 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeNet: Semantic Scene Completion from RGB-D images
Aug 08, 2019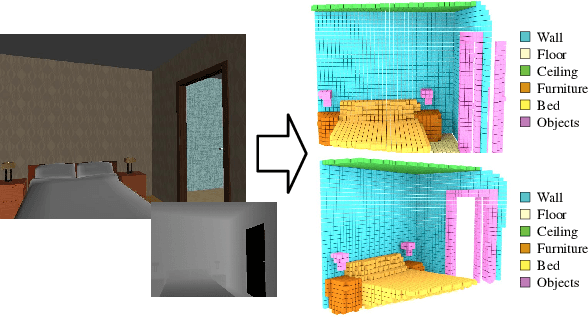
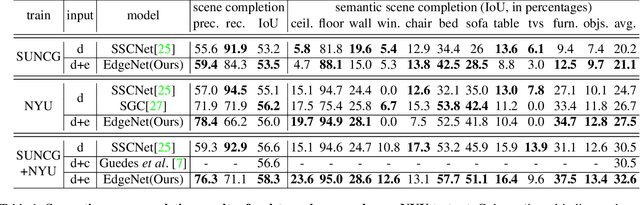
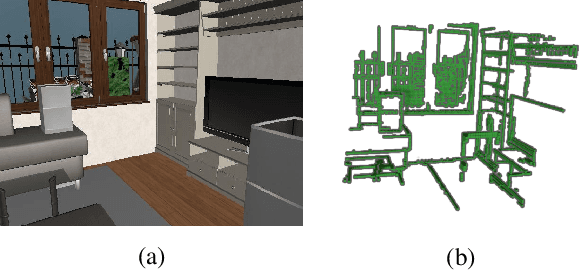
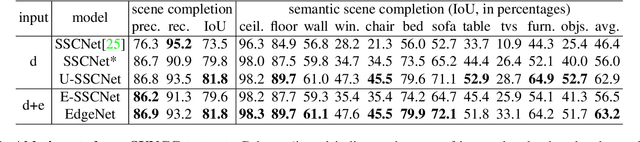
Semantic scene completion is the task of predicting a complete 3D representation of volumetric occupancy with corresponding semantic labels for a scene from a single point of view. Previous works on Semantic Scene Completion from RGB-D data used either only depth or depth with colour by projecting the 2D image into the 3D volume resulting in a sparse data representation. In this work, we present a new strategy to encode colour information in 3D space using edge detection and flipped truncated signed distance. We also present EdgeNet, a new end-to-end neural network architecture capable of handling features generated from the fusion of depth and edge information. Experimental results show improvement of 6.9% over the state-of-the-art result on real data, for end-to-end approaches.
Domain adaptation for holistic skin detection
Mar 16, 2019
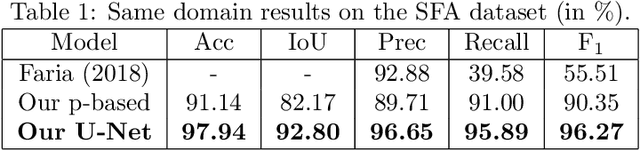
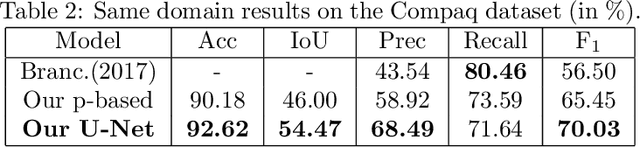
Human skin detection in images is a widely studied topic of Computer Vision for which it is commonly accepted that analysis of pixel color or local patches may suffice. This is because skin regions appear to be relatively uniform and many argue that there is a small chromatic variation among different samples. However, we found that there are strong biases in the datasets commonly used to train or tune skin detection methods. Furthermore, the lack of contextual information may hinder the performance of local approaches. In this paper we present a comprehensive evaluation of holistic and local Convolutional Neural Network (CNN) approaches on in-domain and cross-domain experiments and compare with state-of-the-art pixel-based approaches. We also propose a combination of inductive transfer learning and unsupervised domain adaptation methods, which are evaluated on different domains under several amounts of labelled data availability. We show a clear superiority of CNN over pixel-based approaches even without labelled training samples on the target domain. Furthermore, we provide experimental support for the counter-intuitive superiority of holistic over local approaches for human skin detection.
