 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speaker consistency loss and step-wise optimization for semi-supervised joint training of TTS and ASR using unpaired text data
Jul 11, 2022
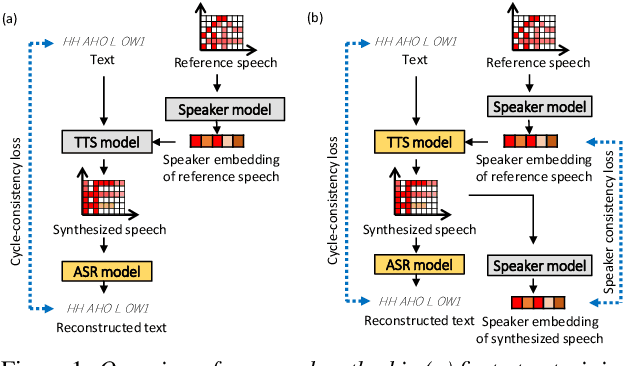
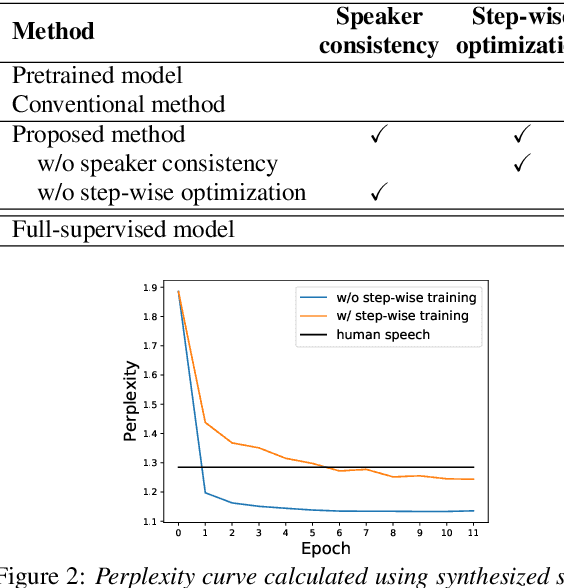
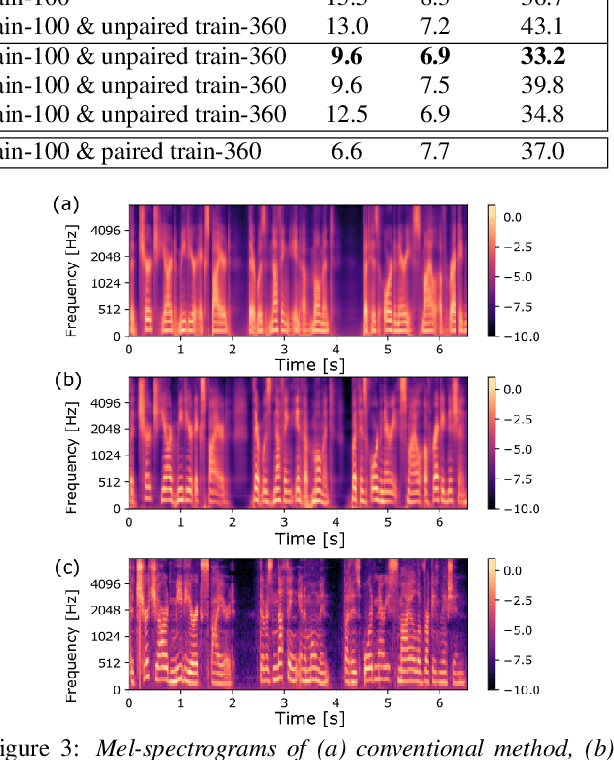
In this paper, we investigate the semi-supervised joint training of text to speech (TTS) and automatic speech recognition (ASR), where a small amount of paired data and a large amount of unpaired text data are available. Conventional studies form a cycle called the TTS-ASR pipeline, where the multispeaker TTS model synthesizes speech from text with a reference speech and the ASR model reconstructs the text from the synthesized speech, after which both models are trained with a cycle-consistency loss. However, the synthesized speech does not reflect the speaker characteristics of the reference speech and the synthesized speech becomes overly easy for the ASR model to recognize after training. This not only decreases the TTS model quality but also limits the ASR model improvement. To solve this problem, we propose improving the cycleconsistency-based training with a speaker consistency loss and step-wise optimization. The speaker consistency loss brings the speaker characteristics of the synthesized speech closer to that of the reference speech. In the step-wise optimization, we first freeze the parameter of the TTS model before both models are trained to avoid over-adaptation of the TTS model to the ASR model. Experimental results demonstrate the efficacy of the proposed method.
