 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I'm sorry to hear that": finding bias in language models with a holistic descriptor dataset
May 18, 2022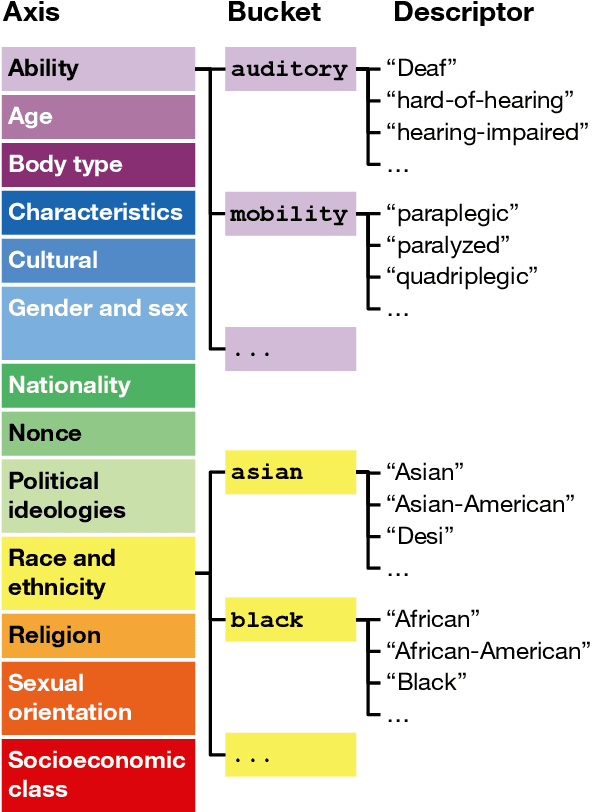

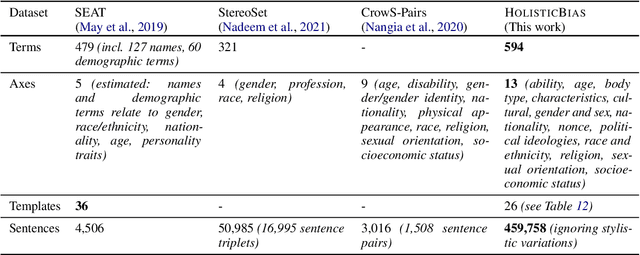
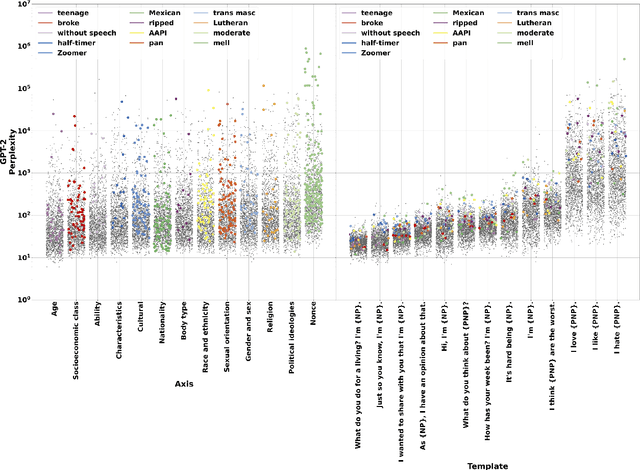
As language models grow in popularity, their biases across all possible markers of demographic identity should be measured and addressed in order to avoid perpetuating existing societal harms. Many datasets for measuring bias currently exist, but they are restricted in their coverage of demographic axes, and are commonly used with preset bias tests that presuppose which types of biases the models exhibit. In this work, we present a new, more inclusive dataset, HOLISTICBIAS, which consists of nearly 600 descriptor terms across 13 different demographic axes. HOLISTICBIAS was assembled in conversation with experts and community members with lived experience through a participatory process. We use these descriptors combinatorially in a set of bias measurement templates to produce over 450,000 unique sentence prompts, and we use these prompts to explore, identify, and reduce novel forms of bias in several generative models. We demonstrate that our dataset is highly efficacious for measuring previously unmeasurable biases in token likelihoods and generations from language models, as well as in an offensiveness classifier. We will invite additions and amendments to the dataset, and we hope it will help serve as a basis for easy-to-use and more standardized methods for evaluating bias in NLP models.