Hand range of motion evaluation for Rheumatoid Arthritis patients
Mar 16, 2019
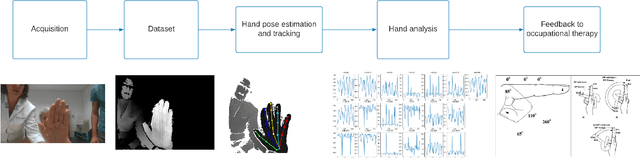
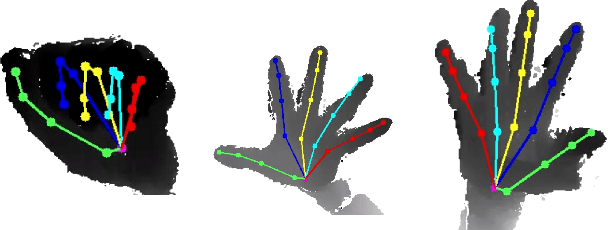

We introduce a framework for dynamic evaluation of the fingers movements: flexion, extension, abduction and adduction. This framework estimates angle measurements from joints computed by a hand pose estimation algorithm using a depth sensor (Realsense SR300). Given depth maps as input, our framework uses Pose-REN, which is a state-of-art hand pose estimation method that estimates 3D hand joint positions using a deep convolutional neural network. The pose estimation algorithm runs in real-time, allowing users to visualise 3D skeleton tracking results at the same time as the depth images are acquired. Once 3D joint poses are obtained, our framework estimates a plane containing the wrist and MCP joints and measures flexion/extension and abduction/aduction angles by applying computational geometry operations with respect to this plane. We analysed flexion and abduction movement patterns using real data, extracting the movement trajectories. Our preliminary results show that this method allows an automatic discrimination of hands with Rheumatoid Arthritis (RA) and healthy patients. The angle between joints can be used as an indicative of current movement capabilities and function. Although the measurements can be noisy and less accurate than those obtained statically through goniometry, the acquisition is much easier, non-invasive and patient-friendly, which shows the potential of our approach. The system can be used with and without orthosis. Our framework allows the acquisition of measurements with minimal intervention and significantly reduces the evaluation time.
Document classification using a Bi-LSTM to unclog Brazil's supreme court
Nov 27, 2018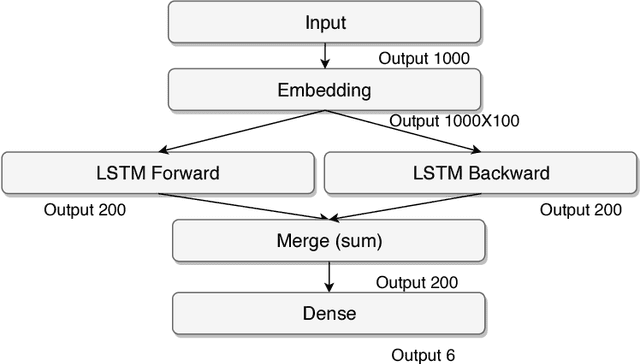

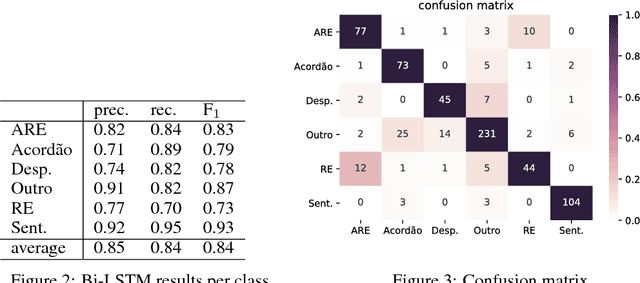
The Brazilian court system is currently the most clogged up judiciary system in the world. Thousands of lawsuit cases reach the supreme court every day. These cases need to be analyzed in order to be associated to relevant tags and allocated to the right team. Most of the cases reach the court as raster scanned documents with widely variable levels of quality. One of the first steps for the analysis is to classify these documents. In this paper we present a Bidirectional Long Short-Term Memory network (Bi-LSTM) to classify these pieces of legal document.