Contaminated speech training methods for robust DNN-HMM distant speech recognition
Oct 10, 2017
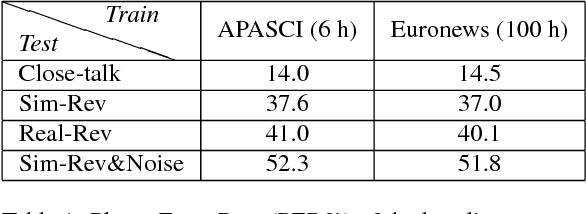
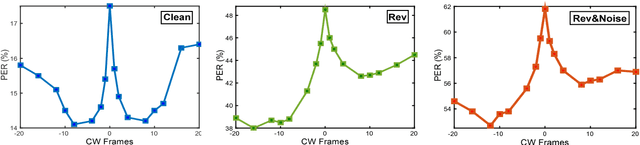
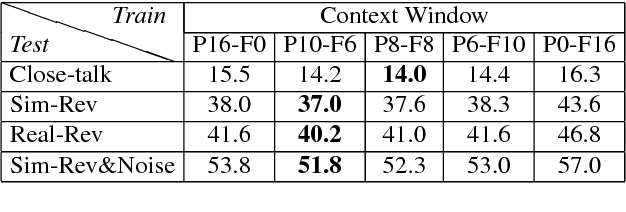
Despite the significant progress made in the last years, state-of-the-art speech recognition technologies provide a satisfactory performance only in the close-talking condition. Robustness of distant speech recognition in adverse acoustic conditions, on the other hand, remains a crucial open issue for future applications of human-machine interaction. To this end, several advances in speech enhancement, acoustic scene analysis as well as acoustic modeling, have recently contributed to improve the state-of-the-art in the field. One of the most effective approaches to derive a robust acoustic modeling is based on using contaminated speech, which proved helpful in reducing the acoustic mismatch between training and testing conditions. In this paper, we revise this classical approach in the context of modern DNN-HMM systems, and propose the adoption of three methods, namely, asymmetric context windowing, close-talk based supervision, and close-talk based pre-training. The experimental results, obtained using both real and simulated data, show a significant advantage in using these three methods, overall providing a 15% error rate reduction compared to the baseline systems. The same trend in performance is confirmed either using a high-quality training set of small size, and a large one.
End-to-End Spoken Language Understanding: Performance analyses of a voice command task in a low resource setting
Jul 17, 2022

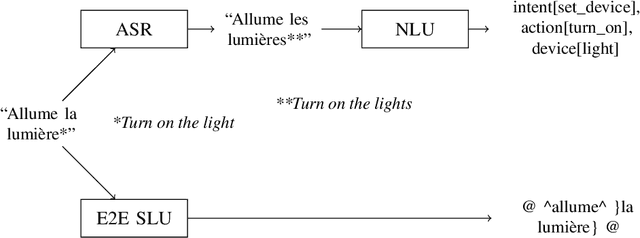
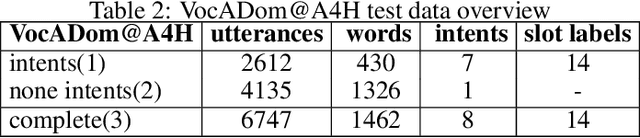
Spoken Language Understanding (SLU) is a core task in most human-machine interaction systems. With the emergence of smart homes, smart phones and smart speakers, SLU has become a key technology for the industry. In a classical SLU approach, an Automatic Speech Recognition (ASR) module transcribes the speech signal into a textual representation from which a Natural Language Understanding (NLU) module extracts semantic information. Recently End-to-End SLU (E2E SLU) based on Deep Neural Networks has gained momentum since it benefits from the joint optimization of the ASR and the NLU parts, hence limiting the cascade of error effect of the pipeline architecture. However, little is known about the actual linguistic properties used by E2E models to predict concepts and intents from speech input. In this paper, we present a study identifying the signal features and other linguistic properties used by an E2E model to perform the SLU task. The study is carried out in the application domain of a smart home that has to handle non-English (here French) voice commands. The results show that a good E2E SLU performance does not always require a perfect ASR capability. Furthermore, the results show the superior capabilities of the E2E model in handling background noise and syntactic variation compared to the pipeline model. Finally, a finer-grained analysis suggests that the E2E model uses the pitch information of the input signal to identify voice command concepts. The results and methodology outlined in this paper provide a springboard for further analyses of E2E models in speech processing.
