 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust parametric modeling of Alzheimer's disease progression
Aug 14, 2019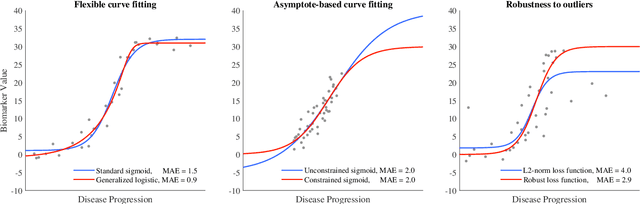
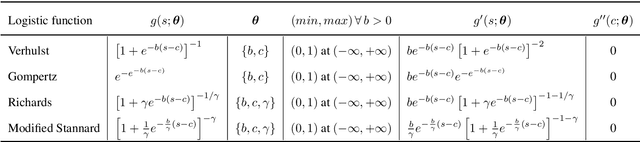

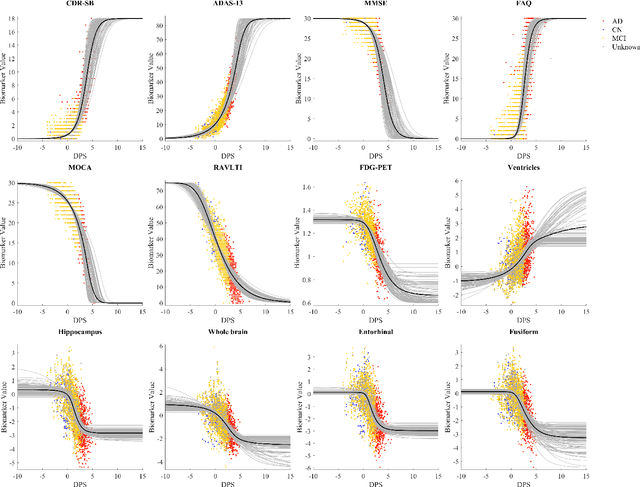
Quantitative characterization of disease progression using longitudinal data can provide long-term predictions for the pathological stages of individuals. This work studies robust modeling of Alzheimer's disease progression using parametric methods. The proposed method linearly maps individual's chronological age to a disease progression score (DPS) and robustly fits a constrained generalized logistic function to the longitudinal dynamic of a biomarker as a function of the DPS using M-estimation. Robustness of the estimates is quantified using bootstrapping via Monte Carlo resampling, and the inflection points are used to temporally order the modeled biomarkers in the disease course. Moreover, kernel density estimation is applied to the obtained DPSs for clinical status prediction using a Bayesian classifier. Different M-estimators and logistic functions, including a new generalized type proposed in this study called modified Stannard, are evaluated on the ADNI database for robust modeling of volumetric MRI and PET biomarkers, as well as neuropsychological tests. The results show that the modified Stannard function fitted using the modified Huber loss achieves the best modeling performance with a mean of median absolute errors (MMAE) of 0.059 across all biomarkers and bootstraps. In addition, applied to the ADNI test set, this model achieves a multi-class area under the ROC curve (MAUC) of 0.87 in clinical status prediction, and it significantly outperforms an analogous state-of-the-art method with a biomarker modeling MMAE of 0.059 vs. 0.061 (p < 0.001). Finally, the experiments show that the proposed model, trained using abundant ADNI data, generalizes well to data from the independent NACC database, where both modeling and diagnostic performance are significantly improved (p < 0.001) compared with using a model trained using relatively sparse NACC data.