Semantic Scene Completion Combining Colour and Depth: preliminary experiments
Feb 13, 2018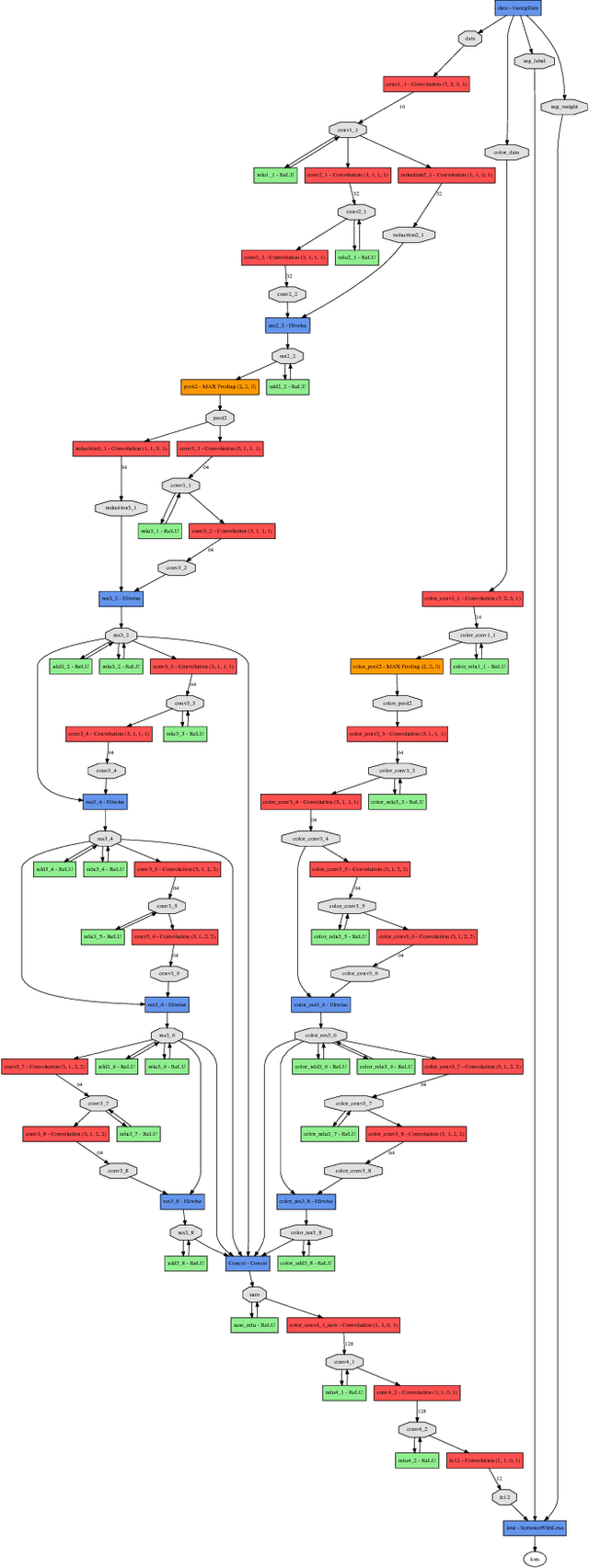
Semantic scene completion is the task of producing a complete 3D voxel representation of volumetric occupancy with semantic labels for a scene from a single-view observation. We built upon the recent work of Song et al. (CVPR 2017), who proposed SSCnet, a method that performs scene completion and semantic labelling in a single end-to-end 3D convolutional network. SSCnet uses only depth maps as input, even though depth maps are usually obtained from devices that also capture colour information, such as RGBD sensors and stereo cameras. In this work, we investigate the potential of the RGB colour channels to improve SSCnet.