* Thierry Desot, Fran\c{c}ois Portet, Michel Vacher, End-to-End Spoken Language Understanding: Performance analyses of a voice command task in a low resource setting, Computer Speech & Language, Volume 75, 2022
Twin Regularization for online speech recognition
Jun 12, 2018
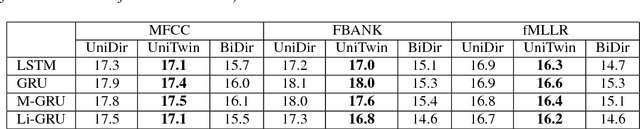
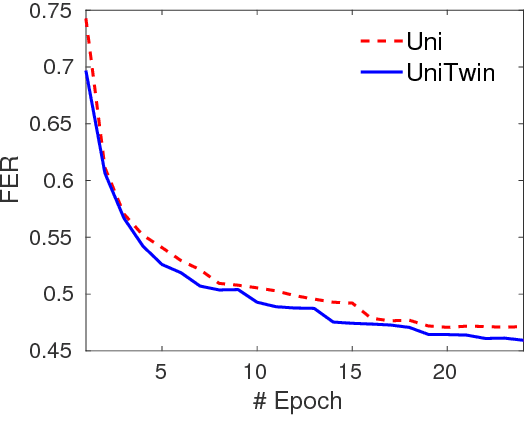
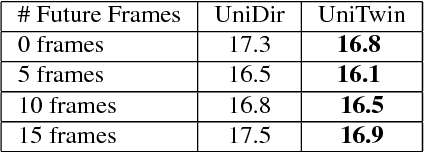
Online speech recognition is crucial for developing natural human-machine interfaces. This modality, however, is significantly more challenging than off-line ASR, since real-time/low-latency constraints inevitably hinder the use of future information, that is known to be very helpful to perform robust predictions. A popular solution to mitigate this issue consists of feeding neural acoustic models with context windows that gather some future frames. This introduces a latency which depends on the number of employed look-ahead features. This paper explores a different approach, based on estimating the future rather than waiting for it. Our technique encourages the hidden representations of a unidirectional recurrent network to embed some useful information about the future. Inspired by a recently proposed technique called Twin Networks, we add a regularization term that forces forward hidden states to be as close as possible to cotemporal backward ones, computed by a "twin" neural network running backwards in time. The experiments, conducted on a number of datasets, recurrent architectures, input features, and acoustic conditions, have shown the effectiveness of this approach. One important advantage is that our method does not introduce any additional computation at test time if compared to standard unidirectional recurrent networks.
