 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Bilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023
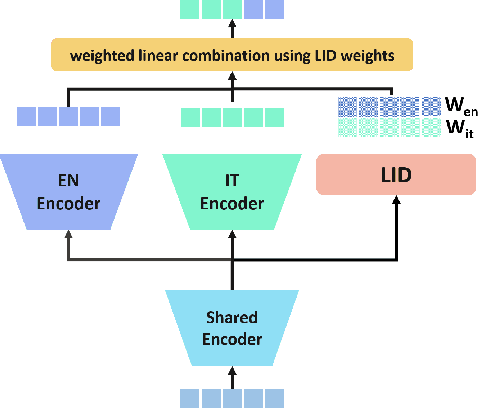
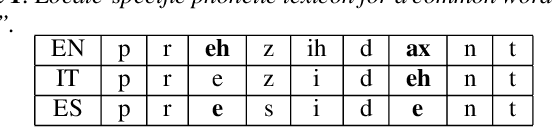
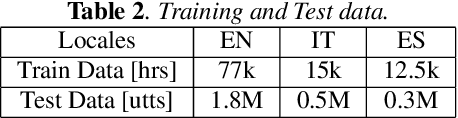
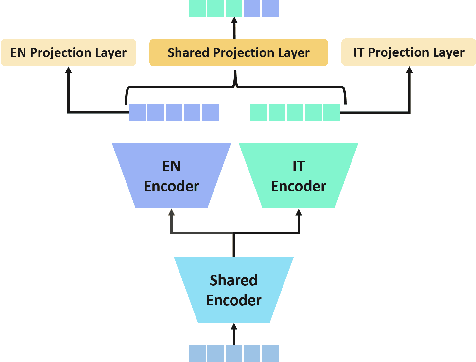
We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
Towards spoken dialect identification of Irish
Jul 14, 2023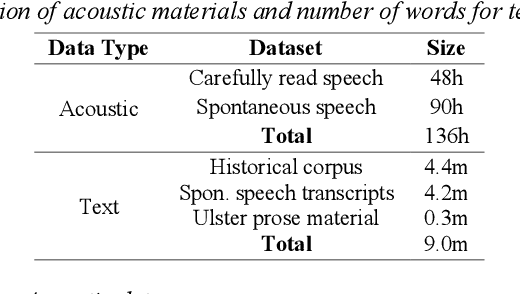
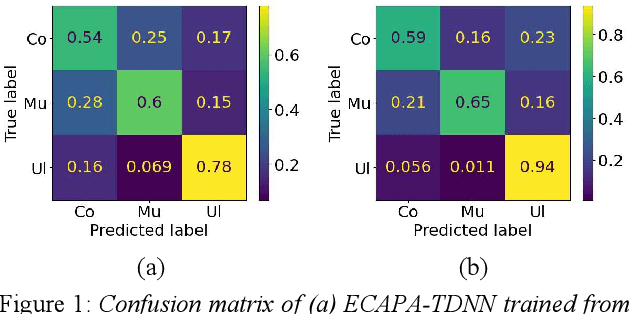
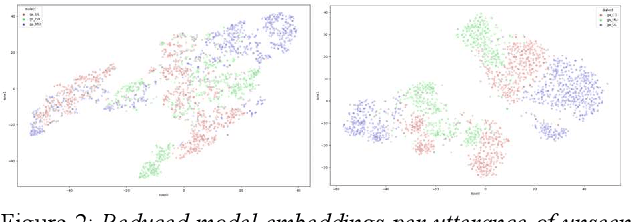
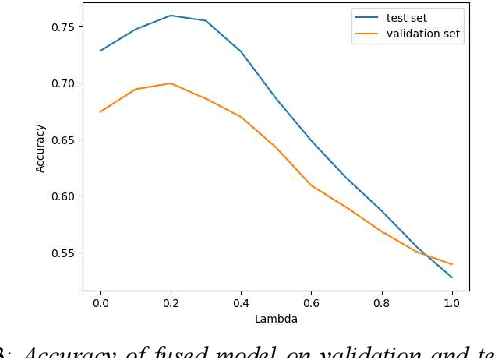
The Irish language is rich in its diversity of dialects and accents. This compounds the difficulty of creating a speech recognition system for the low-resource language, as such a system must contend with a high degree of variability with limited corpora. A recent study investigating dialect bias in Irish ASR found that balanced training corpora gave rise to unequal dialect performance, with performance for the Ulster dialect being consistently worse than for the Connacht or Munster dialects. Motivated by this, the present experiments investigate spoken dialect identification of Irish, with a view to incorporating such a system into the speech recognition pipeline. Two acoustic classification models are tested, XLS-R and ECAPA-TDNN, in conjunction with a text-based classifier using a pretrained Irish-language BERT model. The ECAPA-TDNN, particularly a model pretrained for language identification on the VoxLingua107 dataset, performed best overall, with an accuracy of 73%. This was further improved to 76% by fusing the model's outputs with the text-based model. The Ulster dialect was most accurately identified, with an accuracy of 94%, however the model struggled to disambiguate between the Connacht and Munster dialects, suggesting a more nuanced approach may be necessary to robustly distinguish between the dialects of Irish.
