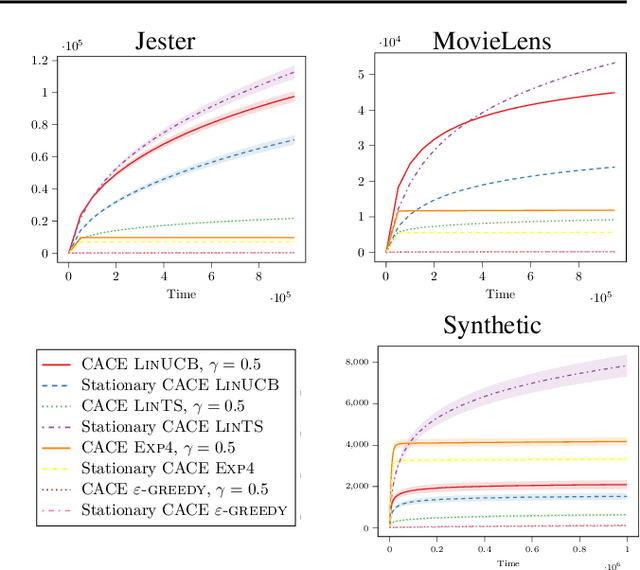
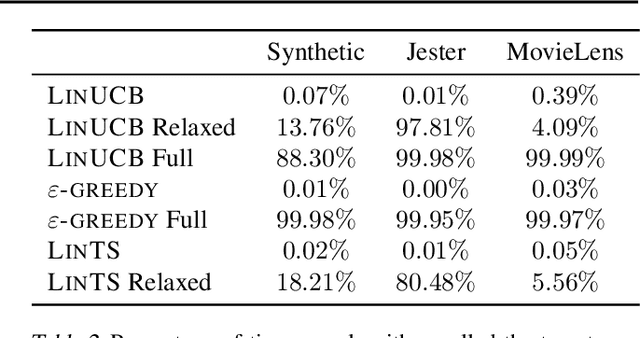
Contextual bandit algorithms are applied in a wide range of domains, from advertising to recommender systems, from clinical trials to education. In many of these domains, malicious agents may have incentives to attack the bandit algorithm to induce it to perform a desired behavior. For instance, an unscrupulous ad publisher may try to increase their own revenue at the expense of the advertisers; a seller may want to increase the exposure of their products, or thwart a competitor's advertising campaign. In this paper, we study several attack scenarios and show that a malicious agent can force a linear contextual bandit algorithm to pull any desired arm $T - o(T)$ times over a horizon of $T$ steps, while applying adversarial modifications to either rewards or contexts that only grow logarithmically as $O(\log T)$. We also investigate the case when a malicious agent is interested in affecting the behavior of the bandit algorithm in a single context (e.g., a specific user). We first provide sufficient conditions for the feasibility of the attack and we then propose an efficient algorithm to perform the attack. We validate our theoretical results on experiments performed on both synthetic and real-world datasets.
