 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Neural content-aware collaborative filtering for cold-start music recommendation
Feb 24, 2021
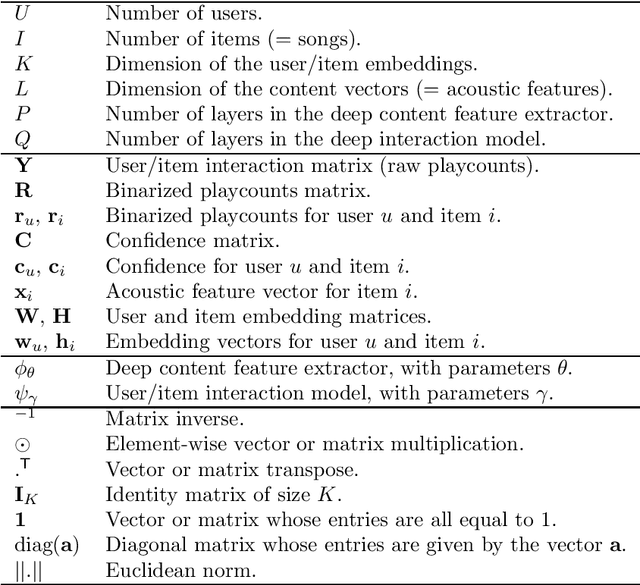
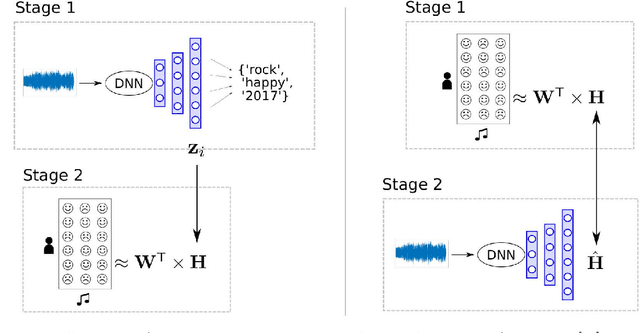
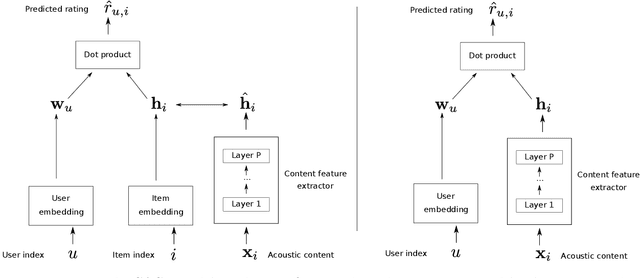
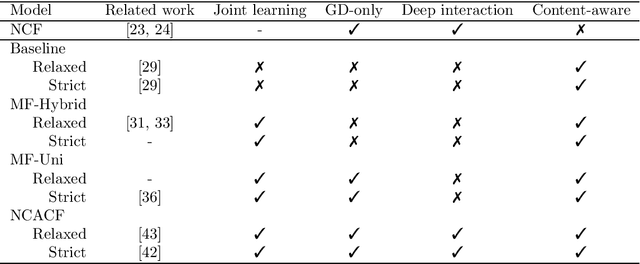
State-of-the-art music recommender systems are based on collaborative filtering, which builds upon learning similarities between users and songs from the available listening data. These approaches inherently face the cold-start problem, as they cannot recommend novel songs with no listening history. Content-aware recommendation addresses this issue by incorporating content information about the songs on top of collaborative filtering. However, methods falling in this category rely on a shallow user/item interaction that originates from a matrix factorization framework. In this work, we introduce neural content-aware collaborative filtering, a unified framework which alleviates these limits, and extends the recently introduced neural collaborative filtering to its content-aware counterpart. We propose a generative model which leverages deep learning for both extracting content information from low-level acoustic features and for modeling the interaction between users and songs embeddings. The deep content feature extractor can either directly predict the item embedding, or serve as a regularization prior, yielding two variants (strict and relaxed) of our model. Experimental results show that the proposed method reaches state-of-the-art results for a cold-start music recommendation task. We notably observe that exploiting deep neural networks for learning refined user/item interactions outperforms approaches using a more simple interaction model in a content-aware framework.
