 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Memory-Based Control for Human-Scale Bipedal Locomotion
Jun 03, 2020
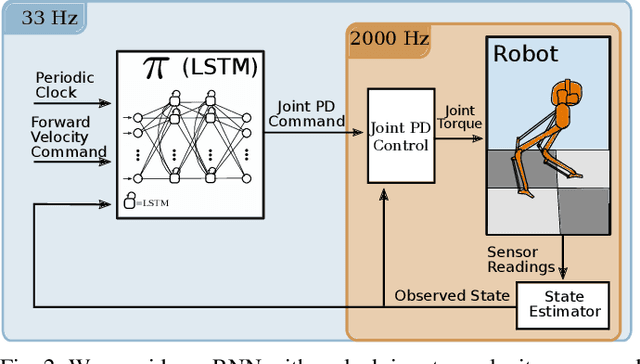
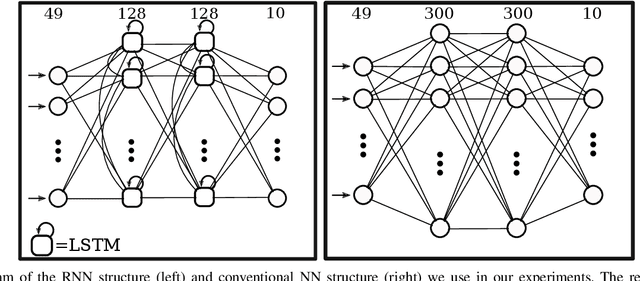

Controlling a non-statically stable biped is a difficult problem largely due to the complex hybrid dynamics involved. Recent work has demonstrated the effectiveness of reinforcement learning (RL) for simulation-based training of neural network controllers that successfully transfer to real bipeds. The existing work, however, has primarily used simple memoryless network architectures, even though more sophisticated architectures, such as those including memory, often yield superior performance in other RL domains. In this work, we consider recurrent neural networks (RNNs) for sim-to-real biped locomotion, allowing for policies that learn to use internal memory to model important physical properties. We show that while RNNs are able to significantly outperform memoryless policies in simulation, they do not exhibit superior behavior on the real biped due to overfitting to the simulation physics unless trained using dynamics randomization to prevent overfitting; this leads to consistently better sim-to-real transfer. We also show that RNNs could use their learned memory states to perform online system identification by encoding parameters of the dynamics into memory.
The Choice Function Framework for Online Policy Improvement
Oct 07, 2019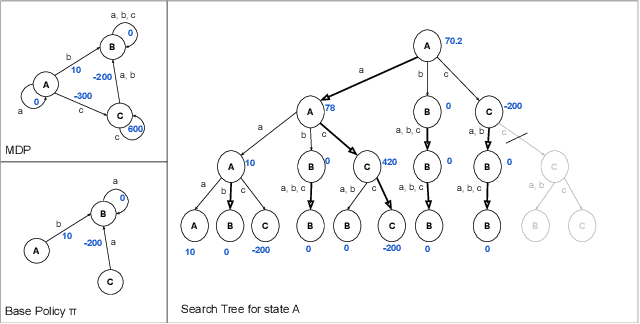
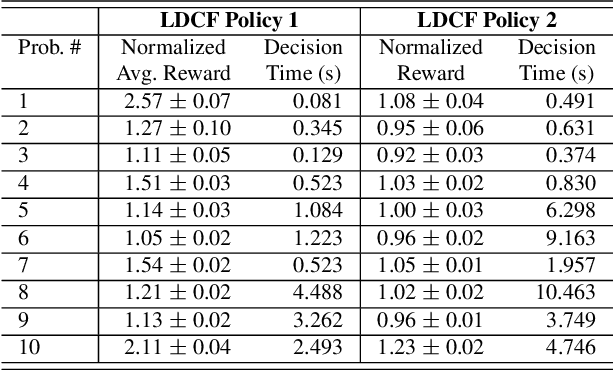
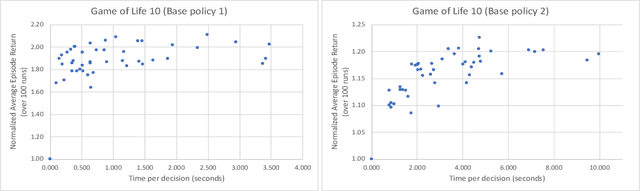
There are notable examples of online search improving over hand-coded or learned policies (e.g. AlphaZero) for sequential decision making. It is not clear, however, whether or not policy improvement is guaranteed for many of these approaches, even when given a perfect evaluation function and transition model. Indeed, simple counter examples show that seemingly reasonable online search procedures can hurt performance compared to the original policy. To address this issue, we introduce the choice function framework for analyzing online search procedures for policy improvement. A choice function specifies the actions to be considered at every node of a search tree, with all other actions being pruned. Our main contribution is to give sufficient conditions for stationary and non-stationary choice functions to guarantee that the value achieved by online search is no worse than the original policy. In addition, we describe a general parametric class of choice functions that satisfy those conditions and present an illustrative use case of the framework's empirical utility.