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
Apr 07, 2022
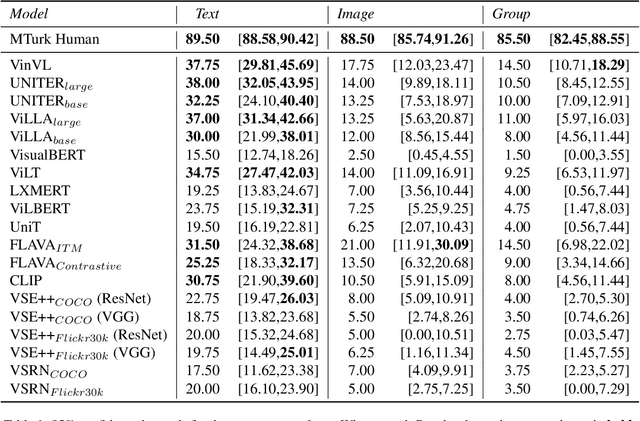
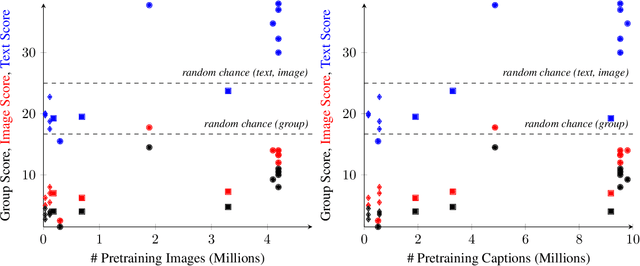
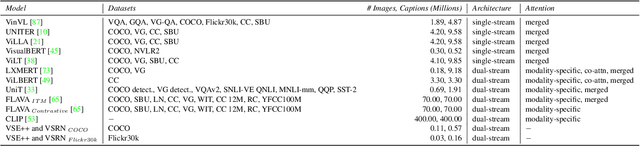
We present a novel task and dataset for evaluating the ability of vision and language models to conduct visio-linguistic compositional reasoning, which we call Winoground. Given two images and two captions, the goal is to match them correctly - but crucially, both captions contain a completely identical set of words, only in a different order. The dataset was carefully hand-curated by expert annotators and is labeled with a rich set of fine-grained tags to assist in analyzing model performance. We probe a diverse range of state-of-the-art vision and language models and find that, surprisingly, none of them do much better than chance. Evidently, these models are not as skilled at visio-linguistic compositional reasoning as we might have hoped. We perform an extensive analysis to obtain insights into how future work might try to mitigate these models' shortcomings. We aim for Winoground to serve as a useful evaluation set for advancing the state of the art and driving further progress in the field. The dataset is available at https://huggingface.co/datasets/facebook/winoground.
Dynatask: A Framework for Creating Dynamic AI Benchmark Tasks
Apr 05, 2022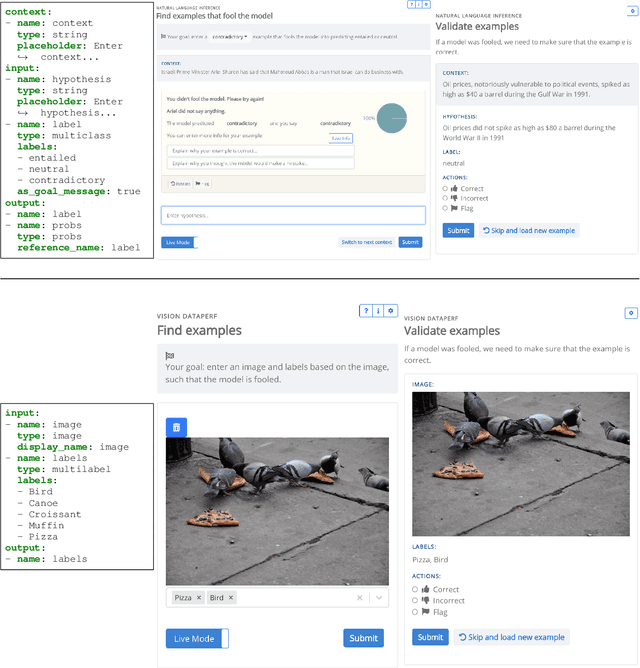
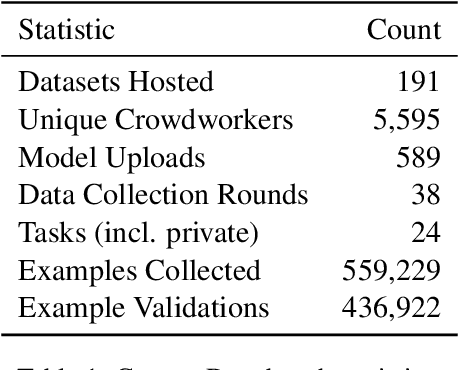
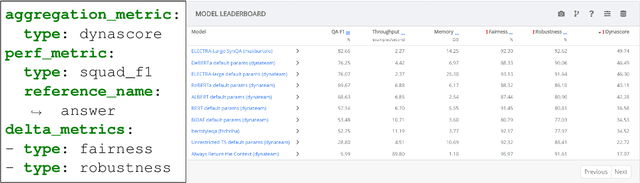
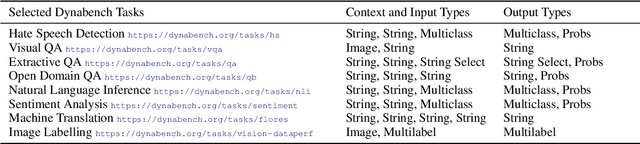
We introduce Dynatask: an open source system for setting up custom NLP tasks that aims to greatly lower the technical knowledge and effort required for hosting and evaluating state-of-the-art NLP models, as well as for conducting model in the loop data collection with crowdworkers. Dynatask is integrated with Dynabench, a research platform for rethinking benchmarking in AI that facilitates human and model in the loop data collection and evaluation. To create a task, users only need to write a short task configuration file from which the relevant web interfaces and model hosting infrastructure are automatically generated. The system is available at https://dynabench.org/ and the full library can be found at https://github.com/facebookresearch/dynabench.