Bilingual End-to-End ASR with Byte-Level Subwords
May 01, 2022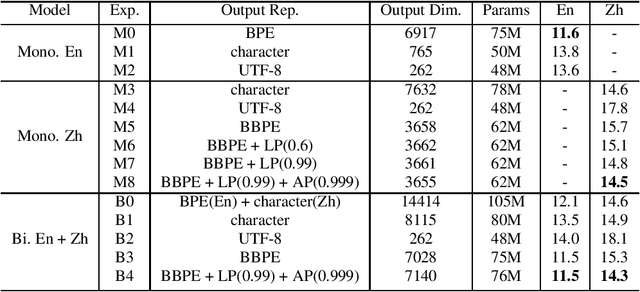
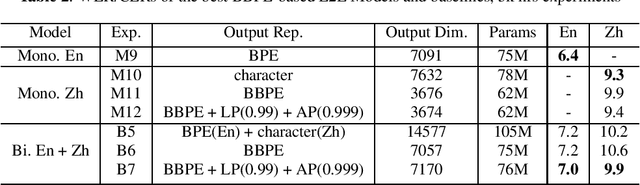
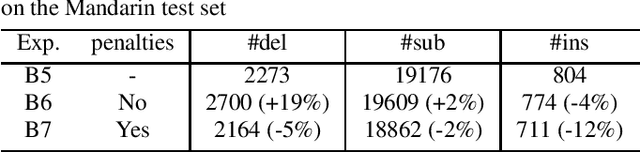
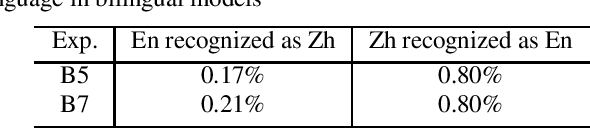
In this paper, we investigate how the output representation of an end-to-end neural network affects multilingual automatic speech recognition (ASR). We study different representations including character-level, byte-level, byte pair encoding (BPE), and byte-level byte pair encoding (BBPE) representations, and analyze their strengths and weaknesses. We focus on developing a single end-to-end model to support utterance-based bilingual ASR, where speakers do not alternate between two languages in a single utterance but may change languages across utterances. We conduct our experiments on English and Mandarin dictation tasks, and we find that BBPE with penalty schemes can improve utterance-based bilingual ASR performance by 2% to 5% relative even with smaller number of outputs and fewer parameters. We conclude with analysis that indicates directions for further improving multilingual ASR.
Multi-Stream End-to-End Speech Recognition
Jun 17, 2019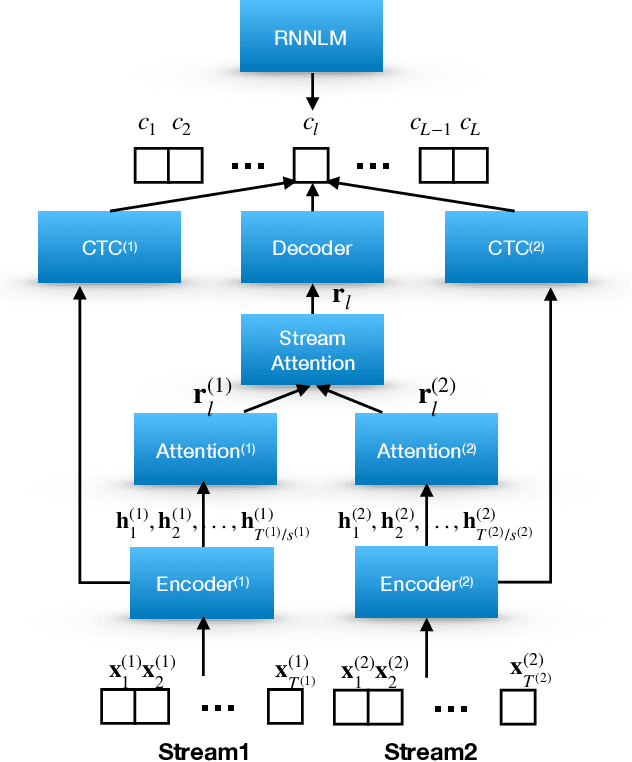
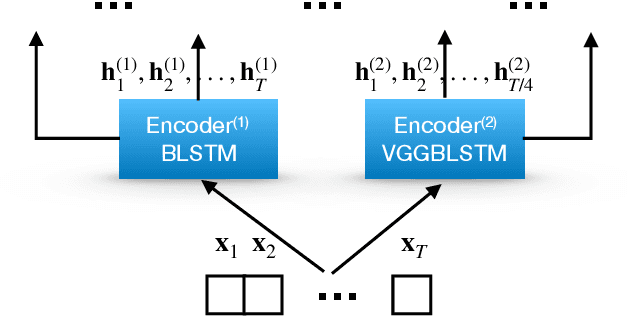
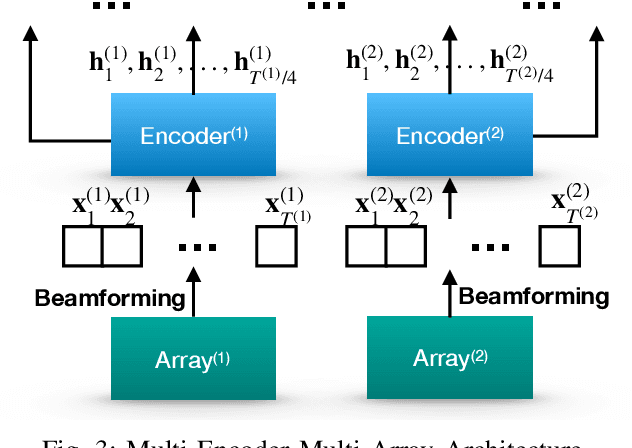
