 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Multi-Reference Learning for Image Super-Resolution
Aug 31, 2021
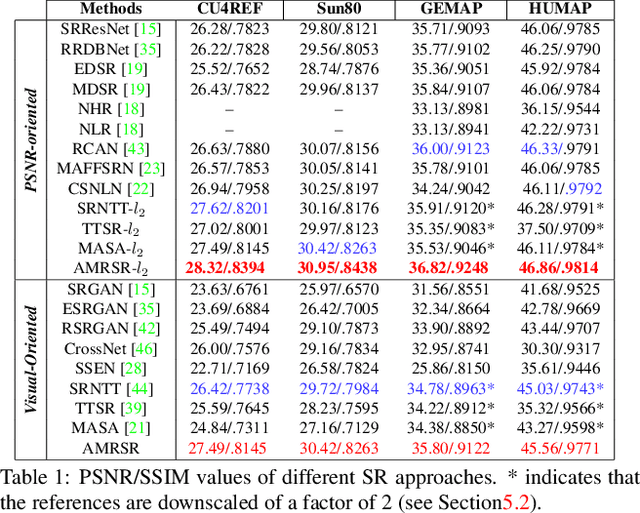
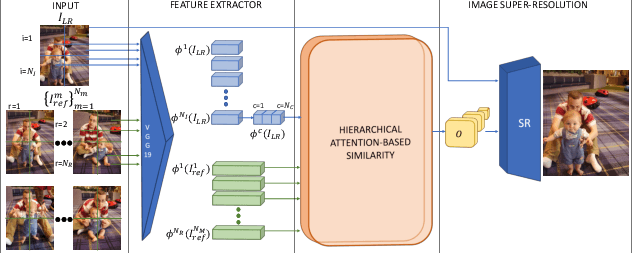
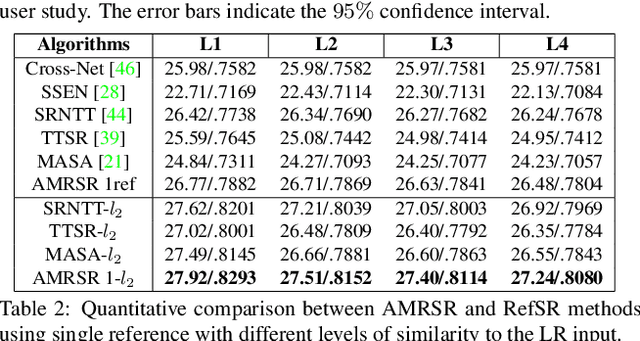
This paper proposes a novel Attention-based Multi-Reference Super-resolution network (AMRSR) that, given a low-resolution image, learns to adaptively transfer the most similar texture from multiple reference images to the super-resolution output whilst maintaining spatial coherence. The use of multiple reference images together with attention-based sampling is demonstrated to achieve significantly improved performance over state-of-the-art reference super-resolution approaches on multiple benchmark datasets. Reference super-resolution approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution reference image. Multi-reference super-resolution extends this approach by providing a more diverse pool of image features to overcome the inherent information deficit whilst maintaining memory efficiency. A novel hierarchical attention-based sampling approach is introduced to learn the similarity between low-resolution image features and multiple reference images based on a perceptual loss. Ablation demonstrates the contribution of both multi-reference and hierarchical attention-based sampling to overall performance. Perceptual and quantitative ground-truth evaluation demonstrates significant improvement in performance even when the reference images deviate significantly from the target image. The project website can be found at https://marcopesavento.github.io/AMRSR/
SyDog: A Synthetic Dog Dataset for Improved 2D Pose Estimation
Jul 31, 2021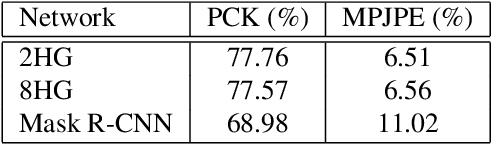
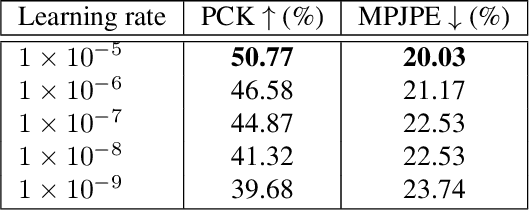

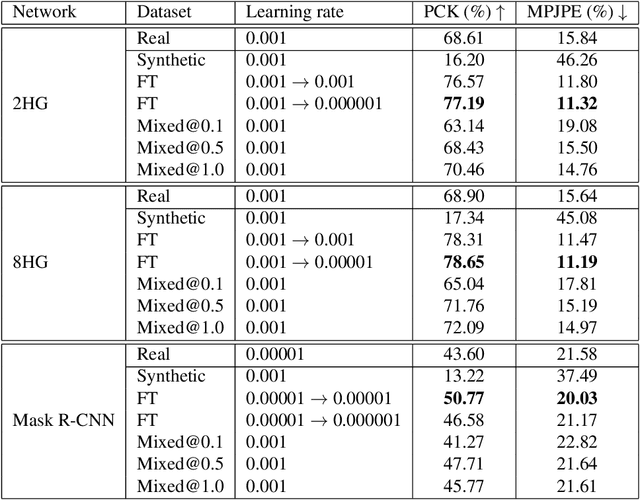
