 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multistream neural architectures for cued-speech recognition using a pre-trained visual feature extractor and constrained CTC decoding
Apr 11, 2022
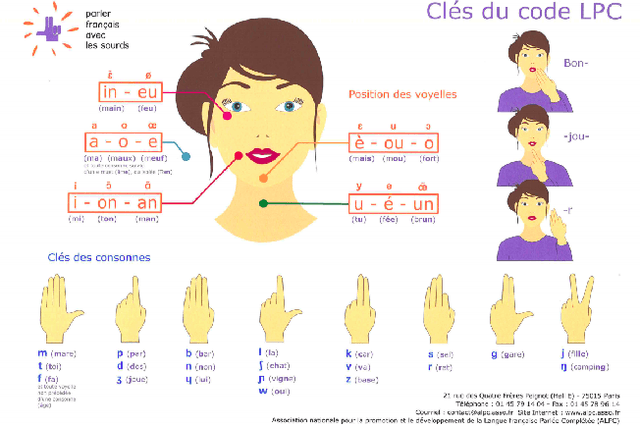
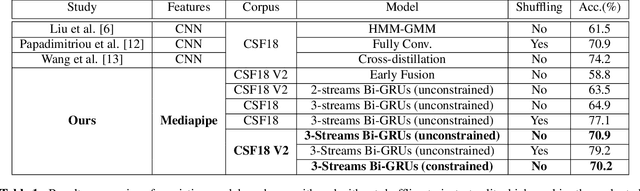
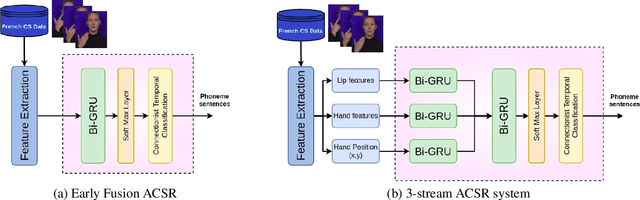
This paper proposes a simple and effective approach for automatic recognition of Cued Speech (CS), a visual communication tool that helps people with hearing impairment to understand spoken language with the help of hand gestures that can uniquely identify the uttered phonemes in complement to lipreading. The proposed approach is based on a pre-trained hand and lips tracker used for visual feature extraction and a phonetic decoder based on a multistream recurrent neural network trained with connectionist temporal classification loss and combined with a pronunciation lexicon. The proposed system is evaluated on an updated version of the French CS dataset CSF18 for which the phonetic transcription has been manually checked and corrected. With a decoding accuracy at the phonetic level of 70.88%, the proposed system outperforms our previous CNN-HMM decoder and competes with more complex baselines.
Passing a Non-verbal Turing Test: Evaluating Gesture Animations Generated from Speech
Jul 01, 2021
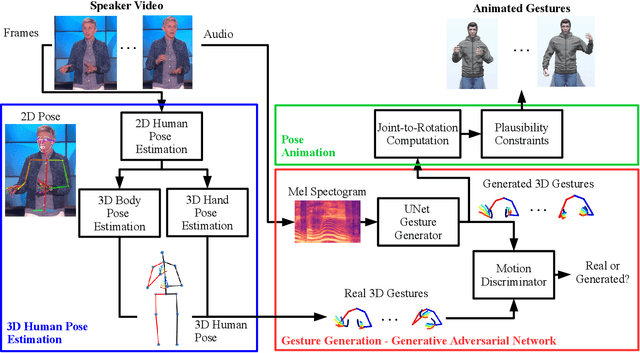


In real life, people communicate using both speech and non-verbal signals such as gestures, face expression or body pose. Non-verbal signals impact the meaning of the spoken utterance in an abundance of ways. An absence of non-verbal signals impoverishes the process of communication. Yet, when users are represented as avatars, it is difficult to translate non-verbal signals along with the speech into the virtual world without specialized motion-capture hardware. In this paper, we propose a novel, data-driven technique for generating gestures directly from speech. Our approach is based on the application of Generative Adversarial Neural Networks (GANs) to model the correlation rather than causation between speech and gestures. This approach approximates neuroscience findings on how non-verbal communication and speech are correlated. We create a large dataset which consists of speech and corresponding gestures in a 3D human pose format from which our model learns the speaker-specific correlation. We evaluate the proposed technique in a user study that is inspired by the Turing test. For the study, we animate the generated gestures on a virtual character. We find that users are not able to distinguish between the generated and the recorded gestures. Moreover, users are able to identify our synthesized gestures as related or not related to a given utterance.