Training recurrent neural networks robust to incomplete data: application to Alzheimer's disease progression modeling
Mar 17, 2019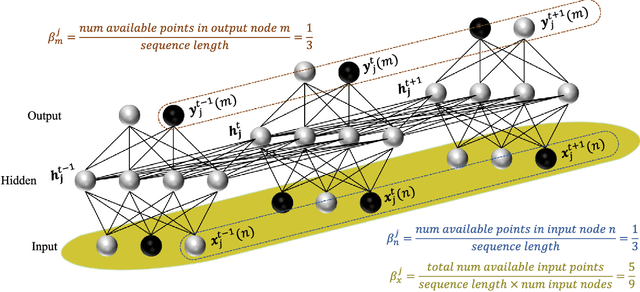
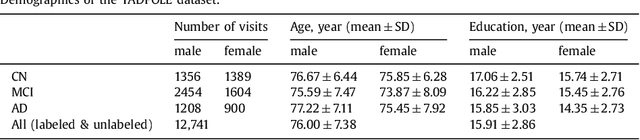
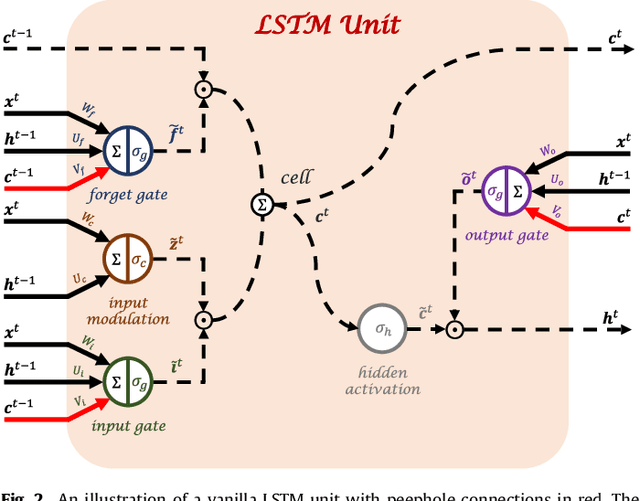
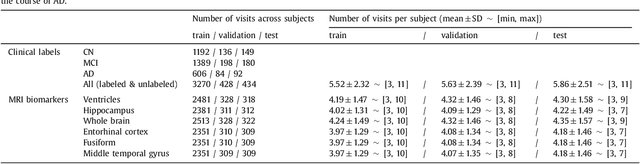
Disease progression modeling (DPM) using longitudinal data is a challenging machine learning task. Existing DPM algorithms neglect temporal dependencies among measurements, make parametric assumptions about biomarker trajectories, do not model multiple biomarkers jointly, and need an alignment of subjects' trajectories. In this paper, recurrent neural networks (RNNs) are utilized to address these issues. However, in many cases, longitudinal cohorts contain incomplete data, which hinders the application of standard RNNs and requires a pre-processing step such as imputation of the missing values. Instead, we propose a generalized training rule for the most widely used RNN architecture, long short-term memory (LSTM) networks, that can handle both missing predictor and target values. The proposed LSTM algorithm is applied to model the progression of Alzheimer's disease (AD) using six volumetric magnetic resonance imaging (MRI) biomarkers, i.e., volumes of ventricles, hippocampus, whole brain, fusiform, middle temporal gyrus, and entorhinal cortex, and it is compared to standard LSTM networks with data imputation and a parametric, regression-based DPM method. The results show that the proposed algorithm achieves a significantly lower mean absolute error (MAE) than the alternatives with p < 0.05 using Wilcoxon signed rank test in predicting values of almost all of the MRI biomarkers. Moreover, a linear discriminant analysis (LDA) classifier applied to the predicted biomarker values produces a significantly larger AUC of 0.90 vs. at most 0.84 with p < 0.001 using McNemar's test for clinical diagnosis of AD. Inspection of MAE curves as a function of the amount of missing data reveals that the proposed LSTM algorithm achieves the best performance up until more than 74% missing values. Finally, it is illustrated how the method can successfully be applied to data with varying time intervals.
