 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Intermediate Representations for Video Understanding
Apr 14, 2021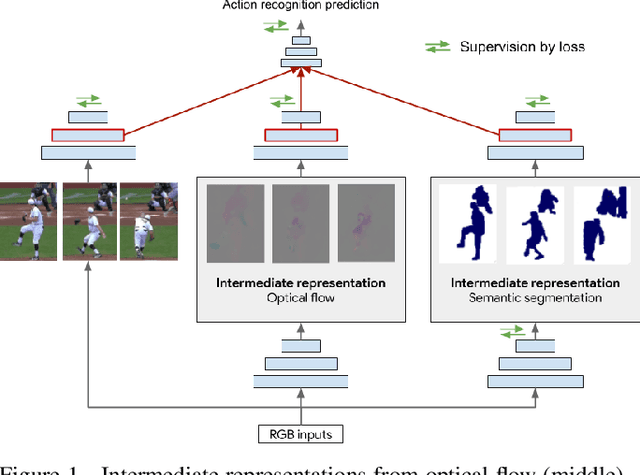
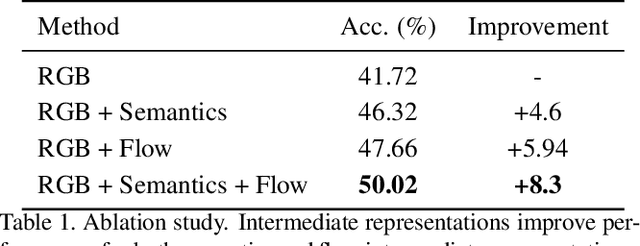
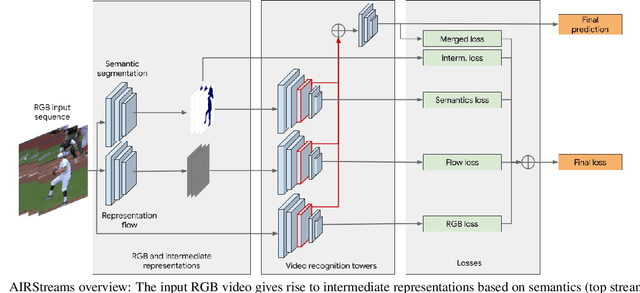
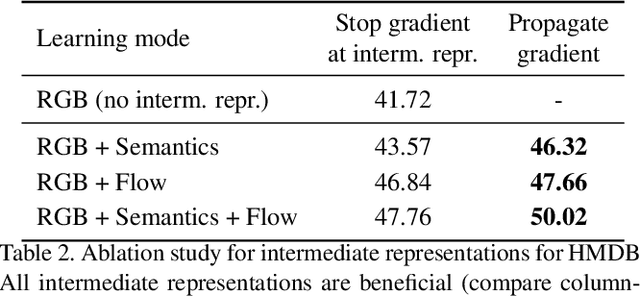
A common strategy to video understanding is to incorporate spatial and motion information by fusing features derived from RGB frames and optical flow. In this work, we introduce a new way to leverage semantic segmentation as an intermediate representation for video understanding and use it in a way that requires no additional labeling. Second, we propose a general framework which learns the intermediate representations (optical flow and semantic segmentation) jointly with the final video understanding task and allows the adaptation of the representations to the end goal. Despite the use of intermediate representations within the network, during inference, no additional data beyond RGB sequences is needed, enabling efficient recognition with a single network. Finally, we present a way to find the optimal learning configuration by searching the best loss weighting via evolution. We obtain more powerful visual representations for videos which lead to performance gains over the state-of-the-art.
