 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePara-active learning
Oct 30, 2013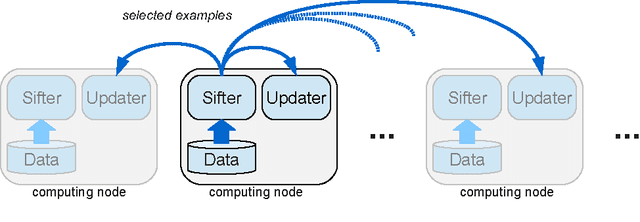

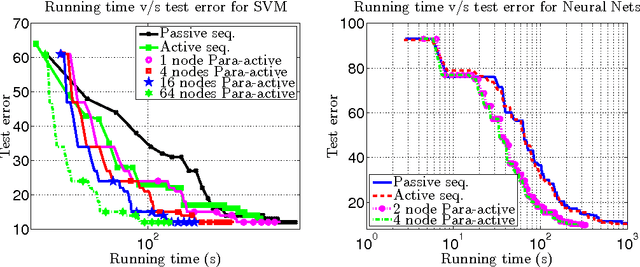
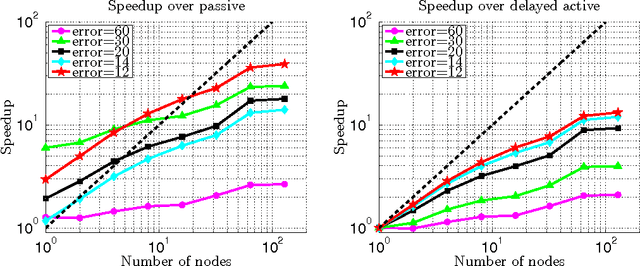
Training examples are not all equally informative. Active learning strategies leverage this observation in order to massively reduce the number of examples that need to be labeled. We leverage the same observation to build a generic strategy for parallelizing learning algorithms. This strategy is effective because the search for informative examples is highly parallelizable and because we show that its performance does not deteriorate when the sifting process relies on a slightly outdated model. Parallel active learning is particularly attractive to train nonlinear models with non-linear representations because there are few practical parallel learning algorithms for such models. We report preliminary experiments using both kernel SVMs and SGD-trained neural networks.
Least Squares Revisited: Scalable Approaches for Multi-class Prediction
Oct 21, 2013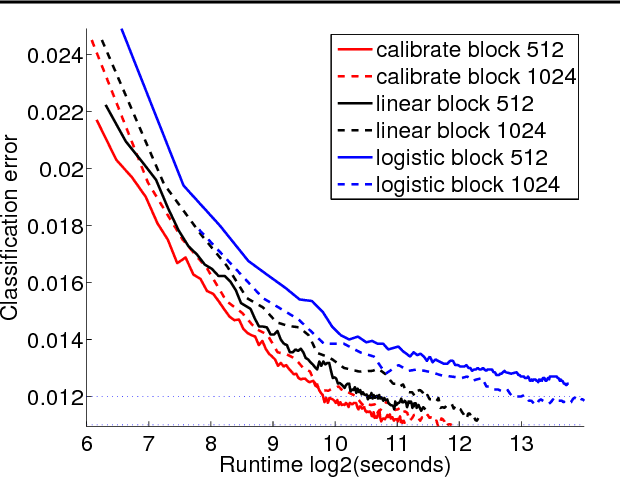

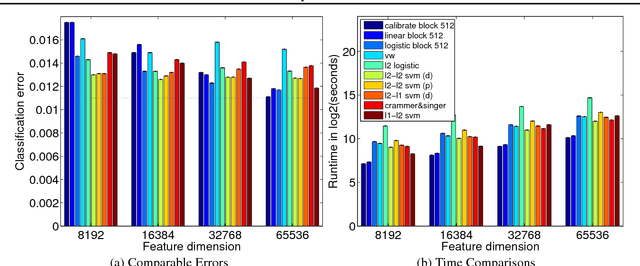
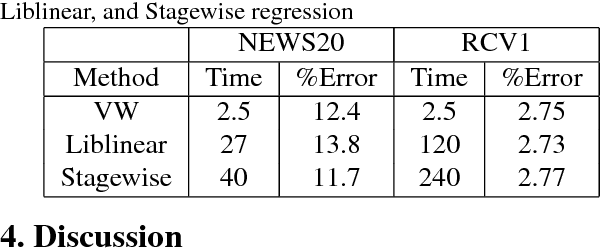
This work provides simple algorithms for multi-class (and multi-label) prediction in settings where both the number of examples n and the data dimension d are relatively large. These robust and parameter free algorithms are essentially iterative least-squares updates and very versatile both in theory and in practice. On the theoretical front, we present several variants with convergence guarantees. Owing to their effective use of second-order structure, these algorithms are substantially better than first-order methods in many practical scenarios. On the empirical side, we present a scalable stagewise variant of our approach, which achieves dramatic computational speedups over popular optimization packages such as Liblinear and Vowpal Wabbit on standard datasets (MNIST and CIFAR-10), while attaining state-of-the-art accuracies.
