 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy distillation helps: a statistical perspective
May 21, 2020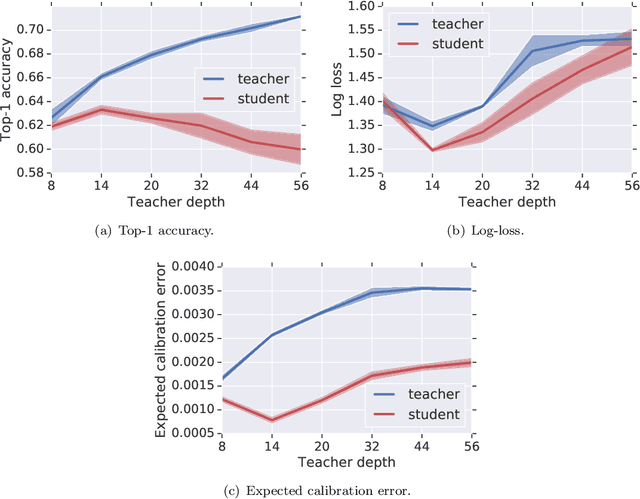
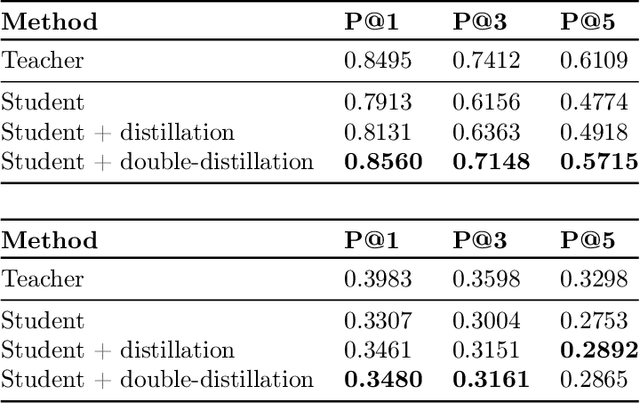
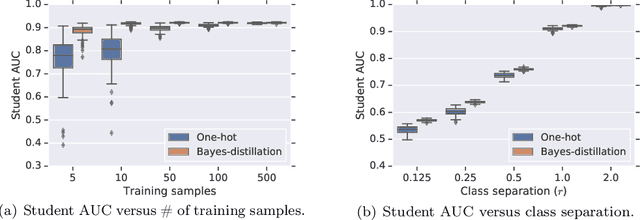
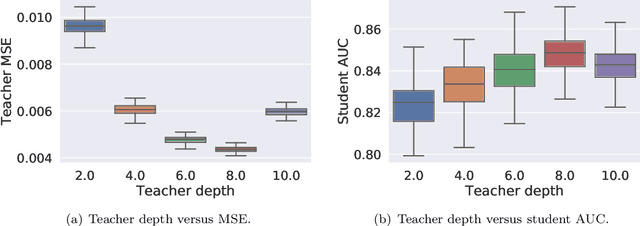
Knowledge distillation is a technique for improving the performance of a simple "student" model by replacing its one-hot training labels with a distribution over labels obtained from a complex "teacher" model. While this simple approach has proven widely effective, a basic question remains unresolved: why does distillation help? In this paper, we present a statistical perspective on distillation which addresses this question, and provides a novel connection to extreme multiclass retrieval techniques. Our core observation is that the teacher seeks to estimate the underlying (Bayes) class-probability function. Building on this, we establish a fundamental bias-variance tradeoff in the student's objective: this quantifies how approximate knowledge of these class-probabilities can significantly aid learning. Finally, we show how distillation complements existing negative mining techniques for extreme multiclass retrieval, and propose a unified objective which combines these ideas.
Doubly-stochastic mining for heterogeneous retrieval
Apr 23, 2020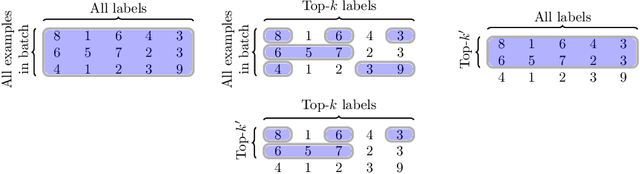