Recognizing Actions in Videos from Unseen Viewpoints
Mar 30, 2021
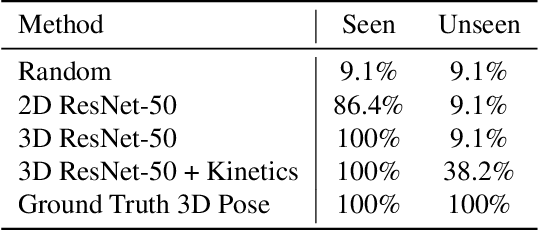
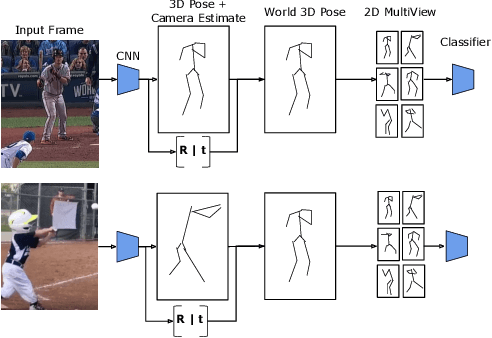
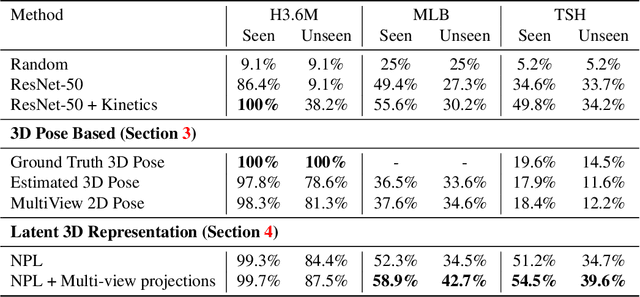
Standard methods for video recognition use large CNNs designed to capture spatio-temporal data. However, training these models requires a large amount of labeled training data, containing a wide variety of actions, scenes, settings and camera viewpoints. In this paper, we show that current convolutional neural network models are unable to recognize actions from camera viewpoints not present in their training data (i.e., unseen view action recognition). To address this, we develop approaches based on 3D representations and introduce a new geometric convolutional layer that can learn viewpoint invariant representations. Further, we introduce a new, challenging dataset for unseen view recognition and show the approaches ability to learn viewpoint invariant representations.
AssembleNet++: Assembling Modality Representations via Attention Connections
Aug 18, 2020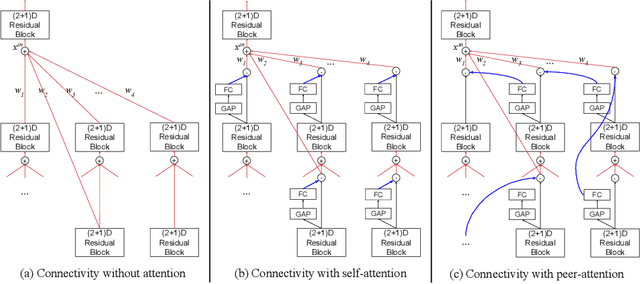
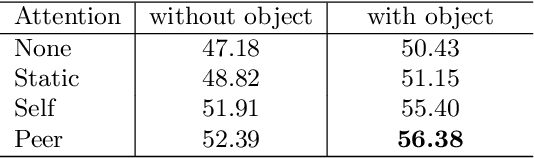
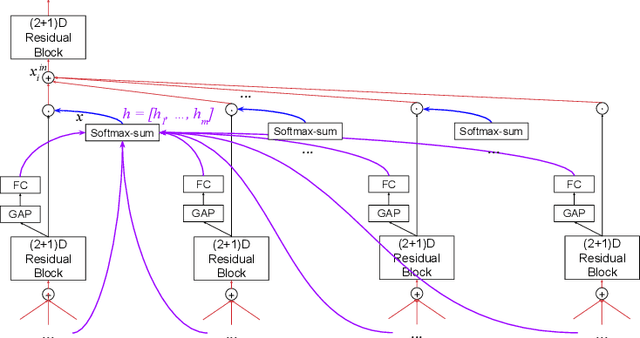
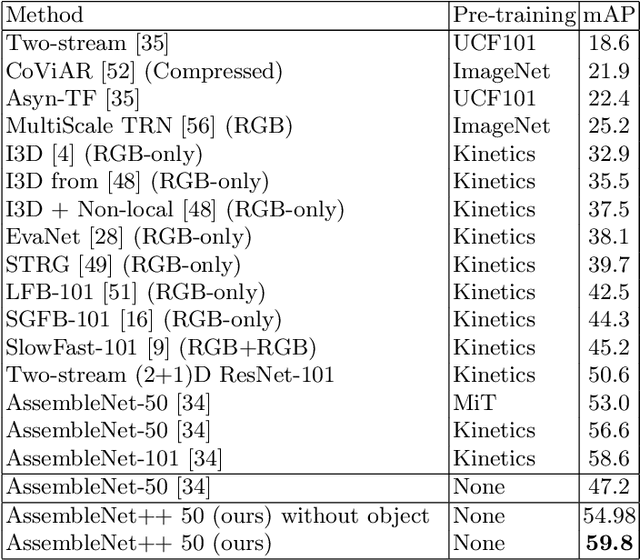
We create a family of powerful video models which are able to: (i) learn interactions between semantic object information and raw appearance and motion features, and (ii) deploy attention in order to better learn the importance of features at each convolutional block of the network. A new network component named peer-attention is introduced, which dynamically learns the attention weights using another block or input modality. Even without pre-training, our models