Improved Algorithms for Conservative Exploration in Bandits
Feb 08, 2020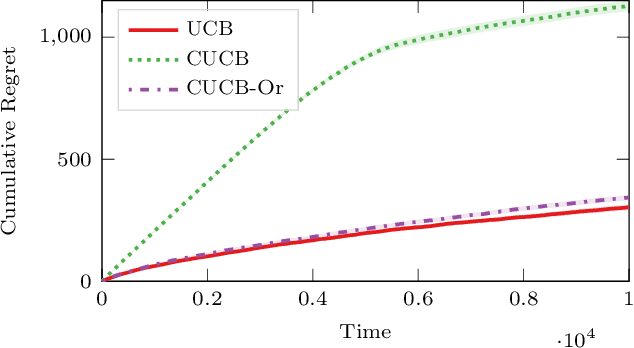
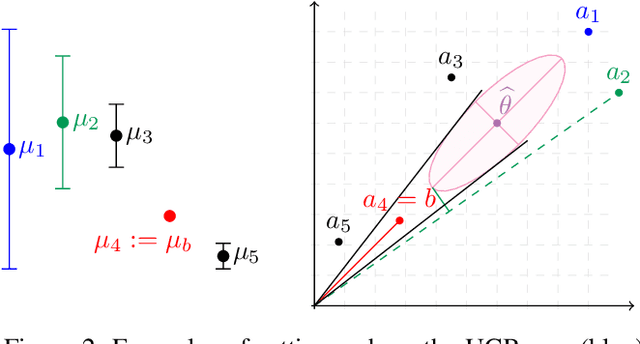
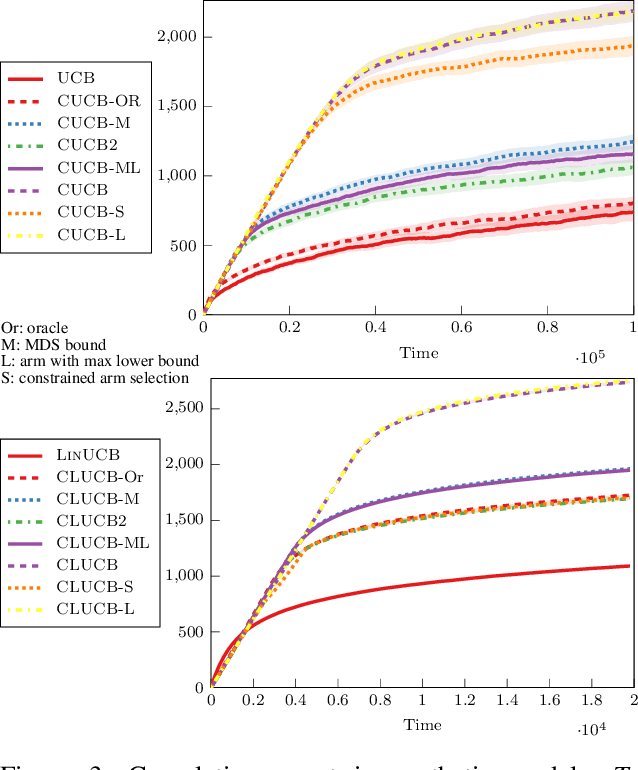
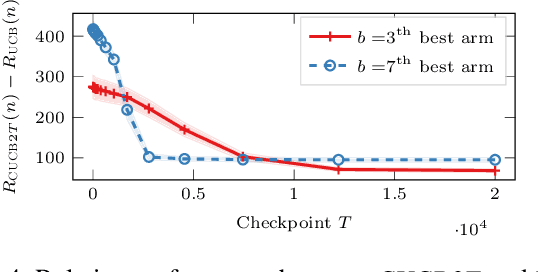
In many fields such as digital marketing, healthcare, finance, and robotics, it is common to have a well-tested and reliable baseline policy running in production (e.g., a recommender system). Nonetheless, the baseline policy is often suboptimal. In this case, it is desirable to deploy online learning algorithms (e.g., a multi-armed bandit algorithm) that interact with the system to learn a better/optimal policy under the constraint that during the learning process the performance is almost never worse than the performance of the baseline itself. In this paper, we study the conservative learning problem in the contextual linear bandit setting and introduce a novel algorithm, the Conservative Constrained LinUCB (CLUCB2). We derive regret bounds for CLUCB2 that match existing results and empirically show that it outperforms state-of-the-art conservative bandit algorithms in a number of synthetic and real-world problems. Finally, we consider a more realistic constraint where the performance is verified only at predefined checkpoints (instead of at every step) and show how this relaxed constraint favorably impacts the regret and empirical performance of CLUCB2.