A Latent-Variable Model for Intrinsic Probing
Jan 20, 2022The success of pre-trained contextualized representations has prompted researchers to analyze them for the presence of linguistic information. Indeed, it is natural to assume that these pre-trained representations do encode some level of linguistic knowledge as they have brought about large empirical improvements on a wide variety of NLP tasks, which suggests they are learning true linguistic generalization. In this work, we focus on intrinsic probing, an analysis technique where the goal is not only to identify whether a representation encodes a linguistic attribute, but also to pinpoint where this attribute is encoded. We propose a novel latent-variable formulation for constructing intrinsic probes and derive a tractable variational approximation to the log-likelihood. Our results show that our model is versatile and yields tighter mutual information estimates than two intrinsic probes previously proposed in the literature. Finally, we find empirical evidence that pre-trained representations develop a cross-lingually entangled notion of morphosyntax.
A Word on Machine Ethics: A Response to Jiang et al.
Nov 07, 2021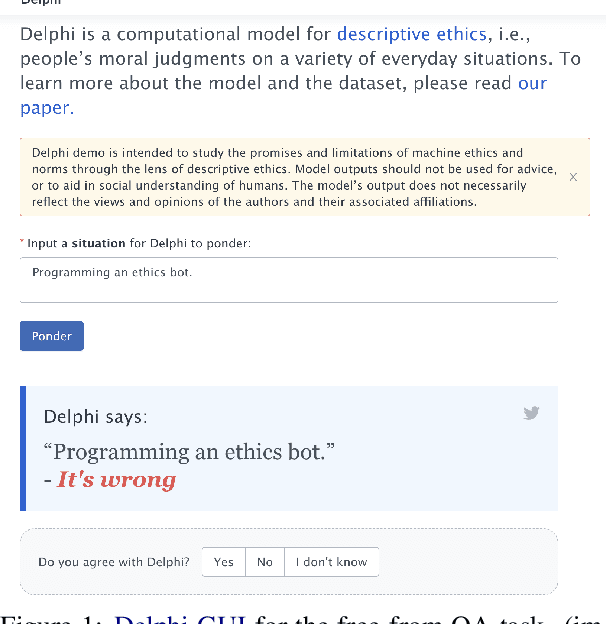

Ethics is one of the longest standing intellectual endeavors of humanity. In recent years, the fields of AI and NLP have attempted to wrangle with how learning systems that interact with humans should be constrained to behave ethically. One proposal in this vein is the construction of morality models that can take in arbitrary text and output a moral judgment about the situation described. In this work, we focus on a single case study of the recently proposed Delphi model and offer a critique of the project's proposed method of automating morality judgments. Through an audit of Delphi, we examine broader issues that would be applicable to any similar attempt. We conclude with a discussion of how machine ethics could usefully proceed, by focusing on current and near-future uses of technology, in a way that centers around transparency, democratic values, and allows for straightforward accountability.