Optimizing musical chord inversions using the cartesian coordinate system
Jun 10, 2022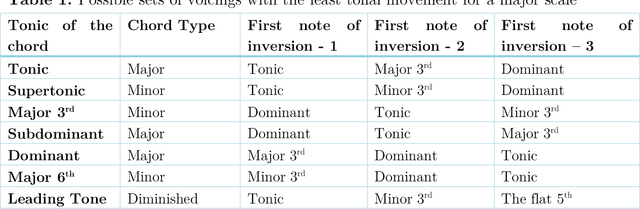

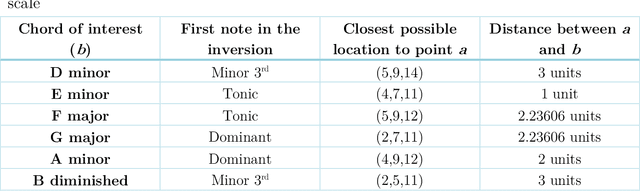
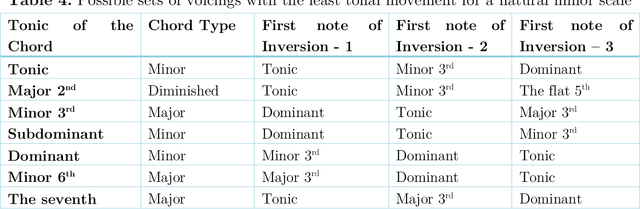
In classical music and in any genre of contemporary music, the tonal elements or notes used for playing are the same. The numerous possibilities of chords for a given instance in a piece make the playing, in general, very intricate, and advanced. The theory sounds quite trivial, yet the application has vast options, each leading to inarguably different outcomes, characterized by scientific and musical principles. Chords and their importance are self-explanatory. A chord is a bunch of notes played together. As far as scientists are concerned, it is a set of tonal frequencies ringing together resulting in a consonant/dissonant sound. It is well-known that the notes of a chord can be rearranged to come up with various voicings (1) of the same chord which enables a composer/player to choose the most optimal one to convey the emotion they wish to convey. Though there are numerous possibilities, it is scientific to think that there is just one appropriate voicing for a particular situation of tonal movements. In this study, we attempt to find the optimal voicings by considering chords to be points in a 3-dimensional cartesian coordinate system and further the fundamental understanding of mathematics in music theory.
Front-end Diarization for Percussion Separation in Taniavartanam of Carnatic Music Concerts
Mar 04, 2021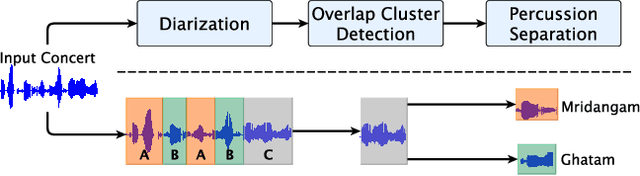
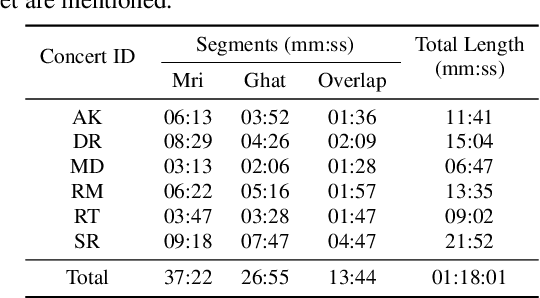
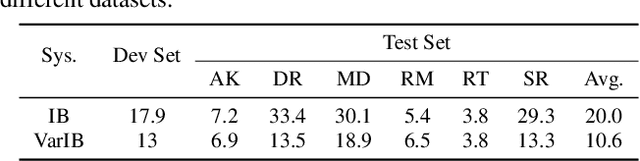
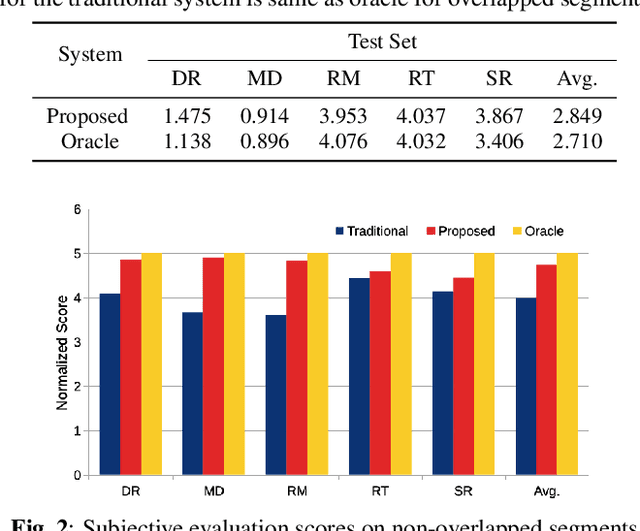
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.