Conservative Exploration in Reinforcement Learning
Feb 08, 2020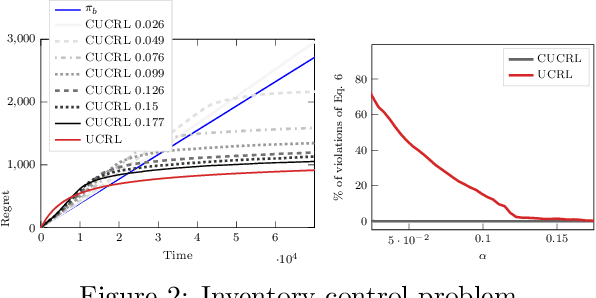

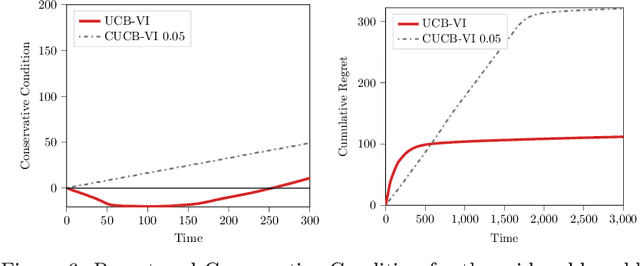
While learning in an unknown Markov Decision Process (MDP), an agent should trade off exploration to discover new information about the MDP, and exploitation of the current knowledge to maximize the reward. Although the agent will eventually learn a good or optimal policy, there is no guarantee on the quality of the intermediate policies. This lack of control is undesired in real-world applications where a minimum requirement is that the executed policies are guaranteed to perform at least as well as an existing baseline. In this paper, we introduce the notion of conservative exploration for average reward and finite horizon problems. We present two optimistic algorithms that guarantee (w.h.p.) that the conservative constraint is never violated during learning. We derive regret bounds showing that being conservative does not hinder the learning ability of these algorithms.
Concentration Inequalities for Multinoulli Random Variables
Jan 30, 2020We investigate concentration inequalities for Dirichlet and Multinomial random variables.
No-Regret Exploration in Goal-Oriented Reinforcement Learning
Jan 30, 2020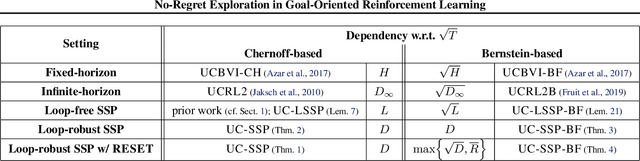
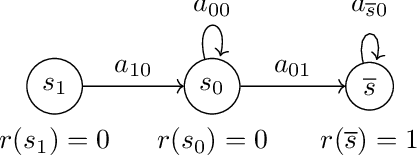

Many popular reinforcement learning problems (e.g., navigation in a maze, some Atari games, mountain car) are instances of the episodic setting under its stochastic shortest path (SSP) formulation, where an agent has to achieve a goal state while minimizing the cumulative cost. Despite the popularity of this setting, the exploration-exploitation dilemma has been sparsely studied in general SSP problems, with most of the theoretical literature focusing on different problems (i.e., fixed-horizon and infinite-horizon) or making the restrictive loop-free SSP assumption (i.e., no state can be visited twice during an episode). In this paper, we study the general SSP problem with no assumption on its dynamics (some policies may actually never reach the goal). We introduce UC-SSP, the first no-regret algorithm in this setting, and prove a regret bound scaling as $\displaystyle \widetilde{\mathcal{O}}( D S \sqrt{ A D K})$ after $K$ episodes for any unknown SSP with $S$ states, $A$ actions, positive costs and SSP-diameter $D$, defined as the smallest expected hitting time from any starting state to the goal. We achieve this result by crafting a novel stopping rule, such that UC-SSP may interrupt the current policy if it is taking too long to achieve the goal and switch to alternative policies that are designed to rapidly terminate the episode.
Frequentist Regret Bounds for Randomized Least-Squares Value Iteration
Nov 01, 2019
We consider the exploration-exploitation dilemma in finite-horizon reinforcement learning (RL). When the state space is large or continuous, traditional tabular approaches are unfeasible and some form of function approximation is mandatory. In this paper, we introduce an optimistically-initialized variant of the popular randomized least-squares value iteration (RLSVI), a model-free algorithm where exploration is induced by perturbing the least-squares approximation of the action-value function. Under the assumption that the Markov decision process has low-rank transition dynamics, we prove that the frequentist regret of RLSVI is upper-bounded by $\widetilde O(d^2 H^2 \sqrt{T})$ where $ d $ are the feature dimension, $ H $ is the horizon, and $ T $ is the total number of steps. To the best of our knowledge, this is the first frequentist regret analysis for randomized exploration with function approximation.