 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Test-Time Guidance Is Enough: Fast Image and Video Editing with Diffusion Guidance
Feb 15, 2026Text-driven image and video editing can be naturally cast as inpainting problems, where masked regions are reconstructed to remain consistent with both the observed content and the editing prompt. Recent advances in test-time guidance for diffusion and flow models provide a principled framework for this task; however, existing methods rely on costly vector--Jacobian product (VJP) computations to approximate the intractable guidance term, limiting their practical applicability. Building upon the recent work of Moufad et al. (2025), we provide theoretical insights into their VJP-free approximation and substantially extend their empirical evaluation to large-scale image and video editing benchmarks. Our results demonstrate that test-time guidance alone can achieve performance comparable to, and in some cases surpass, training-based methods.
Efficient Zero-Shot Inpainting with Decoupled Diffusion Guidance
Dec 20, 2025Diffusion models have emerged as powerful priors for image editing tasks such as inpainting and local modification, where the objective is to generate realistic content that remains consistent with observed regions. In particular, zero-shot approaches that leverage a pretrained diffusion model, without any retraining, have been shown to achieve highly effective reconstructions. However, state-of-the-art zero-shot methods typically rely on a sequence of surrogate likelihood functions, whose scores are used as proxies for the ideal score. This procedure however requires vector-Jacobian products through the denoiser at every reverse step, introducing significant memory and runtime overhead. To address this issue, we propose a new likelihood surrogate that yields simple and efficient to sample Gaussian posterior transitions, sidestepping the backpropagation through the denoiser network. Our extensive experiments show that our method achieves strong observation consistency compared with fine-tuned baselines and produces coherent, high-quality reconstructions, all while significantly reducing inference cost. Code is available at https://github.com/YazidJanati/ding.
Conditional Diffusion Models with Classifier-Free Gibbs-like Guidance
May 27, 2025Classifier-Free Guidance (CFG) is a widely used technique for improving conditional diffusion models by linearly combining the outputs of conditional and unconditional denoisers. While CFG enhances visual quality and improves alignment with prompts, it often reduces sample diversity, leading to a challenging trade-off between quality and diversity. To address this issue, we make two key contributions. First, CFG generally does not correspond to a well-defined denoising diffusion model (DDM). In particular, contrary to common intuition, CFG does not yield samples from the target distribution associated with the limiting CFG score as the noise level approaches zero -- where the data distribution is tilted by a power $w \gt 1$ of the conditional distribution. We identify the missing component: a R\'enyi divergence term that acts as a repulsive force and is required to correct CFG and render it