Fine-grained style control in Transformer-based Text-to-speech Synthesis
Oct 12, 2021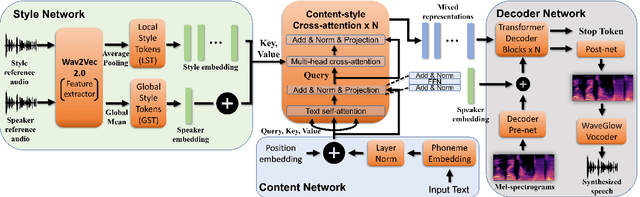

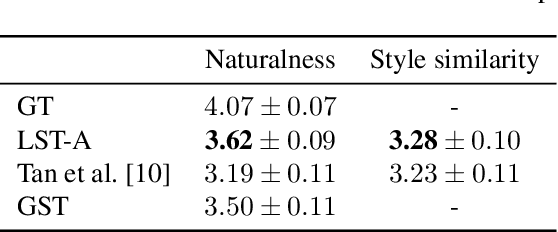
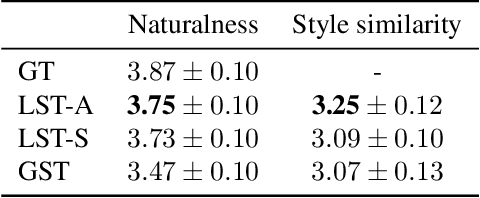
In this paper, we present a novel architecture to realize fine-grained style control on the transformer-based text-to-speech synthesis (TransformerTTS). Specifically, we model the speaking style by extracting a time sequence of local style tokens (LST) from the reference speech. The existing content encoder in TransformerTTS is then replaced by our designed cross-attention blocks for fusion and alignment between content and style. As the fusion is performed along with the skip connection, our cross-attention block provides a good inductive bias to gradually infuse the phoneme representation with a given style. Additionally, we prevent the style embedding from encoding linguistic content by randomly truncating LST during training and using wav2vec 2.0 features. Experiments show that with fine-grained style control, our system performs better in terms of naturalness, intelligibility, and style transferability. Our code and samples are publicly available.
Silent versus modal multi-speaker speech recognition from ultrasound and video
Feb 27, 2021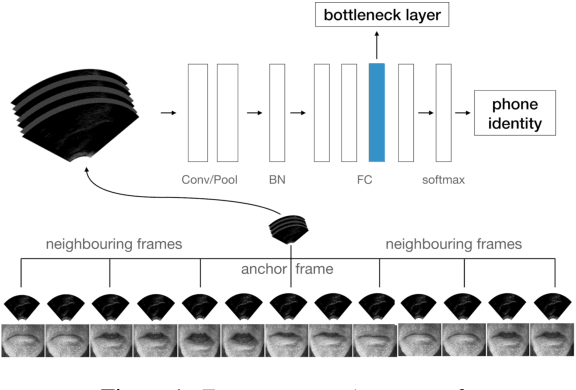
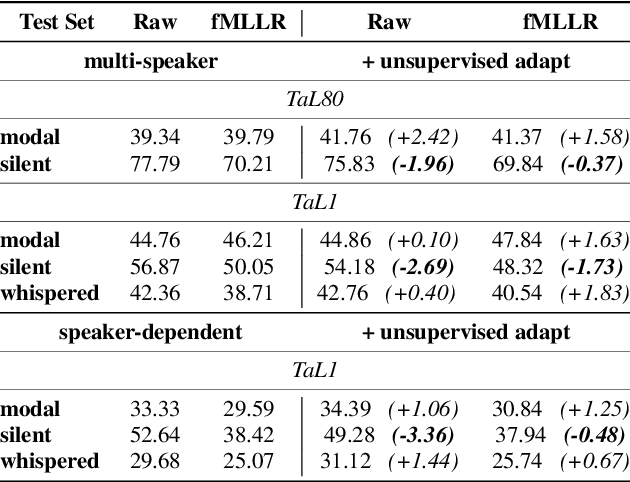
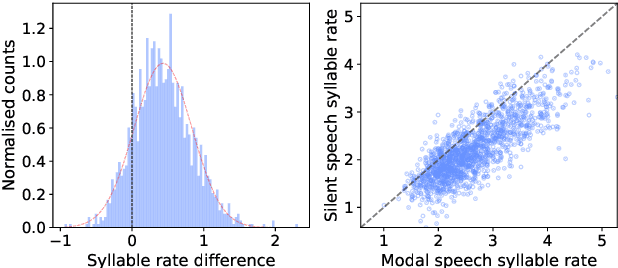

We investigate multi-speaker speech recognition from ultrasound images of the tongue and video images of the lips. We train our systems on imaging data from modal speech, and evaluate on matched test sets of two speaking modes: silent and modal speech. We observe that silent speech recognition from imaging data underperforms compared to modal speech recognition, likely due to a speaking-mode mismatch between training and testing. We improve silent speech recognition performance using techniques that address the domain mismatch, such as fMLLR and unsupervised model adaptation. We also analyse the properties of silent