* arXiv admin note: substantial text overlap with arXiv:1808.05500
PADDIT: Probabilistic Augmentation of Data using Diffeomorphic Image Transformation
Oct 03, 2018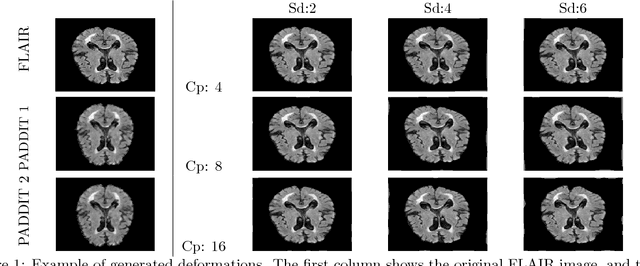
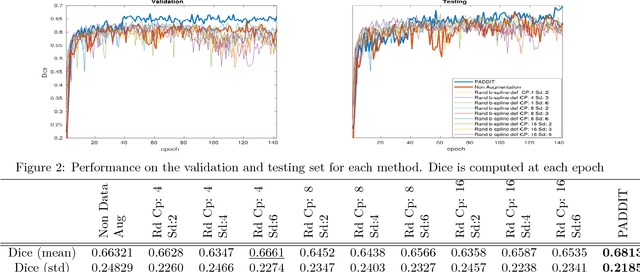
For proper generalization performance of convolutional neural networks (CNNs) in medical image segmentation, the learnt features should be invariant under particular non-linear shape variations of the input. To induce invariance in CNNs to such transformations, we propose Probabilistic Augmentation of Data using Diffeomorphic Image Transformation (PADDIT) -- a systematic framework for generating realistic transformations that can be used to augment data for training CNNs. We show that CNNs trained with PADDIT outperforms CNNs trained without augmentation and with generic augmentation in segmenting white matter hyperintensities from T1 and FLAIR brain MRI scans.
Simultaneous synthesis of FLAIR and segmentation of white matter hypointensities from T1 MRIs
Aug 20, 2018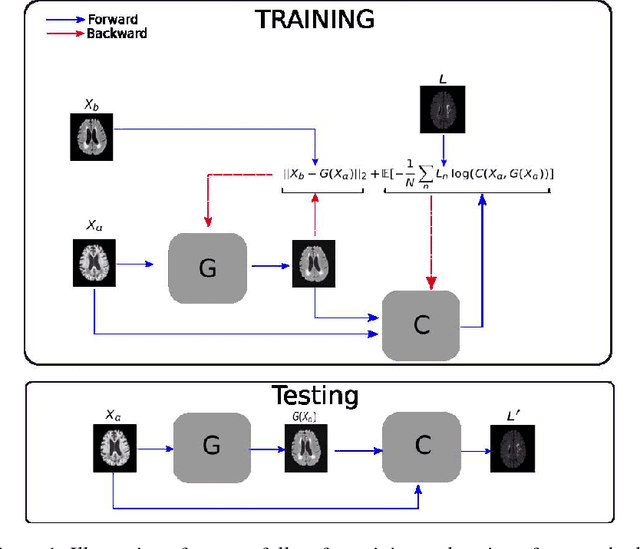
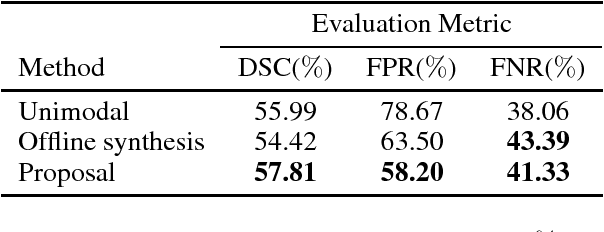
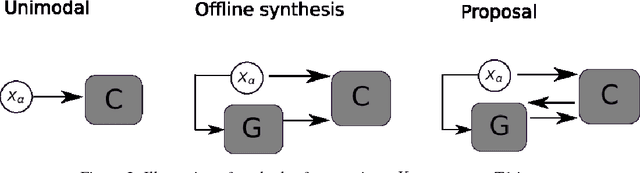
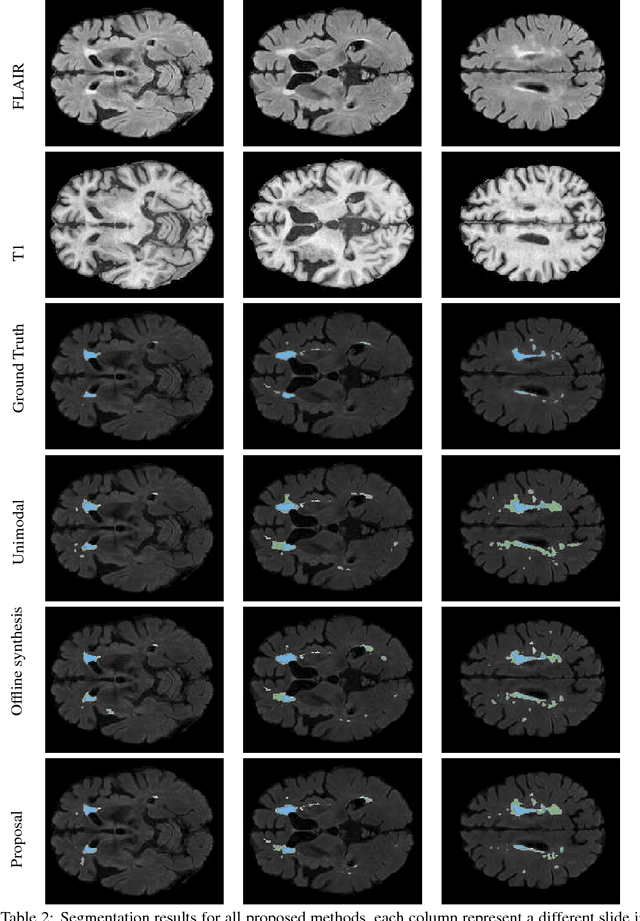
Segmenting vascular pathologies such as white matter lesions in Brain magnetic resonance images (MRIs) require acquisition of multiple sequences such as T1-weighted (T1-w) --on which lesions appear hypointense-- and fluid attenuated inversion recovery (FLAIR) sequence --where lesions appear hyperintense--. However, most of the existing retrospective datasets do not consist of FLAIR sequences. Existing missing modality imputation methods separate the process of imputation, and the process of segmentation. In this paper, we propose a method to link both modality imputation and segmentation using convolutional neural networks. We show that by jointly optimizing the imputation network and the segmentation network, the method not only produces more realistic synthetic FLAIR images from T1-w images, but also improves the segmentation of WMH from T1-w images only.