Turning Whisper into Real-Time Transcription System
Jul 27, 2023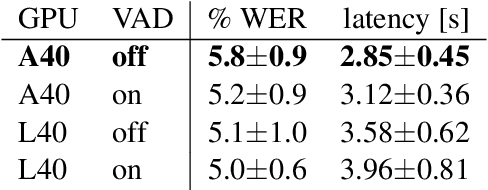
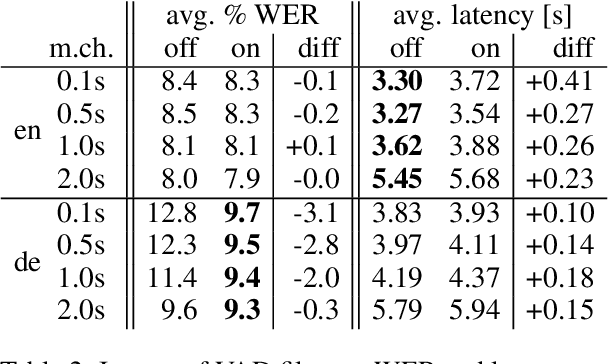
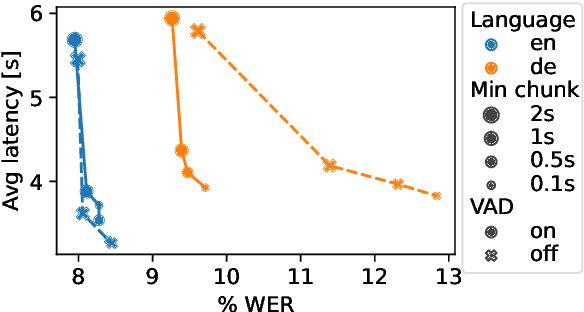
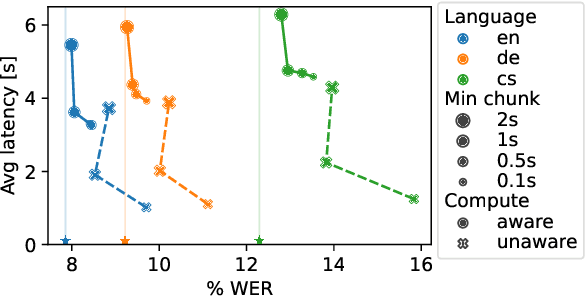
Whisper is one of the recent state-of-the-art multilingual speech recognition and translation models, however, it is not designed for real time transcription. In this paper, we build on top of Whisper and create Whisper-Streaming, an implementation of real-time speech transcription and translation of Whisper-like models. Whisper-Streaming uses local agreement policy with self-adaptive latency to enable streaming transcription. We show that Whisper-Streaming achieves high quality and 3.3 seconds latency on unsegmented long-form speech transcription test set, and we demonstrate its robustness and practical usability as a component in live transcription service at a multilingual conference.
