 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Quantization of Generative Adversarial Networks for Efficient Inference: a Methodological Study
Aug 31, 2021
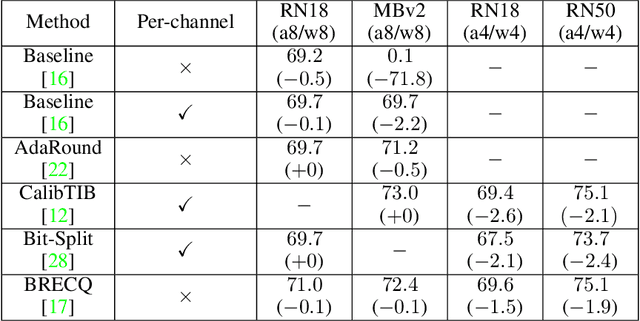
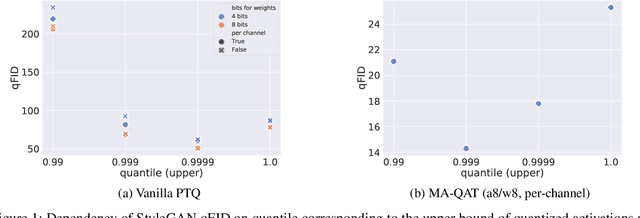
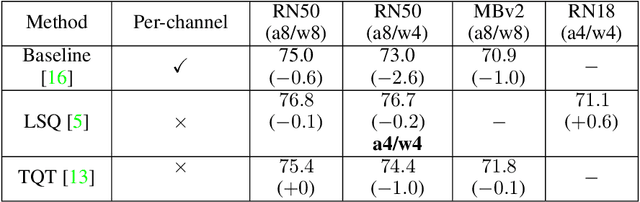

Generative adversarial networks (GANs) have an enormous potential impact on digital content creation, e.g., photo-realistic digital avatars, semantic content editing, and quality enhancement of speech and images. However, the performance of modern GANs comes together with massive amounts of computations performed during the inference and high energy consumption. That complicates, or even makes impossible, their deployment on edge devices. The problem can be reduced with quantization -- a neural network compression technique that facilitates hardware-friendly inference by replacing floating-point computations with low-bit integer ones. While quantization is well established for discriminative models, the performance of modern quantization techniques in application to GANs remains unclear. GANs generate content of a more complex structure than discriminative models, and thus quantization of GANs is significantly more challenging. To tackle this problem, we perform an extensive experimental study of state-of-art quantization techniques on three diverse GAN architectures, namely StyleGAN, Self-Attention GAN, and CycleGAN. As a result, we discovered practical recipes that allowed us to successfully quantize these models for inference with 4/8-bit weights and 8-bit activations while preserving the quality of the original full-precision models.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

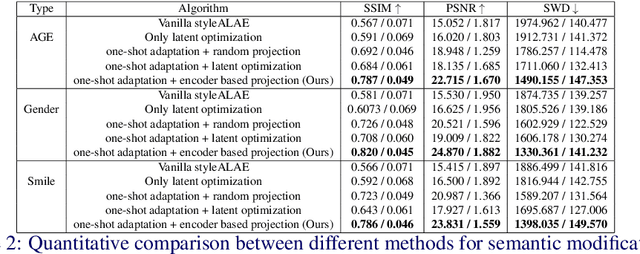

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
ReflectNet -- A Generative Adversarial Method for Single Image Reflection Suppression
May 11, 2021
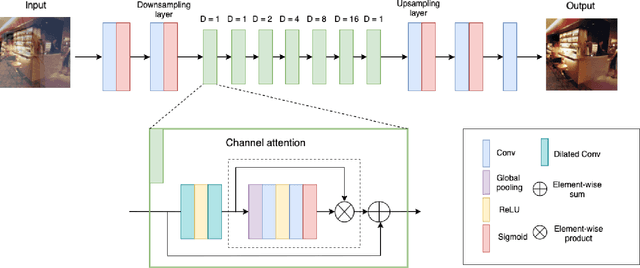


Taking pictures through glass windows almost always produces undesired reflections that degrade the quality of the photo. The ill-posed nature of the reflection removal problem reached the attention of many researchers for more than decades. The main challenge of this problem is the lack of real training data and the necessity of generating realistic synthetic data. In this paper, we proposed a single image reflection removal method based on context understanding modules and adversarial training to efficiently restore the transmission layer without reflection. We also propose a complex data generation model in order to create a large training set with various type of reflections. Our proposed reflection removal method outperforms state-of-the-art methods in terms of PSNR and SSIM on the SIR benchmark dataset.