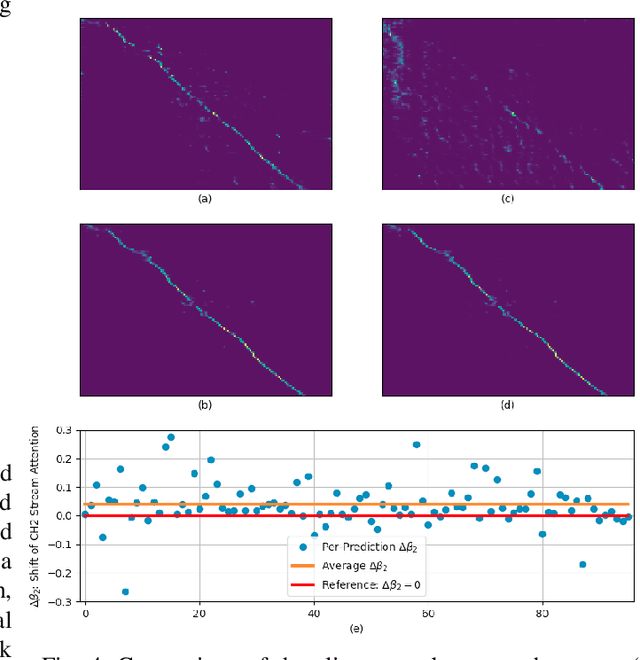
Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end (E2E) Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a multi-stream framework based on joint CTC/Attention E2E ASR with parallel streams represented by separate encoders aiming to capture diverse information. On top of the regular attention networks, the Hierarchical Attention Network (HAN) is introduced to steer the decoder toward the most informative encoders. A separate CTC network is assigned to each stream to force monotonic alignments. Two representative framework have been proposed and discussed, which are Multi-Encoder Multi-Resolution (MEM-Res) framework and Multi-Encoder Multi-Array (MEM-Array) framework, respectively. In MEM-Res framework, two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary information from same acoustics. Experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1% and the best WER of 3.6% in the WSJ eval92 test set. The MEM-Array framework aims at improving the far-field ASR robustness using multiple microphone arrays which are activated by separate encoders. Compared with the best single-array results, the proposed framework has achieved relative WER reduction of 3.7% and 9.7% in AMI and DIRHA multi-array corpora, respectively, which also outperforms conventional fusion strategies.