Robust training of recurrent neural networks to handle missing data for disease progression modeling
Aug 16, 2018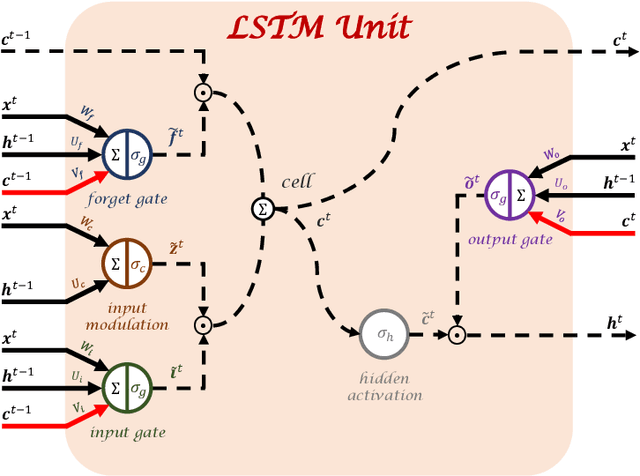



Disease progression modeling (DPM) using longitudinal data is a challenging task in machine learning for healthcare that can provide clinicians with better tools for diagnosis and monitoring of disease. Existing DPM algorithms neglect temporal dependencies among measurements and make parametric assumptions about biomarker trajectories. In addition, they do not model multiple biomarkers jointly and need to align subjects' trajectories. In this paper, recurrent neural networks (RNNs) are utilized to address these issues. However, in many cases, longitudinal cohorts contain incomplete data, which hinders the application of standard RNNs and requires a pre-processing step such as imputation of the missing values. We, therefore, propose a generalized training rule for the most widely used RNN architecture, long short-term memory (LSTM) networks, that can handle missing values in both target and predictor variables. This algorithm is applied for modeling the progression of Alzheimer's disease (AD) using magnetic resonance imaging (MRI) biomarkers. The results show that the proposed LSTM algorithm achieves a lower mean absolute error for prediction of measurements across all considered MRI biomarkers compared to using standard LSTM networks with data imputation or using a regression-based DPM method. Moreover, applying linear discriminant analysis to the biomarkers' values predicted by the proposed algorithm results in a larger area under the receiver operating characteristic curve (AUC) for clinical diagnosis of AD compared to the same alternatives, and the AUC is comparable to state-of-the-art AUCs from a recent cross-sectional medical image classification challenge. This paper shows that built-in handling of missing values in LSTM network training paves the way for application of RNNs in disease progression modeling.
