 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Recurrent Variational Autoencoder for Speech Enhancement
Oct 24, 2019
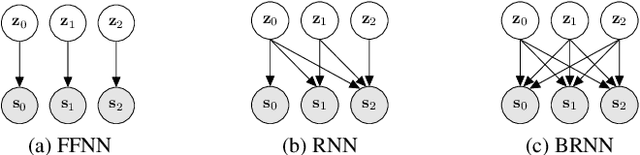
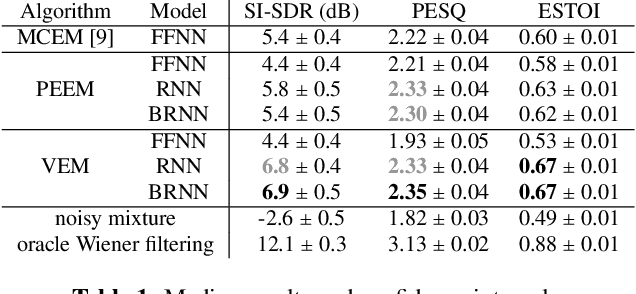
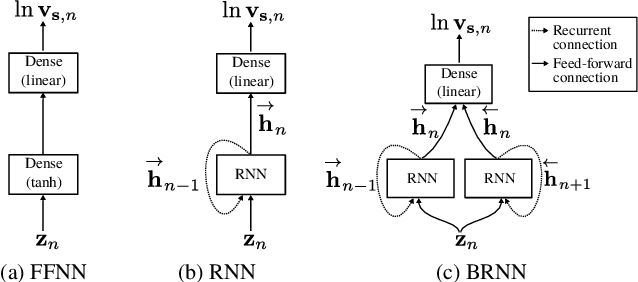
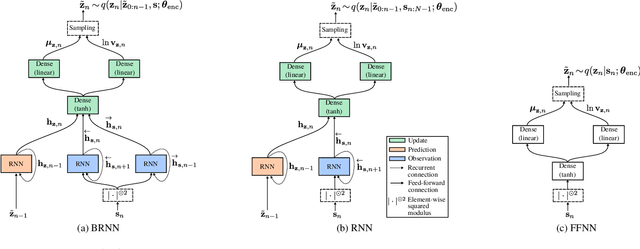
This paper presents a generative approach to speech enhancement based on a recurrent variational autoencoder (RVAE). The deep generative speech model is trained using clean speech signals only, and it is combined with a nonnegative matrix factorization noise model for speech enhancement. We propose a variational expectation-maximization algorithm where the encoder of the RVAE is fine-tuned at test time, to approximate the distribution of the latent variables given the noisy speech observations. Compared with previous approaches based on feed-forward fully-connected architectures, the proposed recurrent deep generative speech model induces a posterior temporal dynamic over the latent variables, which is shown to improve the speech enhancement results.
DeepFry: Identifying Vocal Fry Using Deep Neural Networks
Mar 31, 2022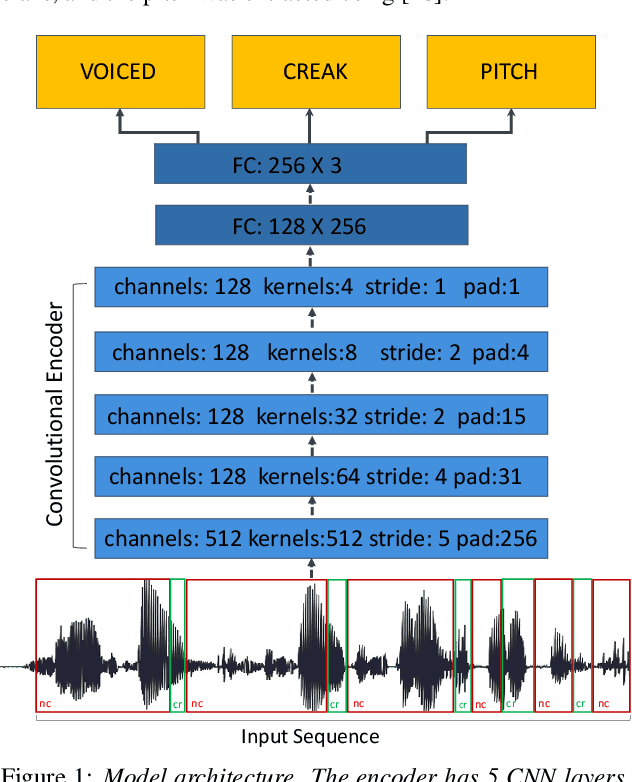
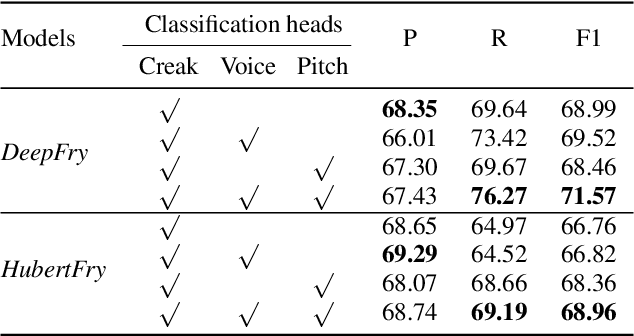

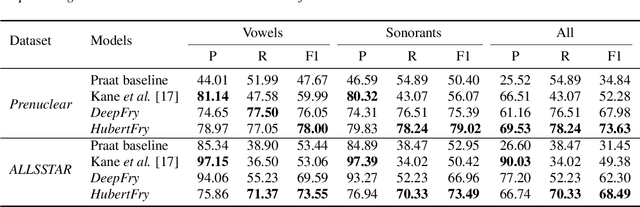
Vocal fry or creaky voice refers to a voice quality characterized by irregular glottal opening and low pitch. It occurs in diverse languages and is prevalent in American English, where it is used not only to mark phrase finality, but also sociolinguistic factors and affect. Due to its irregular periodicity, creaky voice challenges automatic speech processing and recognition systems, particularly for languages where creak is frequently used. This paper proposes a deep learning model to detect creaky voice in fluent speech. The model is composed of an encoder and a classifier trained together. The encoder takes the raw waveform and learns a representation using a convolutional neural network. The classifier is implemented as a multi-headed fully-connected network trained to detect creaky voice, voicing, and pitch, where the last two are used to refine creak prediction. The model