Analyzing Dynamic Adversarial Training Data in the Limit
Oct 16, 2021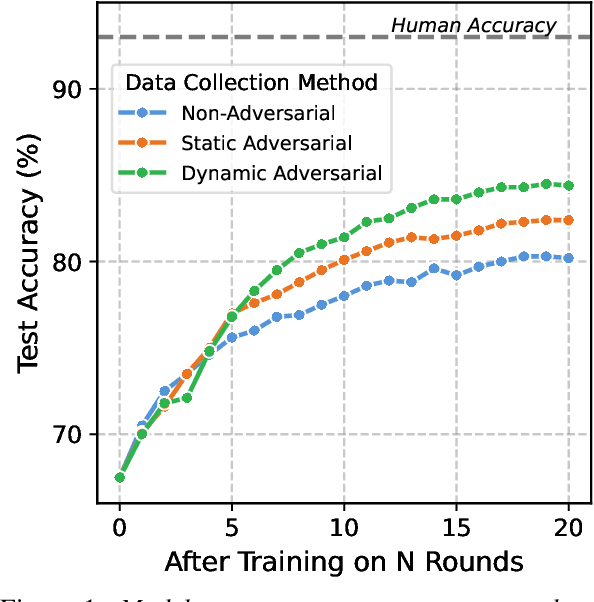
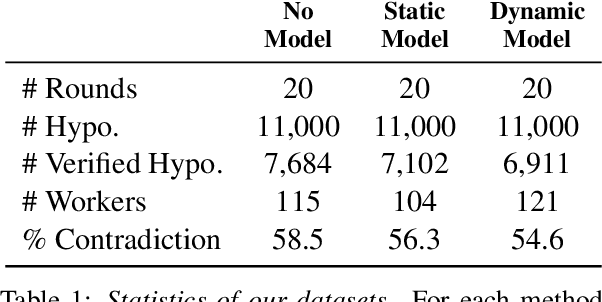

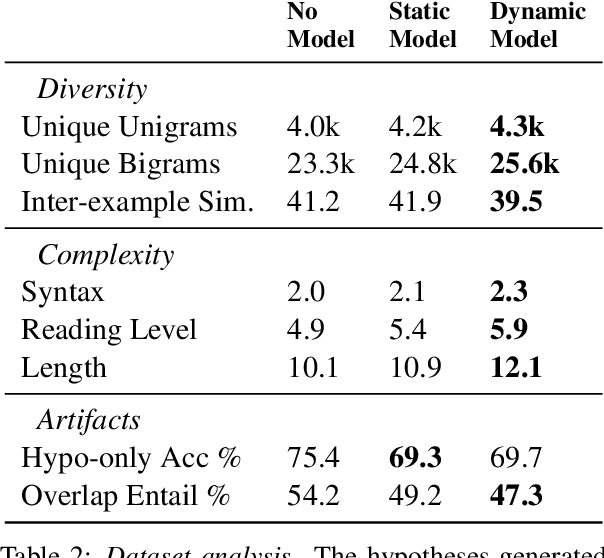
To create models that are robust across a wide range of test inputs, training datasets should include diverse examples that span numerous phenomena. Dynamic adversarial data collection (DADC), where annotators craft examples that challenge continually improving models, holds promise as an approach for generating such diverse training sets. Prior work has shown that running DADC over 1-3 rounds can help models fix some error types, but it does not necessarily lead to better generalization beyond adversarial test data. We argue that running DADC over many rounds maximizes its training-time benefits, as the different rounds can together cover many of the task-relevant phenomena. We present the first study of longer-term DADC, where we collect 20 rounds of NLI examples for a small set of premise paragraphs, with both adversarial and non-adversarial approaches. Models trained on DADC examples make 26% fewer errors on our expert-curated test set compared to models trained on non-adversarial data. Our analysis shows that DADC yields examples that are more difficult, more lexically and syntactically diverse, and contain fewer annotation artifacts compared to non-adversarial examples.