Estimating the pose of animals can facilitate the understanding of animal motion which is fundamental in disciplines such as biomechanics, neuroscience, ethology, robotics and the entertainment industry. Human pose estimation models have achieved high performance due to the huge amount of training data available. Achieving the same results for animal pose estimation is challenging due to the lack of animal pose datasets. To address this problem we introduce SyDog: a synthetic dataset of dogs containing ground truth pose and bounding box coordinates which was generated using the game engine, Unity. We demonstrate that pose estimation models trained on SyDog achieve better performance than models trained purely on real data and significantly reduce the need for the labour intensive labelling of images. We release the SyDog dataset as a training and evaluation benchmark for research in animal motion.
Multi-person Implicit Reconstruction from a Single Image
Apr 19, 2021
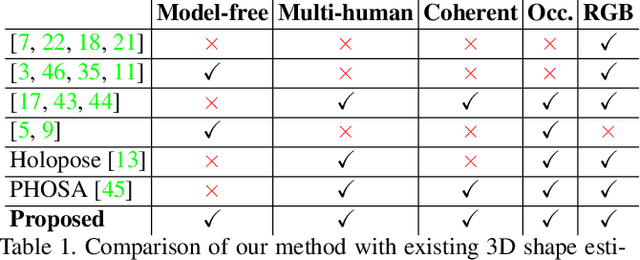
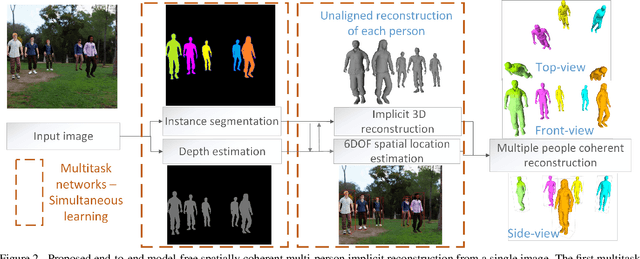
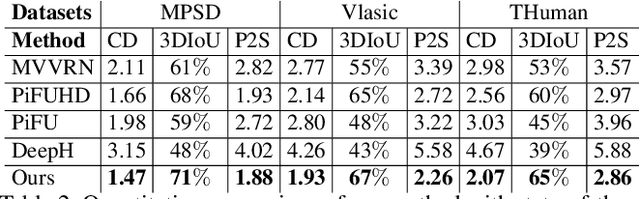
We present a new end-to-end learning framework to obtain detailed and spatially coherent reconstructions of multiple people from a single image. Existing multi-person methods suffer from two main drawbacks: they are often model-based and therefore cannot capture accurate 3D models of people with loose clothing and hair; or they require manual intervention to resolve occlusions or interactions. Our method addresses both limitations by introducing the first end-to-end learning approach to perform model-free implicit reconstruction for realistic 3D capture of multiple clothed people in arbitrary poses (with occlusions) from a single image. Our network simultaneously estimates the 3D geometry of each person and their 6DOF spatial locations, to obtain a coherent multi-human reconstruction. In addition, we introduce a new synthetic dataset that depicts images with a varying number of inter-occluded humans and a variety of clothing and hair styles. We demonstrate robust, high-resolution reconstructions on images of multiple humans with complex occlusions, loose clothing and a large variety of poses and scenes. Our quantitative evaluation on both synthetic and real-world datasets demonstrates state-of-the-art performance with significant improvements in the accuracy and completeness of the reconstructions over competing approaches.
