 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Transform To Compute Them All: Efficient Fusion-Based Full-Reference Video Quality Assessment
Apr 06, 2023The Visual Multimethod Assessment Fusion (VMAF) algorithm has recently emerged as a state-of-the-art approach to video quality prediction, that now pervades the streaming and social media industry. However, since VMAF requires the evaluation of a heterogeneous set of quality models, it is computationally expensive. Given other advances in hardware-accelerated encoding, quality assessment is emerging as a significant bottleneck in video compression pipelines. Towards alleviating this burden, we propose a novel Fusion of Unified Quality Evaluators (FUNQUE) framework, by enabling computation sharing and by using a transform that is sensitive to visual perception to boost accuracy. Further, we expand the FUNQUE framework to define a collection of improved low-complexity fused-feature models that advance the state-of-the-art of video quality performance with respect to both accuracy and computational efficiency.
Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild
Apr 02, 2023



Automatic Perceptual Image Quality Assessment is a challenging problem that impacts billions of internet, and social media users daily. To advance research in this field, we propose a Mixture of Experts approach to train two separate encoders to learn high-level content and low-level image quality features in an unsupervised setting. The unique novelty of our approach is its ability to generate low-level representations of image quality that are complementary to high-level features representing image content. We refer to the framework used to train the two encoders as Re-IQA. For Image Quality Assessment in the Wild, we deploy the complementary low and high-level image representations obtained from the Re-IQA framework to train a linear regression model, which is used to map the image representations to the ground truth quality scores, refer Figure 1. Our method achieves state-of-the-art performance on multiple large-scale image quality assessment databases containing both real and synthetic distortions, demonstrating how deep neural networks can be trained in an unsupervised setting to produce perceptually relevant representations. We conclude from our experiments that the low and high-level features obtained are indeed complementary and positively impact the performance of the linear regressor. A public release of all the codes associated with this work will be made available on GitHub.
Subjective Assessment of High Dynamic Range Videos Under Different Ambient Conditions
Sep 20, 2022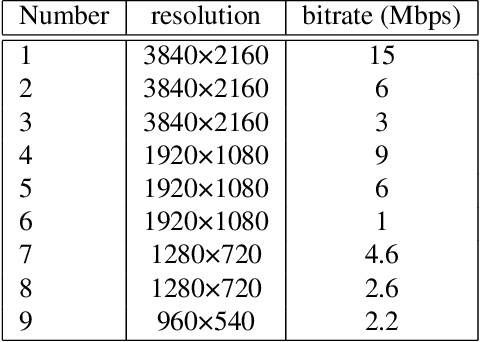

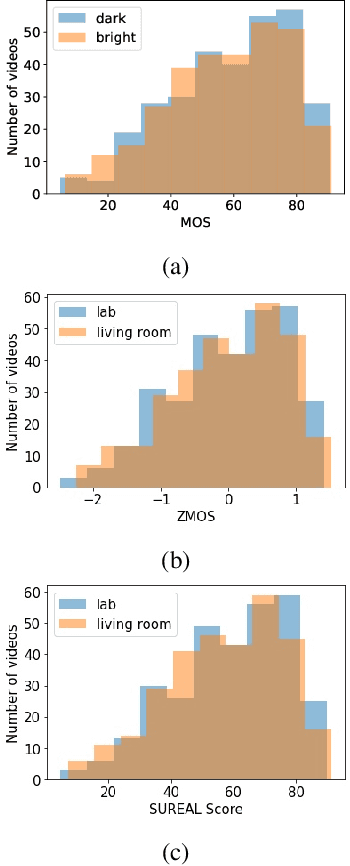
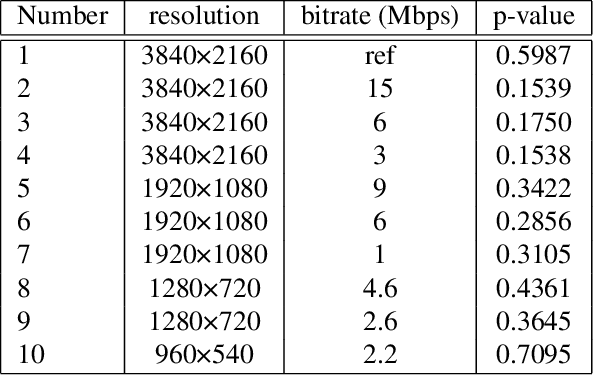
High Dynamic Range (HDR) videos can represent a much greater range of brightness and color than Standard Dynamic Range (SDR) videos and are rapidly becoming an industry standard. HDR videos have more challenging capture, transmission, and display requirements than legacy SDR videos. With their greater bit depth, advanced electro-optical transfer functions, and wider color gamuts, comes the need for video quality algorithms that are specifically designed to predict the quality of HDR videos. Towards this end, we present the first publicly released large-scale subjective study of HDR videos. We study the effect of distortions such as compression and aliasing on the quality of HDR videos. We also study the effect of ambient illumination on perceptual quality of HDR videos by conducting the study in both a dark lab environment and a brighter living-room environment. A total of 66 subjects participated in the study and more than 20,000 opinion scores were collected, which makes this the largest in-lab study of HDR video quality ever. We anticipate that the dataset will be a valuable resource for researchers to develop better models of perceptual quality for HDR videos.