is trained and tested on speech of American English speakers, annotated for creak by trained phoneticians. We evaluated the performance of our system using two encoders: one is tailored for the task, and the other is based on a state-of-the-art unsupervised representation. Results suggest our best-performing system has improved recall and F1 scores compared to previous methods on unseen data.
Data Expansion using Back Translation and Paraphrasing for Hate Speech Detection
May 25, 2021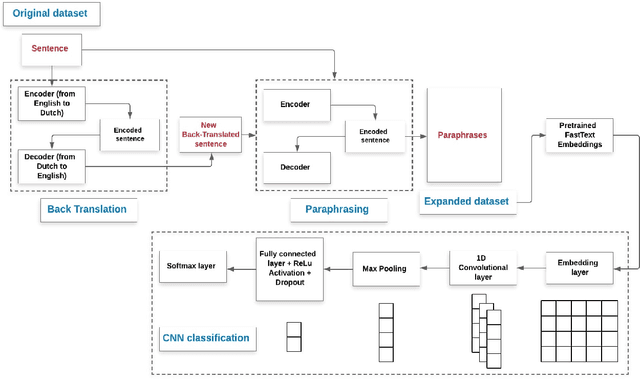
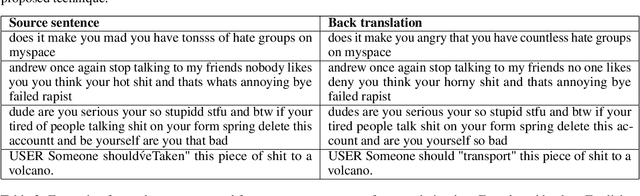
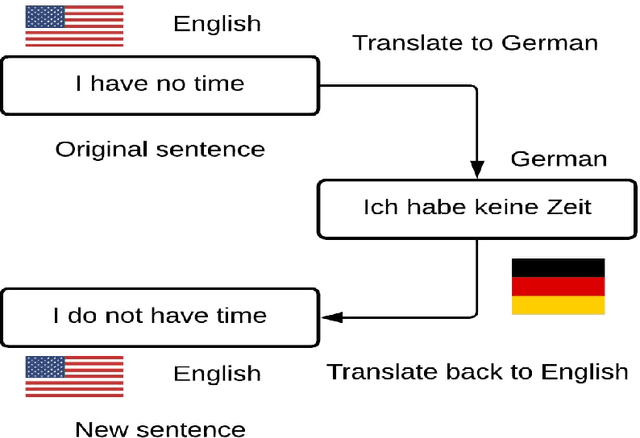
With proliferation of user generated contents in social media platforms, establishing mechanisms to automatically identify toxic and abusive content becomes a prime concern for regulators, researchers, and society. Keeping the balance between freedom of speech and respecting each other dignity is a major concern of social media platform regulators. Although, automatic detection of offensive content using deep learning approaches seems to provide encouraging results, training deep learning-based models requires large amounts of high-quality labeled data, which is often missing. In this regard, we present in this paper a new deep learning-based method that fuses a Back Translation method, and a Paraphrasing technique for data augmentation. Our pipeline investigates different word-embedding-based architectures for classification of hate speech. The back translation technique relies on an encoder-decoder architecture pre-trained on a large corpus and mostly used for machine translation. In addition, paraphrasing exploits the transformer model and the mixture of experts to generate diverse paraphrases. Finally, LSTM, and CNN are compared to seek enhanced classification results. We evaluate our proposal on five publicly available datasets; namely, AskFm corpus, Formspring dataset, Warner and Waseem dataset, Olid, and Wikipedia toxic comments dataset. The performance of the proposal together with comparison to some related state-of-art results demonstrate the effectiveness and soundness of our proposal.