Uncertainty-aware GAN with Adaptive Loss for Robust MRI Image Enhancement
Oct 07, 2021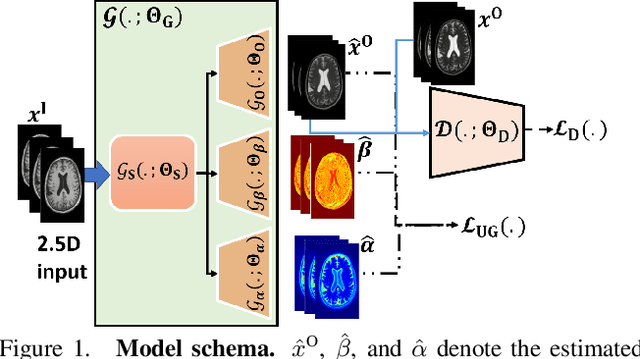
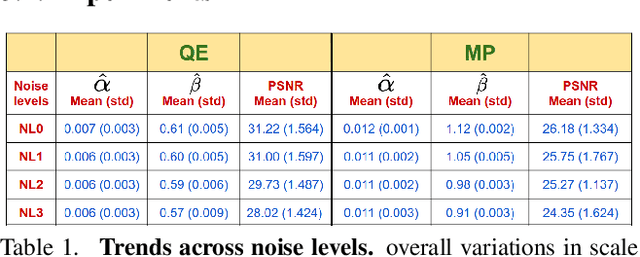
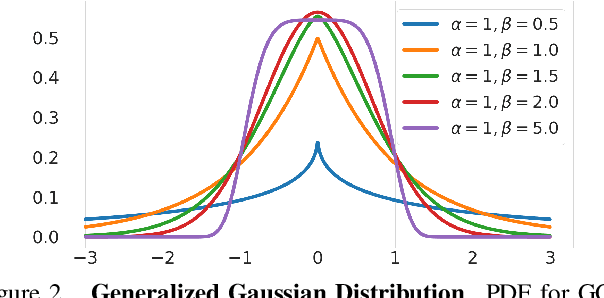
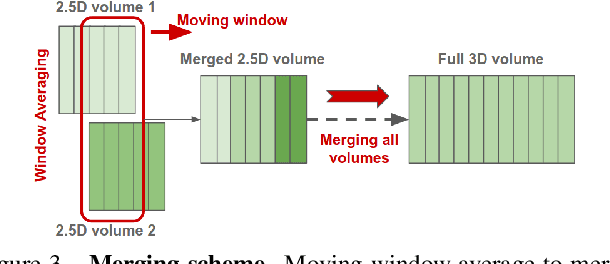
Image-to-image translation is an ill-posed problem as unique one-to-one mapping may not exist between the source and target images. Learning-based methods proposed in this context often evaluate the performance on test data that is similar to the training data, which may be impractical. This demands robust methods that can quantify uncertainty in the prediction for making informed decisions, especially for critical areas such as medical imaging. Recent works that employ conditional generative adversarial networks (GANs) have shown improved performance in learning photo-realistic image-to-image mappings between the source and the target images. However, these methods do not focus on (i)~robustness of the models to out-of-distribution (OOD)-noisy data and (ii)~uncertainty quantification. This paper proposes a GAN-based framework that (i)~models an adaptive loss function for robustness to OOD-noisy data that automatically tunes the spatially varying norm for penalizing the residuals and (ii)~estimates the per-voxel uncertainty in the predictions. We demonstrate our method on two key applications in medical imaging: (i)~undersampled magnetic resonance imaging (MRI) reconstruction (ii)~MRI modality propagation. Our experiments with two different real-world datasets show that the proposed method (i)~is robust to OOD-noisy test data and provides improved accuracy and (ii)~quantifies voxel-level uncertainty in the predictions.
