 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFontFusion: Enhancing Generative Text in Diffusion Models with Typographic Conditioning
Jun 04, 2026Typography generation in diffusion models faces a persistent trade-off: enabling precise font control typically degrades text legibility, while maintaining readability often sacrifices typographic fidelity. We present FontFusion, a plug-and-play conditioning framework for Diffusion Transformer (DiT) architectures that resolves this dilemma through three core innovations: (1) a hierarchical token representation establishing explicit text-font relationships at multiple granularities, (2) position-aware embeddings creating spatial bindings between typography and image content, and (3) a multi-level token dropping strategy improving both computational efficiency and generalization to unseen fonts. Our systematic evaluation of font embedding spaces reveals that a dual encoder combining DeepFont and DINOv2 outperforms any single encoder for typography tasks. FontFusion demonstrates 76% relative improvement on challenging decorative fonts over single-encoder baselines and font consistency gains exceeding approximately 68-76% over unconditioned models, while integrating into existing DiT architectures without retraining.
LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition
Mar 18, 2026Media design layer generation enables the creation of fully editable, layered design documents such as posters, flyers, and logos using only natural language prompts. Existing methods either restrict outputs to a fixed number of layers or require each layer to contain only spatially continuous regions, causing the layer count to scale linearly with design complexity. We propose LaDe (Layered Media Design), a latent diffusion framework that generates a flexible number of semantically meaningful layers. LaDe combines three components: an LLM-based prompt expander that transforms a short user intent into structured per-layer descriptions that guide the generation, a Latent Diffusion Transformer with a 4D RoPE positional encoding mechanism that jointly generates the full media design and its constituent RGBA layers, and an RGBA VAE that decodes each layer with full alpha-channel support. By conditioning on layer samples during training, our unified framework supports three tasks: text-to-image generation, text-to-layers media design generation, and media design decomposition. We compare LaDe to Qwen-Image-Layered on text-to-layers and image-to-layers tasks on the Crello test set. LaDe outperforms Qwen-Image-Layered in text-to-layers generation by improving text-to-layer alignment, as validated by two VLM-as-a-judge evaluators (GPT-4o mini and Qwen3-VL).
Generative Adversarial Training for Text-to-Speech Synthesis Based on Raw Phonetic Input and Explicit Prosody Modelling
Oct 14, 2023



We describe an end-to-end speech synthesis system that uses generative adversarial training. We train our Vocoder for raw phoneme-to-audio conversion, using explicit phonetic, pitch and duration modeling. We experiment with several pre-trained models for contextualized and decontextualized word embeddings and we introduce a new method for highly expressive character voice matching, based on discreet style tokens.
A Fast Deep Learning Network for Automatic Image Auto-Straightening
May 12, 2021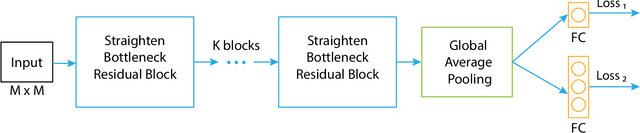
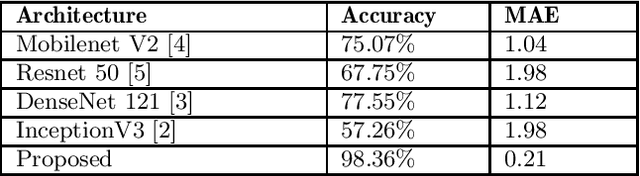
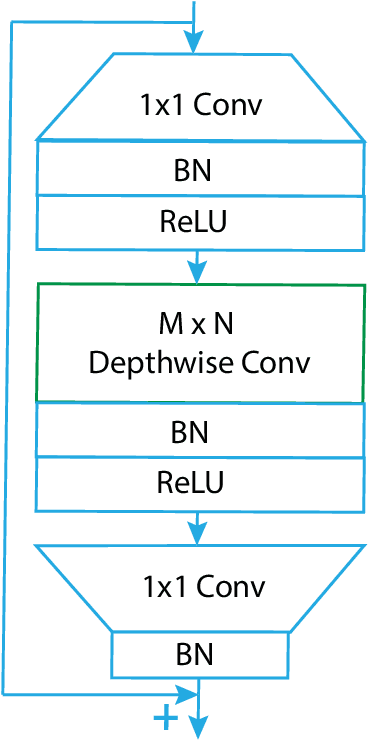
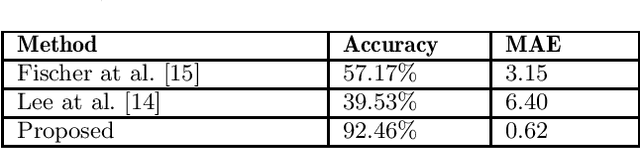
Rectifying the orientation of images represents a daily task for every photographer. This task may be complicated even for the human eye, especially when the horizon or other horizontal and vertical lines in the image are missing. In this paper we address this problem and propose a new deep learning network specially adapted for image rotation correction: we introduce the rectangle-shaped depthwise convolutions which are specialized in detecting long lines from the image and a new adapted loss function that addresses the problem of orientation errors. Compared to other methods that are able to detect rotation errors only on few image categories, like man-made structures, the proposed method can be used on a larger variety of photographs e.g., portraits, landscapes, sport, night photos etc. Moreover, the model is adapted to mobile devices and can be run in real time, both for pictures and for videos. An extensive evaluation of our model on different datasets shows that it remarkably generalizes, not being dependent on any particular type of image. Finally, we significantly outperform the state-of-the-art methods, providing superior results.
ReflectNet -- A Generative Adversarial Method for Single Image Reflection Suppression
May 11, 2021
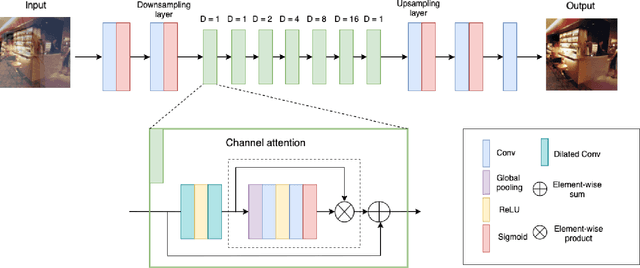


Taking pictures through glass windows almost always produces undesired reflections that degrade the quality of the photo. The ill-posed nature of the reflection removal problem reached the attention of many researchers for more than decades. The main challenge of this problem is the lack of real training data and the necessity of generating realistic synthetic data. In this paper, we proposed a single image reflection removal method based on context understanding modules and adversarial training to efficiently restore the transmission layer without reflection. We also propose a complex data generation model in order to create a large training set with various type of reflections. Our proposed reflection removal method outperforms state-of-the-art methods in terms of PSNR and SSIM on the SIR benchmark dataset.