ESB: A Benchmark For Multi-Domain End-to-End Speech Recognition
Oct 24, 2022
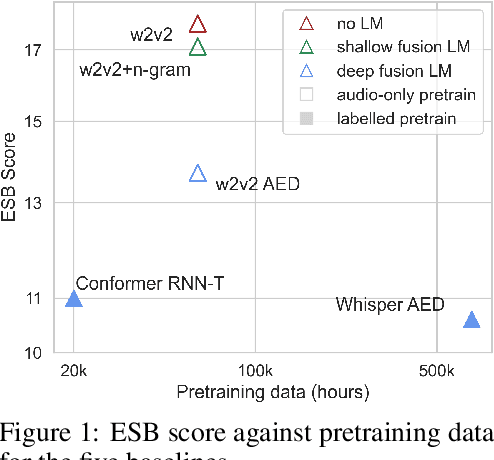
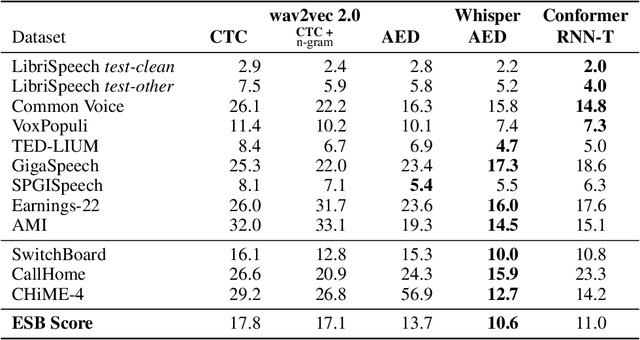
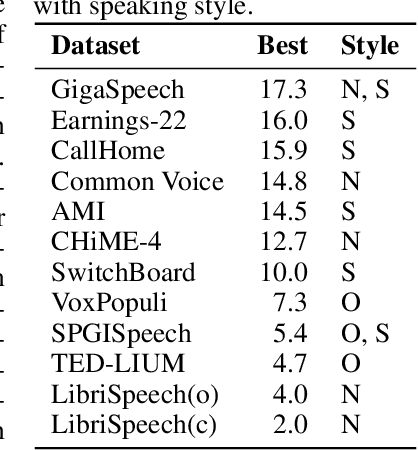
Speech recognition applications cover a range of different audio and text distributions, with different speaking styles, background noise, transcription punctuation and character casing. However, many speech recognition systems require dataset-specific tuning (audio filtering, punctuation removal and normalisation of casing), therefore assuming a-priori knowledge of both the audio and text distributions. This tuning requirement can lead to systems failing to generalise to other datasets and domains. To promote the development of multi-domain speech systems, we introduce the End-to-end Speech Benchmark (ESB) for evaluating the performance of a single automatic speech recognition (ASR) system across a broad set of speech datasets. Benchmarked systems must use the same data pre- and post-processing algorithm across datasets - assuming the audio and text data distributions are a-priori unknown. We compare a series of state-of-the-art (SoTA) end-to-end (E2E) systems on this benchmark, demonstrating how a single speech system can be applied and evaluated on a wide range of data distributions. We find E2E systems to be effective across datasets: in a fair comparison, E2E systems achieve within 2.6% of SoTA systems tuned to a specific dataset. Our analysis reveals that transcription artefacts, such as punctuation and casing, pose difficulties for ASR systems and should be included in evaluation. We believe E2E benchmarking over a range of datasets promotes the research of multi-domain speech recognition systems. ESB is available at https://huggingface.co/esb.
