 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Private Speech Characterization with Secure Multiparty Computation
Jul 01, 2020
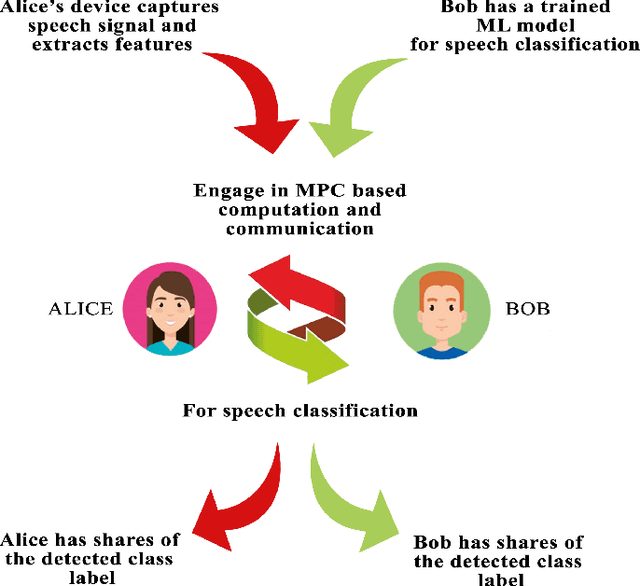

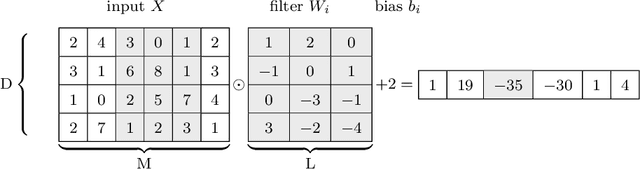
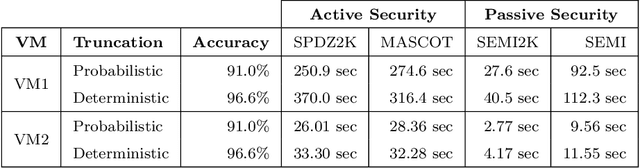
Deep learning in audio signal processing, such as human voice audio signal classification, is a rich application area of machine learning. Legitimate use cases include voice authentication, gunfire detection, and emotion recognition. While there are clear advantages to automated human speech classification, application developers can gain knowledge beyond the professed scope from unprotected audio signal processing. In this paper we propose the first privacy-preserving solution for deep learning-based audio classification that is provably secure. Our approach, which is based on Secure Multiparty Computation, allows to classify a speech signal of one party (Alice) with a deep neural network of another party (Bob) without Bob ever seeing Alice's speech signal in an unencrypted manner. As threat models, we consider both passive security, i.e. with semi-honest parties who follow the instructions of the cryptographic protocols, as well as active security, i.e. with malicious parties who deviate from the protocols. We evaluate the efficiency-security-accuracy trade-off of the proposed solution in a use case for privacy-preserving emotion detection from speech with a convolutional neural network. In the semi-honest case we can classify a speech signal in under 0.3 sec; in the malicious case it takes $\sim$1.6 sec. In both cases there is no leakage of information, and we achieve classification accuracies that are the same as when computations are done on unencrypted data.