CONVIQT: Contrastive Video Quality Estimator
Jun 29, 2022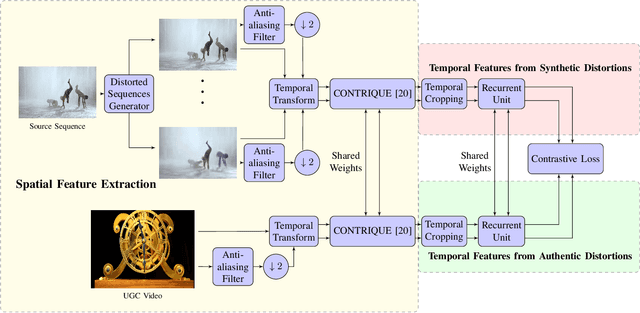


Perceptual video quality assessment (VQA) is an integral component of many streaming and video sharing platforms. Here we consider the problem of learning perceptually relevant video quality representations in a self-supervised manner. Distortion type identification and degradation level determination is employed as an auxiliary task to train a deep learning model containing a deep Convolutional Neural Network (CNN) that extracts spatial features, as well as a recurrent unit that captures temporal information. The model is trained using a contrastive loss and we therefore refer to this training framework and resulting model as CONtrastive VIdeo Quality EstimaTor (CONVIQT). During testing, the weights of the trained model are frozen, and a linear regressor maps the learned features to quality scores in a no-reference (NR) setting. We conduct comprehensive evaluations of the proposed model on multiple VQA databases by analyzing the correlations between model predictions and ground-truth quality ratings, and achieve competitive performance when compared to state-of-the-art NR-VQA models, even though it is not trained on those databases. Our ablation experiments demonstrate that the learned representations are highly robust and generalize well across synthetic and realistic distortions. Our results indicate that compelling representations with perceptual bearing can be obtained using self-supervised learning. The implementations used in this work have been made available at https://github.com/pavancm/CONVIQT.