Hi, my name is Martha: Using names to measure and mitigate bias in generative dialogue models
Sep 07, 2021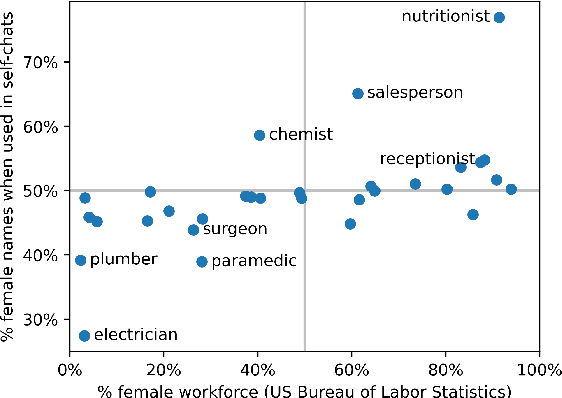
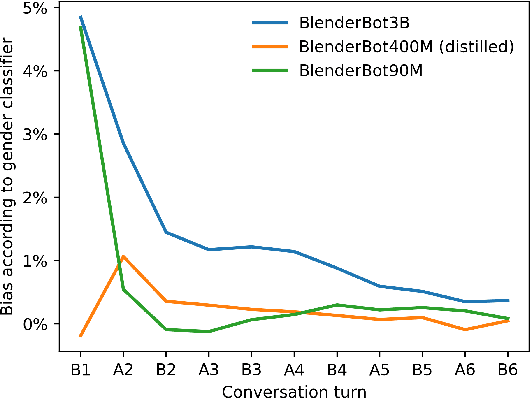
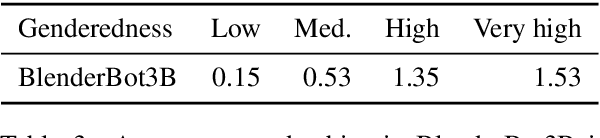
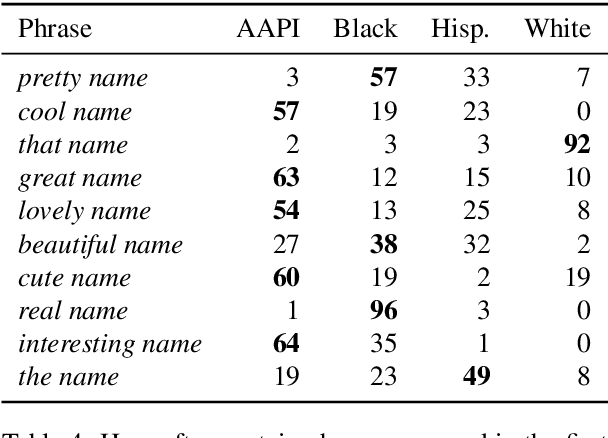
All AI models are susceptible to learning biases in data that they are trained on. For generative dialogue models, being trained on real human conversations containing unbalanced gender and race/ethnicity references can lead to models that display learned biases, which we define here broadly as any measurable differences in the distributions of words or semantic content of conversations based on demographic groups. We measure the strength of such biases by producing artificial conversations between two copies of a dialogue model, conditioning one conversational partner to state a name commonly associated with a certain gender and/or race/ethnicity. We find that larger capacity models tend to exhibit more gender bias and greater stereotyping of occupations by gender. We show that several methods of tuning these dialogue models, specifically name scrambling, controlled generation, and unlikelihood training, are effective in reducing bias in conversation, including on a downstream conversational task. Name scrambling is also effective in lowering differences in token usage across conversations where partners have names associated with different genders or races/ethnicities.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021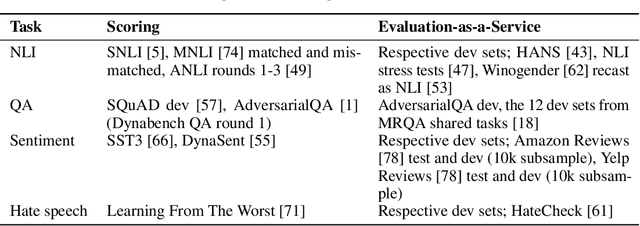