A Reliable Effective Terascale Linear Learning System
Jul 12, 2013We present a system and a set of techniques for learning linear predictors with convex losses on terascale datasets, with trillions of features, {The number of features here refers to the number of non-zero entries in the data matrix.} billions of training examples and millions of parameters in an hour using a cluster of 1000 machines. Individually none of the component techniques are new, but the careful synthesis required to obtain an efficient implementation is. The result is, up to our knowledge, the most scalable and efficient linear learning system reported in the literature (as of 2011 when our experiments were conducted). We describe and thoroughly evaluate the components of the system, showing the importance of the various design choices.
Oracle inequalities for computationally adaptive model selection
Aug 01, 2012
We analyze general model selection procedures using penalized empirical loss minimization under computational constraints. While classical model selection approaches do not consider computational aspects of performing model selection, we argue that any practical model selection procedure must not only trade off estimation and approximation error, but also the computational effort required to compute empirical minimizers for different function classes. We provide a framework for analyzing such problems, and we give algorithms for model selection under a computational budget. These algorithms satisfy oracle inequalities that show that the risk of the selected model is not much worse than if we had devoted all of our omputational budget to the optimal function class.
Ergodic Mirror Descent
Aug 01, 2012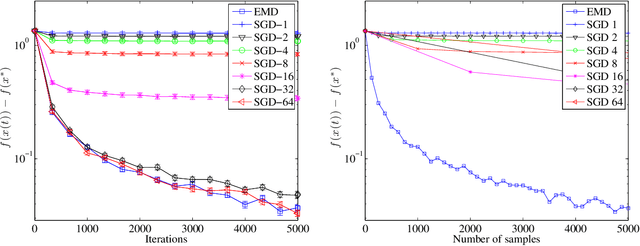
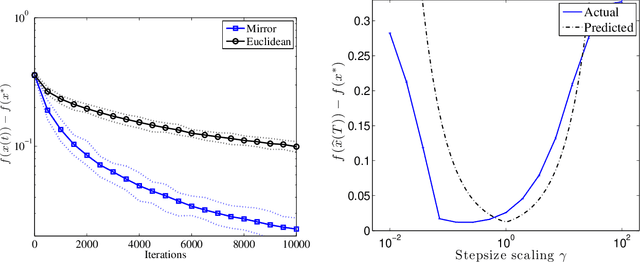
We generalize stochastic subgradient descent methods to situations in which we do not receive independent samples from the distribution over which we optimize, but instead receive samples that are coupled over time. We show that as long as the source of randomness is suitably ergodic---it converges quickly enough to a stationary distribution---the method enjoys strong convergence guarantees, both in expectation and with high probability. This result has implications for stochastic optimization in high-dimensional spaces, peer-to-peer distributed optimization schemes, decision problems with dependent data, and stochastic optimization problems over combinatorial spaces.