outperform the previous work on standard public activity recognition datasets with continuous videos, establishing new state-of-the-art. We also confirm that our findings of having neural connections from the object modality and the use of peer-attention is generally applicable for different existing architectures, improving their performances. We name our model explicitly as AssembleNet++. The code will be available at: https://sites.google.com/corp/view/assemblenet/
* ECCV 2020 camera-ready version
Adversarial Generative Grammars for Human Activity Prediction
Aug 14, 2020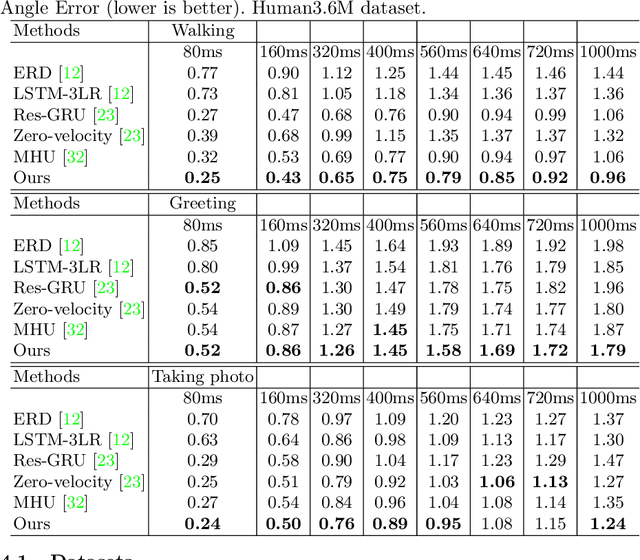
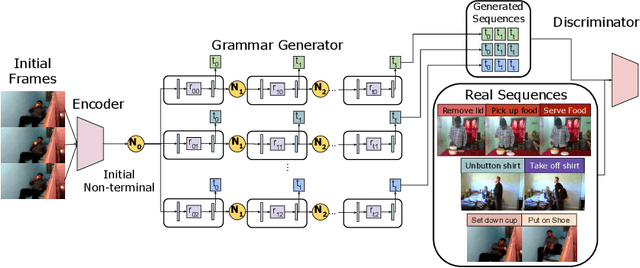
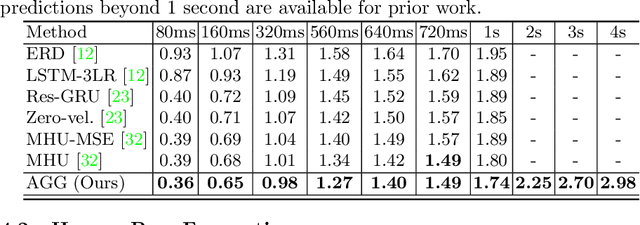
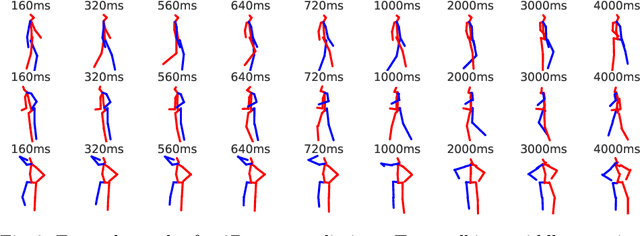
In this paper we propose an adversarial generative grammar model for future prediction. The objective is to learn a model that explicitly captures temporal dependencies, providing a capability to forecast multiple, distinct future activities. Our adversarial grammar is designed so that it can learn stochastic production rules from the data distribution, jointly with its latent non-terminal representations. Being able to select multiple production rules during inference leads to different predicted outcomes, thus efficiently modeling many plausible futures. The adversarial generative grammar is evaluated on the Charades, MultiTHUMOS, Human3.6M, and 50 Salads datasets and on two activity prediction tasks: future 3D human pose prediction and future activity prediction. The proposed adversarial grammar outperforms the state-of-the-art approaches, being able to predict much more accurately and further in the future, than prior work.
AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification
Jul 31, 2020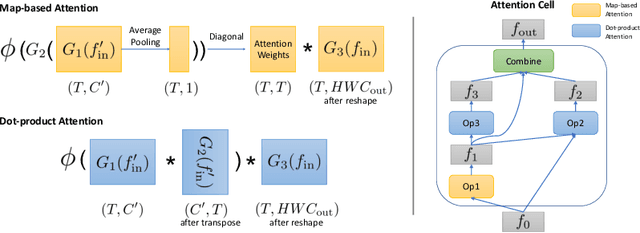
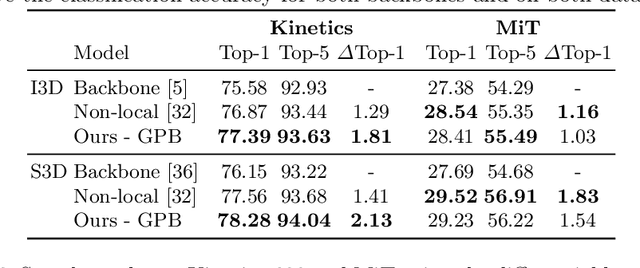
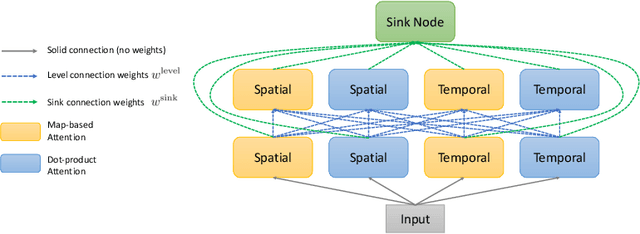
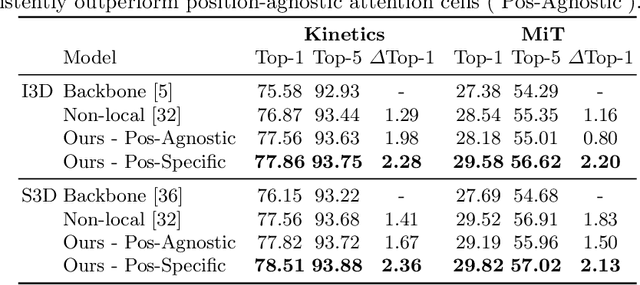
Convolutional operations have two limitations: (1) do not explicitly model where to focus as the same filter is applied to all the positions, and (2) are unsuitable for modeling long-range dependencies as they only operate on a small neighborhood. While both limitations can be alleviated by attention operations, many design choices remain to be determined to use attention, especially when applying attention to videos. Towards a principled way of applying attention to videos, we address the task of spatiotemporal attention cell search. We propose a novel search space for spatiotemporal attention cells, which allows the search algorithm to flexibly explore various design choices in the cell. The discovered attention cells can be seamlessly inserted into existing backbone networks, e.g., I3D or S3D, and improve video classification accuracy by more than 2% on both Kinetics-600 and MiT datasets. The discovered attention cells outperform non-local blocks on both datasets, and demonstrate strong generalization across different modalities, backbones, and datasets. Inserting our attention cells into I3D-R50 yields state-of-the-art performance on both datasets.