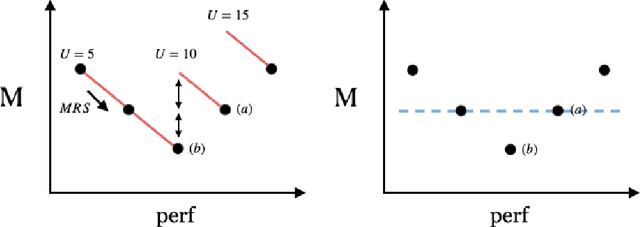
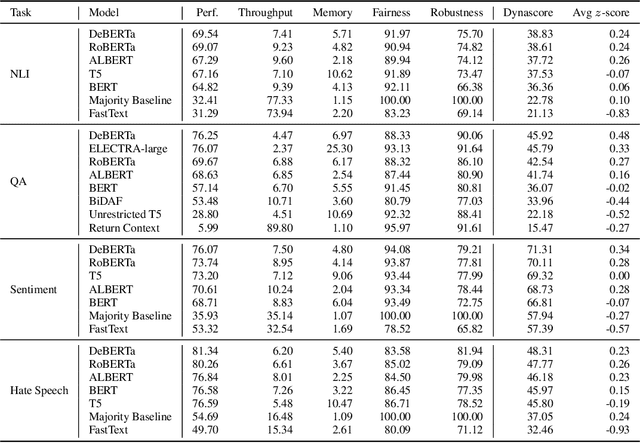
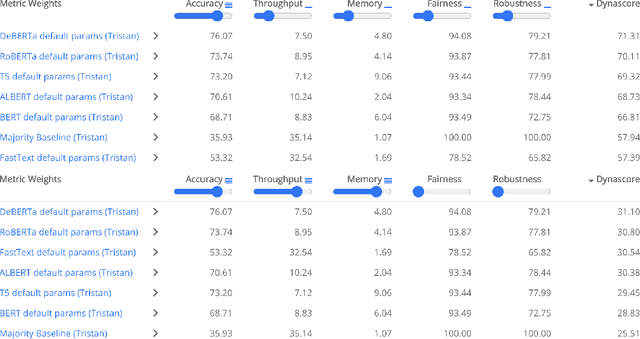
We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.
Investigating Failures of Automatic Translation in the Case of Unambiguous Gender
Apr 16, 2021
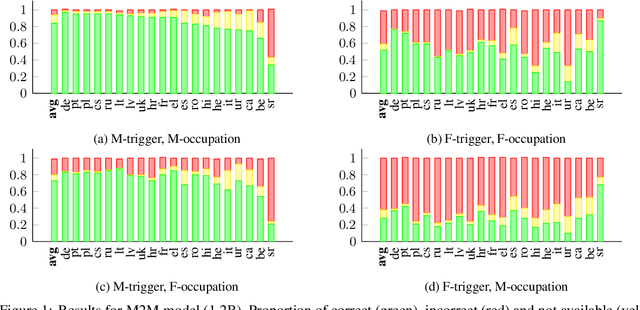
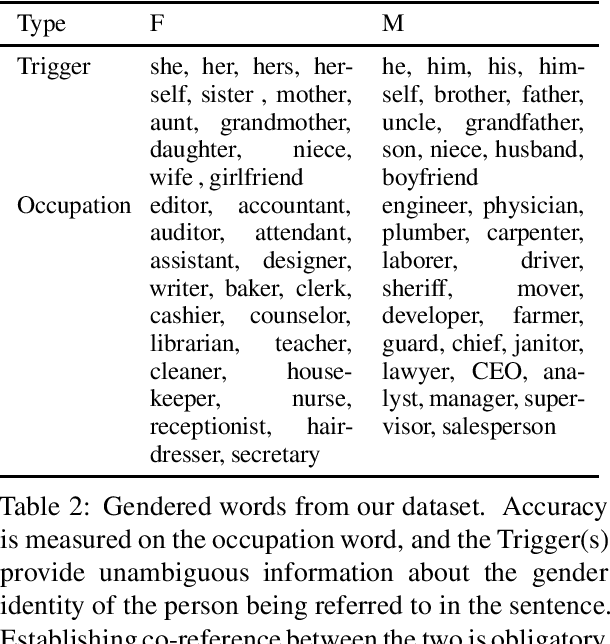
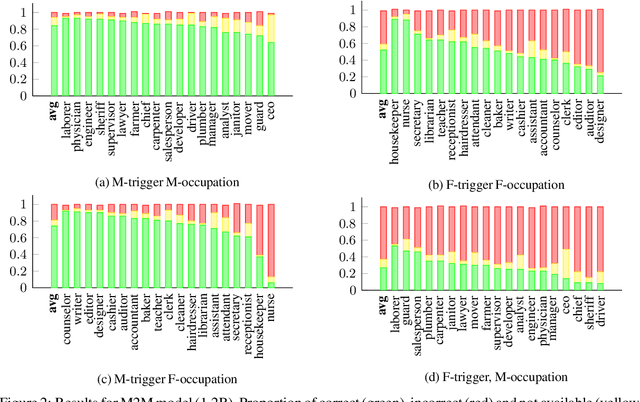
Transformer based models are the modern work horses for neural machine translation (NMT), reaching state of the art across several benchmarks. Despite their impressive accuracy, we observe a systemic and rudimentary class of errors made by transformer based models with regards to translating from a language that doesn't mark gender on nouns into others that do. We find that even when the surrounding context provides unambiguous evidence of the appropriate grammatical gender marking, no transformer based model we tested was able to accurately gender occupation nouns systematically. We release an evaluation scheme and dataset for measuring the ability of transformer based NMT models to translate gender morphology correctly in unambiguous contexts across syntactically diverse sentences. Our dataset translates from an English source into 20 languages from several different language families. With the availability of this dataset, our hope is that the NMT community can iterate on solutions for this class of especially egregious errors.