Temporal Consistency Loss for High Resolution Textured and Clothed 3DHuman Reconstruction from Monocular Video
Apr 19, 2021
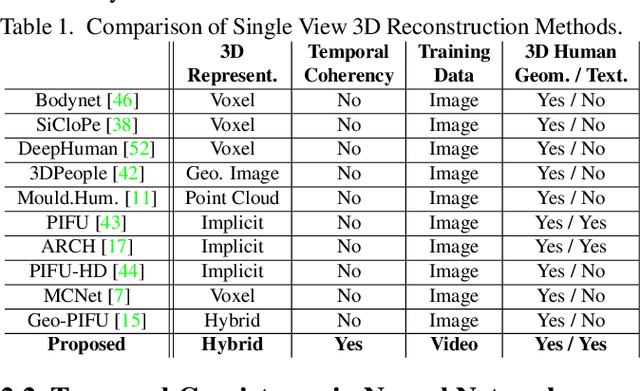
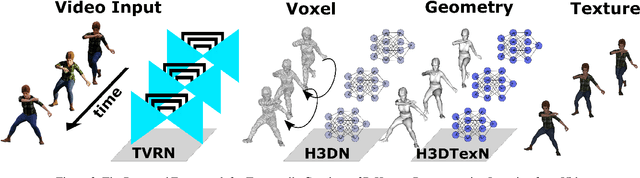
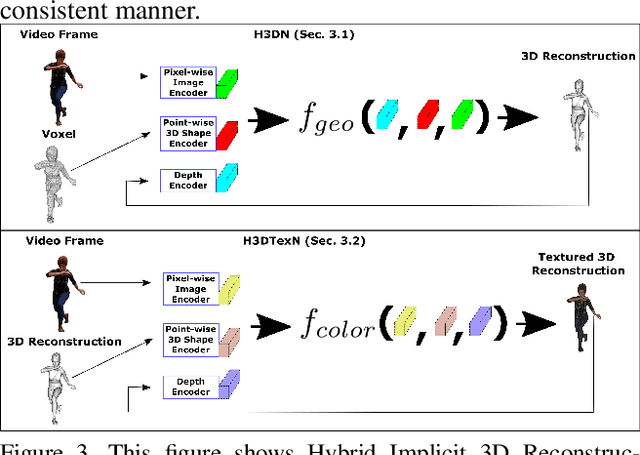
We present a novel method to learn temporally consistent 3D reconstruction of clothed people from a monocular video. Recent methods for 3D human reconstruction from monocular video using volumetric, implicit or parametric human shape models, produce per frame reconstructions giving temporally inconsistent output and limited performance when applied to video. In this paper, we introduce an approach to learn temporally consistent features for textured reconstruction of clothed 3D human sequences from monocular video by proposing two advances: a novel temporal consistency loss function; and hybrid representation learning for implicit 3D reconstruction from 2D images and coarse 3D geometry. The proposed advances improve the temporal consistency and accuracy of both the 3D reconstruction and texture prediction from a monocular video. Comprehensive comparative performance evaluation on images of people demonstrates that the proposed method significantly outperforms the state-of-the-art learning-based single image 3D human shape estimation approaches achieving significant improvement of reconstruction accuracy, completeness, quality and temporal consistency.