Explaining Reinforcement Learning to Mere Mortals: An Empirical Study
Mar 22, 2019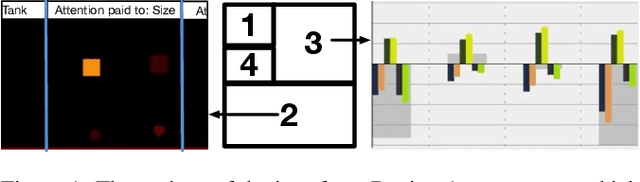
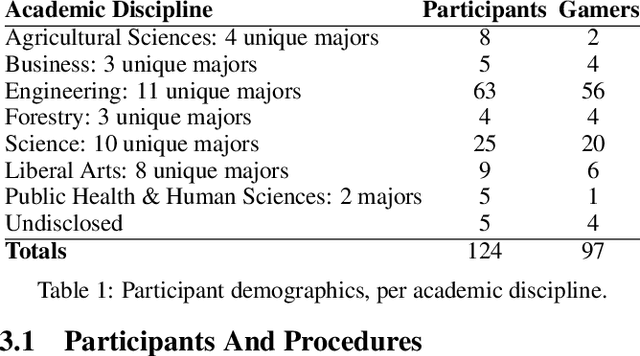
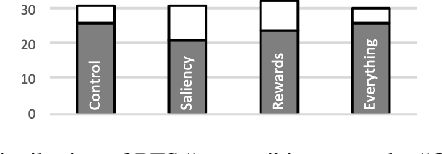
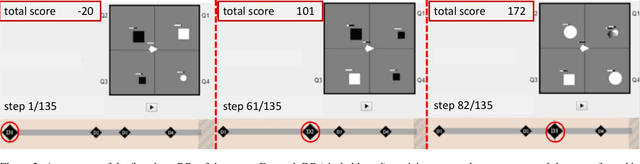
We present a user study to investigate the impact of explanations on non-experts' understanding of reinforcement learning (RL) agents. We investigate both a common RL visualization, saliency maps (the focus of attention), and a more recent explanation type, reward-decomposition bars (predictions of future types of rewards). We designed a 124 participant, four-treatment experiment to compare participants' mental models of an RL agent in a simple Real-Time Strategy (RTS) game. Our results show that the combination of both saliency and reward bars were needed to achieve a statistically significant improvement in mental model score over the control. In addition, our qualitative analysis of the data reveals a number of effects for further study.