Adjust-free adversarial example generation in speech recognition using evolutionary multi-objective optimization under black-box condition
Dec 22, 2020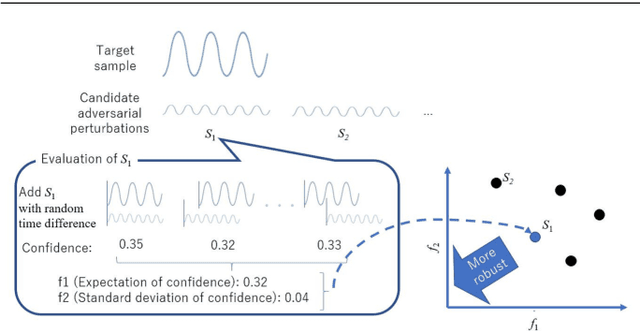


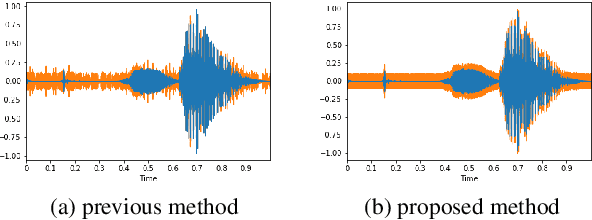
This paper proposes a black-box adversarial attack method to automatic speech recognition systems. Some studies have attempted to attack neural networks for speech recognition; however, these methods did not consider the robustness of generated adversarial examples against timing lag with a target speech. The proposed method in this paper adopts Evolutionary Multi-objective Optimization (EMO)that allows it generating robust adversarial examples under black-box scenario. Experimental results showed that the proposed method successfully generated adjust-free adversarial examples, which are sufficiently robust against timing lag so that an attacker does not need to take the timing of playing it against the target speech.
Emotion-Controllable Generalized Talking Face Generation
May 02, 2022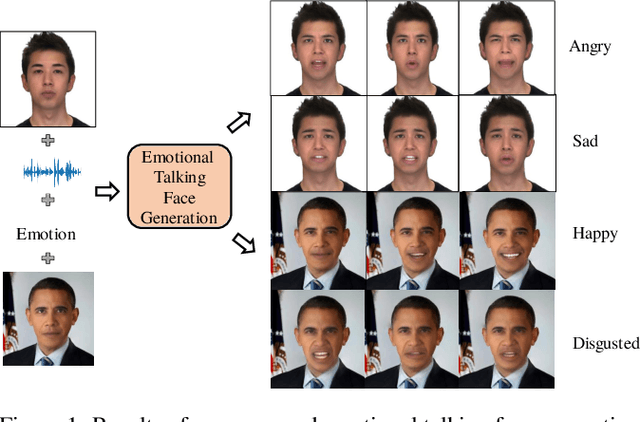
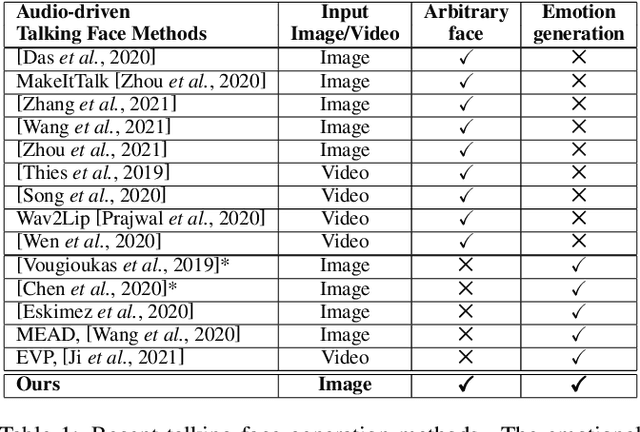
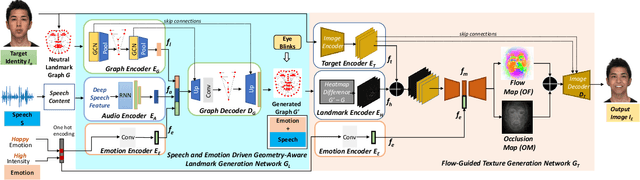

Despite the significant progress in recent years, very few of the AI-based talking face generation methods attempt to render natural emotions. Moreover, the scope of the methods is majorly limited to the characteristics of the training