AViD Dataset: Anonymized Videos from Diverse Countries
Jul 10, 2020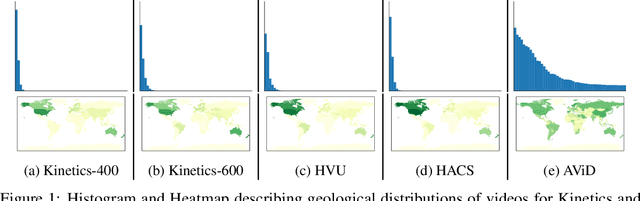
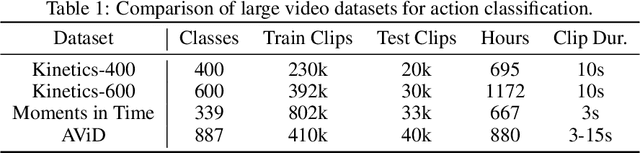

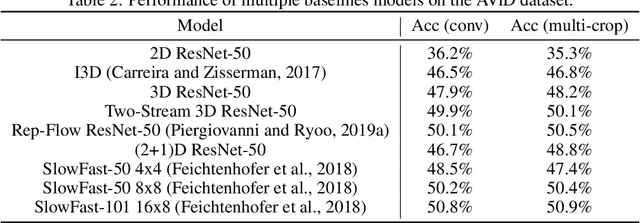
We introduce a new public video dataset for action recognition: Anonymized Videos from Diverse countries (AViD). Unlike existing public video datasets, AViD is a collection of action videos from many different countries. The motivation is to create a public dataset that would benefit training and pretraining of action recognition models for everybody, rather than making it useful for limited countries. Further, all the face identities in the AViD videos are properly anonymized to protect their privacy. It also is a static dataset where each video is licensed with the creative commons license. We confirm that most of the existing video datasets are statistically biased to only capture action videos from a limited number of countries. We experimentally illustrate that models trained with such biased datasets do not transfer perfectly to action videos from the other countries, and show that AViD addresses such problem. We also confirm that the new AViD dataset could serve as a good dataset for pretraining the models, performing comparably or better than prior datasets.
Evolving Losses for Unsupervised Video Representation Learning
Feb 26, 2020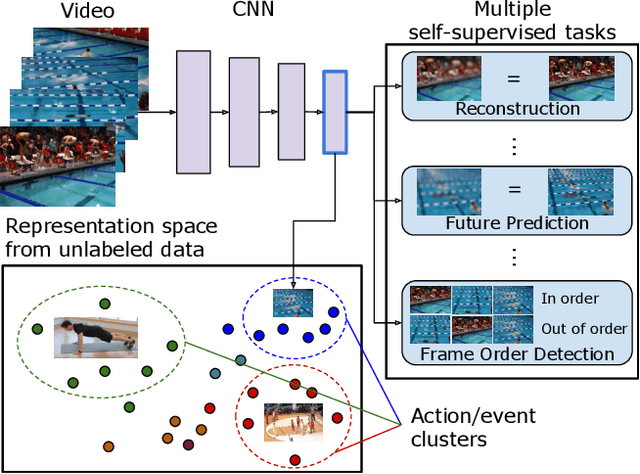
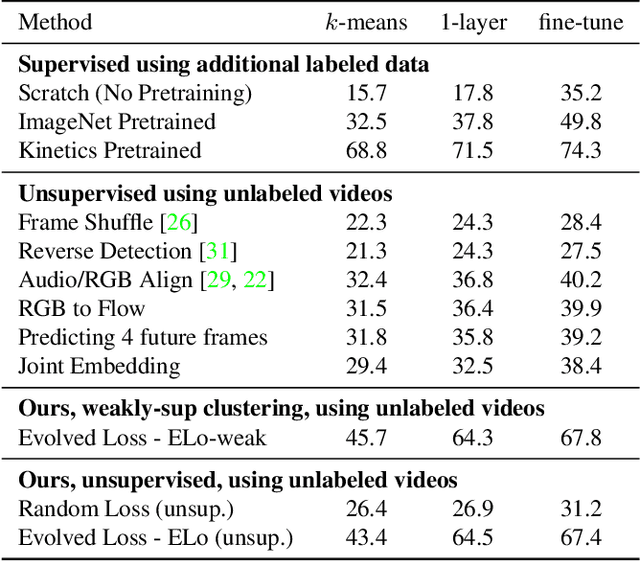
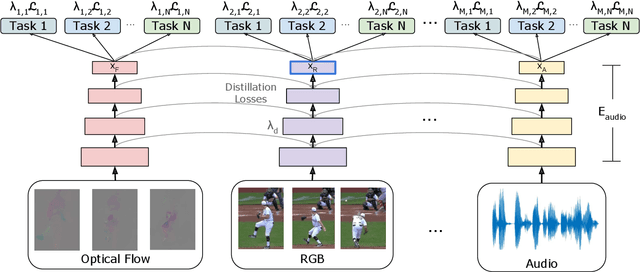
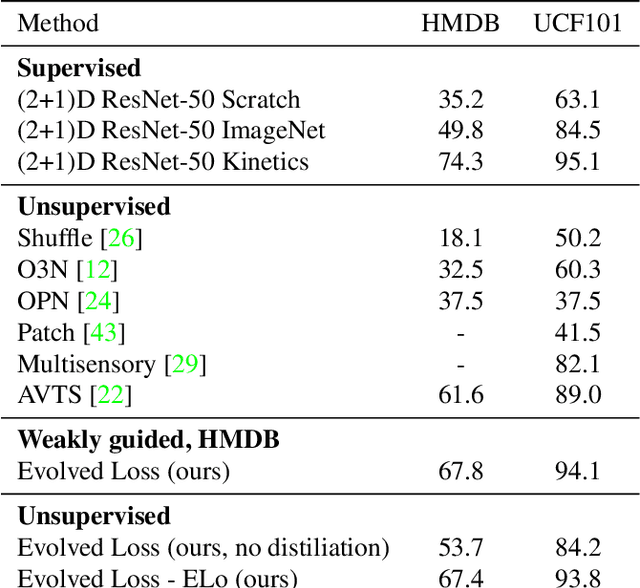