Boundary Optimizing Network (BON)
Jan 23, 2018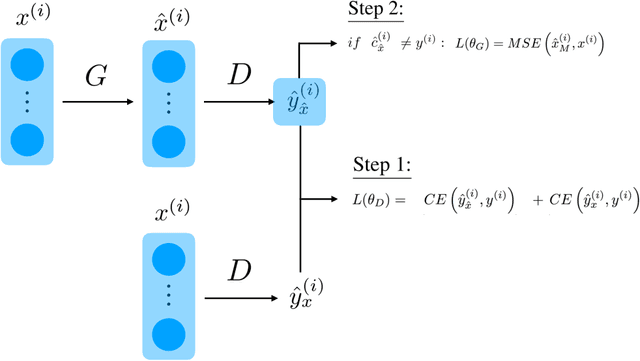
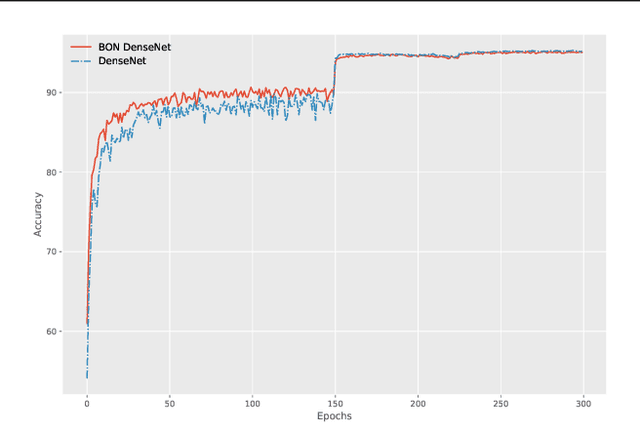
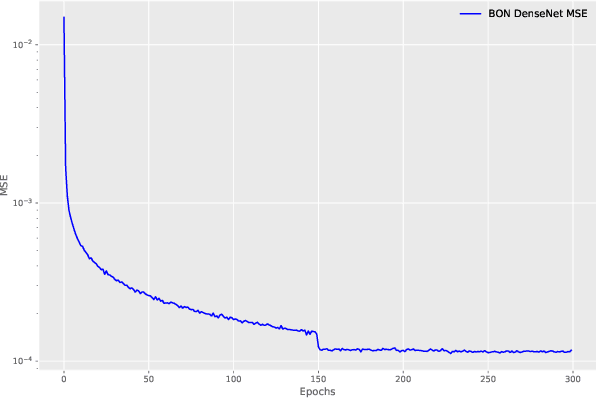
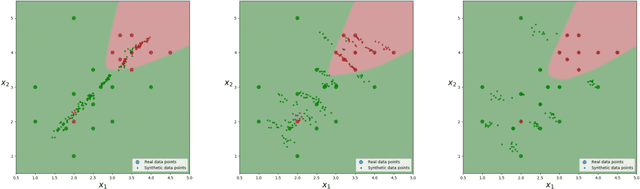
Despite all the success that deep neural networks have seen in classifying certain datasets, the challenge of finding optimal solutions that generalize still remains. In this paper, we propose the Boundary Optimizing Network (BON), a new approach to generalization for deep neural networks when used for supervised learning. Given a classification network, we propose to use a collaborative generative network that produces new synthetic data points in the form of perturbations of original data points. In this way, we create a data support around each original data point which prevents decision boundaries from passing too close to the original data points, i.e. prevents overfitting. We show that BON improves convergence on CIFAR-10 using the state-of-the-art Densenet. We do however observe that the generative network suffers from catastrophic forgetting during training, and we therefore propose to use a variation of Memory Aware Synapses to optimize the generative network (called BON++). On the Iris dataset, we visualize the effect of BON++ when the generator does not suffer from catastrophic forgetting and conclude that the approach has the potential to create better boundaries in a higher dimensional space.