Multi-View Consistency Loss for Improved Single-Image 3D Reconstruction of Clothed People
Sep 29, 2020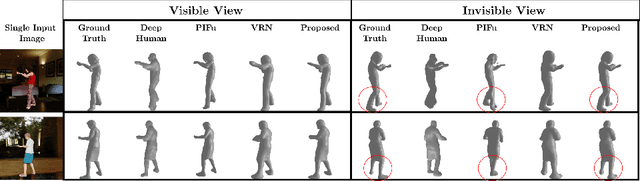
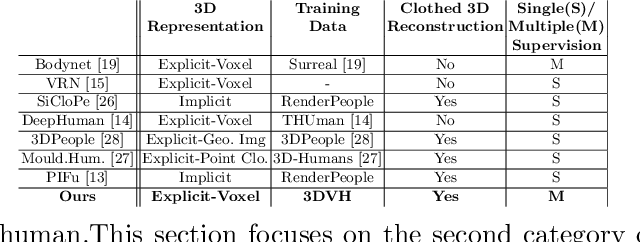
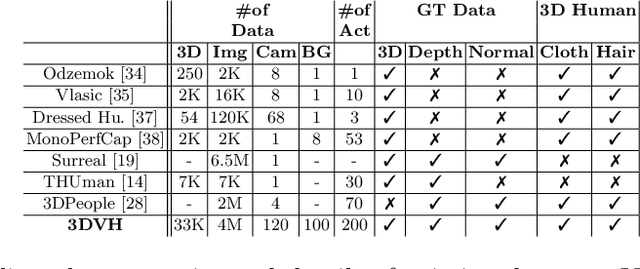
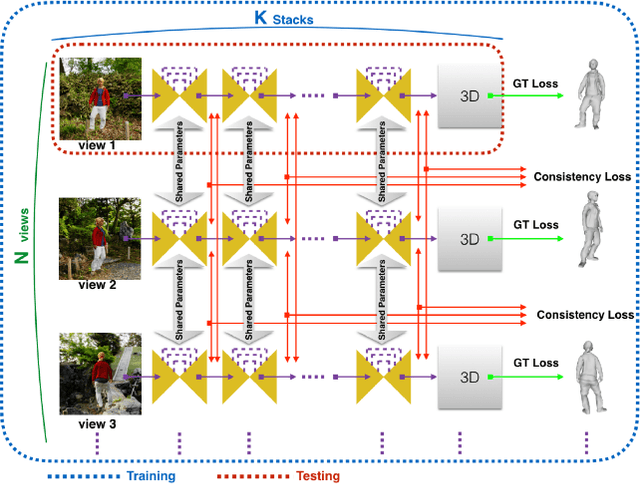
We present a novel method to improve the accuracy of the 3D reconstruction of clothed human shape from a single image. Recent work has introduced volumetric, implicit and model-based shape learning frameworks for reconstruction of objects and people from one or more images. However, the accuracy and completeness for reconstruction of clothed people is limited due to the large variation in shape resulting from clothing, hair, body size, pose and camera viewpoint. This paper introduces two advances to overcome this limitation: firstly a new synthetic dataset of realistic clothed people, 3DVH; and secondly, a novel multiple-view loss function for training of monocular volumetric shape estimation, which is demonstrated to significantly improve generalisation and reconstruction accuracy. The 3DVH dataset of realistic clothed 3D human models rendered with diverse natural backgrounds is demonstrated to allows transfer to reconstruction from real images of people. Comprehensive comparative performance evaluation on both synthetic and real images of people demonstrates that the proposed method significantly outperforms the previous state-of-the-art learning-based single image 3D human shape estimation approaches achieving significant improvement of reconstruction accuracy, completeness, and quality. An ablation study shows that this is due to both the proposed multiple-view training and the new 3DVH dataset. The code and the dataset can be found at the project website: https://akincaliskan3d.github.io/MV3DH/.