Continuous Metric Learning For Transferable Speech Emotion Recognition and Embedding Across Low-resource Languages
Mar 28, 2022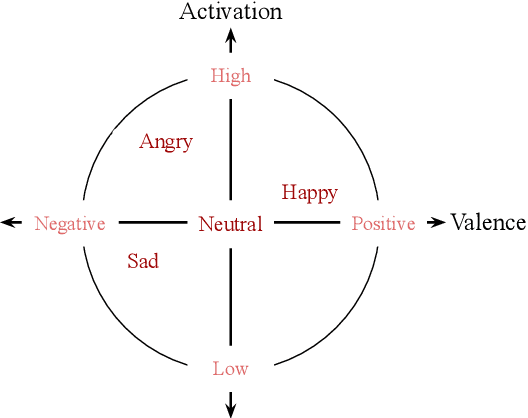

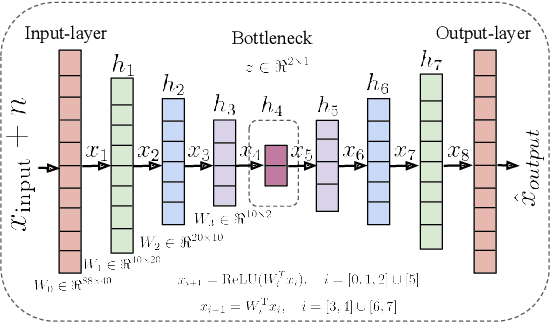

Speech emotion recognition~(SER) refers to the technique of inferring the emotional state of an individual from speech signals. SERs continue to garner interest due to their wide applicability. Although the domain is mainly founded on signal processing, machine learning, and deep learning, generalizing over languages continues to remain a challenge. However, developing generalizable and transferable models are critical due to a lack of sufficient resources in terms of data and labels for languages beyond the most commonly spoken ones. To improve performance over languages, we propose a denoising autoencoder with semi-supervision using a continuous metric loss based on either activation or valence. The novelty of this work lies in our proposal of continuous metric learning, which is among the first proposals on the topic to the best of our knowledge. Furthermore, to address the lack of activation and valence labels in the transfer datasets, we annotate the signal samples with activation and valence levels corresponding to a dimensional model of emotions, which were then used to evaluate the quality of the embedding over the transfer datasets. We show that the proposed semi-supervised model consistently outperforms the baseline unsupervised method, which is a conventional denoising autoencoder, in terms of emotion classification accuracy as well as correlation with respect to the dimensional variables. Further evaluation of classification accuracy with respect to the reference, a BERT based speech representation model, shows that the proposed method is comparable to the reference method in classifying specific emotion classes at a much lower complexity.
Lead2Gold: Towards exploiting the full potential of noisy transcriptions for speech recognition
Oct 16, 2019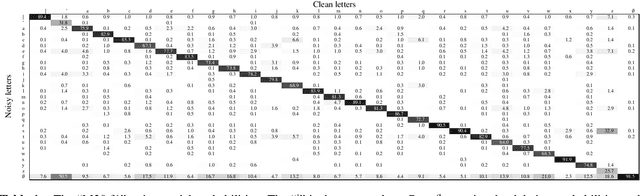
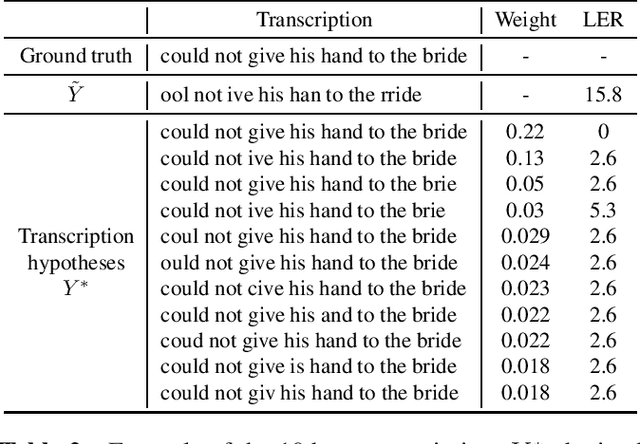
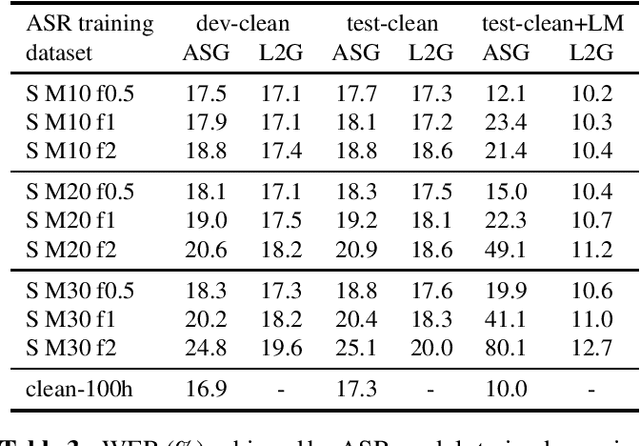