Interactive Naming for Explaining Deep Neural Networks: A Formative Study
Dec 20, 2018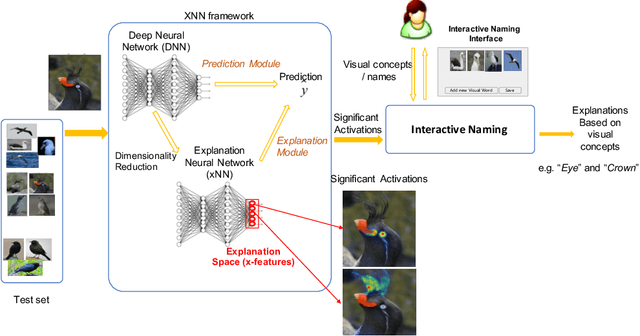
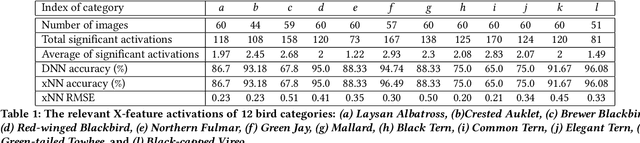
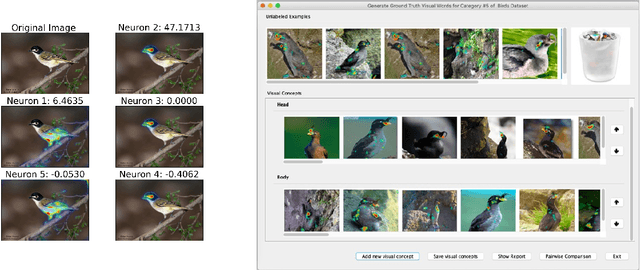
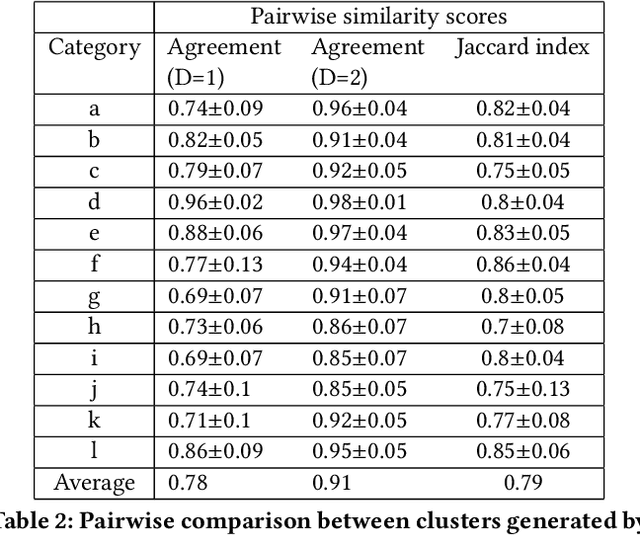
We consider the problem of explaining the decisions of deep neural networks for image recognition in terms of human-recognizable visual concepts. In particular, given a test set of images, we aim to explain each classification in terms of a small number of image regions, or activation maps, which have been associated with semantic concepts by a human annotator. This allows for generating summary views of the typical reasons for classifications, which can help build trust in a classifier and/or identify example types for which the classifier may not be trusted. For this purpose, we developed a user interface for "interactive naming," which allows a human annotator to manually cluster significant activation maps in a test set into meaningful groups called "visual concepts". The main contribution of this paper is a systematic study of the visual concepts produced by five human annotators using the interactive naming interface. In particular, we consider the adequacy of the concepts for explaining the classification of test-set images, correspondence of the concepts to activations of individual neurons, and the inter-annotator agreement of visual concepts. We find that a large fraction of the activation maps have recognizable visual concepts, and that there is significant agreement between the different annotators about their denotations. Our work is an exploratory study of the interplay between machine learning and human recognition mediated by visualizations of the results of learning.
Learning Finite State Representations of Recurrent Policy Networks
Nov 29, 2018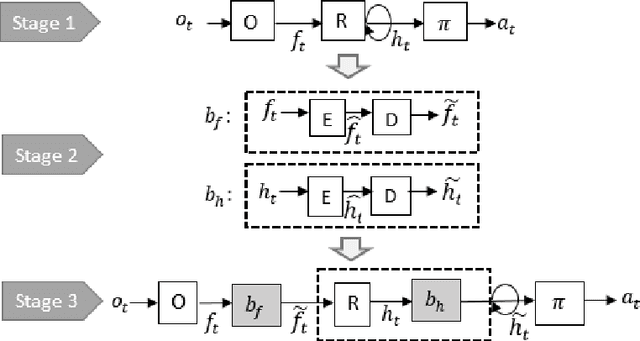



Recurrent neural networks (RNNs) are an effective representation of control policies for a wide range of reinforcement and imitation learning problems. RNN policies, however, are particularly difficult to explain, understand, and analyze due to their use of continuous-valued memory vectors and observation features. In this paper, we introduce a new technique, Quantized Bottleneck Insertion, to learn finite representations of these vectors and features. The result is a quantized representation of the RNN that can be analyzed to improve our understanding of memory use and general behavior. We present results of this approach on synthetic environments and six Atari games. The resulting finite representations are surprisingly small in some cases, using as few as 3 discrete memory states and 10 observations for a perfect Pong policy. We also show that these finite policy representations lead to improved interpretability.