dataset, hence they fail to generalize to arbitrary unseen faces. In this paper, we propose a one-shot facial geometry-aware emotional talking face generation method that can generalize to arbitrary faces. We propose a graph convolutional neural network that uses speech content feature, along with an independent emotion input to generate emotion and speech-induced motion on facial geometry-aware landmark representation. This representation is further used in our optical flow-guided texture generation network for producing the texture. We propose a two-branch texture generation network, with motion and texture branches designed to consider the motion and texture content independently. Compared to the previous emotion talking face methods, our method can adapt to arbitrary faces captured in-the-wild by fine-tuning with only a single image of the target identity in neutral emotion.
Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition
Feb 14, 2021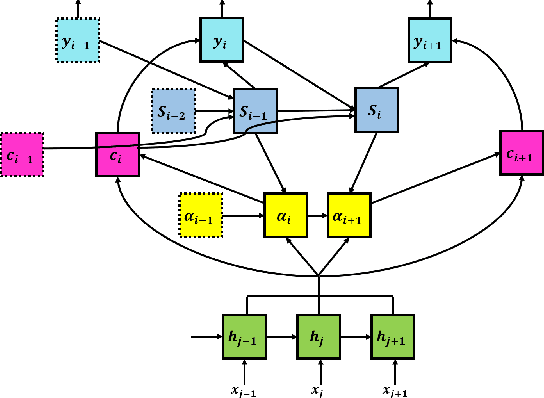
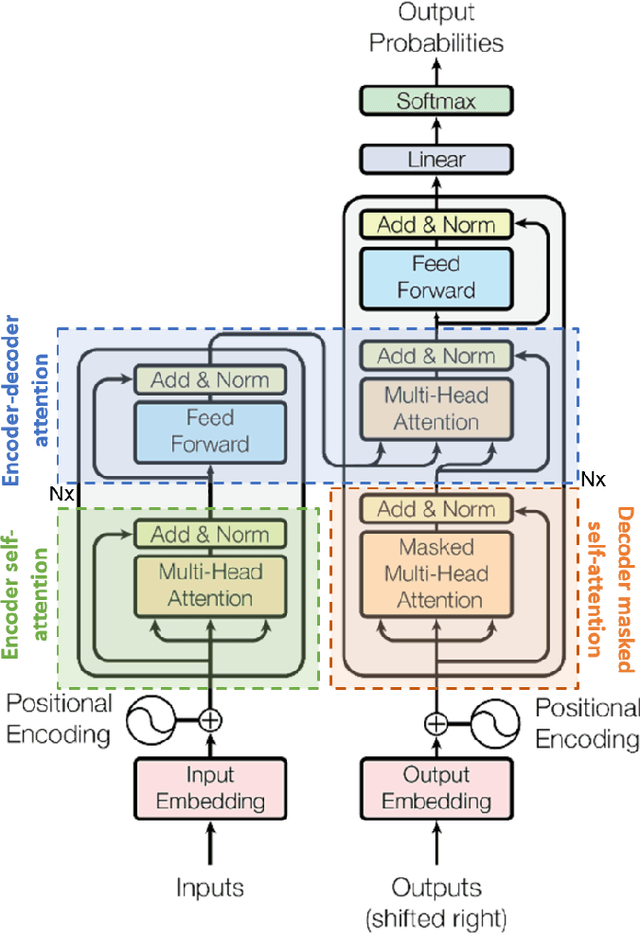
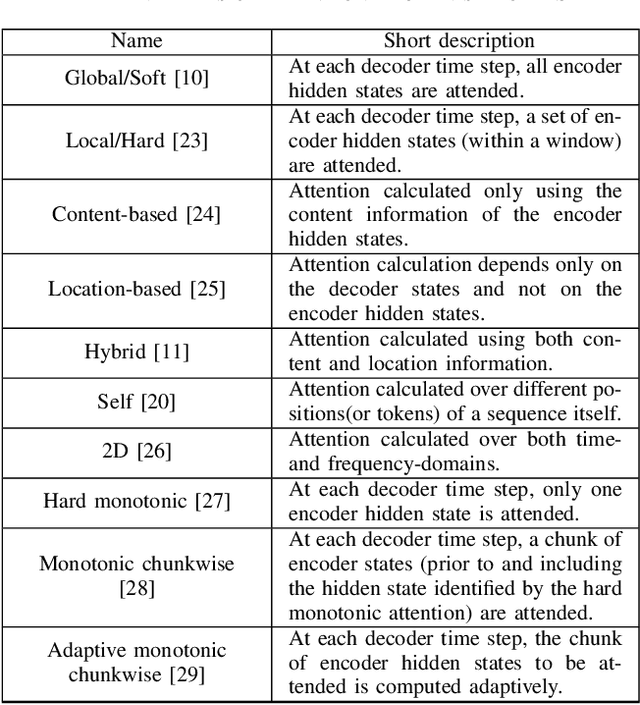
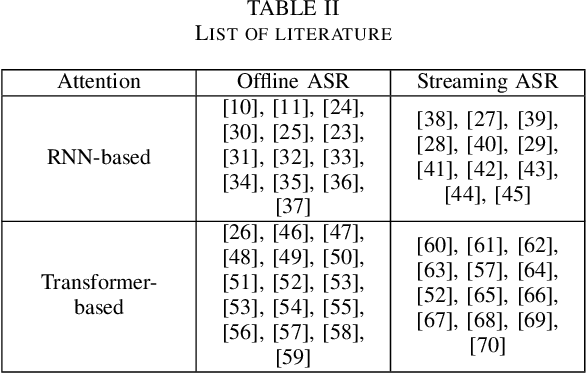
Attention is a very popular and effective mechanism in artificial neural network-based sequence-to-sequence models. In this survey paper, a comprehensive review of the different attention models used in developing automatic speech recognition systems is provided. The paper focuses on the development and evolution of attention models for offline and streaming speech recognition within recurrent neural network- and Transformer- based architectures.