Efficient Per-Shot Convex Hull Prediction By Recurrent Learning
Jun 10, 2022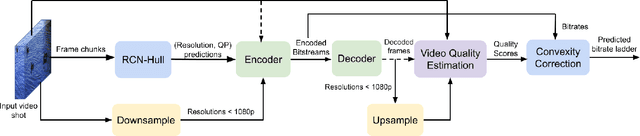
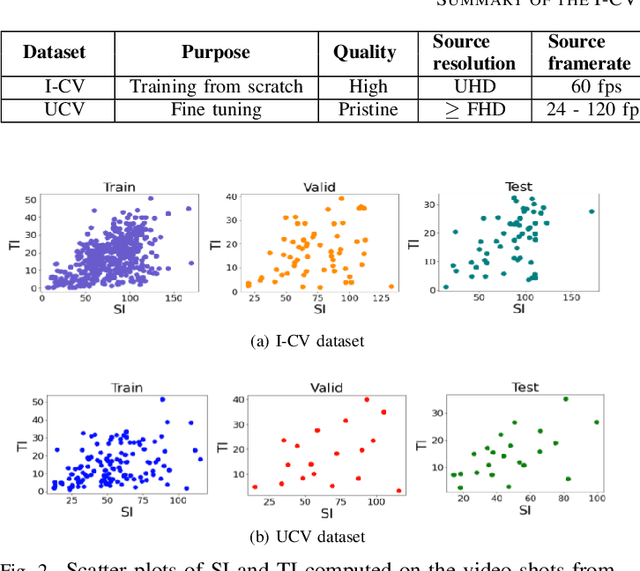
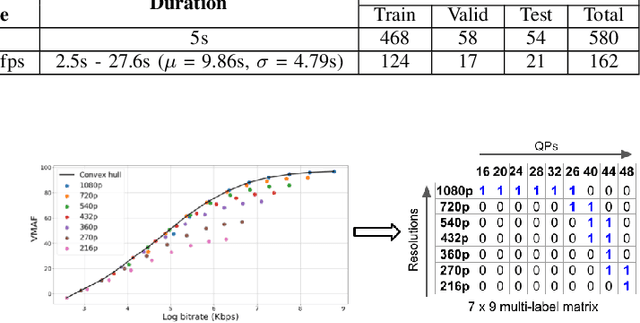
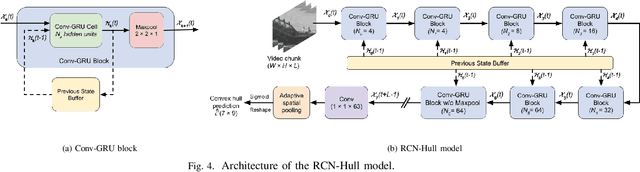
Adaptive video streaming relies on the construction of efficient bitrate ladders to deliver the best possible visual quality to viewers under bandwidth constraints. The traditional method of content dependent bitrate ladder selection requires a video shot to be pre-encoded with multiple encoding parameters to find the optimal operating points given by the convex hull of the resulting rate-quality curves. However, this pre-encoding step is equivalent to an exhaustive search process over the space of possible encoding parameters, which causes significant overhead in terms of both computation and time expenditure. To reduce this overhead, we propose a deep learning based method of content aware convex hull prediction. We employ a recurrent convolutional network (RCN) to implicitly analyze the spatiotemporal complexity of video shots in order to predict their convex hulls. A two-step transfer learning scheme is adopted to train our proposed RCN-Hull model, which ensures sufficient content diversity to analyze scene complexity, while also making it possible capture the scene statistics of pristine source videos. Our experimental results reveal that our proposed model yields better approximations of the optimal convex hulls, and offers competitive time savings as compared to existing approaches. On average, the pre-encoding time was reduced by 58.0% by our method, while the average Bjontegaard delta bitrate (BD-rate) of the predicted convex hulls against ground truth was 0.08%, while the mean absolute deviation of the BD-rate distribution was 0.44%
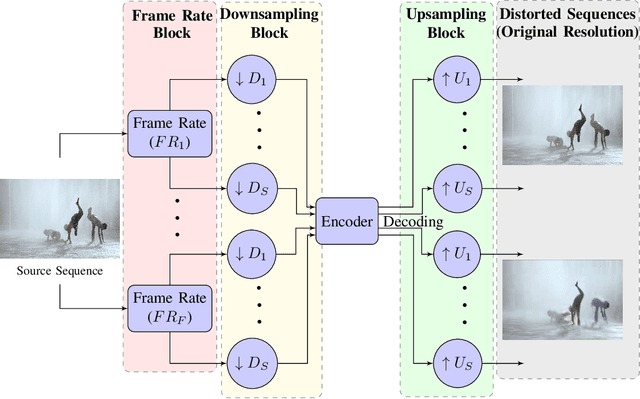
Making Video Quality Assessment Models Sensitive to Frame Rate Distortions
May 21, 2022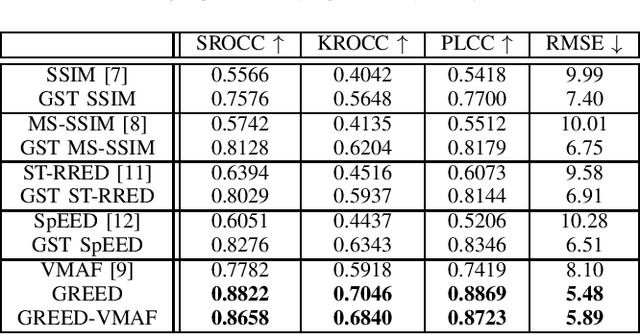
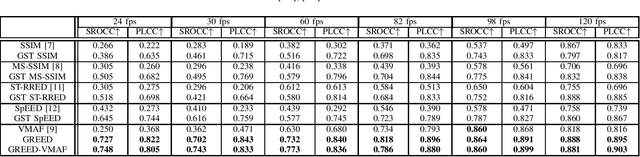
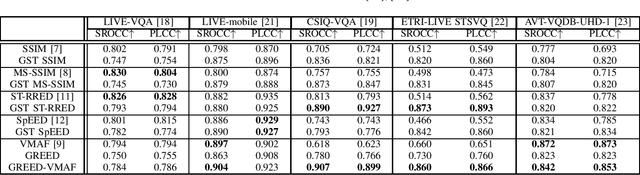