Unsupervised Word Segmentation using K Nearest Neighbors
Apr 27, 2022
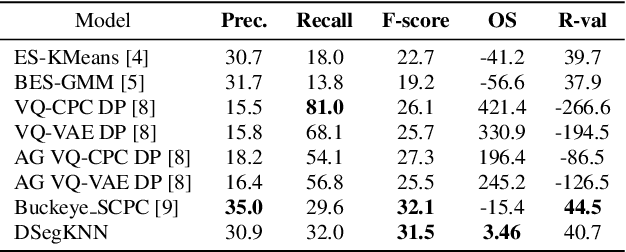
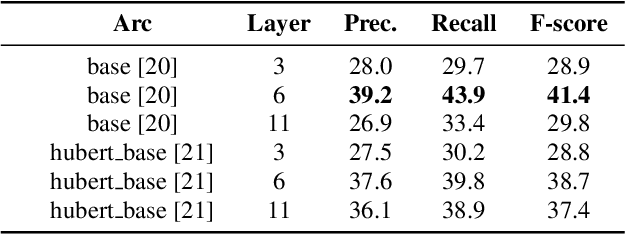
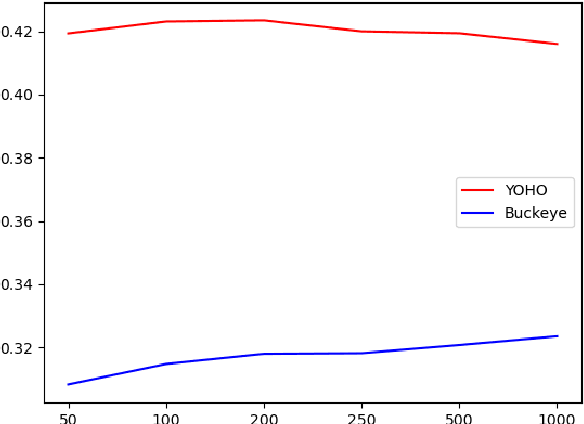
In this paper, we propose an unsupervised kNN-based approach for word segmentation in speech utterances. Our method relies on self-supervised pre-trained speech representations, and compares each audio segment of a given utterance to its K nearest neighbors within the training set. Our main assumption is that a segment containing more than one word would occur less often than a segment containing a single word. Our method does not require phoneme discovery and is able to operate directly on pre-trained audio representations. This is in contrast to current methods that use a two-stage approach; first detecting the phonemes in the utterance and then detecting word-boundaries according to statistics calculated on phoneme patterns. Experiments on two datasets demonstrate improved results over previous single-stage methods and competitive results on state-of-the-art two-stage methods.
A Large-scale Dataset for Hate Speech Detection on Vietnamese Social Media Texts
Mar 29, 2021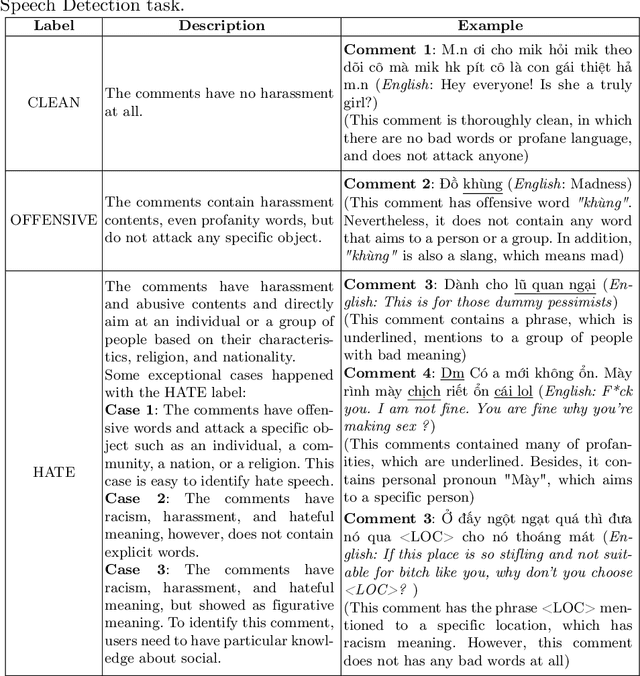
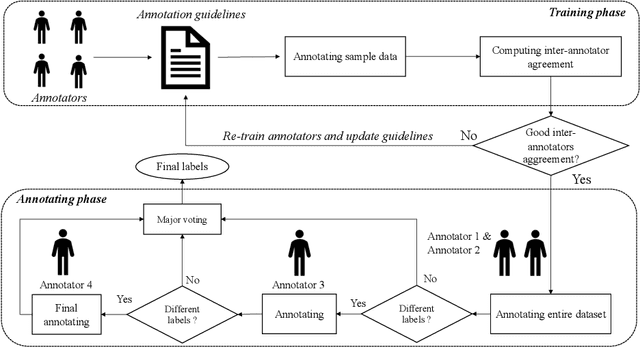
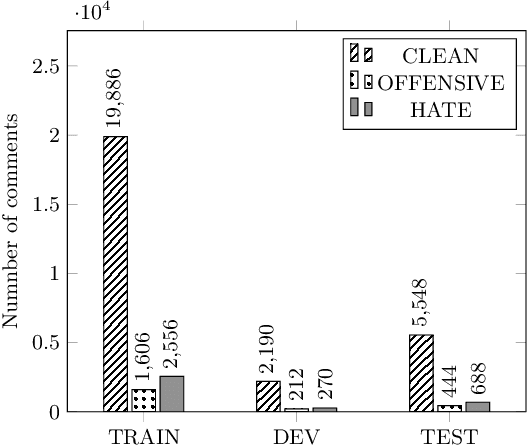

In recent years, Vietnam witnesses the mass development of social network users on different social platforms such as Facebook, Youtube, Instagram, and Tiktok. On social medias, hate speech has become a critical problem for social network users. To solve this problem, we introduce the ViHSD - a human-annotated dataset for automatically detecting hate speech on the social network. This dataset contains over 30,000 comments, each comment in the dataset has one of three labels: CLEAN, OFFENSIVE, or HATE. Besides, we introduce the data creation process for annotating and evaluating the quality of the dataset. Finally, we evaluated the dataset by deep learning models and transformer models.