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020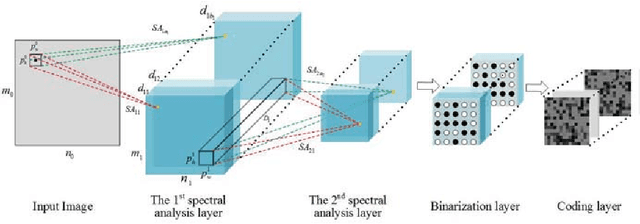
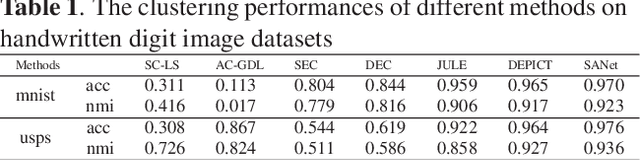

Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
Learning Dense Wide Baseline Stereo Matching for People
Oct 02, 2019

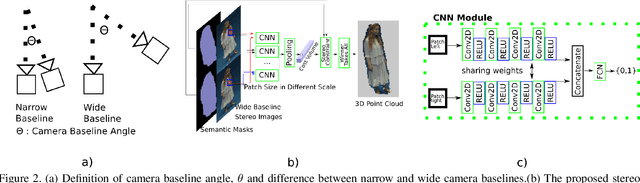
Existing methods for stereo work on narrow baseline image pairs giving limited performance between wide baseline views. This paper proposes a framework to learn and estimate dense stereo for people from wide baseline image pairs. A synthetic people stereo patch dataset (S2P2) is introduced to learn wide baseline dense stereo matching for people. The proposed framework not only learns human specific features from synthetic data but also exploits pooling layer and data augmentation to adapt to real data. The network learns from the human specific stereo patches from the proposed dataset for wide-baseline stereo estimation. In addition to patch match learning, a stereo constraint is introduced in the framework to solve wide baseline stereo reconstruction of humans. Quantitative and qualitative performance evaluation against state-of-the-art methods of proposed method demonstrates improved wide baseline stereo reconstruction on challenging datasets. We show that it is possible to learn stereo matching from synthetic people dataset and improve performance on real datasets for stereo reconstruction of people from narrow and wide baseline stereo data.