We consider the problem of capturing distortions arising from changes in frame rate as part of Video Quality Assessment (VQA). Variable frame rate (VFR) videos have become much more common, and streamed videos commonly range from 30 frames per second (fps) up to 120 fps. VFR-VQA offers unique challenges in terms of distortion types as well as in making non-uniform comparisons of reference and distorted videos having different frame rates. The majority of current VQA models require compared videos to be of the same frame rate, but are unable to adequately account for frame rate artifacts. The recently proposed Generalized Entropic Difference (GREED) VQA model succeeds at this task, using natural video statistics models of entropic differences of temporal band-pass coefficients, delivering superior performance on predicting video quality changes arising from frame rate distortions. Here we propose a simple fusion framework, whereby temporal features from GREED are combined with existing VQA models, towards improving model sensitivity towards frame rate distortions. We find through extensive experiments that this feature fusion significantly boosts model performance on both HFR/VFR datasets as well as fixed frame rate (FFR) VQA databases. Our results suggest that employing efficient temporal representations can result much more robust and accurate VQA models when frame rate variations can occur.
Estimating the Resize Parameter in End-to-end Learned Image Compression
Apr 26, 2022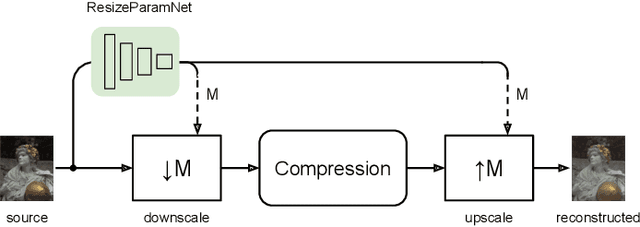
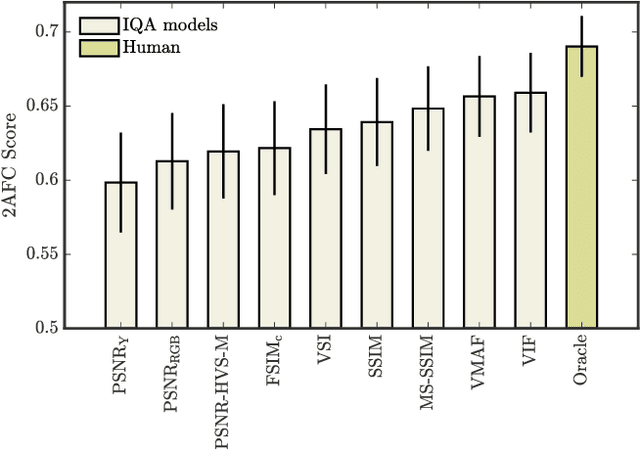
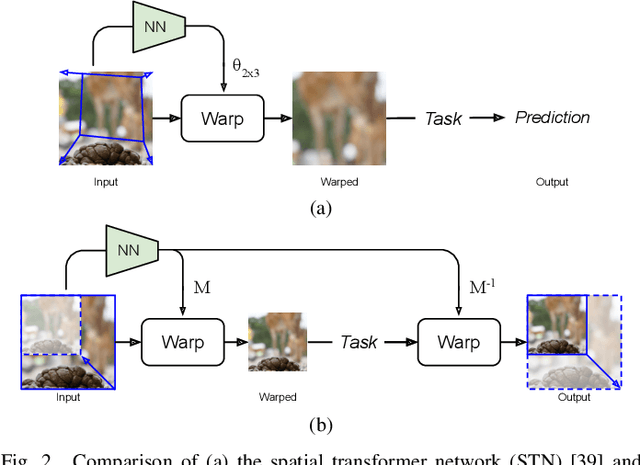
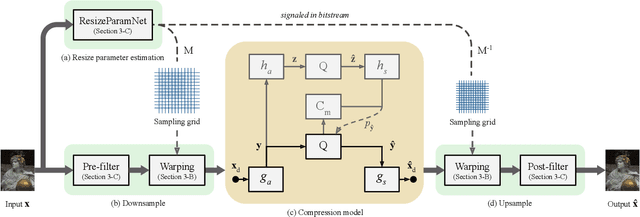
We describe a search-free resizing framework that can further improve the rate-distortion tradeoff of recent learned image compression models. Our approach is simple: compose a pair of differentiable downsampling/upsampling layers that sandwich a neural compression model. To determine resize factors for different inputs, we utilize another neural network jointly trained with the compression model, with the end goal of minimizing the rate-distortion objective. Our