 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Estimation of 3D Body Shape and Pose using Minimal Cameras
Aug 08, 2019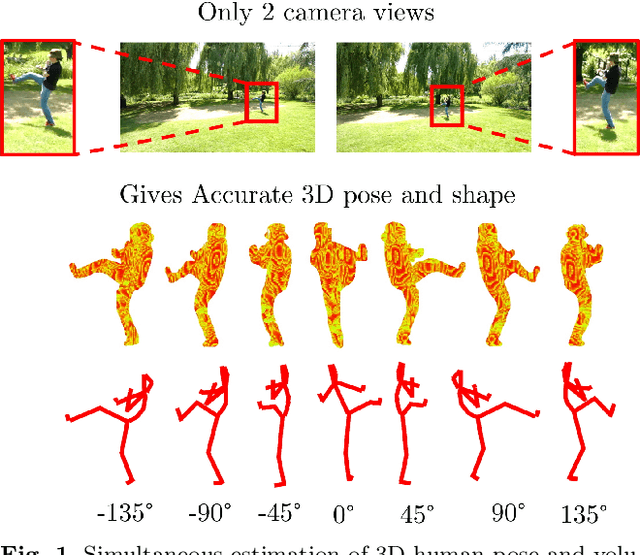
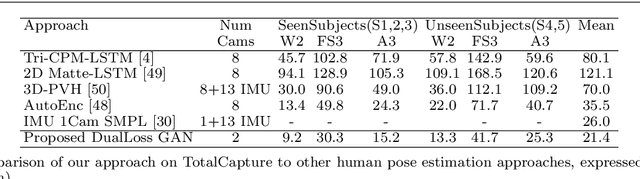
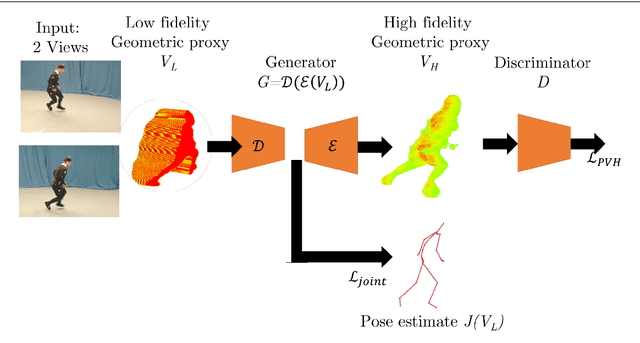
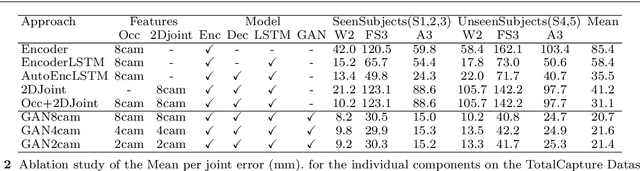
We present an approach to accurately estimate high fidelity markerless 3D pose and volumetric reconstruction of human performance using only a small set of camera views ($\sim 2$). Our method utilises a dual loss in a generative adversarial network that can yield improved performance in both reconstruction and pose estimate error. We use a deep prior implicitly learnt by the network trained over a dataset of view-ablated multi-view video footage of a wide range of subjects and actions. Uniquely we use a multi-channel symmetric 3D convolutional encoder-decoder with a dual loss to enforce the learning of a latent embedding that enforces skeletal joint positions and a deep volumetric reconstruction of the performer. An extensive evaluation is performed with state of the art performance reported on three datasets; Human 3.6M, TotalCapture and TotalCaptureOutdoor. The method opens the possibility of high-end volumetric and pose performance capture in on-set and prosumer scenarios where time or cost prohibit a high witness camera count.
Deep Autoencoder for Combined Human Pose Estimation and body Model Upscaling
Jul 04, 2018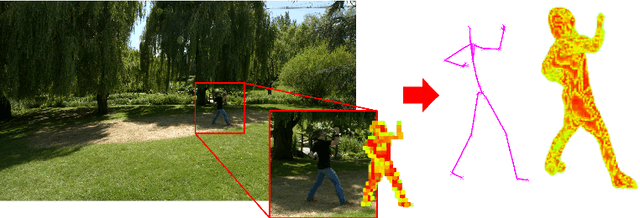
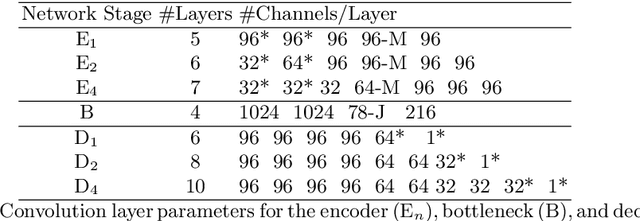
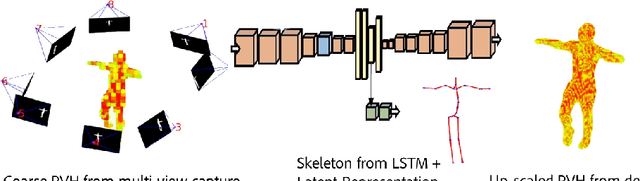
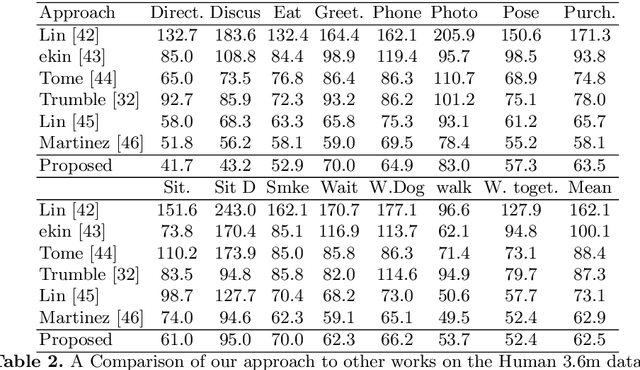
We present a method for simultaneously estimating 3D human pose and body shape from a sparse set of wide-baseline camera views. We train a symmetric convolutional autoencoder with a dual loss that enforces learning of a latent representation that encodes skeletal joint positions, and at the same time learns a deep representation of volumetric body shape. We harness the latter to up-scale input volumetric data by a factor of $4 \times$, whilst recovering a 3D estimate of joint positions with equal or greater accuracy than the state of the art. Inference runs in real-time (25 fps) and has the potential for passive human behaviour monitoring where there is a requirement for high fidelity estimation of human body shape and pose.