Identity Signals in Emoji Do not Influence Perception of Factual Truth on Twitter
May 07, 2021
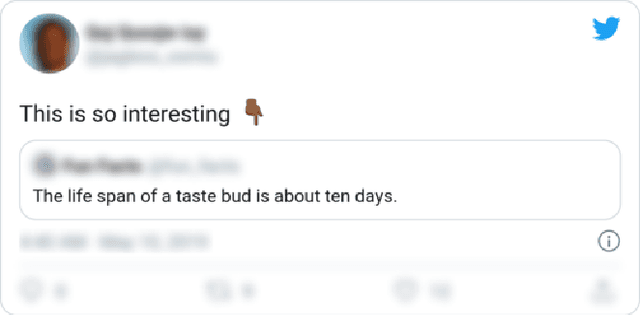
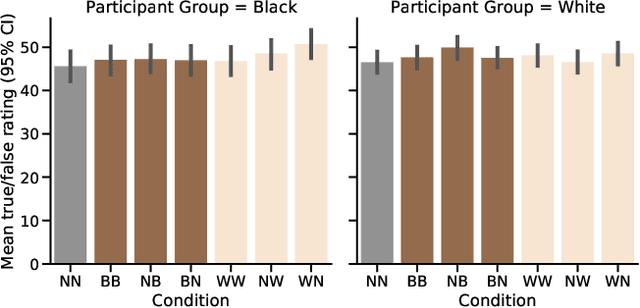
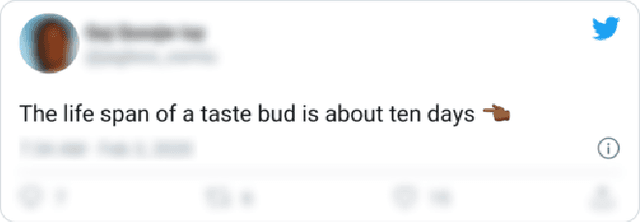
Prior work has shown that Twitter users use skin-toned emoji as an act of self-representation to express their racial/ethnic identity. We test whether this signal of identity can influence readers' perceptions about the content of a post containing that signal. In a large scale (n=944) pre-registered controlled experiment, we manipulate the presence of skin-toned emoji and profile photos in a task where readers rate obscure trivia facts (presented as tweets) as true or false. Using a Bayesian statistical analysis, we find that neither emoji nor profile photo has an effect on how readers rate these facts. This result will be of some comfort to anyone concerned about the manipulation of online users through the crafting of fake profiles.