Continuous Silent Speech Recognition using EEG
Mar 15, 2020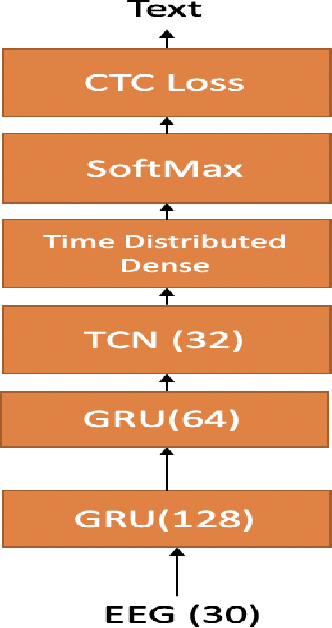
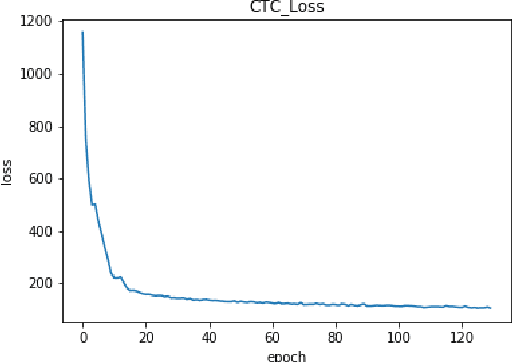
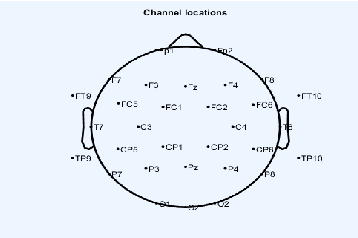
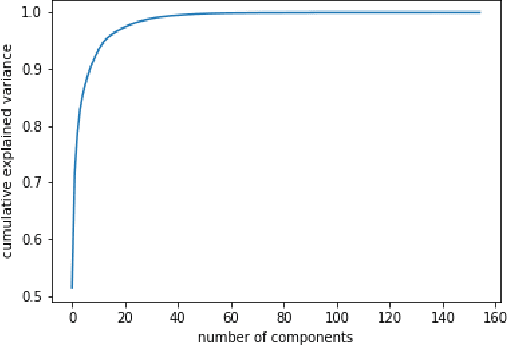
In this paper we explore continuous silent speech recognition using electroencephalography (EEG) signals. We implemented a connectionist temporal classification (CTC) automatic speech recognition (ASR) model to translate EEG signals recorded in parallel while subjects were reading English sentences in their mind without producing any voice to text. Our results demonstrate the feasibility of using EEG signals for performing continuous silent speech recognition. We demonstrate our results for a limited English vocabulary consisting of 30 unique sentences.