We present a new method to learn video representations from large-scale unlabeled video data. Ideally, this representation will be generic and transferable, directly usable for new tasks such as action recognition and zero or few-shot learning. We formulate unsupervised representation learning as a multi-modal, multi-task learning problem, where the representations are shared across different modalities via distillation. Further, we introduce the concept of loss function evolution by using an evolutionary search algorithm to automatically find optimal combination of loss functions capturing many (self-supervised) tasks and modalities. Thirdly, we propose an unsupervised representation evaluation metric using distribution matching to a large unlabeled dataset as a prior constraint, based on Zipf's law. This unsupervised constraint, which is not guided by any labeling, produces similar results to weakly-supervised, task-specific ones. The proposed unsupervised representation learning results in a single RGB network and outperforms previous methods. Notably, it is also more effective than several label-based methods (e.g., ImageNet), with the exception of large, fully labeled video datasets.
* arXiv admin note: text overlap with arXiv:1906.03248
Tiny Video Networks
Oct 15, 2019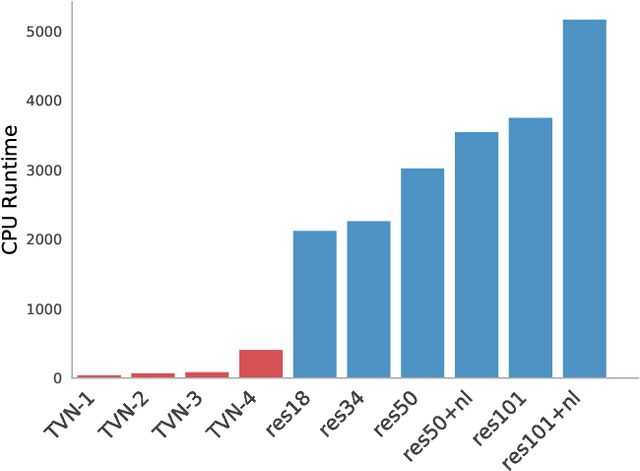
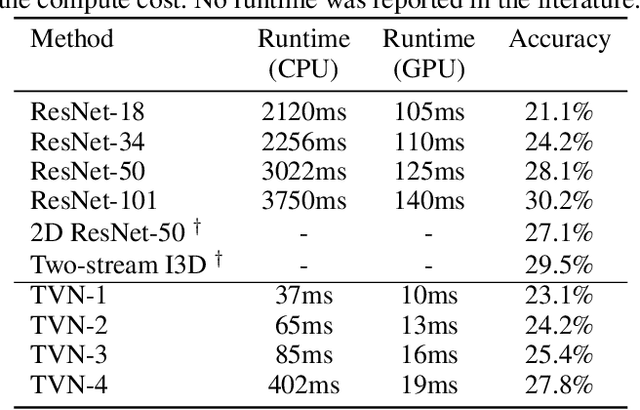
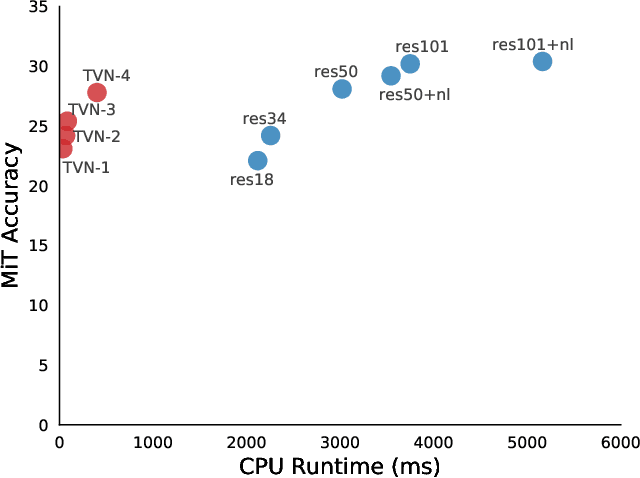