Comparative Analysis of the wav2vec 2.0 Feature Extractor
Aug 08, 2023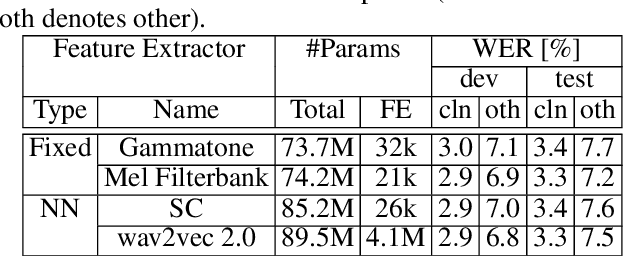
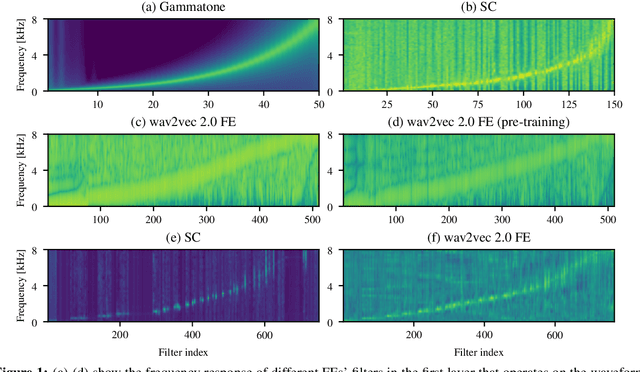
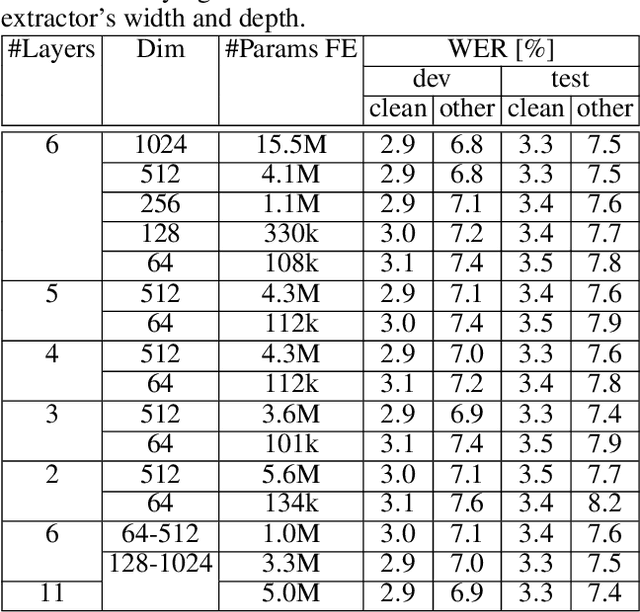
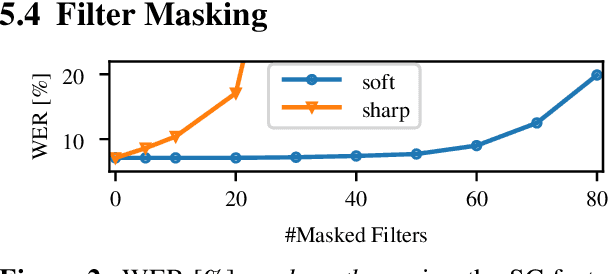
Automatic speech recognition (ASR) systems typically use handcrafted feature extraction pipelines. To avoid their inherent information loss and to achieve more consistent modeling from speech to transcribed text, neural raw waveform feature extractors (FEs) are an appealing approach. Also the wav2vec 2.0 model, which has recently gained large popularity, uses a convolutional FE which operates directly on the speech waveform. However, it is not yet studied extensively in the literature. In this work, we study its capability to replace the standard feature extraction methods in a connectionist temporal classification (CTC) ASR model and compare it to an alternative neural FE. We show that both are competitive with traditional FEs on the LibriSpeech benchmark and analyze the effect of the individual components. Furthermore, we analyze the learned filters and show that the most important information for the ASR system is obtained by a set of bandpass filters.
On Monotonic Aggregation for Open-domain QA
Aug 08, 2023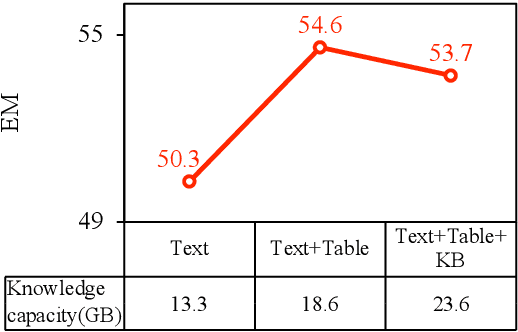
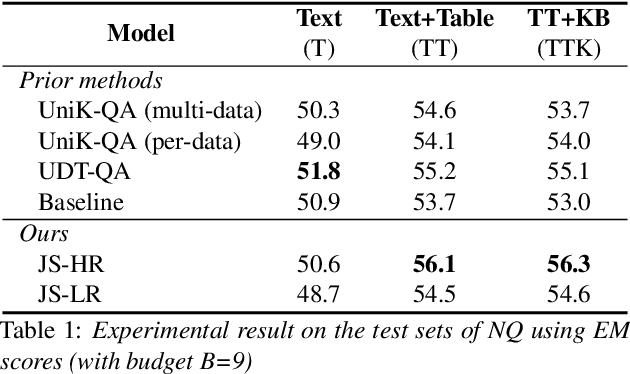
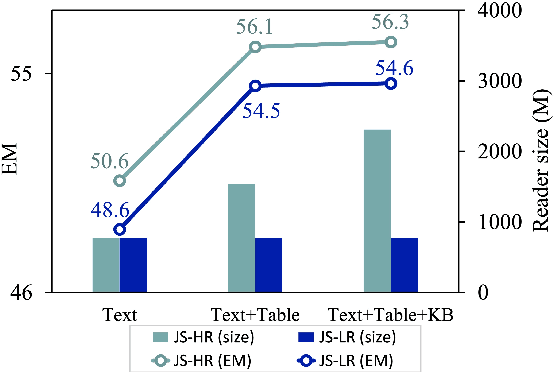
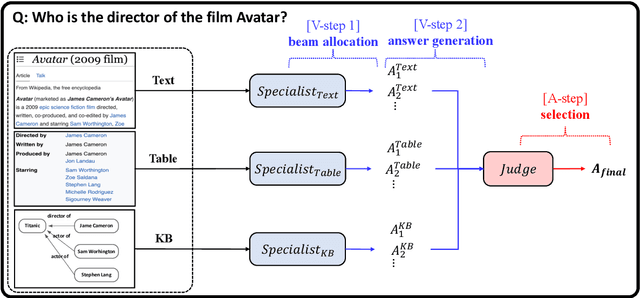
Question answering (QA) is a critical task for speech-based retrieval from knowledge sources, by sifting only the answers without requiring to read supporting documents. Specifically, open-domain QA aims to answer user questions on unrestricted knowledge sources. Ideally, adding