results suggest that "compression friendly" downsampled representations can be quickly determined during encoding by using an auxiliary network and differentiable image warping. By conducting extensive experimental tests on existing deep image compression models, we show results that our new resizing parameter estimation framework can provide Bj{\o}ntegaard-Delta rate (BD-rate) improvement of about 10% against leading perceptual quality engines. We also carried out a subjective quality study, the results of which show that our new approach yields favorable compressed images. To facilitate reproducible research in this direction, the implementation used in this paper is being made freely available online at: https://github.com/treammm/ResizeCompression.
Perceptual Quality Assessment of UGC Gaming Videos
Apr 13, 2022
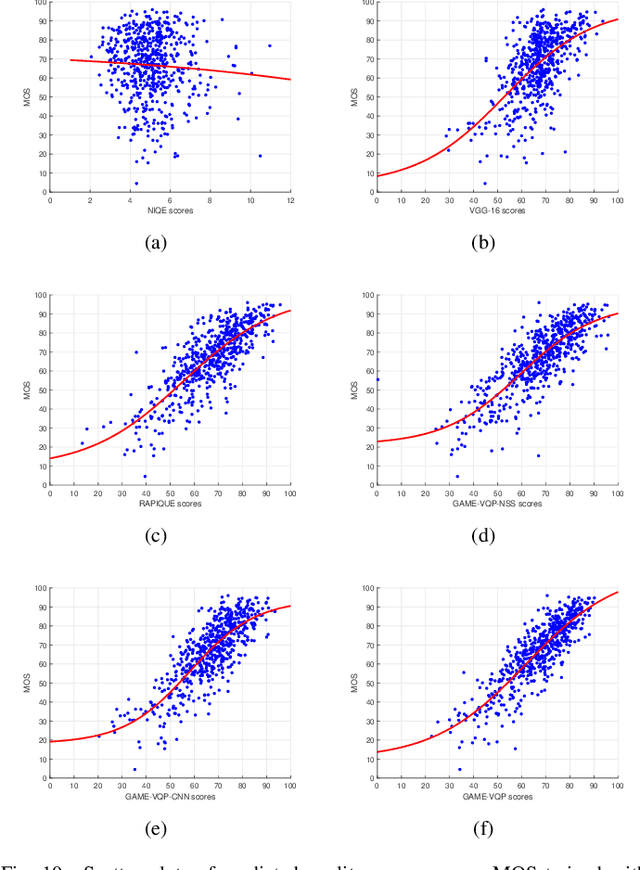
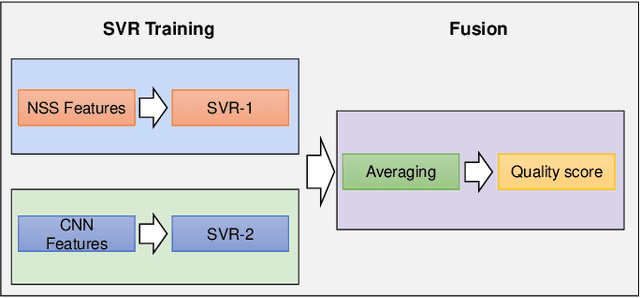
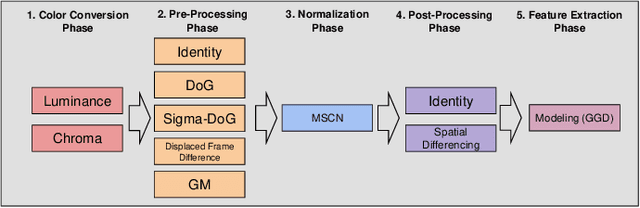
In recent years, with the vigorous development of the video game industry, the proportion of gaming videos on major video websites like YouTube has dramatically increased. However, relatively little research has been done on the automatic quality prediction of gaming videos, especially on those that fall in the category of "User-Generated-Content" (UGC). Since current leading general-purpose Video Quality Assessment (VQA) models do not perform well on this type of gaming videos, we have created a new VQA model specifically designed to succeed on UGC gaming videos, which we call the Gaming Video Quality Predictor (GAME-VQP). GAME-VQP successfully predicts the unique statistical characteristics of gaming videos by drawing upon features designed under modified natural scene statistics models, combined with gaming specific features learned by a Convolution Neural Network. We study the performance of GAME-VQP on a very recent large UGC gaming video database called LIVE-YT-Gaming, and find that it both outperforms other mainstream general VQA models as well as VQA models specifically designed for gaming videos. The new model will be made public after paper being accepted.