Video understanding is a challenging problem with great impact on the abilities of autonomous agents working in the real-world. Yet, solutions so far have been computationally intensive, with the fastest algorithms running for more than half a second per video snippet on powerful GPUs. We propose a novel idea on video architecture learning - Tiny Video Networks - which automatically designs highly efficient models for video understanding. The tiny video models run with competitive performance for as low as 37 milliseconds per video on a CPU and 10 milliseconds on a standard GPU.
Model-based Behavioral Cloning with Future Image Similarity Learning
Oct 08, 2019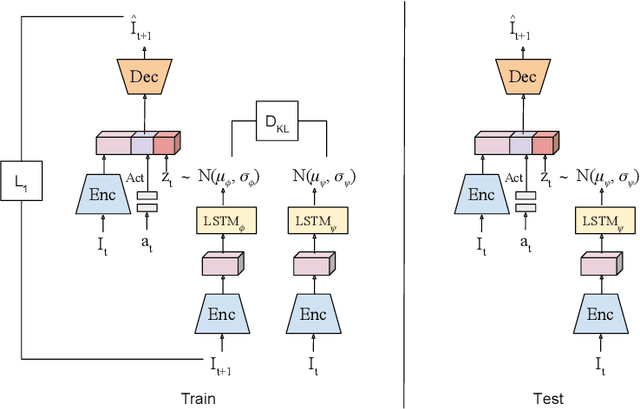


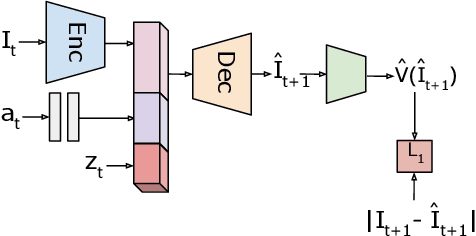
We present a visual imitation learning framework that enables learning of robot action policies solely based on expert samples without any robot trials. Robot exploration and on-policy trials in a real-world environment could often be expensive/dangerous. We present a new approach to address this problem by learning a future scene prediction model solely on a collection of expert trajectories consisting of unlabeled example videos and actions, and by enabling generalized action cloning using future image similarity. The robot learns to visually predict the consequences of taking an action, and obtains the policy by evaluating how similar the predicted future image is to an expert image. We develop a stochastic action-conditioned convolutional autoencoder, and present how we take advantage of future images for robot learning. We conduct experiments in simulated and real-life environments using a ground mobility robot with and without obstacles, and compare our models to multiple baseline methods.