Visualizing and Understanding Atari Agents
Sep 10, 2018
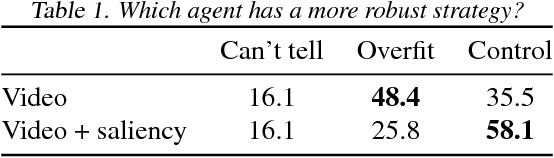
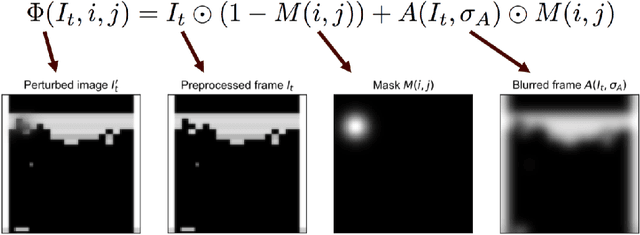

While deep reinforcement learning (deep RL) agents are effective at maximizing rewards, it is often unclear what strategies they use to do so. In this paper, we take a step toward explaining deep RL agents through a case study using Atari 2600 environments. In particular, we focus on using saliency maps to understand how an agent learns and executes a policy. We introduce a method for generating useful saliency maps and use it to show 1) what strong agents attend to, 2) whether agents are making decisions for the right or wrong reasons, and 3) how agents evolve during learning. We also test our method on non-expert human subjects and find that it improves their ability to reason about these agents. Overall, our results show that saliency information can provide significant insight into an RL agent's decisions and learning behavior.
Open Category Detection with PAC Guarantees
Aug 01, 2018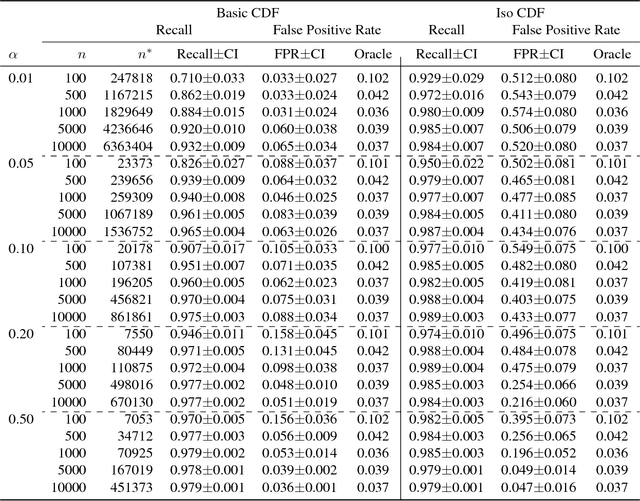
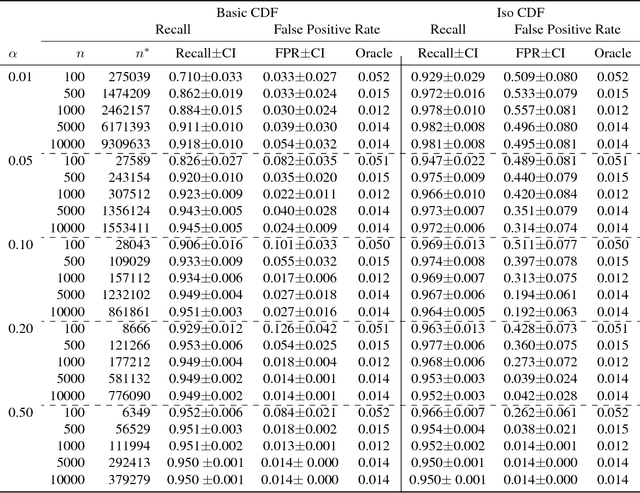
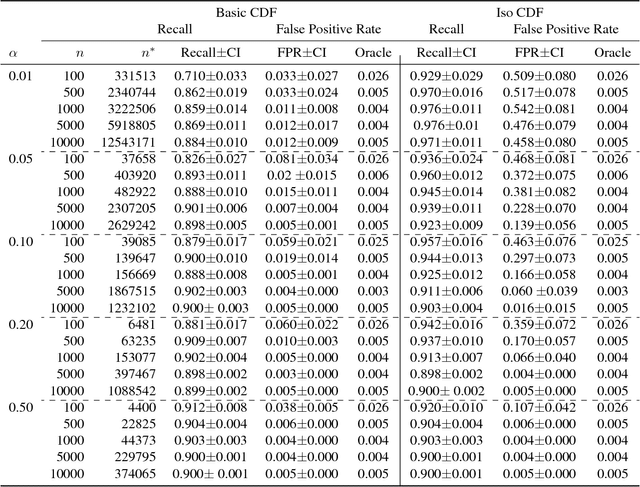
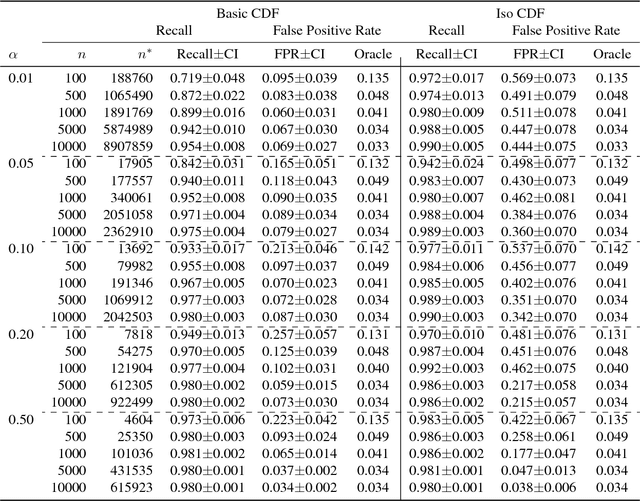
Open category detection is the problem of detecting "alien" test instances that belong to categories or classes that were not present in the training data. In many applications, reliably detecting such aliens is central to ensuring the safety and accuracy of test set predictions. Unfortunately, there are no algorithms that provide theoretical guarantees on their ability to detect aliens under general assumptions. Further, while there are algorithms for open category detection, there are few empirical results that directly report alien detection rates. Thus, there are significant theoretical and empirical gaps in our understanding of open category detection. In this paper, we take a step toward addressing this gap by studying a simple, but practically-relevant variant of open category detection. In our setting, we are provided with a "clean" training set that contains only the target categories of interest and an unlabeled "contaminated" training set that contains a fraction $\alpha$ of alien examples. Under the assumption that we know an upper bound on $\alpha$, we develop an algorithm with PAC-style guarantees on the alien detection rate, while aiming to minimize false alarms. Empirical results on synthetic and standard benchmark datasets demonstrate the regimes in which the algorithm can be effective and provide a baseline for further advancements.