and modal speech in terms of utterance duration and the size of the articulatory space. To estimate the articulatory space, we compute the convex hull of tongue splines, extracted from ultrasound tongue images. Overall, we observe that the duration of silent speech is longer than that of modal speech, and that silent speech covers a smaller articulatory space than modal speech. Although these two properties are statistically significant across speaking modes, they do not directly correlate with word error rates from speech recognition.
FlowVocoder: A small Footprint Neural Vocoder based Normalizing flow for Speech Synthesis
Sep 27, 2021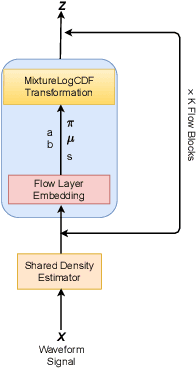

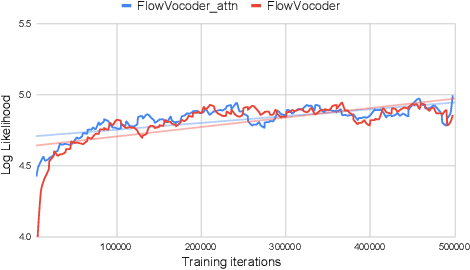
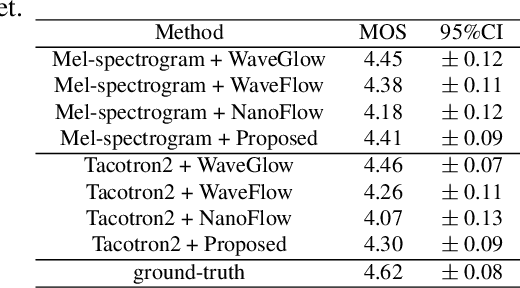
Recently, non-autoregressive neural vocoders have provided remarkable performance in generating high-fidelity speech and have been able to produce synthetic speech in real-time. However, non-autoregressive neural vocoders such as WaveGlow are far behind autoregressive neural vocoders like WaveFlow in terms of modeling audio signals due to their limitation in expressiveness. In addition, though NanoFlow is a state-of-the-art autoregressive neural vocoder that has immensely small parameters, its performance is marginally lower than WaveFlow. Therefore, in this paper, we propose a new type of autoregressive neural vocoder called FlowVocoder, which has a small memory footprint and is able to generate high-fidelity audio in real-time. Our proposed model improves the expressiveness of flow blocks by operating a mixture of Cumulative Distribution Function(CDF) for bipartite transformation. Hence, the proposed model is capable of modeling waveform signals as well as WaveFlow, while its memory footprint is much smaller thanWaveFlow. As shown in experiments, FlowVocoder achieves competitive results with baseline methods in terms of both subjective and objective evaluation, also, it is more suitable for real-time text-to-speech applications.