a source should not decrease the accuracy, but we find this property (denoted as "monotonicity") does not hold for current state-of-the-art methods. We identify the cause, and based on that we propose Judge-Specialist framework. Our framework consists of (1) specialist retrievers/readers to cover individual sources, and (2) judge, a dedicated language model to select the final answer. Our experiments show that our framework not only ensures monotonicity, but also outperforms state-of-the-art multi-source QA methods on Natural Questions. Additionally, we show that our models robustly preserve the monotonicity against noise from speech recognition. We publicly release our code and setting.
Improving grapheme-to-phoneme conversion by learning pronunciations from speech recordings
Jul 31, 2023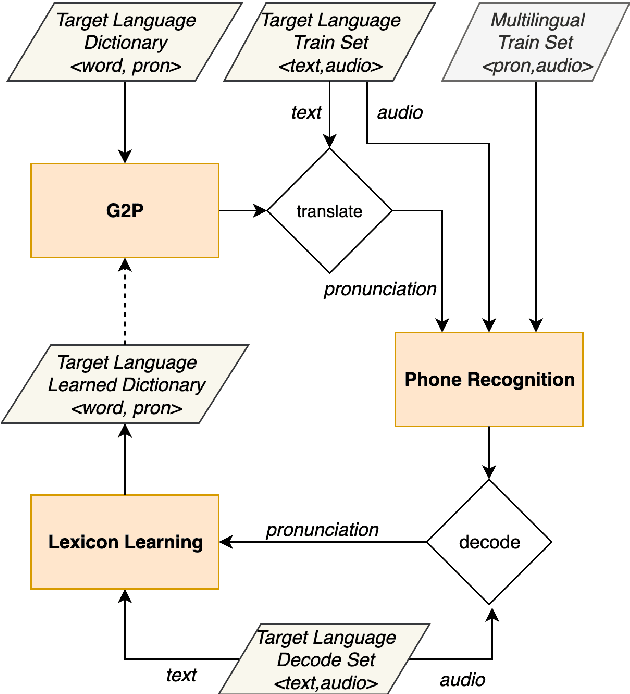

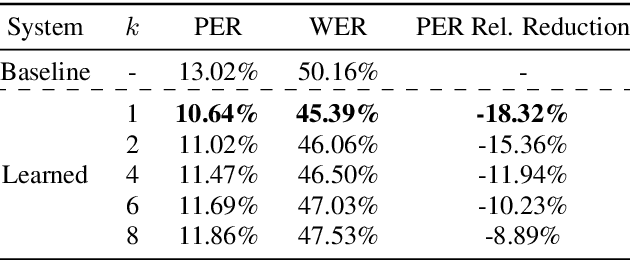
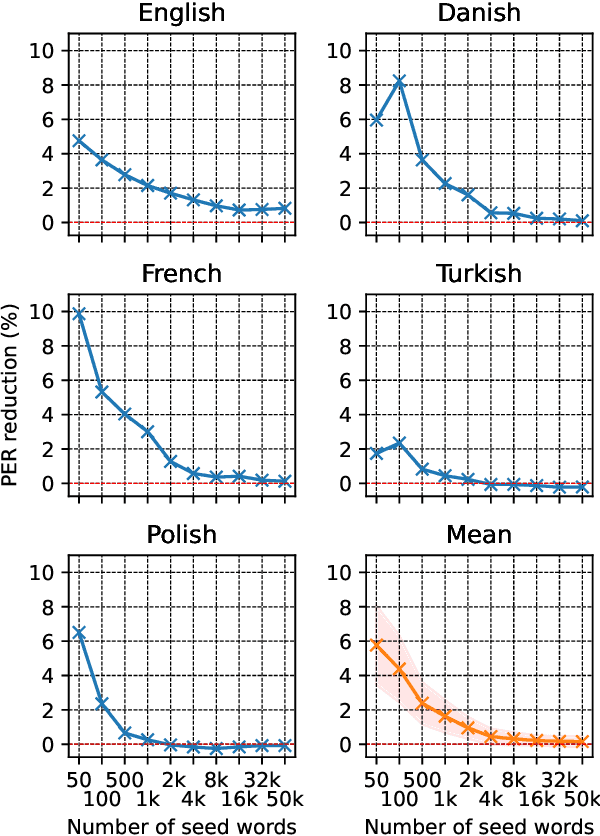
The Grapheme-to-Phoneme (G2P) task aims to convert orthographic input into a discrete phonetic representation. G2P conversion is beneficial to various speech processing applications, such as text-to-speech and speech recognition. However, these tend to rely on manually-annotated pronunciation dictionaries, which are often time-consuming and costly to acquire. In this paper, we propose a method to improve the G2P conversion task by learning pronunciation examples from audio recordings. Our approach bootstraps a G2P with a small set of annotated examples. The G2P model is used to train a multilingual phone recognition system, which then decodes speech recordings with a phonetic representation. Given hypothesized phoneme labels, we learn pronunciation dictionaries for out-of-vocabulary words, and we use those to re-train the G2P system. Results indicate that our approach consistently improves the phone error rate of G2P systems across languages and amount of available data.