Multi-Task Learning with Sentiment, Emotion, and Target Detection to Recognize Hate Speech and Offensive Language
Oct 13, 2021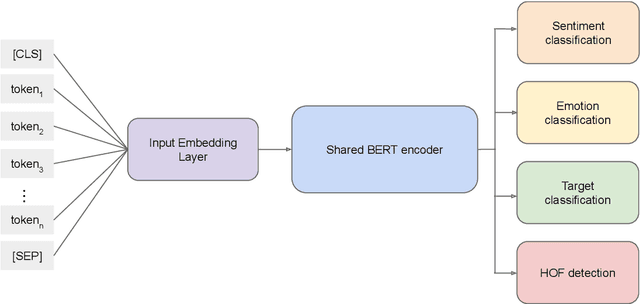
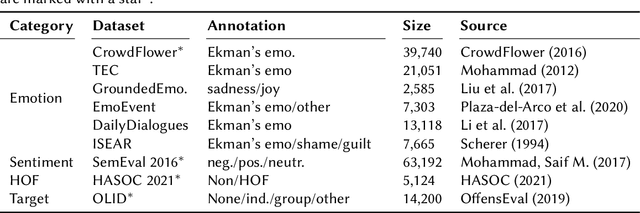
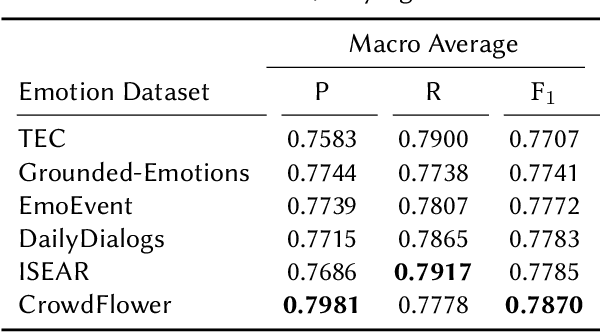
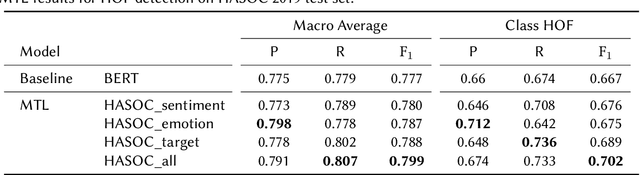
The recognition of hate speech and offensive language (HOF) is commonly formulated as a classification task to decide if a text contains HOF. We investigate whether HOF detection can profit by taking into account the relationships between HOF and similar concepts: (a) HOF is related to sentiment analysis because hate speech is typically a negative statement and expresses a negative opinion; (b) it is related to emotion analysis, as expressed hate points to the author experiencing (or pretending to experience) anger while the addressees experience (or are intended to experience) fear. (c) Finally, one constituting element of HOF is the mention of a targeted person or group. On this basis, we hypothesize that HOF detection shows improvements when being modeled jointly with these concepts, in a multi-task learning setup. We base our experiments on existing data sets for each of these concepts (sentiment, emotion, target of HOF) and evaluate our models as a participant (as team IMS-SINAI) in the HASOC FIRE 2021 English Subtask 1A. Based on model-selection experiments in which we consider multiple available resources and submissions to the shared task, we find that the combination of the CrowdFlower emotion corpus, the SemEval 2016 Sentiment Corpus, and the OffensEval 2019 target detection data leads to an F1 =.79 in a multi-head multi-task learning model based on BERT, in comparison to .7895 of plain BERT. On the HASOC 2019 test data, this result is more substantial with an increase by 2pp in F1 and a considerable increase in recall. Across both data sets (2019, 2021), the recall is particularly increased for the class of HOF (6pp for the 2019 data and 3pp for the 2021 data), showing that MTL with emotion, sentiment, and target identification is an appropriate approach for early warning systems that might be deployed in social media platforms.