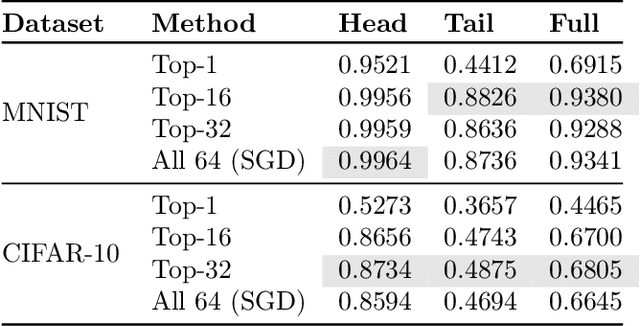
Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.
Federated Learning with Only Positive Labels
Apr 21, 2020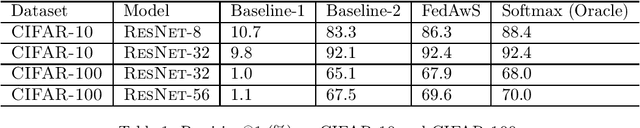

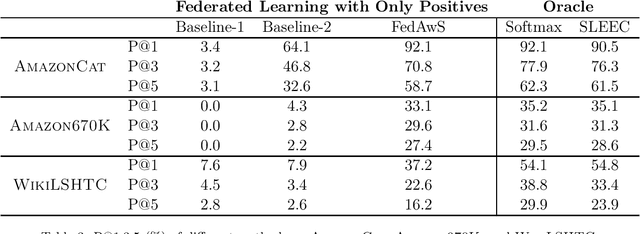

We consider learning a multi-class classification model in the federated setting, where each user has access to the positive data associated with only a single class. As a result, during each federated learning round, the users need to locally update the classifier without having access to the features and the model parameters for the negative classes. Thus, naively employing conventional decentralized learning such as the distributed SGD or Federated Averaging may lead to trivial or extremely poor classifiers. In particular, for the embedding based classifiers, all the class embeddings might collapse to a single point. To address this problem, we propose a generic framework for training with only positive labels, namely Federated Averaging with Spreadout (FedAwS), where the server imposes a geometric regularizer after each round to encourage classes to be spreadout in the embedding space. We show, both theoretically and empirically, that FedAwS can almost match the performance of conventional learning where users have access to negative labels. We further extend the proposed method to the settings with large output spaces.
Does label smoothing mitigate label noise?
Mar 05, 2020
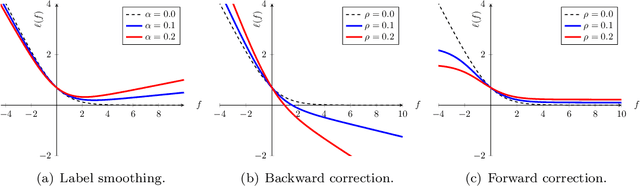
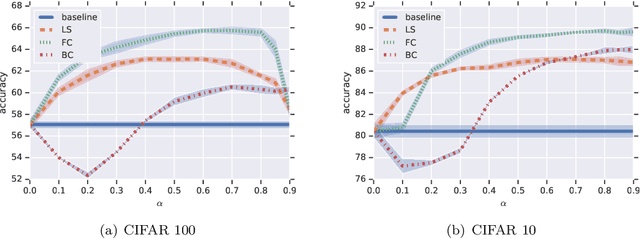

Label smoothing is commonly used in training deep learning models, wherein one-hot training labels are mixed with uniform label vectors. Empirically, smoothing has been shown to improve both predictive performance and model calibration. In this paper, we study whether label smoothing is also effective as a means of coping with label noise. While label smoothing apparently amplifies this problem --- being equivalent to injecting symmetric noise to the labels --- we show how it relates to a general family of loss-correction techniques from the label noise literature. Building on this connection, we show that label smoothing is competitive with loss-correction under label noise. Further, we show that when distilling models from noisy data, label smoothing of the teacher is beneficial; this is in contrast to recent findings for noise-free problems, and sheds further light on settings where label smoothing is beneficial.
Supervised Learning: No Loss No Cry
Feb 10, 2020
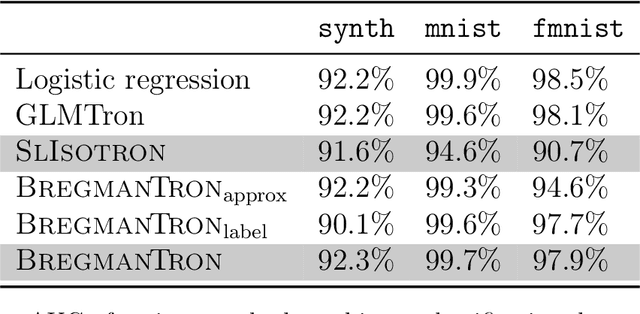