Schema Independent Relational Learning
Nov 06, 2017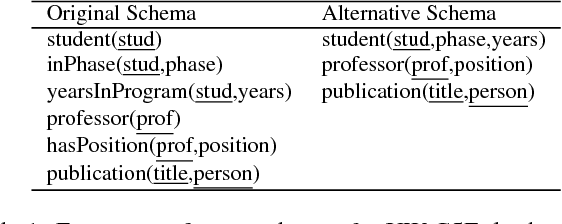
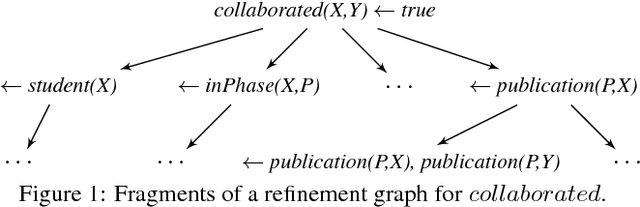

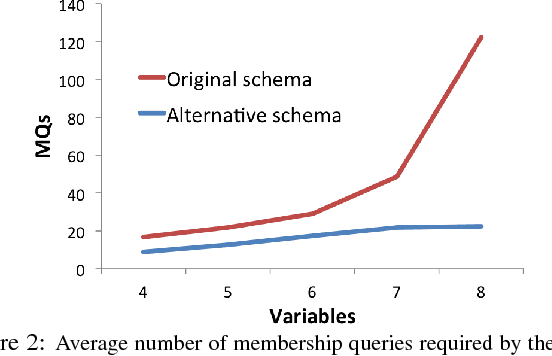
Learning novel concepts and relations from relational databases is an important problem with many applications in database systems and machine learning. Relational learning algorithms learn the definition of a new relation in terms of existing relations in the database. Nevertheless, the same data set may be represented under different schemas for various reasons, such as efficiency, data quality, and usability. Unfortunately, the output of current relational learning algorithms tends to vary quite substantially over the choice of schema, both in terms of learning accuracy and efficiency. This variation complicates their off-the-shelf application. In this paper, we introduce and formalize the property of schema independence of relational learning algorithms, and study both the theoretical and empirical dependence of existing algorithms on the common class of (de) composition schema transformations. We study both sample-based learning algorithms, which learn from sets of labeled examples, and query-based algorithms, which learn by asking queries to an oracle. We prove that current relational learning algorithms are generally not schema independent. For query-based learning algorithms we show that the (de) composition transformations influence their query complexity. We propose Castor, a sample-based relational learning algorithm that achieves schema independence by leveraging data dependencies. We support the theoretical results with an empirical study that demonstrates the schema dependence/independence of several algorithms on existing benchmark and real-world datasets under (de) compositions.
AutoMode: Relational Learning With Less Black Magic
Oct 03, 2017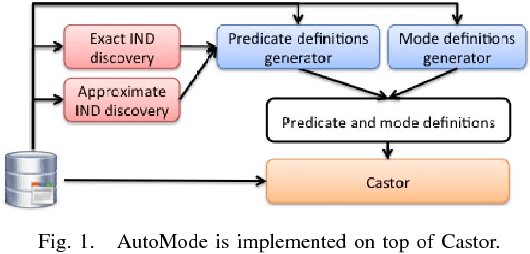
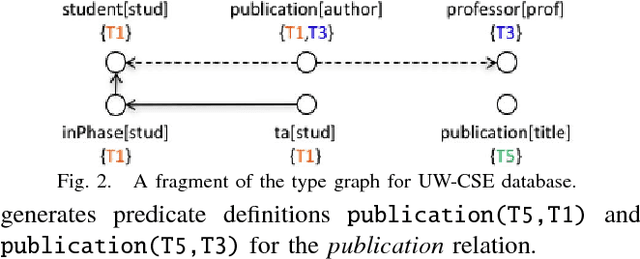

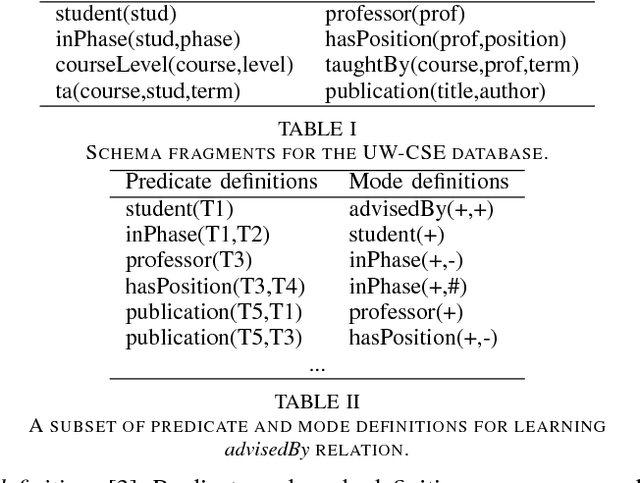
Relational databases are valuable resources for learning novel and interesting relations and concepts. Relational learning algorithms learn the Datalog definition of new relations in terms of the existing relations in the database. In order to constraint the search through the large space of candidate definitions, users must tune the algorithm by specifying a language bias. Unfortunately, specifying the language bias is done via trial and error and is guided by the expert's intuitions. Hence, it normally takes a great deal of time and effort to effectively use these algorithms. In particular, it is hard to find a user that knows computer science concepts, such as database schema, and has a reasonable intuition about the target relation in special domains, such as biology. We propose AutoMode, a system that leverages information in the schema and content of the database to automatically induce the language bias used by popular relational learning systems. We show that AutoMode delivers the same accuracy as using manually-written language bias by imposing only a slight overhead on the running time of the learning algorithm.