Adversarial Joint Training with Self-Attention Mechanism for Robust End-to-End Speech Recognition
Apr 03, 2021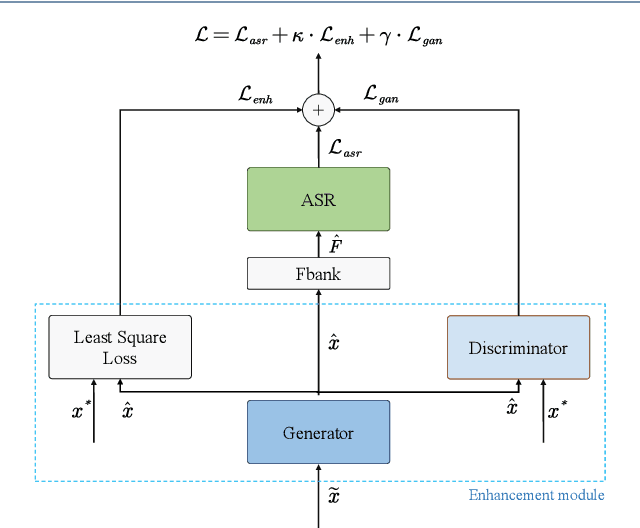

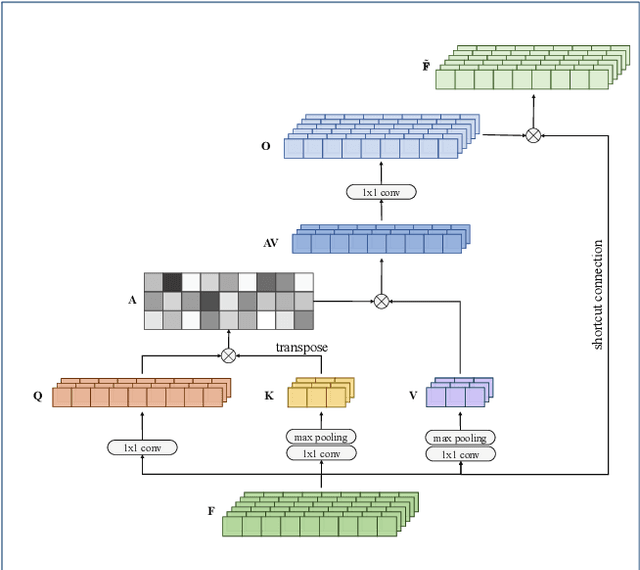
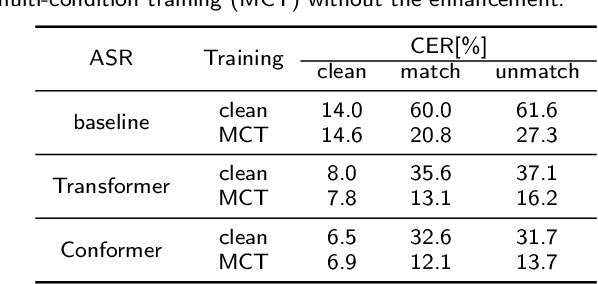
Lately, the self-attention mechanism has marked a new milestone in the field of automatic speech recognition (ASR). Nevertheless, its performance is susceptible to environmental intrusions as the system predicts the next output symbol depending on the full input sequence and the previous predictions. Inspired by the extensive applications of the generative adversarial networks (GANs) in speech enhancement and ASR tasks, we propose an adversarial joint training framework with the self-attention mechanism to boost the noise robustness of the ASR system. Generally, it consists of a self-attention speech enhancement GAN and a self-attention end-to-end ASR model. There are two highlights which are worth noting in this proposed framework. One is that it benefits from the advancement of both self-attention mechanism and GANs; while the other is that the discriminator of GAN plays the role of the global discriminant network in the stage of the adversarial joint training, which guides the enhancement front-end to capture more compatible structures for the subsequent ASR module and thereby offsets the limitation of the separate training and handcrafted loss functions. With the adversarial joint optimization, the proposed framework is expected to learn more robust representations suitable for the ASR task. We execute systematic experiments on the corpus AISHELL-1, and the experimental results show that on the artificial noisy test set, the proposed framework achieves the relative improvements of 66% compared to the ASR model trained by clean data solely, 35.1% compared to the speech enhancement & ASR scheme without joint training, and 5.3% compared to multi-condition training.