Transformer-S2A: Robust and Efficient Speech-to-Animation
Nov 18, 2021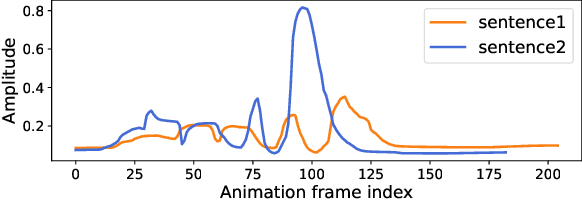
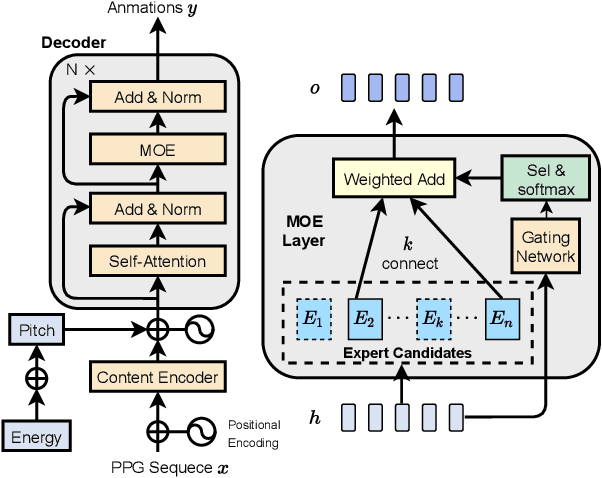
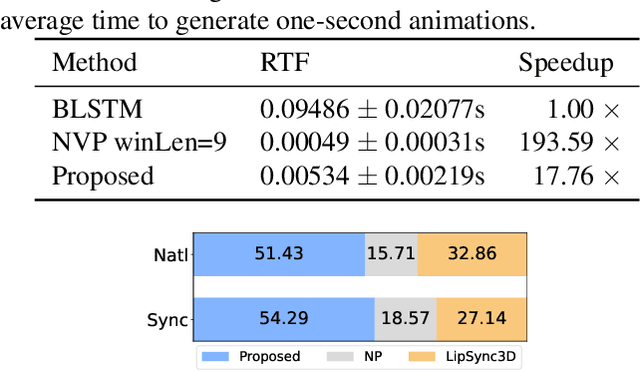

We propose a novel robust and efficient Speech-to-Animation (S2A) approach for synchronized facial animation generation in human-computer interaction. Compared with conventional approaches, the proposed approach utilize phonetic posteriorgrams (PPGs) of spoken phonemes as input to ensure the cross-language and cross-speaker ability, and introduce corresponding prosody features (i.e. pitch and energy) to further enhance the expression of generated animation. Mixtureof-experts (MOE)-based Transformer is employed to better model contextual information while provide significant optimization on computation efficiency. Experiments demonstrate the effectiveness of the proposed approach on both objective and subjective evaluation with 17x inference speedup compared with the state-of-the-art approach.