Enhance Language Identification using Dual-mode Model with Knowledge Distillation
Mar 07, 2022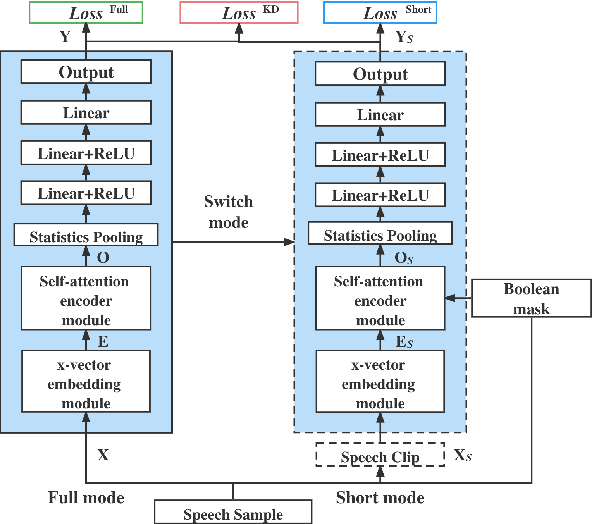
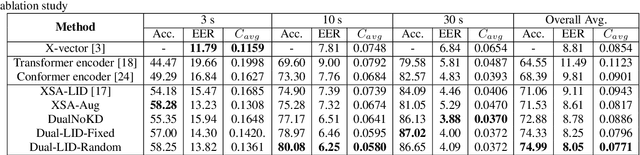

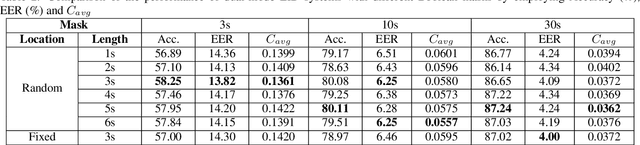
In this paper, we propose to employ a dual-mode framework on the x-vector self-attention (XSA-LID) model with knowledge distillation (KD) to enhance its language identification (LID) performance for both long and short utterances. The dual-mode XSA-LID model is trained by jointly optimizing both the full and short modes with their respective inputs being the full-length speech and its short clip extracted by a specific Boolean mask, and KD is applied to further boost the performance on short utterances. In addition, we investigate the impact of clip-wise linguistic variability and lexical integrity for LID by analyzing the variation of LID performance in terms of the lengths and positions of the mimicked speech clips. We evaluated our approach on the MLS14 data from the NIST 2017 LRE. With the 3~s random-location Boolean mask, our proposed method achieved 19.23%, 21.52% and 8.37% relative improvement in average cost compared with the XSA-LID model on 3s, 10s, and 30s speech, respectively.