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
Mar 29, 2022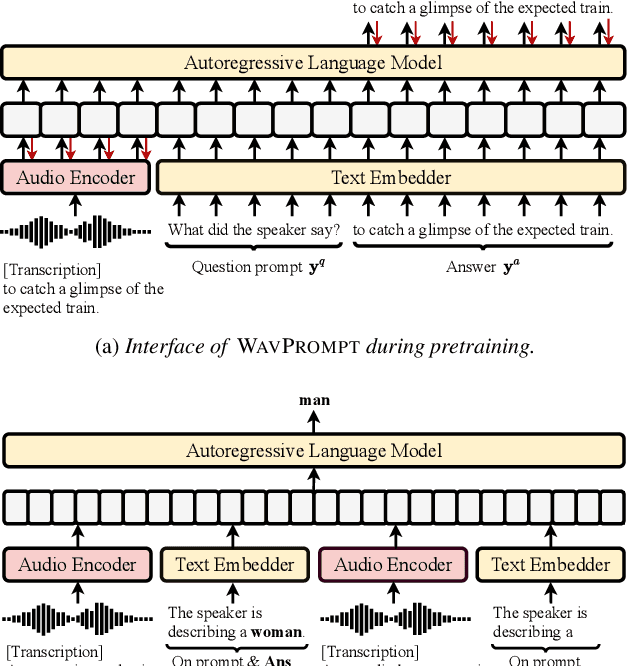

Large-scale auto-regressive language models pretrained on massive text have demonstrated their impressive ability to perform new natural language tasks with only a few text examples, without the need for fine-tuning. Recent studies further show that such a few-shot learning ability can be extended to the text-image setting by training an encoder to encode the images into embeddings functioning like the text embeddings of the language model. Interested in exploring the possibility of transferring the few-shot learning ability to the audio-text setting, we propose a novel speech understanding framework, WavPrompt, where we finetune a wav2vec model to generate a sequence of audio embeddings understood by the language model. We show that WavPrompt is a few-shot learner that can perform speech understanding tasks better than a naive text baseline. We conduct detailed ablation studies on different components and hyperparameters to empirically identify the best model configuration. In addition, we conduct a non-speech understanding experiment to show WavPrompt can extract more information than just the transcriptions.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022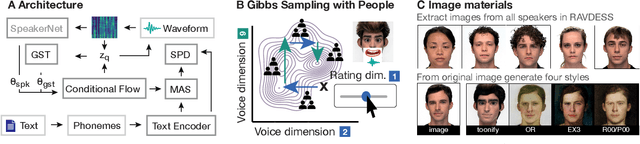
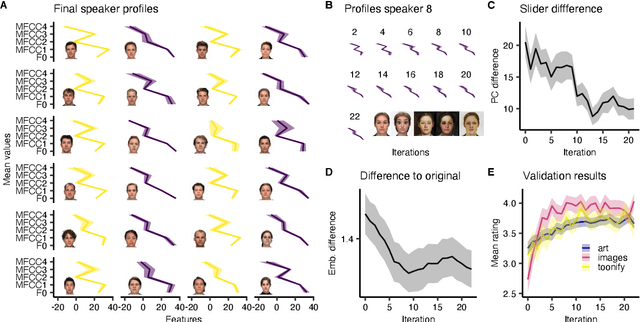
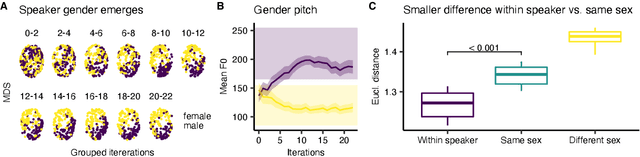
Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.