Semantic Estimation of 3D Body Shape and Pose using Minimal Cameras
Aug 08, 2019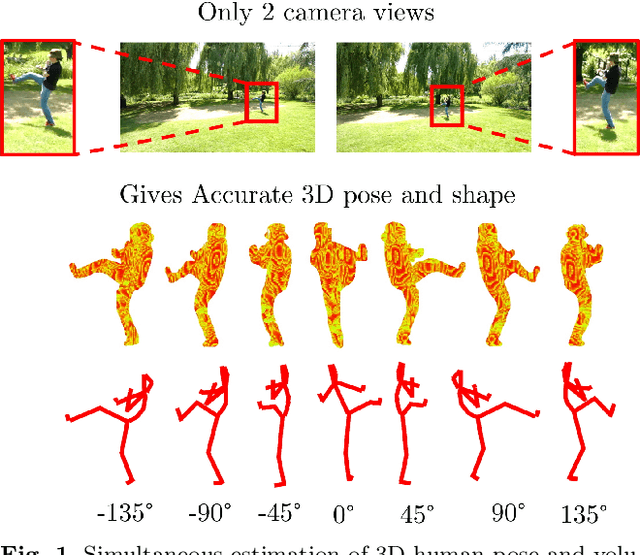
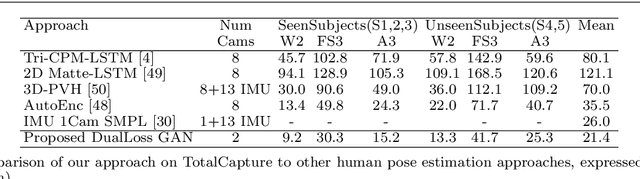
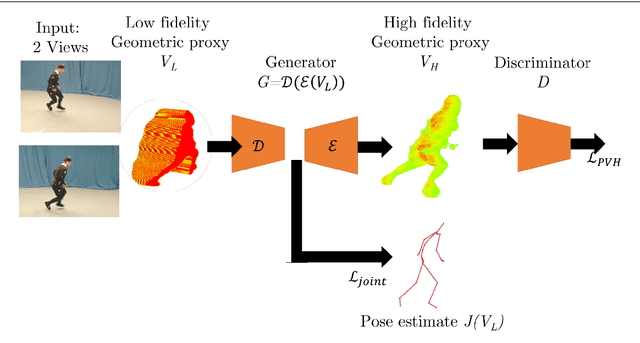
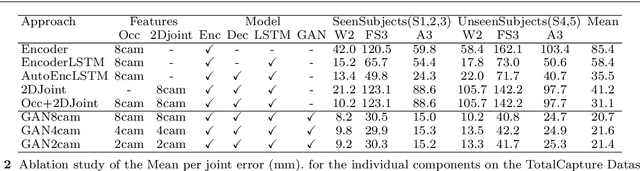
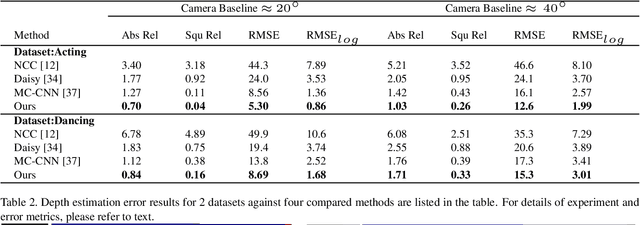
We present an approach to accurately estimate high fidelity markerless 3D pose and volumetric reconstruction of human performance using only a small set of camera views ($\sim 2$). Our method utilises a dual loss in a generative adversarial network that can yield improved performance in both reconstruction and pose estimate error. We use a deep prior implicitly learnt by the network trained over a dataset of view-ablated multi-view video footage of a wide range of subjects and actions. Uniquely we use a multi-channel symmetric 3D convolutional encoder-decoder with a dual loss to enforce the learning of a latent embedding that enforces skeletal joint positions and a deep volumetric reconstruction of the performer. An extensive evaluation is performed with state of the art performance reported on three datasets; Human 3.6M, TotalCapture and TotalCaptureOutdoor. The method opens the possibility of high-end volumetric and pose performance capture in on-set and prosumer scenarios where time or cost prohibit a high witness camera count.