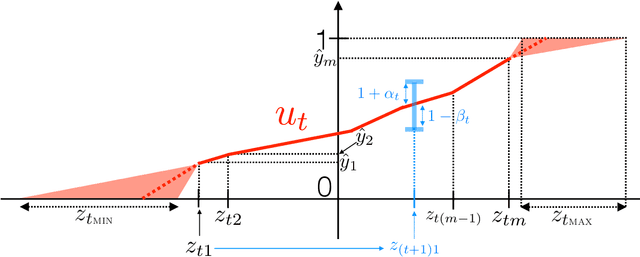
Supervised learning requires the specification of a loss function to minimise. While the theory of admissible losses from both a computational and statistical perspective is well-developed, these offer a panoply of different choices. In practice, this choice is typically made in an \emph{ad hoc} manner. In hopes of making this procedure more principled, the problem of \emph{learning the loss function} for a downstream task (e.g., classification) has garnered recent interest. However, works in this area have been generally empirical in nature. In this paper, we revisit the {\sc SLIsotron} algorithm of Kakade et al. (2011) through a novel lens, derive a generalisation based on Bregman divergences, and show how it provides a principled procedure for learning the loss. In detail, we cast {\sc SLIsotron} as learning a loss from a family of composite square losses. By interpreting this through the lens of \emph{proper losses}, we derive a generalisation of {\sc SLIsotron} based on Bregman divergences. The resulting {\sc BregmanTron} algorithm jointly learns the loss along with the classifier. It comes equipped with a simple guarantee of convergence for the loss it learns, and its set of possible outputs comes with a guarantee of agnostic approximability of Bayes rule. Experiments indicate that the {\sc BregmanTron} substantially outperforms the {\sc SLIsotron}, and that the loss it learns can be minimized by other algorithms for different tasks, thereby opening the interesting problem of \textit{loss transfer} between domains.
Online Hierarchical Clustering Approximations
Sep 20, 2019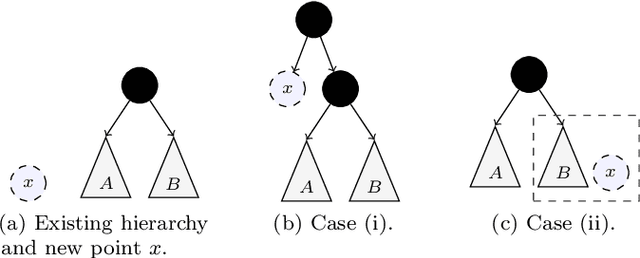