No-audio speaking status detection in crowded settings via visual pose-based filtering and wearable acceleration
Nov 01, 2022

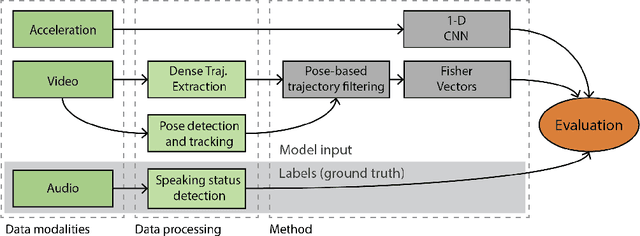
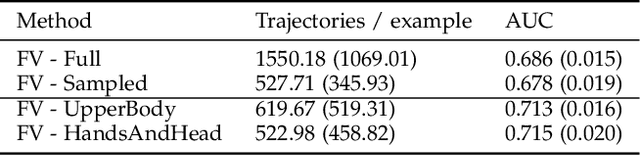
Recognizing who is speaking in a crowded scene is a key challenge towards the understanding of the social interactions going on within. Detecting speaking status from body movement alone opens the door for the analysis of social scenes in which personal audio is not obtainable. Video and wearable sensors make it possible recognize speaking in an unobtrusive, privacy-preserving way. When considering the video modality, in action recognition problems, a bounding box is traditionally used to localize and segment out the target subject, to then recognize the action taking place within it. However, cross-contamination, occlusion, and the articulated nature of the human body, make this approach challenging in a crowded scene. Here, we leverage articulated body poses for subject localization and in the subsequent speech detection stage. We show that the selection of local features around pose keypoints has a positive effect on generalization performance while also significantly reducing the number of local features considered, making for a more efficient method. Using two in-the-wild datasets with different viewpoints of subjects, we investigate the role of cross-contamination in this effect. We additionally make use of acceleration measured through wearable sensors for the same task, and present a multimodal approach combining both methods.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 09, 2021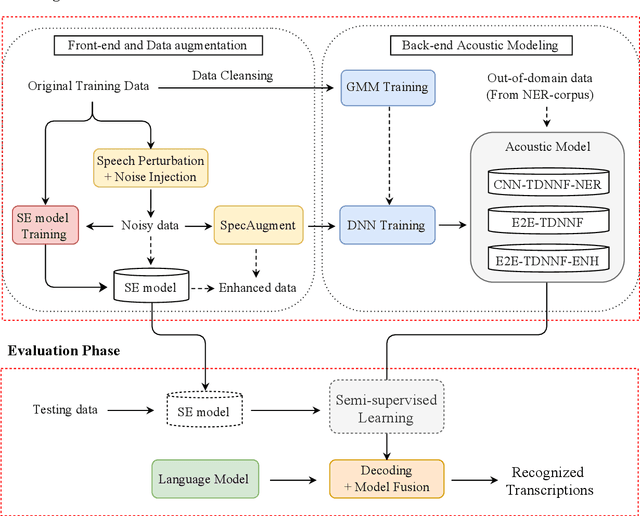
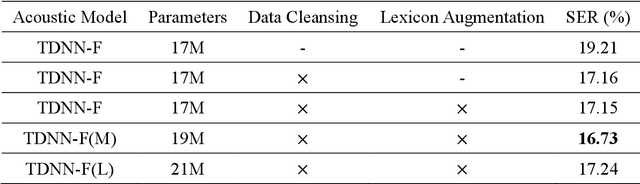
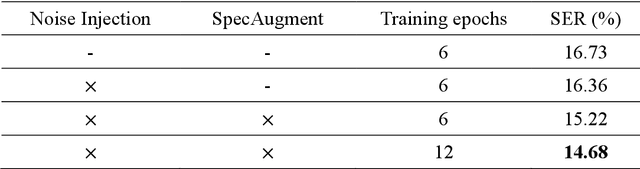
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
A Survey of Online Hate Speech through the Causal Lens
Sep 16, 2021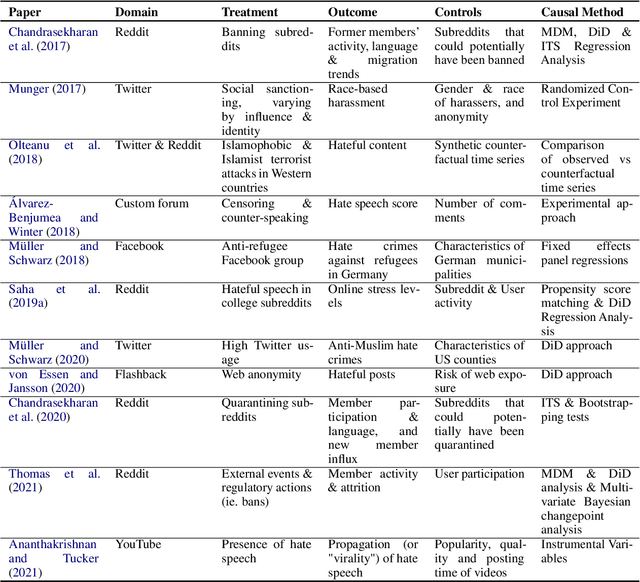
The societal issue of digital hostility has previously attracted a lot of attention. The topic counts an ample body of literature, yet remains prominent and challenging as ever due to its subjective nature. We posit that a better understanding of this problem will require the use of causal inference frameworks. This survey summarises the relevant research that revolves around estimations of causal effects related to online hate speech. Initially, we provide an argumentation as to why re-establishing the exploration of hate speech in causal terms is of the essence. Following that, we give an overview of the leading studies classified with respect to the direction of their outcomes, as well as an outline of all related research, and a summary of open research problems that can influence future work on the topic.