Deep-Learnt Classification of Light Curves
Sep 19, 2017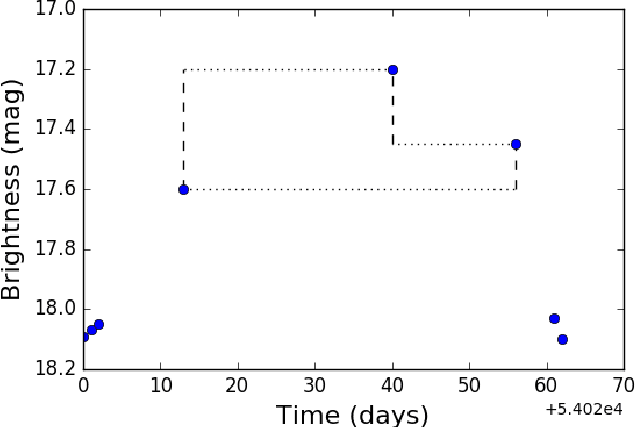
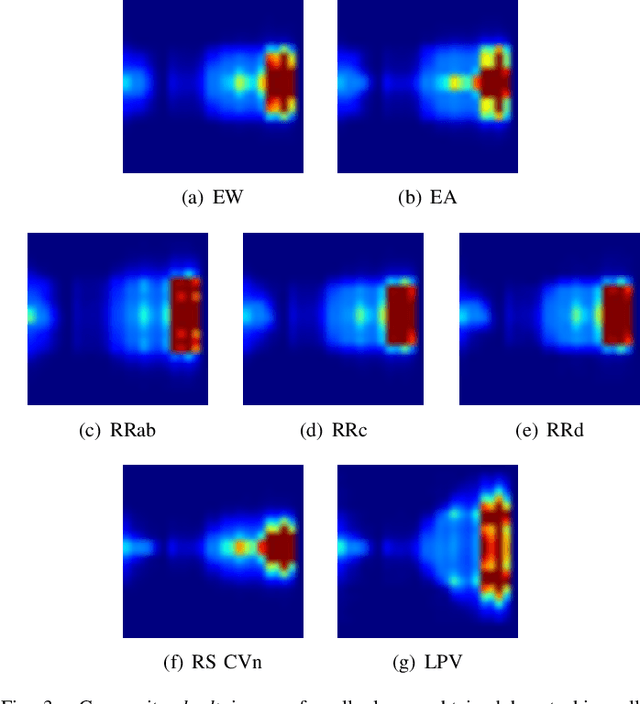
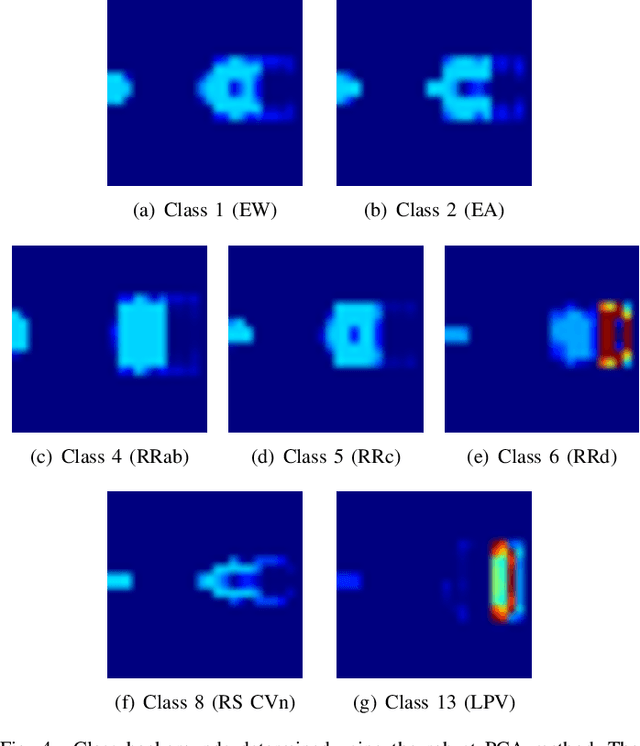
Astronomy light curves are sparse, gappy, and heteroscedastic. As a result standard time series methods regularly used for financial and similar datasets are of little help and astronomers are usually left to their own instruments and techniques to classify light curves. A common approach is to derive statistical features from the time series and to use machine learning methods, generally supervised, to separate objects into a few of the standard classes. In this work, we transform the time series to two-dimensional light curve representations in order to classify them using modern deep learning techniques. In particular, we show that convolutional neural networks based classifiers work well for broad characterization and classification. We use labeled datasets of periodic variables from CRTS survey and show how this opens doors for a quick classification of diverse classes with several possible exciting extensions.