Self-supervised Outdoor Scene Relighting
Jul 07, 2021
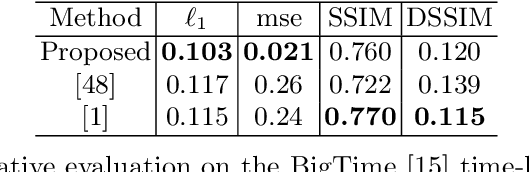
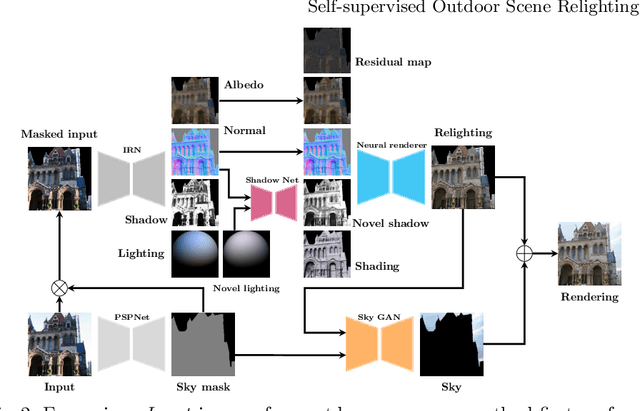
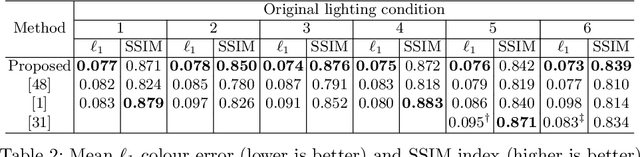
Outdoor scene relighting is a challenging problem that requires good understanding of the scene geometry, illumination and albedo. Current techniques are completely supervised, requiring high quality synthetic renderings to train a solution. Such renderings are synthesized using priors learned from limited data. In contrast, we propose a self-supervised approach for relighting. Our approach is trained only on corpora of images collected from the internet without any user-supervision. This virtually endless source of training data allows training a general relighting solution. Our approach first decomposes an image into its albedo, geometry and illumination. A novel relighting is then produced by modifying the illumination parameters. Our solution capture shadow using a dedicated shadow prediction map, and does not rely on accurate geometry estimation. We evaluate our technique subjectively and objectively using a new dataset with ground-truth relighting. Results show the ability of our technique to produce photo-realistic and physically plausible results, that generalizes to unseen scenes.
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Mar 05, 2020