Fast global convergence of gradient methods for high-dimensional statistical recovery
Jul 25, 2012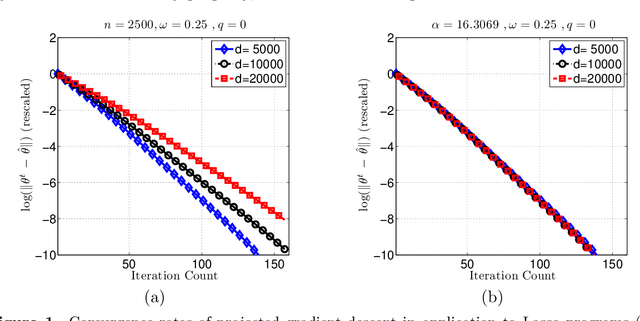
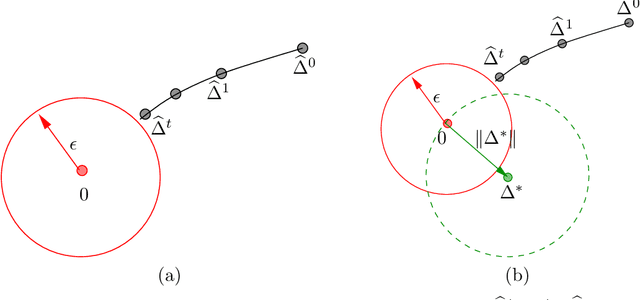
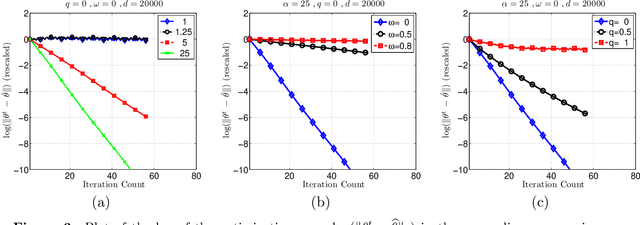
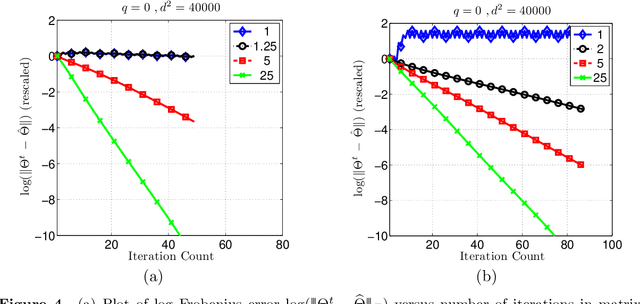
Many statistical $M$-estimators are based on convex optimization problems formed by the combination of a data-dependent loss function with a norm-based regularizer. We analyze the convergence rates of projected gradient and composite gradient methods for solving such problems, working within a high-dimensional framework that allows the data dimension $\pdim$ to grow with (and possibly exceed) the sample size $\numobs$. This high-dimensional structure precludes the usual global assumptions---namely, strong convexity and smoothness conditions---that underlie much of classical optimization analysis. We define appropriately restricted versions of these conditions, and show that they are satisfied with high probability for various statistical models. Under these conditions, our theory guarantees that projected gradient descent has a globally geometric rate of convergence up to the \emph{statistical precision} of the model, meaning the typical distance between the true unknown parameter $\theta^*$ and an optimal solution $\hat{\theta}$. This result is substantially sharper than previous convergence results, which yielded sublinear convergence, or linear convergence only up to the noise level. Our analysis applies to a wide range of $M$-estimators and statistical models, including sparse linear regression using Lasso ($\ell_1$-regularized regression); group Lasso for block sparsity; log-linear models with regularization; low-rank matrix recovery using nuclear norm regularization; and matrix decomposition. Overall, our analysis reveals interesting connections between statistical precision and computational efficiency in high-dimensional estimation.
Stochastic optimization and sparse statistical recovery: An optimal algorithm for high dimensions
Jul 18, 2012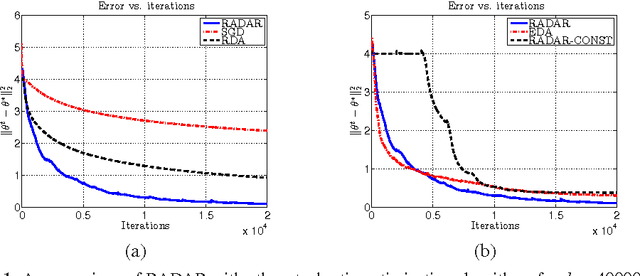
We develop and analyze stochastic optimization algorithms for problems in which the expected loss is strongly convex, and the optimum is (approximately) sparse. Previous approaches are able to exploit only one of these two structures, yielding an $\order(\pdim/T)$ convergence rate for strongly convex objectives in $\pdim$ dimensions, and an $\order(\sqrt{(\spindex \log \pdim)/T})$ convergence rate when the optimum is $\spindex$-sparse. Our algorithm is based on successively solving a series of $\ell_1$-regularized optimization problems using Nesterov's dual averaging algorithm. We establish that the error of our solution after $T$ iterations is at most $\order((\spindex \log\pdim)/T)$, with natural extensions to approximate sparsity. Our results apply to locally Lipschitz losses including the logistic, exponential, hinge and least-squares losses. By recourse to statistical minimax results, we show that our convergence rates are optimal up to multiplicative constant factors. The effectiveness of our approach is also confirmed in numerical simulations, in which we compare to several baselines on a least-squares regression problem.