EdgeNet: Semantic Scene Completion from RGB-D images
Aug 08, 2019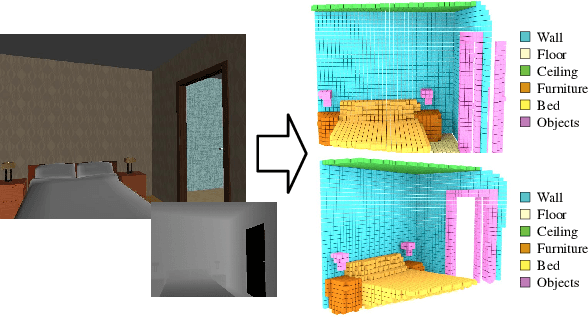
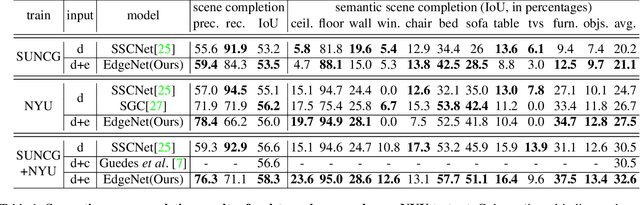
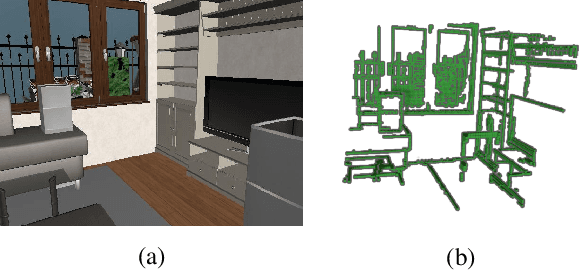
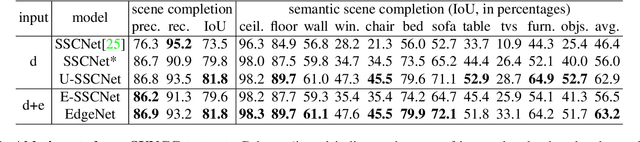
Semantic scene completion is the task of predicting a complete 3D representation of volumetric occupancy with corresponding semantic labels for a scene from a single point of view. Previous works on Semantic Scene Completion from RGB-D data used either only depth or depth with colour by projecting the 2D image into the 3D volume resulting in a sparse data representation. In this work, we present a new strategy to encode colour information in 3D space using edge detection and flipped truncated signed distance. We also present EdgeNet, a new end-to-end neural network architecture capable of handling features generated from the fusion of depth and edge information. Experimental results show improvement of 6.9% over the state-of-the-art result on real data, for end-to-end approaches.
U4D: Unsupervised 4D Dynamic Scene Understanding
Jul 23, 2019
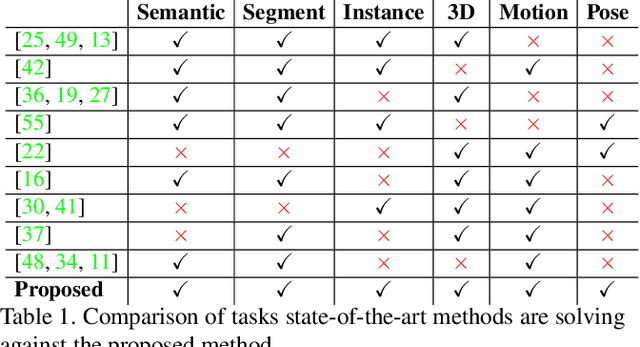

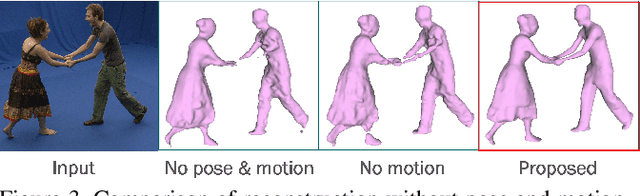
We introduce the first approach to solve the challenging problem of unsupervised 4D visual scene understanding for complex dynamic scenes with multiple interacting people from multi-view video. Our approach simultaneously estimates a detailed model that includes a per-pixel semantically and temporally coherent reconstruction, together with instance-level segmentation exploiting photo-consistency, semantic and motion information. We further leverage recent advances in 3D pose estimation to constrain the joint semantic instance segmentation and 4D temporally coherent reconstruction. This enables per person semantic instance segmentation of multiple interacting people in complex dynamic scenes. Extensive evaluation of the joint visual scene understanding framework against state-of-the-art methods on challenging indoor and outdoor sequences demonstrates a significant (approx 40%) improvement in semantic segmentation, reconstruction and scene flow accuracy.