ML-Based Analysis to Identify Speech Features Relevant in Predicting Alzheimer's Disease
Oct 25, 2021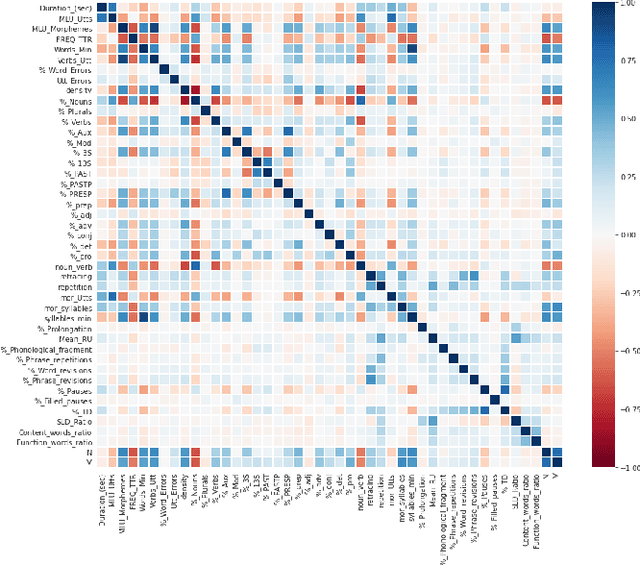
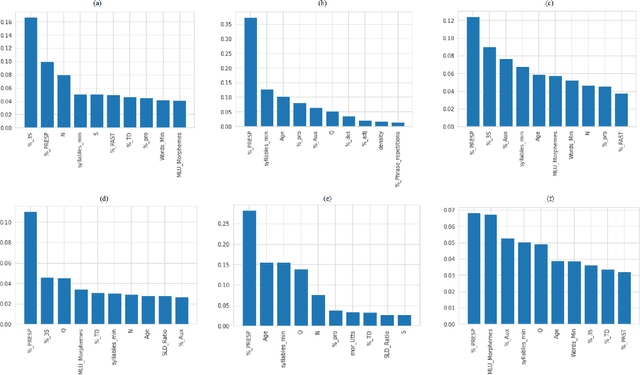
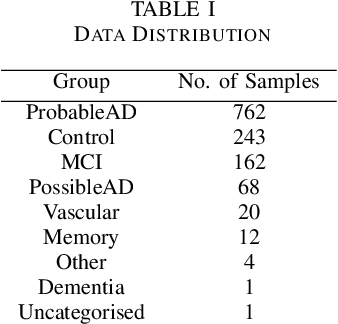

Alzheimer's disease (AD) is a neurodegenerative disease that affects nearly 50 million individuals across the globe and is one of the leading causes of deaths globally. It is projected that by 2050, the number of people affected by the disease would more than double. Consequently, the growing advancements in technology beg the question, can technology be used to predict Alzheimer's for a better and early diagnosis? In this paper, we focus on this very problem. Specifically, we have trained both ML models and neural networks to predict and classify participants based on their speech patterns. We computed a number of linguistic variables using DementiaBank's Pitt Corpus, a database consisting of transcripts of interviews with subjects suffering from multiple neurodegenerative diseases. We then trained both binary classifiers, as well as multiclass classifiers to distinguish AD from normal aging and other neurodegenerative diseases. We also worked on establishing the link between specific speech factors that can help determine the onset of AD. Confusion matrices and feature importance graphs have been plotted model-wise to compare the performances of our models. In both multiclass and binary classification, neural networks were found to outperform the other models with a testing accuracy of 76.44% and 92.05% respectively. For the feature importance, it was concluded that '%_PRESP' (present participle), '%_3S' (3rd person present tense markers) were two of the most important speech features for our classifiers in predicting AD.