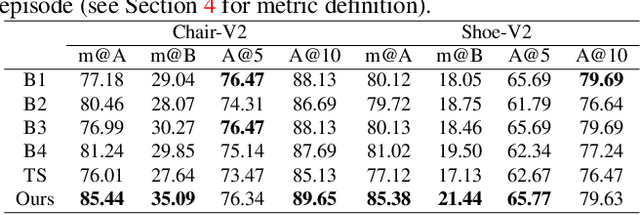
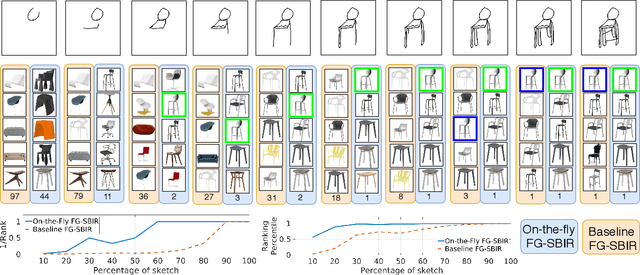
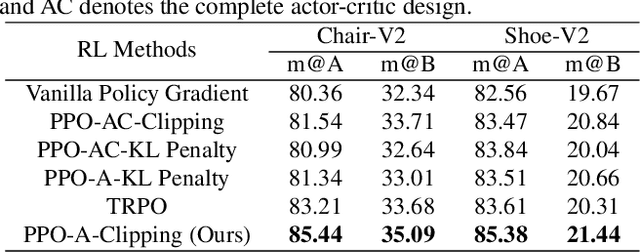
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
VolNet: Estimating Human Body Part Volumes from a Single RGB Image
Jul 05, 2021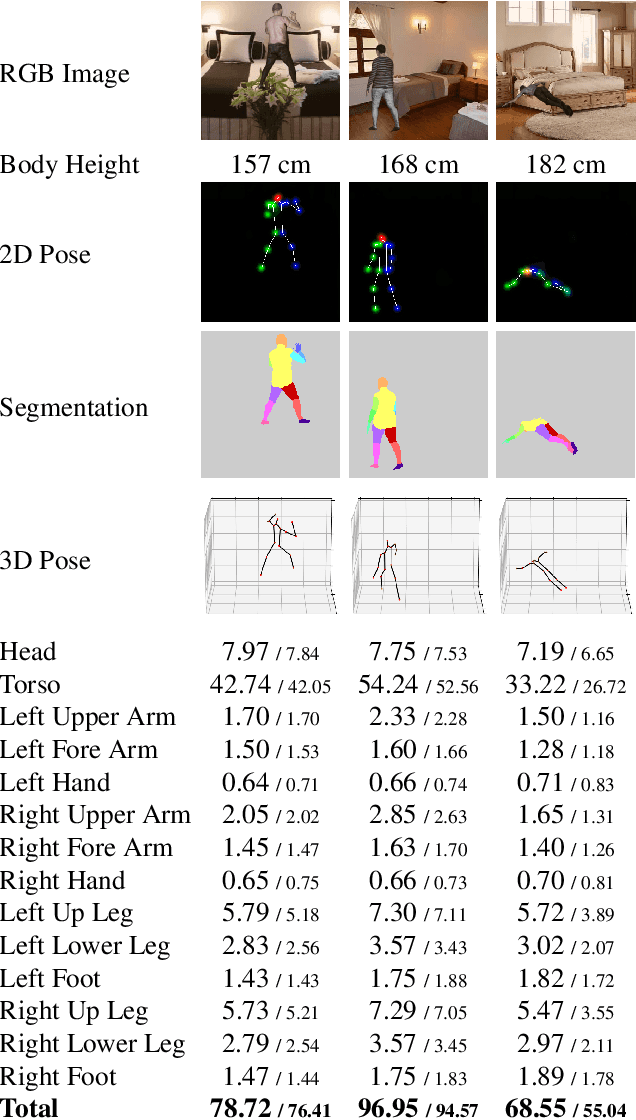
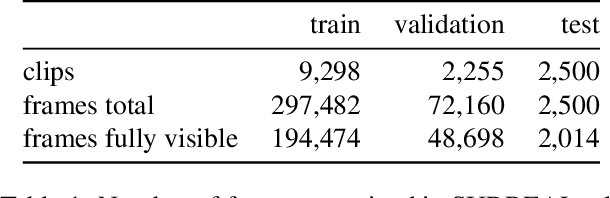
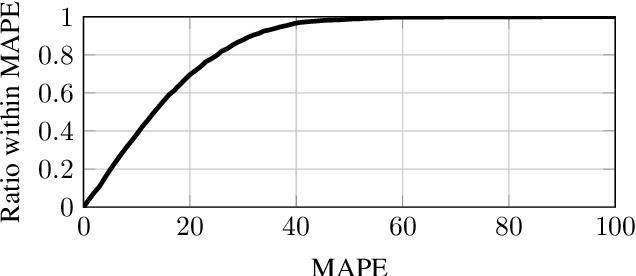
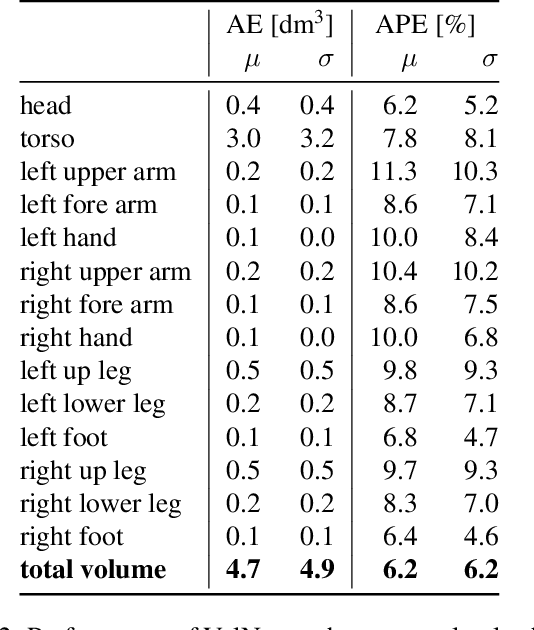
Human body volume estimation from a single RGB image is a challenging problem despite minimal attention from the research community. However VolNet, an architecture leveraging 2D and 3D pose estimation, body part segmentation and volume regression extracted from a single 2D RGB image combined with the subject's body height can be used to estimate the total body volume. VolNet is designed to predict the 2D and 3D pose as well as the body part segmentation in intermediate tasks. We generated a synthetic, large-scale dataset of photo-realistic images of human bodies with a wide range of body shapes and realistic poses called SURREALvols. By using Volnet and combining multiple stacked hourglass networks together with ResNeXt, our model correctly predicted the volume in ~82% of cases with a 10% tolerance threshold. This is a considerable improvement compared to state-of-the-art solutions such as BodyNet with only a ~38% success rate.