Incorporating Feedback into Tree-based Anomaly Detection
Aug 30, 2017
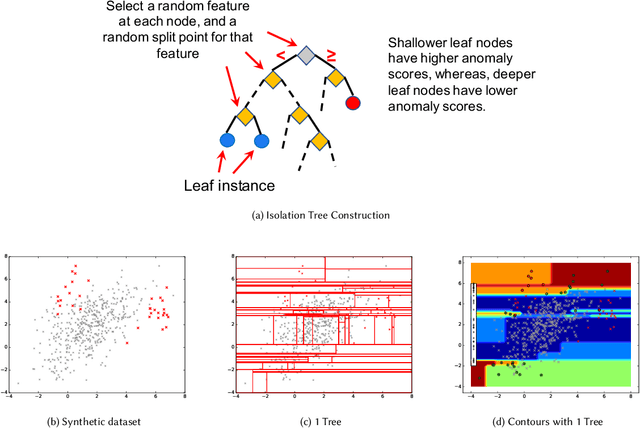
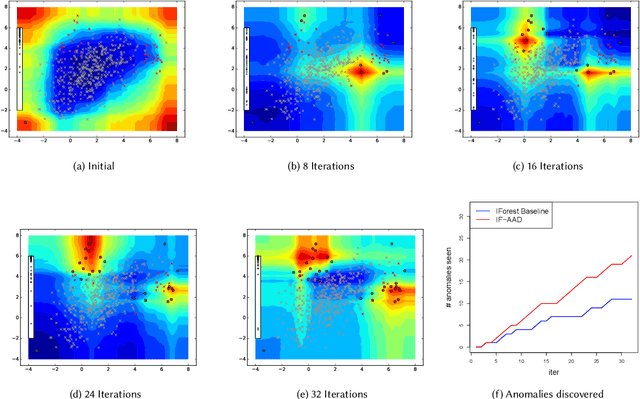
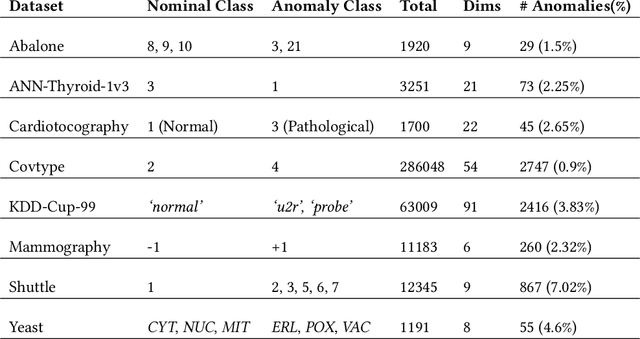
Anomaly detectors are often used to produce a ranked list of statistical anomalies, which are examined by human analysts in order to extract the actual anomalies of interest. Unfortunately, in realworld applications, this process can be exceedingly difficult for the analyst since a large fraction of high-ranking anomalies are false positives and not interesting from the application perspective. In this paper, we aim to make the analyst's job easier by allowing for analyst feedback during the investigation process. Ideally, the feedback influences the ranking of the anomaly detector in a way that reduces the number of false positives that must be examined before discovering the anomalies of interest. In particular, we introduce a novel technique for incorporating simple binary feedback into tree-based anomaly detectors. We focus on the Isolation Forest algorithm as a representative tree-based anomaly detector, and show that we can significantly improve its performance by incorporating feedback, when compared with the baseline algorithm that does not incorporate feedback. Our technique is simple and scales well as the size of the data increases, which makes it suitable for interactive discovery of anomalies in large datasets.