OxfordVGG Submission to the EGO4D AV Transcription Challenge
Jul 18, 2023

This report presents the technical details of our submission on the EGO4D Audio-Visual (AV) Automatic Speech Recognition Challenge 2023 from the OxfordVGG team. We present WhisperX, a system for efficient speech transcription of long-form audio with word-level time alignment, along with two text normalisers which are publicly available. Our final submission obtained 56.0% of the Word Error Rate (WER) on the challenge test set, ranked 1st on the leaderboard. All baseline codes and models are available on https://github.com/m-bain/whisperX.
Latent Phrase Matching for Dysarthric Speech
Jun 08, 2023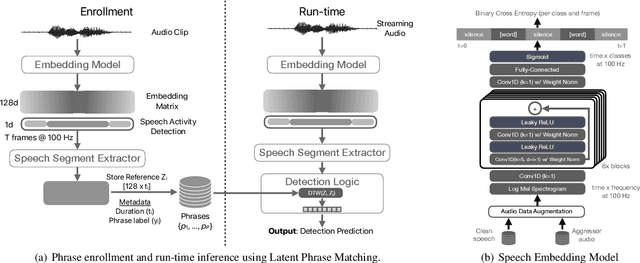
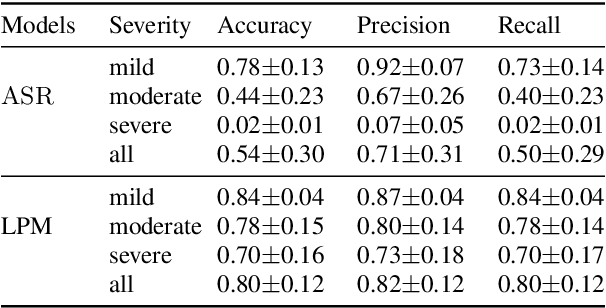
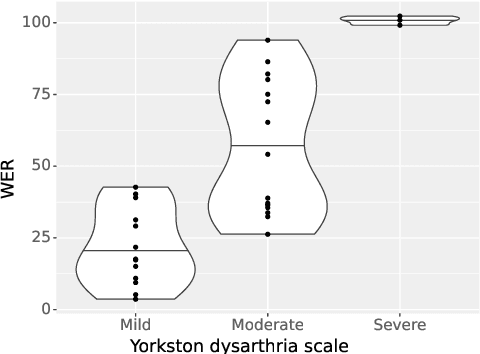
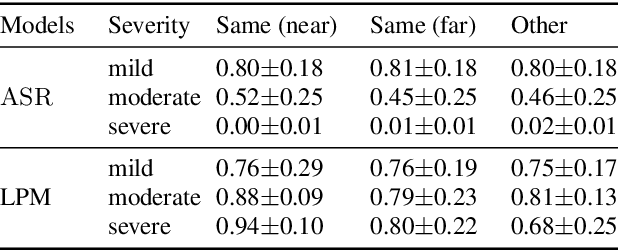
Many consumer speech recognition systems are not tuned for people with speech disabilities, resulting in poor recognition and user experience, especially for severe speech differences. Recent studies have emphasized interest in personalized speech models from people with atypical speech patterns. We propose a query-by-example-based personalized phrase recognition system that is trained using small amounts of speech, is language agnostic, does not assume a traditional pronunciation lexicon, and generalizes well across speech difference severities. On an internal dataset collected from 32 people with dysarthria, this approach works regardless of severity and shows a 60% improvement in recall relative to a commercial speech recognition system. On the public EasyCall dataset of dysarthric speech, our approach improves accuracy by 30.5%. Performance degrades as the number of phrases increases, but consistently outperforms ASR systems when trained with 50 unique phrases.