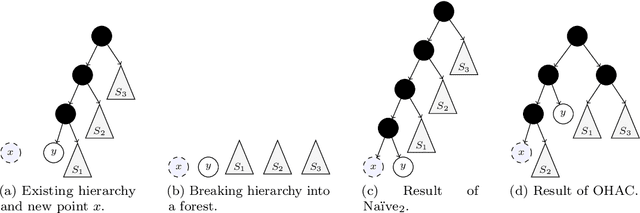
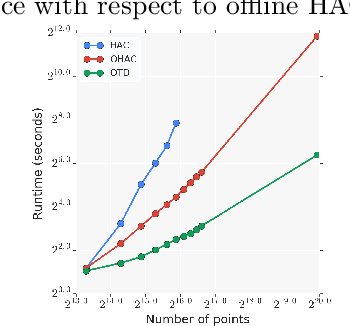
Hierarchical clustering is a widely used approach for clustering datasets at multiple levels of granularity. Despite its popularity, existing algorithms such as hierarchical agglomerative clustering (HAC) are limited to the offline setting, and thus require the entire dataset to be available. This prohibits their use on large datasets commonly encountered in modern learning applications. In this paper, we consider hierarchical clustering in the online setting, where points arrive one at a time. We propose two algorithms that seek to optimize the Moseley and Wang (MW) revenue function, a variant of the Dasgupta cost. These algorithms offer different tradeoffs between efficiency and MW revenue performance. The first algorithm, OTD, is a highly efficient Online Top Down algorithm which provably achieves a 1/3-approximation to the MW revenue under a data separation assumption. The second algorithm, OHAC, is an online counterpart to offline HAC, which is known to yield a 1/3-approximation to the MW revenue, and produce good quality clusters in practice. We show that OHAC approximates offline HAC by leveraging a novel split-merge procedure. We empirically show that OTD and OHAC offer significant efficiency and cluster quality gains respectively over baselines.
Noise-tolerant fair classification
Jan 30, 2019
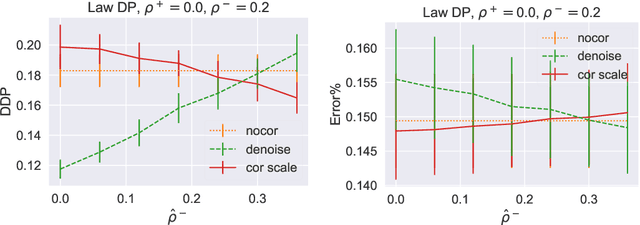

Fair machine learning concerns the analysis and design of learning algorithms that do not exhibit systematic bias with respect to some sensitive feature (e.g., race, gender). This subject has received sustained interest in the past few years, with considerable progress on both devising sensible measures of fairness, and means of achieving them. Typically, the latter involves correcting one's learning procedure so that there is no bias on the training sample. However, all such work has operated under the assumption that the sensitive feature available in one's training sample is perfectly reliable. This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of privacy concerns. This poses the question of whether one can still learn fair classifiers in the presence of such noisy sensitive features. In this paper, we answer the question in the affirmative for a widely-used measure of fairness and model of noise. We show that if one measures fairness using the mean-difference score, and sensitive features are subject to noise from the mutually contaminated learning model, then owing to a simple identity we only need to change the desired fairness-tolerance. The requisite tolerance can be estimated by leveraging existing noise-rate estimators. We finally show that our procedure is empirically effective on two case-studies involving sensitive feature censoring.
Fairness risk measures
Jan 24, 2019
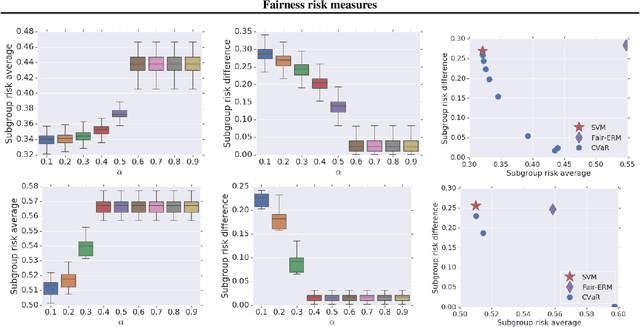
Ensuring that classifiers are non-discriminatory or fair with respect to a sensitive feature (e.g., race or gender) is a topical problem. Progress in this task requires fixing a definition of fairness, and there have been several proposals in this regard over the past few years. Several of these, however, assume either binary sensitive features (thus precluding categorical or real-valued sensitive groups), or result in non-convex objectives (thus adversely affecting the optimisation landscape). In this paper, we propose a new definition of fairness that generalises some existing proposals, while allowing for generic sensitive features and resulting in a convex objective. The key idea is to enforce that the expected losses (or risks) across each subgroup induced by the sensitive feature are commensurate. We show how this relates to the rich literature on risk measures from mathematical finance. As a special case, this leads to a new convex fairness-aware objective based on minimising the conditional value at risk (CVaR).
Cold-start Playlist Recommendation with Multitask Learning
Jan 18, 2019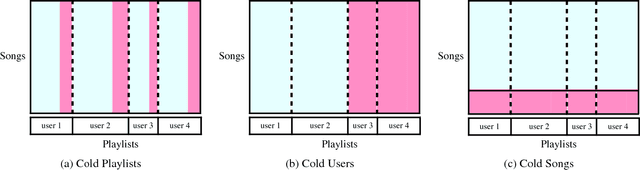
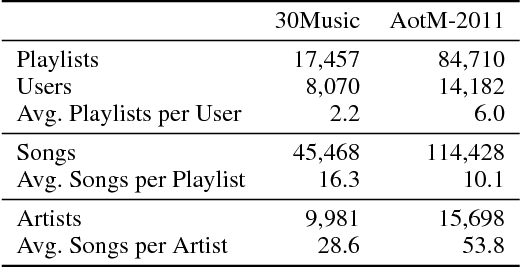