Complex Spectral Mapping With Attention Based Convolution Recrrent Neural Network for Speech Enhancement
Apr 12, 2021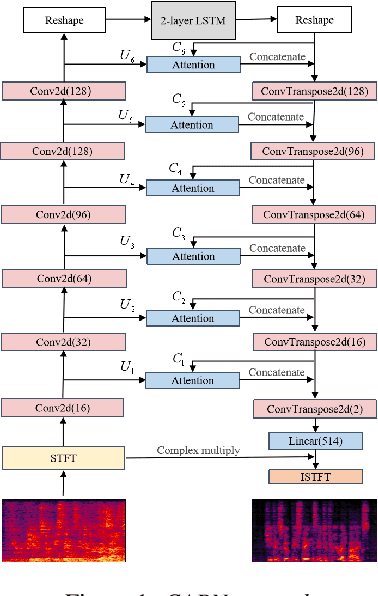
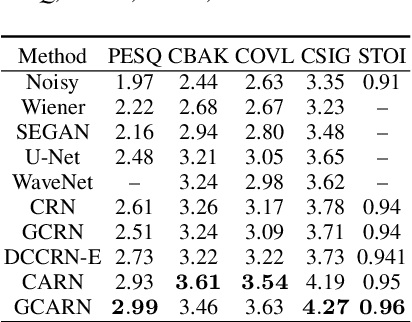
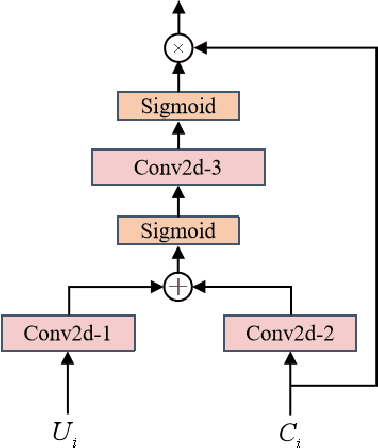
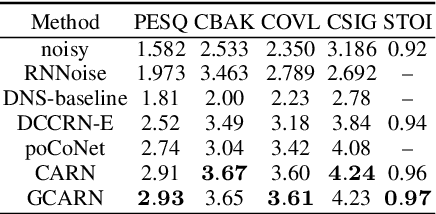
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.