Accented Speech Recognition under the Indian context
Sep 11, 2022
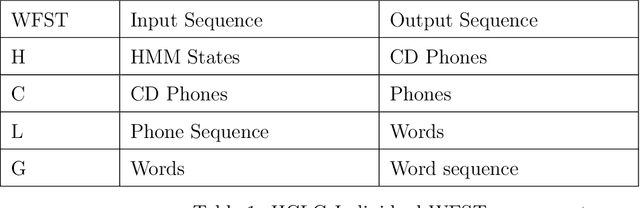
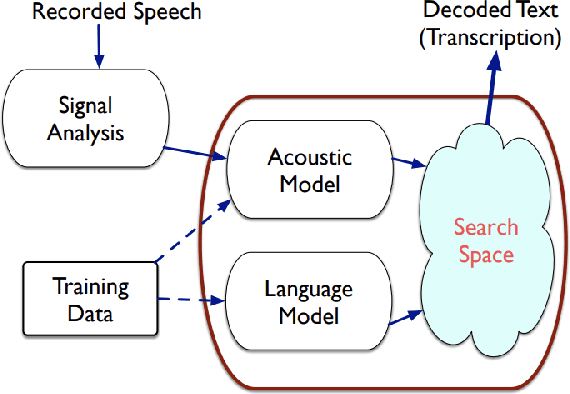
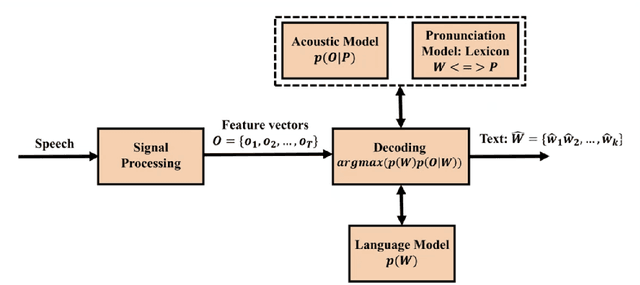
Accent forms an integral part of identifying cultures, emotions, behavior'ss, etc. People often perceive each other in a different manner due to their accent. The accent itself can be a conveyor of status, pride, and other emotional information which can be captured through Speech itself. Accent itself can be defined as: "the way in which people in a particular area, country, or social group pronounce words" or "a special emphasis given to a syllable in a word, word in a sentence, or note in a set of musical notes". Accented Speech Recognition is one the most important problems in the domain of Speech Recognition. Speech recognition is an interdisciplinary sub-field of Computer Science and Linguistics research where the main aim is to develop technologies which enable conversion of speech into text. The speech can be of any form such as read speech or spontaneous speech, conversational speech. As all instances of language utterances are present speech is very diverse and exhibits many traits of variability. This diversity stems from the environmental conditions, variabilities from speaker to speaker, channel noise, differences in Speech production due to disabilities, presence of disfluencies. Speech therefore is indeed a rich source of information waiting to be exploited.