 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Byte-level Representation for End-to-end ASR
Jun 14, 2024We propose a novel approach to optimizing a byte-level representation for end-to-end automatic speech recognition (ASR). Byte-level representation is often used by large scale multilingual ASR systems when the character set of the supported languages is large. The compactness and universality of byte-level representation allow the ASR models to use smaller output vocabularies and therefore, provide more flexibility. UTF-8 is a commonly used byte-level representation for multilingual ASR, but it is not designed to optimize machine learning tasks directly. By using auto-encoder and vector quantization, we show that we can optimize a byte-level representation for ASR and achieve better accuracy. Our proposed framework can incorporate information from different modalities, and provides an error correction mechanism. In an English/Mandarin dictation task, we show that a bilingual ASR model built with this approach can outperform UTF-8 representation by 5% relative in error rate.
Cross-lingual Knowledge Transfer and Iterative Pseudo-labeling for Low-Resource Speech Recognition with Transducers
May 23, 2023



Voice technology has become ubiquitous recently. However, the accuracy, and hence experience, in different languages varies significantly, which makes the technology not equally inclusive. The availability of data for different languages is one of the key factors affecting accuracy, especially in training of all-neural end-to-end automatic speech recognition systems. Cross-lingual knowledge transfer and iterative pseudo-labeling are two techniques that have been shown to be successful for improving the accuracy of ASR systems, in particular for low-resource languages, like Ukrainian. Our goal is to train an all-neural Transducer-based ASR system to replace a DNN-HMM hybrid system with no manually annotated training data. We show that the Transducer system trained using transcripts produced by the hybrid system achieves 18% reduction in terms of word error rate. However, using a combination of cross-lingual knowledge transfer from related languages and iterative pseudo-labeling, we are able to achieve 35% reduction of the error rate.
Bilingual End-to-End ASR with Byte-Level Subwords
May 01, 2022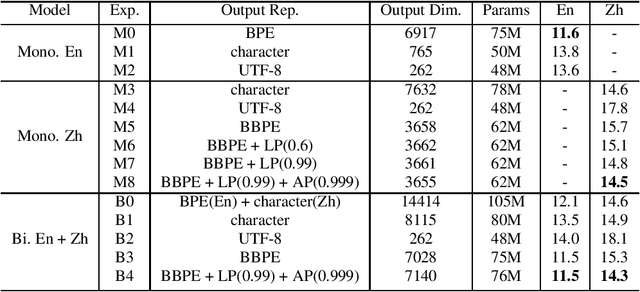
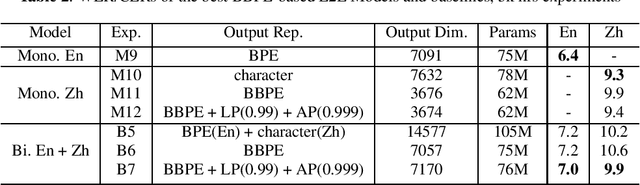
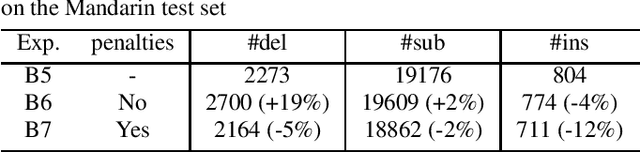
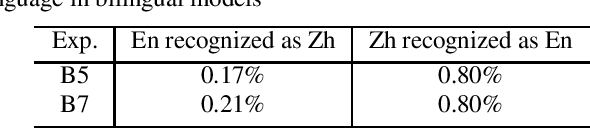
In this paper, we investigate how the output representation of an end-to-end neural network affects multilingual automatic speech recognition (ASR). We study different representations including character-level, byte-level, byte pair encoding (BPE), and byte-level byte pair encoding (BBPE) representations, and analyze their strengths and weaknesses. We focus on developing a single end-to-end model to support utterance-based bilingual ASR, where speakers do not alternate between two languages in a single utterance but may change languages across utterances. We conduct our experiments on English and Mandarin dictation tasks, and we find that BBPE with penalty schemes can improve utterance-based bilingual ASR performance by 2% to 5% relative even with smaller number of outputs and fewer parameters. We conclude with analysis that indicates directions for further improving multilingual ASR.