The Generalization Ability of Online Algorithms for Dependent Data
Jun 07, 2012
We study the generalization performance of online learning algorithms trained on samples coming from a dependent source of data. We show that the generalization error of any stable online algorithm concentrates around its regret--an easily computable statistic of the online performance of the algorithm--when the underlying ergodic process is $\beta$- or $\phi$-mixing. We show high probability error bounds assuming the loss function is convex, and we also establish sharp convergence rates and deviation bounds for strongly convex losses and several linear prediction problems such as linear and logistic regression, least-squares SVM, and boosting on dependent data. In addition, our results have straightforward applications to stochastic optimization with dependent data, and our analysis requires only martingale convergence arguments; we need not rely on more powerful statistical tools such as empirical process theory.
Noisy matrix decomposition via convex relaxation: Optimal rates in high dimensions
Mar 06, 2012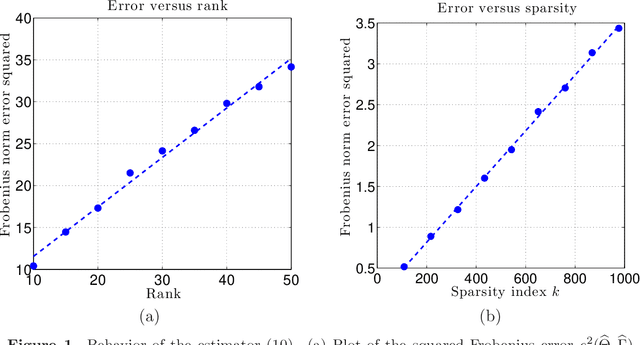
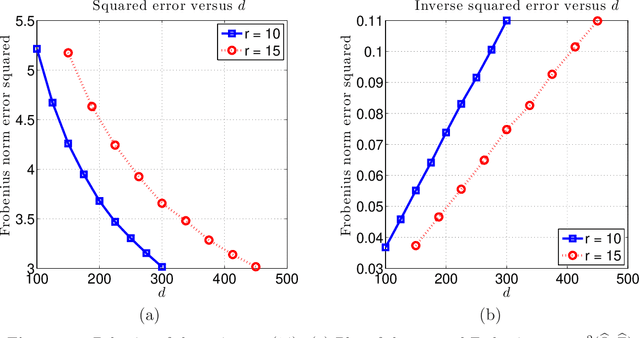
We analyze a class of estimators based on convex relaxation for solving high-dimensional matrix decomposition problems. The observations are noisy realizations of a linear transformation $\mathfrak{X}$ of the sum of an approximately) low rank matrix $\Theta^\star$ with a second matrix $\Gamma^\star$ endowed with a complementary form of low-dimensional structure; this set-up includes many statistical models of interest, including factor analysis, multi-task regression, and robust covariance estimation. We derive a general theorem that bounds the Frobenius norm error for an estimate of the pair $(\Theta^\star, \Gamma^\star)$ obtained by solving a convex optimization problem that combines the nuclear norm with a general decomposable regularizer. Our results utilize a "spikiness" condition that is related to but milder than singular vector incoherence. We specialize our general result to two cases that have been studied in past work: low rank plus an entrywise sparse matrix, and low rank plus a columnwise sparse matrix. For both models, our theory yields non-asymptotic Frobenius error bounds for both deterministic and stochastic noise matrices, and applies to matrices $\Theta^\star$ that can be exactly or approximately low rank, and matrices $\Gamma^\star$ that can be exactly or approximately sparse. Moreover, for the case of stochastic noise matrices and the identity observation operator, we establish matching lower bounds on the minimax error. The sharpness of our predictions is confirmed by numerical simulations.
* 41 pages, 2 figures
Contextual Bandit Learning with Predictable Rewards
Mar 02, 2012Contextual bandit learning is a reinforcement learning problem where the learner repeatedly receives a set of features (context), takes an action and receives a reward based on the action and context. We consider this problem under a realizability assumption: there exists a function in a (known) function class, always capable of predicting the expected reward, given the action and context. Under this assumption, we show three things. We present a new algorithm---Regressor Elimination--- with a regret similar to the agnostic setting (i.e. in the absence of realizability assumption). We prove a new lower bound showing no algorithm can achieve superior performance in the worst case even with the realizability assumption. However, we do show that for any set of policies (mapping contexts to actions), there is a distribution over rewards (given context) such that our new algorithm has constant regret unlike the previous approaches.