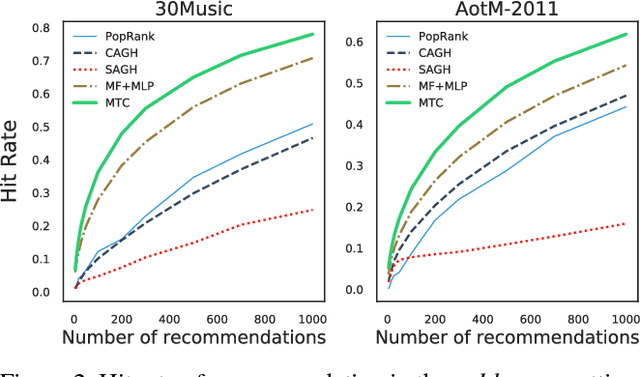
Playlist recommendation involves producing a set of songs that a user might enjoy. We investigate this problem in three cold-start scenarios: (i) cold playlists, where we recommend songs to form new personalised playlists for an existing user; (ii) cold users, where we recommend songs to form new playlists for a new user; and (iii) cold songs, where we recommend newly released songs to extend users' existing playlists. We propose a flexible multitask learning method to deal with all three settings. The method learns from user-curated playlists, and encourages songs in a playlist to be ranked higher than those that are not by minimising a bipartite ranking loss. Inspired by an equivalence between bipartite ranking and binary classification, we show how one can efficiently approximate an optimal solution of the multitask learning objective by minimising a classification loss. Empirical results on two real playlist datasets show the proposed approach has good performance for cold-start playlist recommendation.
Comparative Document Summarisation via Classification
Dec 06, 2018


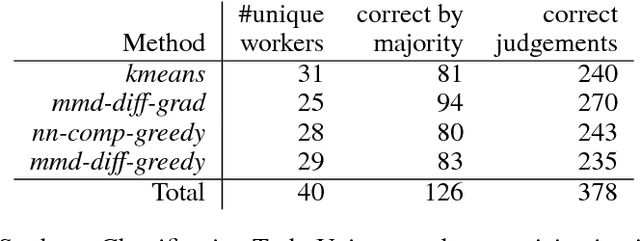
This paper considers extractive summarisation in a comparative setting: given two or more document groups (e.g., separated by publication time), the goal is to select a small number of documents that are representative of each group, and also maximally distinguishable from other groups. We formulate a set of new objective functions for this problem that connect recent literature on document summarisation, interpretable machine learning, and data subset selection. In particular, by casting the problem as a binary classification amongst different groups, we derive objectives based on the notion of maximum mean discrepancy, as well as a simple yet effective gradient-based optimisation strategy. Our new formulation allows scalable evaluations of comparative summarisation as a classification task, both automatically and via crowd-sourcing. To this end, we evaluate comparative summarisation methods on a newly curated collection of controversial news topics over 13 months. We observe that gradient-based optimisation outperforms discrete and baseline approaches in 15 out of 24 different automatic evaluation settings. In crowd-sourced evaluations, summaries from gradient optimisation elicit 7% more accurate classification from human workers than discrete optimisation. Our result contrasts with recent literature on submodular data subset selection that favours discrete optimisation. We posit that our formulation of comparative summarisation will prove useful in a diverse range of use cases such as comparing content sources, authors, related topics, or distinct view points.