consistent with a proper DDM. Our analysis shows that this correction term vanishes in the low-noise limit. Second, motivated by this insight, we propose a Gibbs-like sampling procedure to draw samples from the desired tilted distribution. This method starts with an initial sample from the conditional diffusion model without CFG and iteratively refines it, preserving diversity while progressively enhancing sample quality. We evaluate our approach on both image and text-to-audio generation tasks, demonstrating substantial improvements over CFG across all considered metrics. The code is available at https://github.com/yazidjanati/cfgig
A Mixture-Based Framework for Guiding Diffusion Models
Feb 05, 2025Denoising diffusion models have driven significant progress in the field of Bayesian inverse problems. Recent approaches use pre-trained diffusion models as priors to solve a wide range of such problems, only leveraging inference-time compute and thereby eliminating the need to retrain task-specific models on the same dataset. To approximate the posterior of a Bayesian inverse problem, a diffusion model samples from a sequence of intermediate posterior distributions, each with an intractable likelihood function. This work proposes a novel mixture approximation of these intermediate distributions. Since direct gradient-based sampling of these mixtures is infeasible due to intractable terms, we propose a practical method based on Gibbs sampling. We validate our approach through extensive experiments on image inverse problems, utilizing both pixel- and latent-space diffusion priors, as well as on source separation with an audio diffusion model. The code is available at https://www.github.com/badr-moufad/mgdm
Variational Diffusion Posterior Sampling with Midpoint Guidance
Oct 13, 2024



Diffusion models have recently shown considerable potential in solving Bayesian inverse problems when used as priors. However, sampling from the resulting denoising posterior distributions remains a challenge as it involves intractable terms. To tackle this issue, state-of-the-art approaches formulate the problem as that of sampling from a surrogate diffusion model targeting the posterior and decompose its scores into two terms: the prior score and an intractable guidance term. While the former is replaced by the pre-trained score of the considered diffusion model, the guidance term has to be estimated. In this paper, we propose a novel approach that utilises a decomposition of the transitions which, in contrast to previous methods, allows a trade-off between the complexity of the intractable guidance term and that of the prior transitions. We validate the proposed approach through extensive experiments on linear and nonlinear inverse problems, including challenging cases with latent diffusion models as priors, and demonstrate its effectiveness in reconstructing electrocardiogram (ECG) from partial measurements for accurate cardiac diagnosis.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022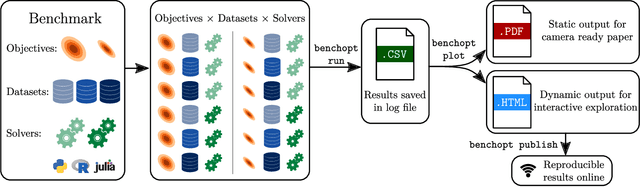
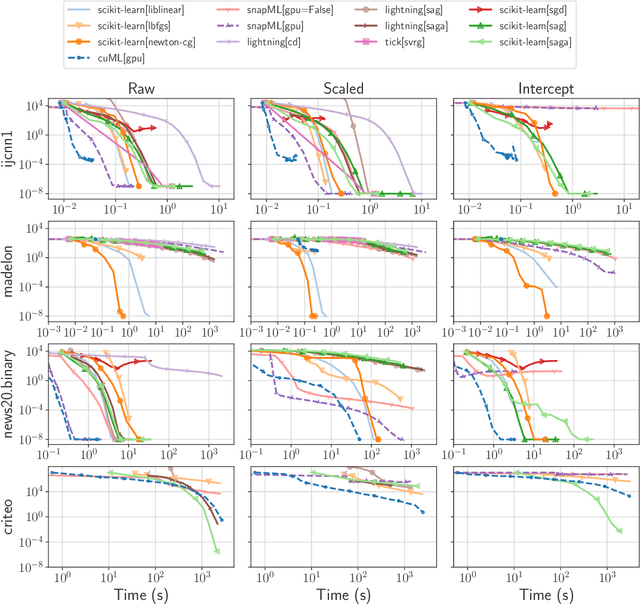
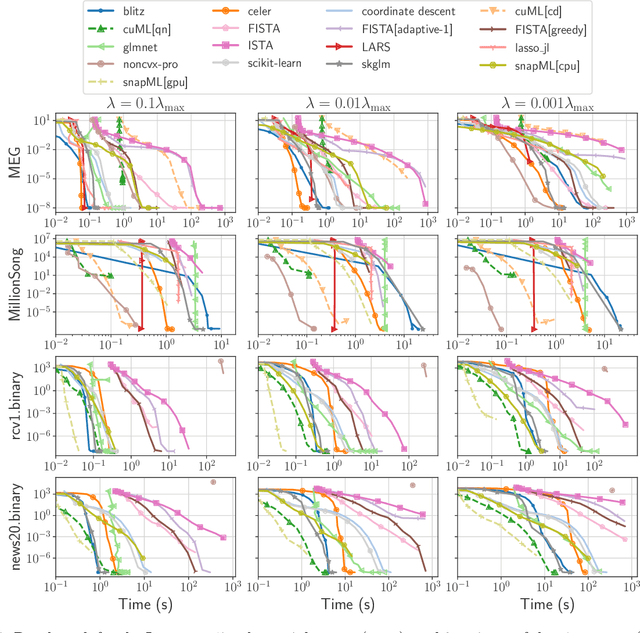
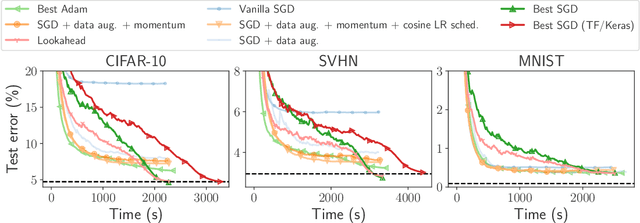
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.