* 8 pages, 9 figures, 6 tables, 2 listings. Accepted to 2017 IEEE Symposium Series on Computational Intelligence (SSCI)
A Statistical Model for Simultaneous Template Estimation, Bias Correction, and Registration of 3D Brain Images
May 01, 2017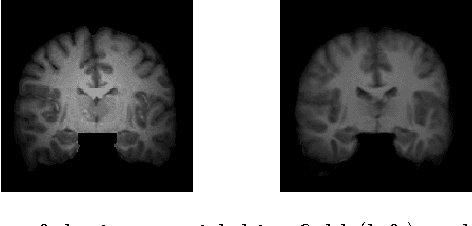
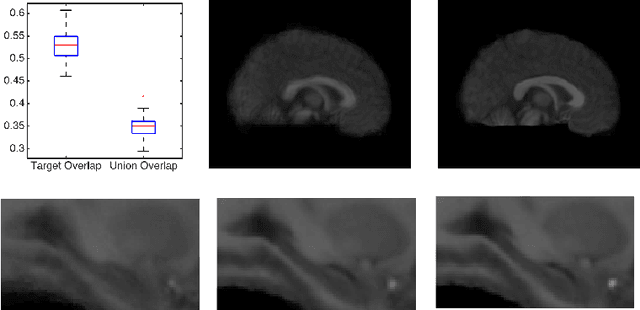
Template estimation plays a crucial role in computational anatomy since it provides reference frames for performing statistical analysis of the underlying anatomical population variability. While building models for template estimation, variability in sites and image acquisition protocols need to be accounted for. To account for such variability, we propose a generative template estimation model that makes simultaneous inference of both bias fields in individual images, deformations for image registration, and variance hyperparameters. In contrast, existing maximum a posterori based methods need to rely on either bias-invariant similarity measures or robust image normalization. Results on synthetic and real brain MRI images demonstrate the capability of the model to capture heterogeneity in intensities and provide a reliable template estimation from registration.