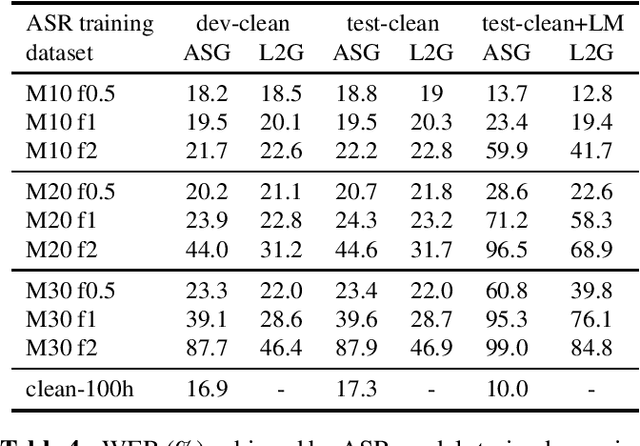
The transcriptions used to train an Automatic Speech Recognition (ASR) system may contain errors. Usually, either a quality control stage discards transcriptions with too many errors, or the noisy transcriptions are used as is. We introduce Lead2Gold, a method to train an ASR system that exploits the full potential of noisy transcriptions. Based on a noise model of transcription errors, Lead2Gold searches for better transcriptions of the training data with a beam search that takes this noise model into account. The beam search is differentiable and does not require a forced alignment step, thus the whole system is trained end-to-end. Lead2Gold can be viewed as a new loss function that can be used on top of any sequence-to-sequence deep neural network. We conduct proof-of-concept experiments on noisy transcriptions generated from letter corruptions with different noise levels. We show that Lead2Gold obtains a better ASR accuracy than a competitive baseline which does not account for the (artificially-introduced) transcription noise.
Does Speech enhancement of publicly available data help build robust Speech Recognition Systems?
Nov 20, 2019
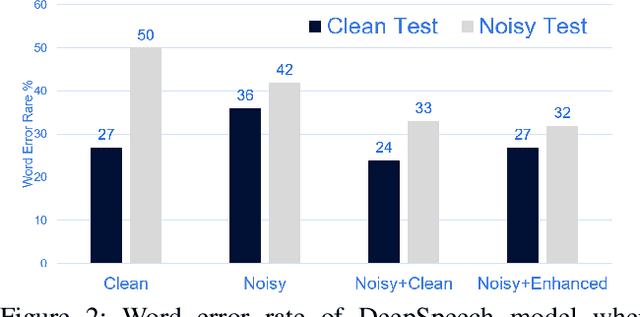
Automatic speech recognition (ASR) systems play a key role in many commercial products including voice assistants. Typically, they require large amounts of clean speech data for training which gives an undue advantage to large organizations which have tons of private data. In this paper, we have first curated a fairly big dataset using publicly available data sources. Thereafter, we tried to investigate if we can use publicly available noisy data to train robust ASR systems. We have used speech enhancement to clean the noisy data first and then used it together with its cleaned version to train ASR systems. We have found that using speech enhancement gives 9.5\% better word error rate than training on just noisy data and 9\% better than training on just clean data. It's performance is also comparable to the ideal case scenario when trained on noisy and its clean version.