DeepFacePencil: Creating Face Images from Freehand Sketches
Aug 31, 2020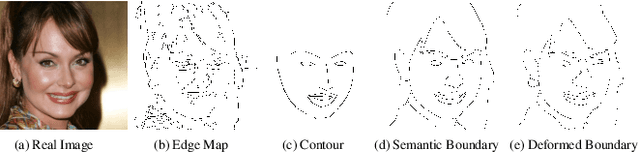

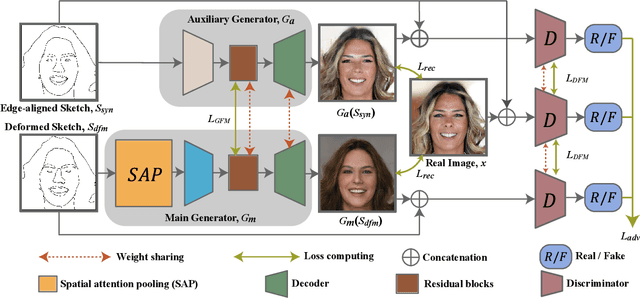
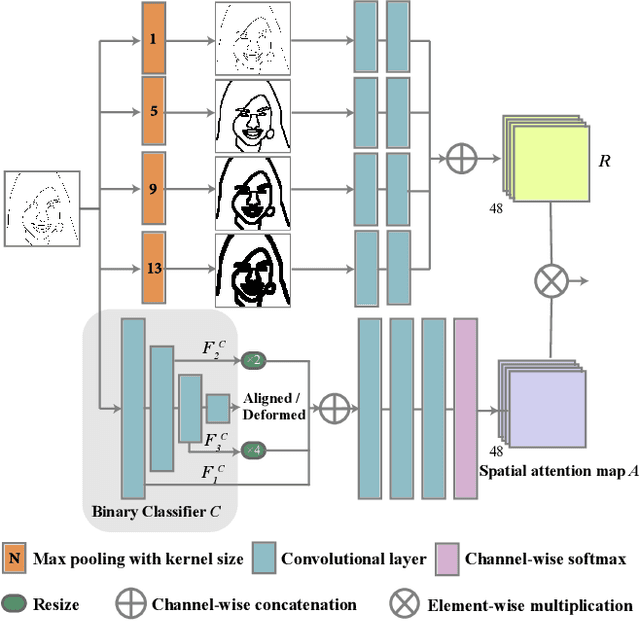
In this paper, we explore the task of generating photo-realistic face images from hand-drawn sketches. Existing image-to-image translation methods require a large-scale dataset of paired sketches and images for supervision. They typically utilize synthesized edge maps of face images as training data. However, these synthesized edge maps strictly align with the edges of the corresponding face images, which limit their generalization ability to real hand-drawn sketches with vast stroke diversity. To address this problem, we propose DeepFacePencil, an effective tool that is able to generate photo-realistic face images from hand-drawn sketches, based on a novel dual generator image translation network during training. A novel spatial attention pooling (SAP) is designed to adaptively handle stroke distortions which are spatially varying to support various stroke styles and different levels of details. We conduct extensive experiments and the results demonstrate the superiority of our model over existing methods on both image quality and model generalization to hand-drawn sketches.