Foveation-based Deep Video Compression without Motion Search
Mar 30, 2022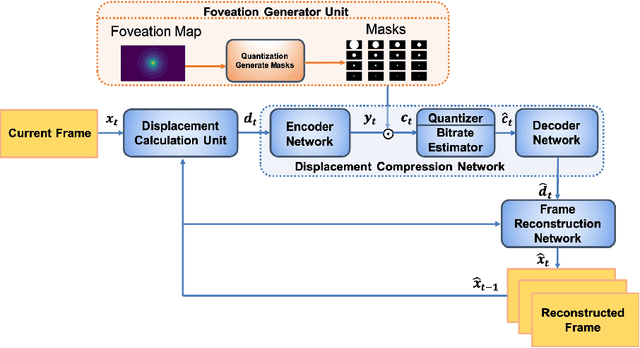

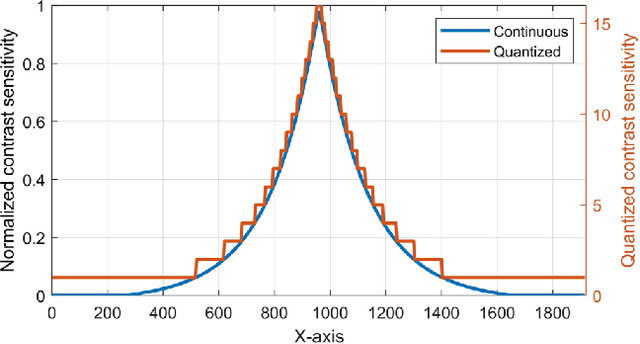
The requirements of much larger file sizes, different storage formats, and immersive viewing conditions of VR pose significant challenges to the goals of acquiring, transmitting, compressing, and displaying high-quality VR content. At the same time, the great potential of deep learning to advance progress on the video compression problem has driven a significant research effort. Because of the high bandwidth requirements of VR, there has also been significant interest in the use of space-variant, foveated compression protocols. We have integrated these techniques to create an end-to-end deep learning video compression framework. A feature of our new compression model is that it dispenses with the need for expensive search-based motion prediction computations. This is accomplished by exploiting statistical regularities inherent in video motion expressed by displaced frame differences. Foveation protocols are desirable since only a small portion of a video viewed in VR may be visible as a user gazes in any given direction. Moreover, even within a current field of view (FOV), the resolution of retinal neurons rapidly decreases with distance (eccentricity) from the projected point of gaze. In our learning based approach, we implement foveation by introducing a Foveation Generator Unit (FGU) that generates foveation masks which direct the allocation of bits, significantly increasing compression efficiency while making it possible to retain an impression of little to no additional visual loss given an appropriate viewing geometry. Our experiment results reveal that our new compression model, which we call the Foveated MOtionless VIdeo Codec (Foveated MOVI-Codec), is able to efficiently compress videos without computing motion, while outperforming foveated version of both H.264 and H.265 on the widely used UVG dataset and on the HEVC Standard Class B Test Sequences.