Effectiveness of Mining Audio and Text Pairs from Public Data for Improving ASR Systems for Low-Resource Languages
Aug 26, 2022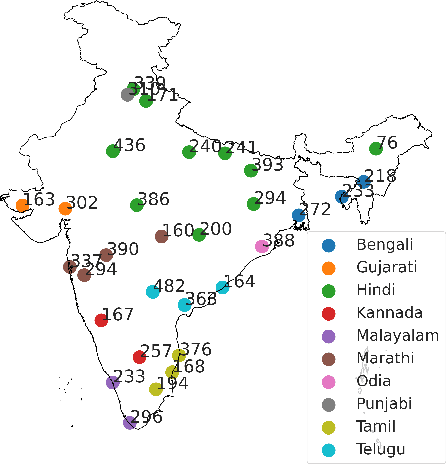
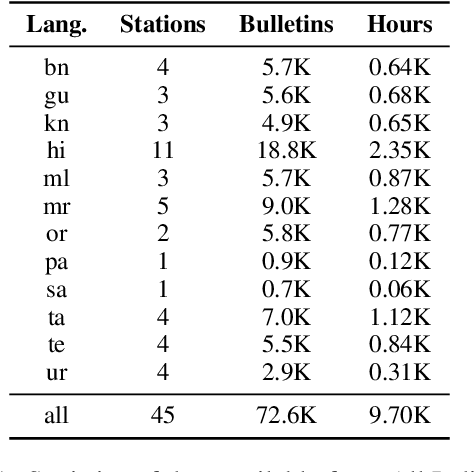

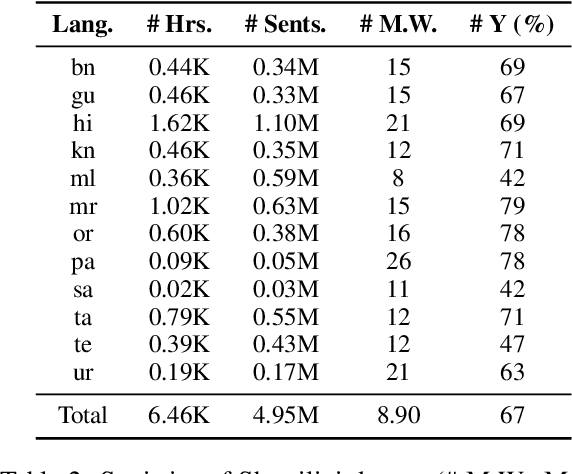
End-to-end (E2E) models have become the default choice for state-of-the-art speech recognition systems. Such models are trained on large amounts of labelled data, which are often not available for low-resource languages. Techniques such as self-supervised learning and transfer learning hold promise, but have not yet been effective in training accurate models. On the other hand, collecting labelled datasets on a diverse set of domains and speakers is very expensive. In this work, we demonstrate an inexpensive and effective alternative to these approaches by ``mining'' text and audio pairs for Indian languages from public sources, specifically from the public archives of All India Radio. As a key component, we adapt the Needleman-Wunsch algorithm to align sentences with corresponding audio segments given a long audio and a PDF of its transcript, while being robust to errors due to OCR, extraneous text, and non-transcribed speech. We thus create Shrutilipi, a dataset which contains over 6,400 hours of labelled audio across 12 Indian languages totalling to 4.95M sentences. On average, Shrutilipi results in a 2.3x increase over publicly available labelled data. We establish the quality of Shrutilipi with 21 human evaluators across the 12 languages. We also establish the diversity of Shrutilipi in terms of represented regions, speakers, and mentioned named entities. Significantly, we show that adding Shrutilipi to the training set of Wav2Vec models leads to an average decrease in WER of 5.8\% for 7 languages on the IndicSUPERB benchmark. For Hindi, which has the most benchmarks (7), the average WER falls from 18.8% to 13.5%. This improvement extends to efficient models: We show a 2.3% drop in WER for a Conformer model (10x smaller than Wav2Vec). Finally, we demonstrate the diversity of Shrutilipi by showing that the model trained with it is more robust to noisy input.