 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Old is New Again: Classical Dimensionality Reduction for Efficient Saliency-Guided Biometric Attack Detection
Jun 11, 2026Saliency-guided training is a paradigm in visual recognition that encourages models to focus on the most relevant image regions during learning. While its application in biometric presentation attack detection (PAD) has shown strong benefits in robustness and generalization, adoption is often limited by the high cost, domain specificity, and limited scalability of existing saliency acquisition methods, such as human annotations over a limited dataset. We present a novel, cost-efficient, and highly-scalable approach to saliency acquisition using maps inspired by classical dimensionality reduction techniques: PCA and LDA. Our proposed methods generate saliency maps directly from raw training data, requiring no human annotation nor domain knowledge. We contextualize the effectiveness of these saliency sources in three saliency-explored domains (iris PAD, synthetic face detection, fingerprint PAD) and demonstrate its scalability in two saliency-novel domains (fingerprint vein PAD and ID card PAD). Across all domains tested, models trained using dimensionality reduction-sourced saliency maps exceed baseline and sometimes SOTA saliency methods without any resource investment or domain-specific tooling. Our findings overcome an important yet unaddressed barrier to saliency-guided training for biometric attack detection and beyond.
Emotion is Not Just a Label: Latent Emotional Factors in LLM Processing
Mar 10, 2026Large language models are routinely deployed on text that varies widely in emotional tone, yet their reasoning behavior is typically evaluated without accounting for emotion as a source of representational variation. Prior work has largely treated emotion as a prediction target, for example in sentiment analysis or emotion classification. In contrast, we study emotion as a latent factor that shapes how models attend to and reason over text. We analyze how emotional tone systematically alters attention geometry in transformer models, showing that metrics such as locality, center-of-mass distance, and entropy vary across emotions and correlate with downstream question-answering performance. To facilitate controlled study of these effects, we introduce Affect-Uniform ReAding QA (AURA-QA), a question-answering dataset with emotionally balanced, human-authored context passages. Finally, an emotional regularization framework is proposed that constrains emotion-conditioned representational drift during training. Experiments across multiple QA benchmarks demonstrate that this approach improves reading comprehension in both emotionally-varying and non-emotionally varying datasets, yielding consistent gains under distribution shift and in-domain improvements on several benchmarks.
Saliency-Guided Training for Fingerprint Presentation Attack Detection
May 04, 2025
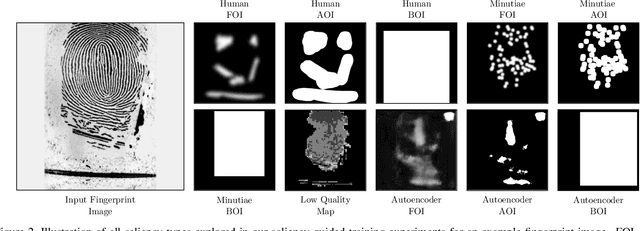


Saliency-guided training, which directs model learning to important regions of images, has demonstrated generalization improvements across various biometric presentation attack detection (PAD) tasks. This paper presents its first application to fingerprint PAD. We conducted a 50-participant study to create a dataset of 800 human-annotated fingerprint perceptually-important maps, explored alongside algorithmically-generated "pseudosaliency," including minutiae-based, image quality-based, and autoencoder-based saliency maps. Evaluating on the 2021 Fingerprint Liveness Detection Competition testing set, we explore various configurations within five distinct training scenarios to assess the impact of saliency-guided training on accuracy and generalization. Our findings demonstrate the effectiveness of saliency-guided training for fingerprint PAD in both limited and large data contexts, and we present a configuration capable of earning the first place on the LivDet-2021 benchmark. Our results highlight saliency-guided training's promise for increased model generalization capabilities, its effectiveness when data is limited, and its potential to scale to larger datasets in fingerprint PAD. All collected saliency data and trained models are released with the paper to support reproducible research.
Grains of Saliency: Optimizing Saliency-based Training of Biometric Attack Detection Models
May 01, 2024



Incorporating human-perceptual intelligence into model training has shown to increase the generalization capability of models in several difficult biometric tasks, such as presentation attack detection (PAD) and detection of synthetic samples. After the initial collection phase, human visual saliency (e.g., eye-tracking data, or handwritten annotations) can be integrated into model training through attention mechanisms, augmented training samples, or through human perception-related components of loss functions. Despite their successes, a vital, but seemingly neglected, aspect of any saliency-based training is the level of salience granularity (e.g., bounding boxes, single saliency maps, or saliency aggregated from multiple subjects) necessary to find a balance between reaping the full benefits of human saliency and the cost of its collection. In this paper, we explore several different levels of salience granularity and demonstrate that increased generalization capabilities of PAD and synthetic face detection can be achieved by using simple yet effective saliency post-processing techniques across several different CNNs.