Sometimes We Want Translationese
Apr 15, 2021
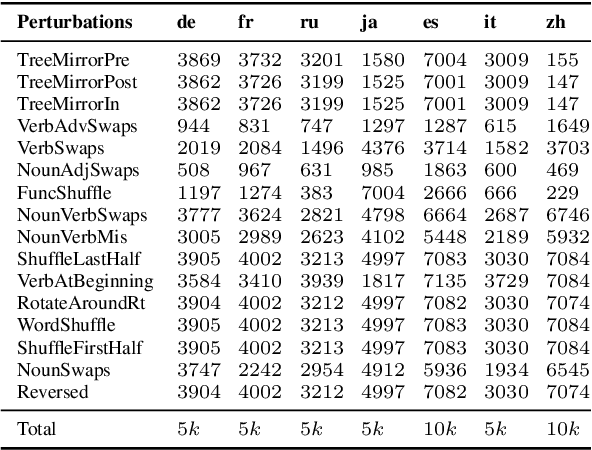

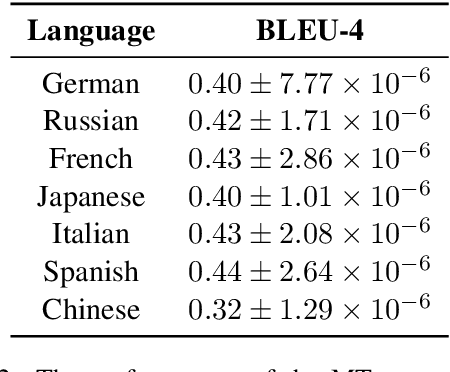
Rapid progress in Neural Machine Translation (NMT) systems over the last few years has been driven primarily towards improving translation quality, and as a secondary focus, improved robustness to input perturbations (e.g. spelling and grammatical mistakes). While performance and robustness are important objectives, by over-focusing on these, we risk overlooking other important properties. In this paper, we draw attention to the fact that for some applications, faithfulness to the original (input) text is important to preserve, even if it means introducing unusual language patterns in the (output) translation. We propose a simple, novel way to quantify whether an NMT system exhibits robustness and faithfulness, focusing on the case of word-order perturbations. We explore a suite of functions to perturb the word order of source sentences without deleting or injecting tokens, and measure the effects on the target side in terms of both robustness and faithfulness. Across several experimental conditions, we observe a strong tendency towards robustness rather than faithfulness. These results allow us to better understand the trade-off between faithfulness and robustness in NMT, and opens up the possibility of developing systems where users have more autonomy and control in selecting which property is best suited for their use case.