Evolving Losses for Unlabeled Video Representation Learning
Jun 07, 2019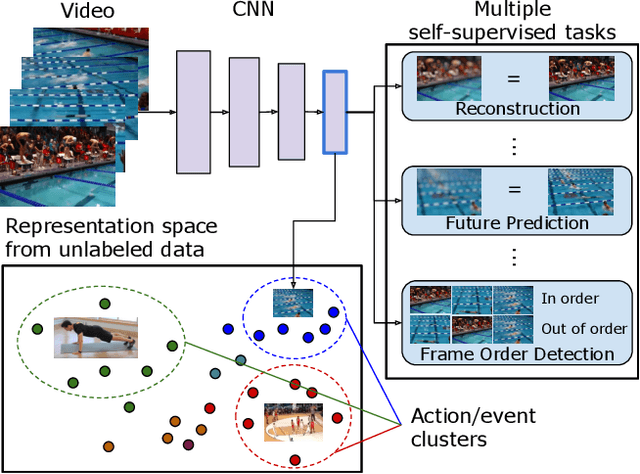
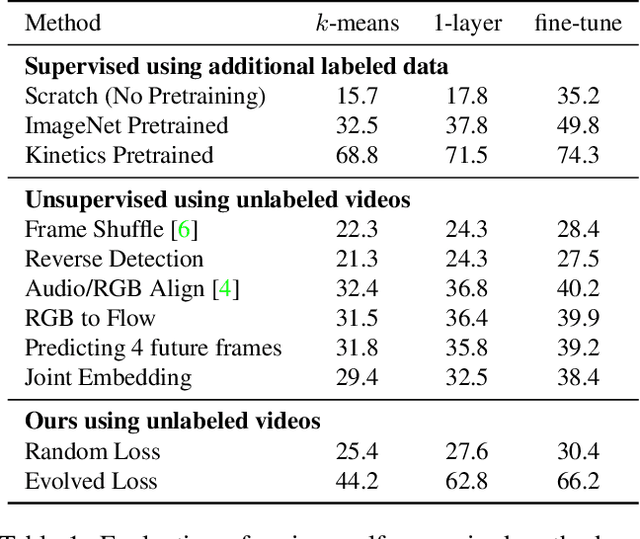
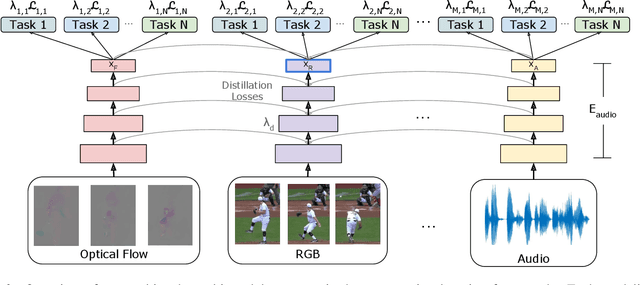
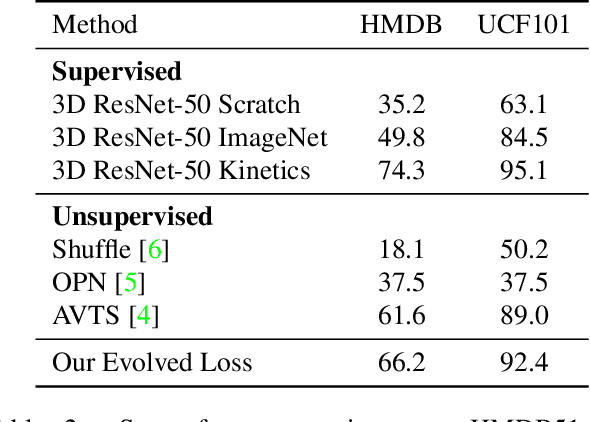
We present a new method to learn video representations from unlabeled data. Given large-scale unlabeled video data, the objective is to benefit from such data by learning a generic and transferable representation space that can be directly used for a new task such as zero/few-shot learning. We formulate our unsupervised representation learning as a multi-modal, multi-task learning problem, where the representations are also shared across different modalities via distillation. Further, we also introduce the concept of finding a better loss function to train such multi-task multi-modal representation space using an evolutionary algorithm; our method automatically searches over different combinations of loss functions capturing multiple (self-supervised) tasks and modalities. Our formulation allows for the distillation of audio, optical flow and temporal information into a single, RGB-based convolutional neural network. We also compare the effects of using additional unlabeled video data and evaluate our representation learning on standard public video datasets.