FaceFilter: Audio-visual speech separation using still images
May 14, 2020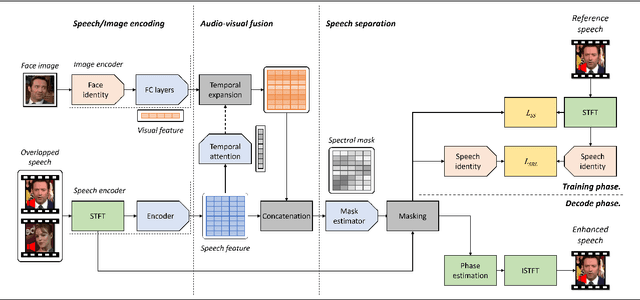
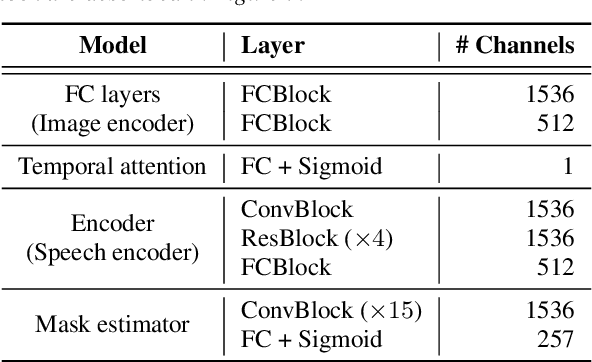
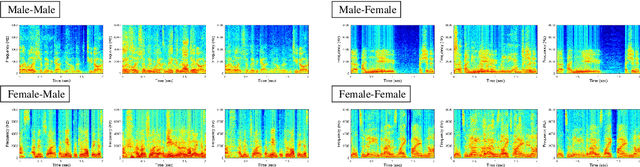
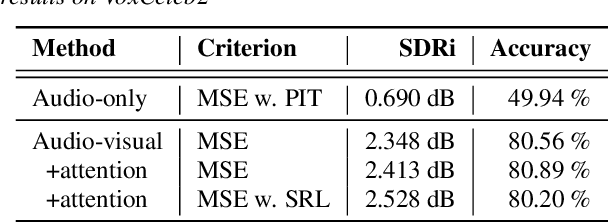
The objective of this paper is to separate a target speaker's speech from a mixture of two speakers using a deep audio-visual speech separation network. Unlike previous works that used lip movement on video clips or pre-enrolled speaker information as an auxiliary conditional feature, we use a single face image of the target speaker. In this task, the conditional feature is obtained from facial appearance in cross-modal biometric task, where audio and visual identity representations are shared in latent space. Learnt identities from facial images enforce the network to isolate matched speakers and extract the voices from mixed speech. It solves the permutation problem caused by swapped channel outputs, frequently occurred in speech separation tasks. The proposed method is far more practical than video-based speech separation since user profile images are readily available on many platforms. Also, unlike speaker-aware separation methods, it is applicable on separation with unseen speakers who have never been enrolled before. We show strong qualitative and quantitative results on challenging real-world examples.
Space-Efficient Representation of Entity-centric Query Language Models
Jun 29, 2022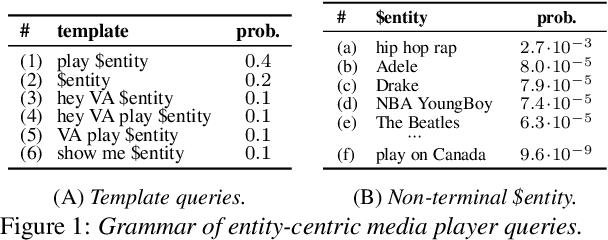

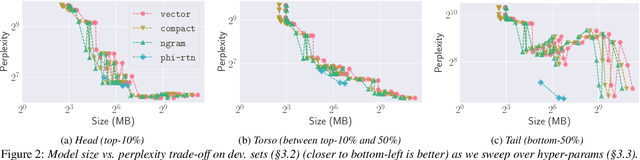
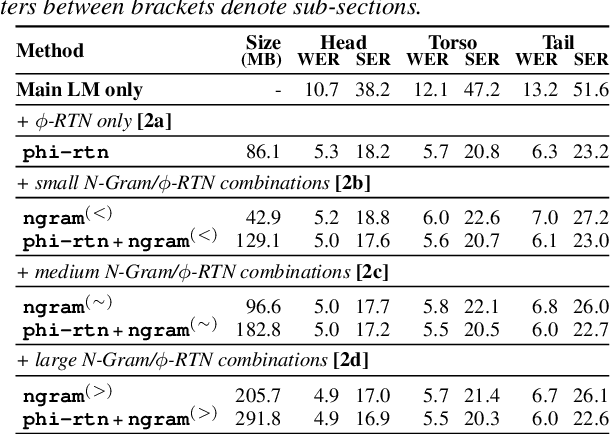
Virtual assistants make use of automatic speech recognition (ASR) to help users answer entity-centric queries. However, spoken entity recognition is a difficult problem, due to the large number of frequently-changing named entities. In addition, resources available for recognition are constrained when ASR is performed on-device. In this work, we investigate the use of probabilistic grammars as language models within the finite-state transducer (FST) framework. We introduce a deterministic approximation to probabilistic grammars that avoids the explicit expansion of non-terminals at model creation time, integrates directly with the FST framework, and is complementary to n-gram models. We obtain a 10% relative word error rate improvement on long tail entity queries compared to when a similarly-sized n-gram model is used without our method.