Speech prosody and remote experiments: a technical report
Jun 21, 2021
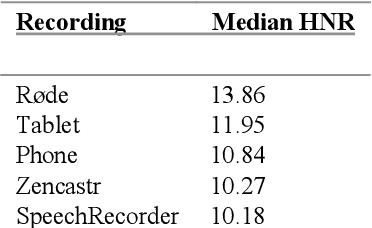

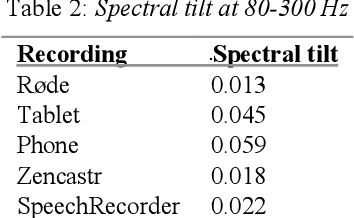
The aim of this paper is twofold. First, we present a review of different recording options for gathering prosodic data in the event that fieldwork is impracticable (e.g. due to pandemics). Under this light, we mimic a long-distance reading task experiment using different software and hardware synchronously. In order to evaluate the employed methodologies, we extract noise levels and frequency manipulation of the recordings. Subsequently, we examine the impact of the different recordings onto linguistic variables, such as the pitch curves and values. We also include a discussion on experimental practicalities. After balancing these factors, we decree an online platform, Zencastr, as the most affordable and practical for acoustic data collection. Secondly, we want to open up a debate on the most optimal remote methodology that researchers on speech prosody can deploy.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022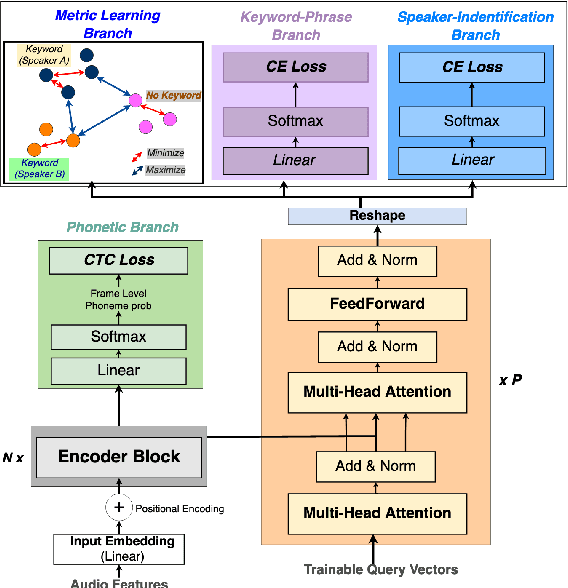
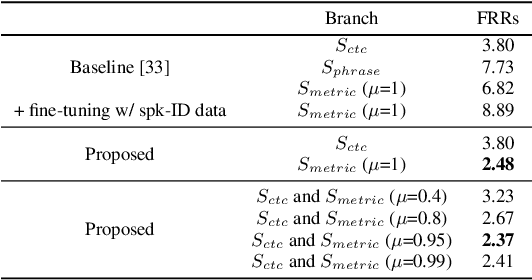
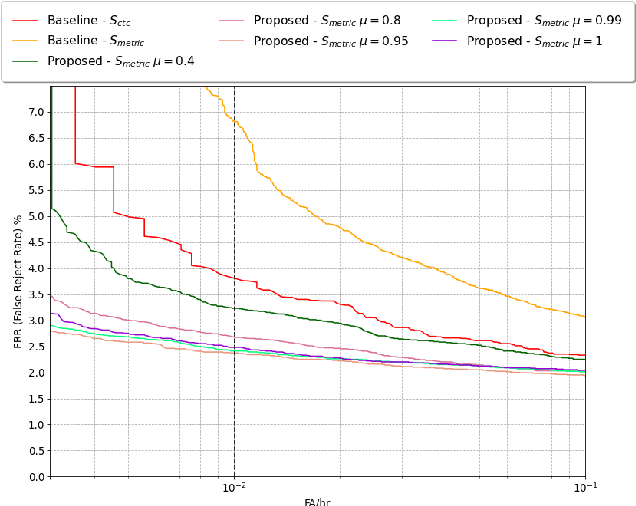
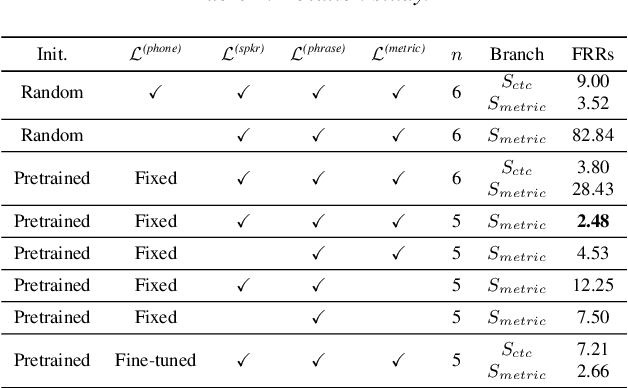
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.