Most Likely Separation of Intensity and Warping Effects in Image Registration
Mar 15, 2017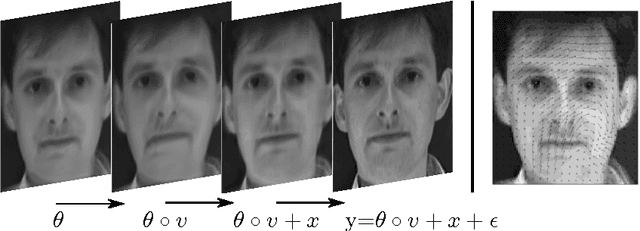
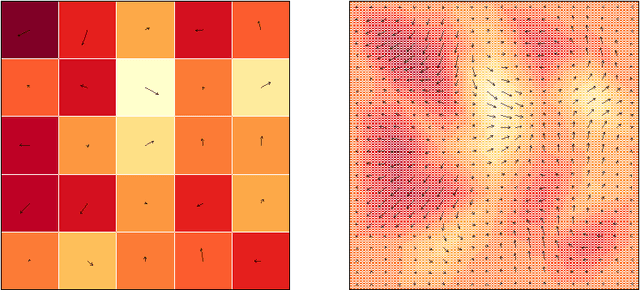
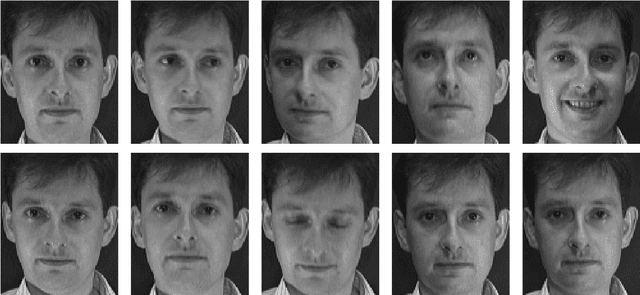

This paper introduces a class of mixed-effects models for joint modeling of spatially correlated intensity variation and warping variation in 2D images. Spatially correlated intensity variation and warp variation are modeled as random effects, resulting in a nonlinear mixed-effects model that enables simultaneous estimation of template and model parameters by optimization of the likelihood function. We propose an algorithm for fitting the model which alternates estimation of variance parameters and image registration. This approach avoids the potential estimation bias in the template estimate that arises when treating registration as a preprocessing step. We apply the model to datasets of facial images and 2D brain magnetic resonance images to illustrate the simultaneous estimation and prediction of intensity and warp effects.
A Stochastic Large Deformation Model for Computational Anatomy
Dec 16, 2016
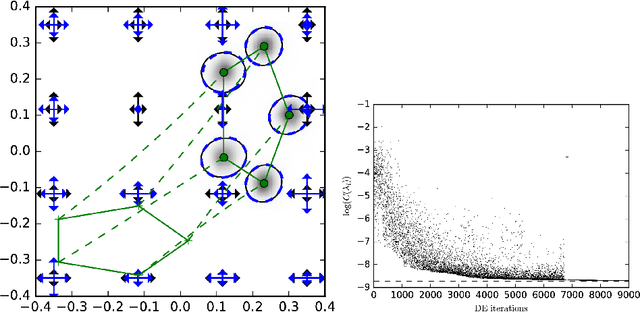

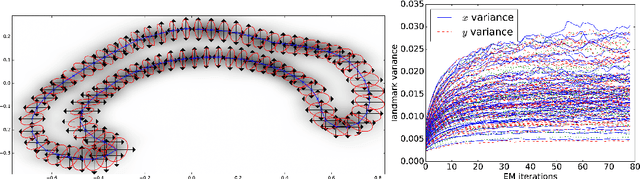
In the study of shapes of human organs using computational anatomy, variations are found to arise from inter-subject anatomical differences, disease-specific effects, and measurement noise. This paper introduces a stochastic model for incorporating random variations into the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework. By accounting for randomness in a particular setup which is crafted to fit the geometrical properties of LDDMM, we formulate the template estimation problem for landmarks with noise and give two methods for efficiently estimating the parameters of the noise fields from a prescribed data set. One method directly approximates the time evolution of the variance of each landmark by a finite set of differential equations, and the other is based on an Expectation-Maximisation algorithm. In the second method, the evaluation of the data likelihood is achieved without registering the landmarks, by applying bridge sampling using a stochastically perturbed version of the large deformation gradient flow algorithm. The method and the estimation algorithms are experimentally validated on synthetic examples and shape data of human corpora callosa.