Subjective and Objective Analysis of Streamed Gaming Videos
Mar 24, 2022
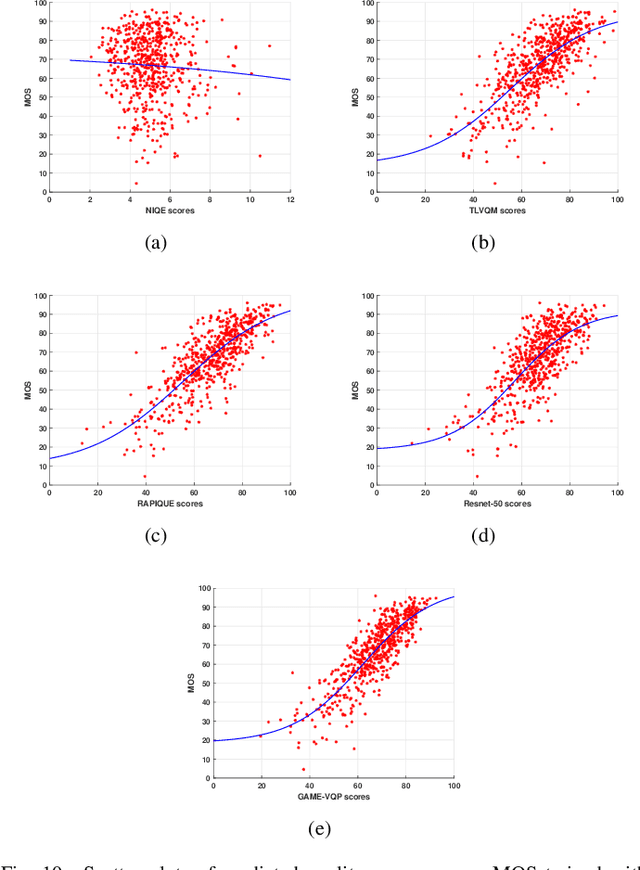
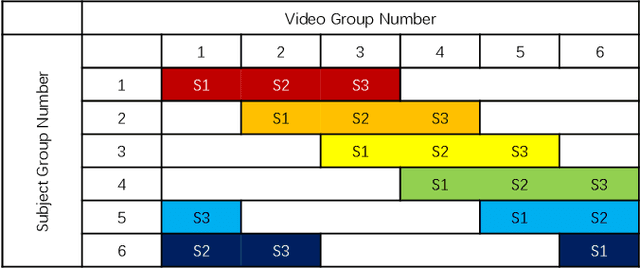
The rising popularity of online User-Generated-Content (UGC) in the form of streamed and shared videos, has hastened the development of perceptual Video Quality Assessment (VQA) models, which can be used to help optimize their delivery. Gaming videos, which are a relatively new type of UGC videos, are created when skilled gamers post videos of their gameplay. These kinds of screenshots of UGC gameplay videos have become extremely popular on major streaming platforms like YouTube and Twitch. Synthetically-generated gaming content presents challenges to existing VQA algorithms, including those based on natural scene/video statistics models. Synthetically generated gaming content presents different statistical behavior than naturalistic videos. A number of studies have been directed towards understanding the perceptual characteristics of professionally generated gaming videos arising in gaming video streaming, online gaming, and cloud gaming. However, little work has been done on understanding the quality of UGC gaming videos, and how it can be characterized and predicted. Towards boosting the progress of gaming video VQA model development, we conducted a comprehensive study of subjective and objective VQA models on UGC gaming videos. To do this, we created a novel UGC gaming video resource, called the LIVE-YouTube Gaming video quality (LIVE-YT-Gaming) database, comprised of 600 real UGC gaming videos. We conducted a subjective human study on this data, yielding 18,600 human quality ratings recorded by 61 human subjects. We also evaluated a number of state-of-the-art (SOTA) VQA models on the new database, including a new one, called GAME-VQP, based on both natural video statistics and CNN-learned features. To help support work in this field, we are making the new LIVE-YT-Gaming Database, publicly available through the link: https://live.ece.utexas.edu/research/LIVE-YT-Gaming/index.html .