Musical Word Embedding: Bridging the Gap between Listening Contexts and Music
Jul 23, 2020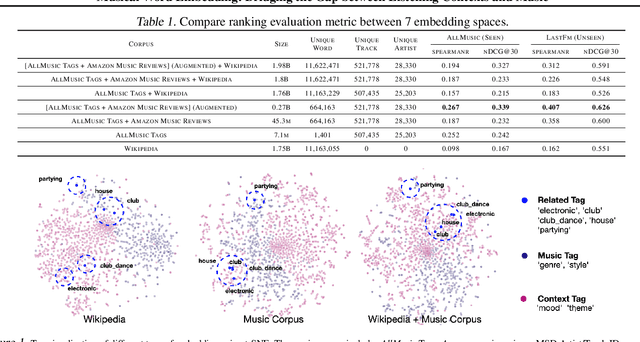
Word embedding pioneered by Mikolov et al. is a staple technique for word representations in natural language processing (NLP) research which has also found popularity in music information retrieval tasks. Depending on the type of text data for word embedding, however, vocabulary size and the degree of musical pertinence can significantly vary. In this work, we (1) train the distributed representation of words using combinations of both general text data and music-specific data and (2) evaluate the system in terms of how they associate listening contexts with musical compositions.
Markup-to-Image Diffusion Models with Scheduled Sampling
Oct 11, 2022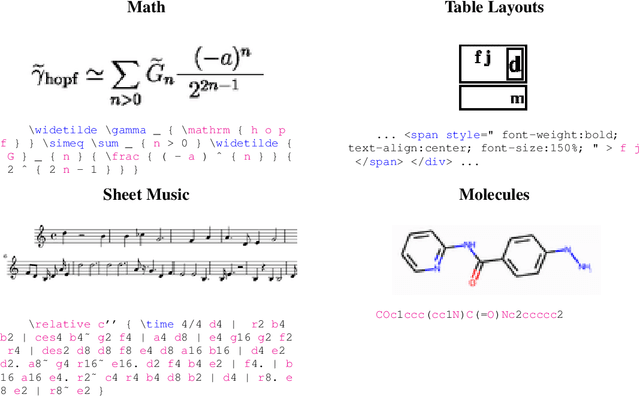

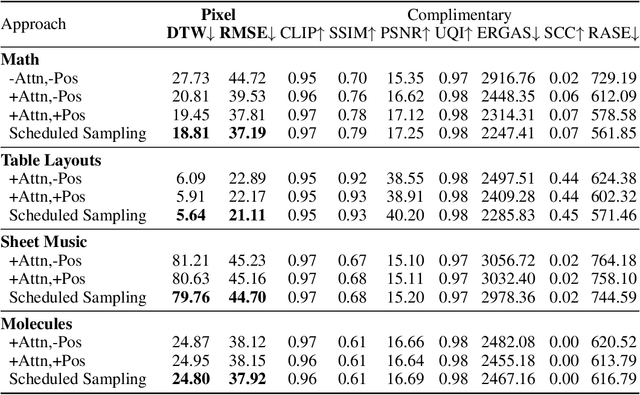
Building on recent advances in image generation, we present a fully data-driven approach to rendering markup into images. The approach is based on diffusion models, which parameterize the distribution of data using a sequence of denoising operations on top of a Gaussian noise distribution. We view the diffusion denoising process as a sequential decision making process, and show that it exhibits compounding errors similar to exposure bias issues in imitation learning problems. To mitigate these issues, we adapt the scheduled sampling algorithm to diffusion training. We conduct experiments on four markup datasets: mathematical formulas (LaTeX), table layouts (HTML), sheet music (LilyPond), and molecular images (SMILES). These experiments each verify the effectiveness of the diffusion process and the use of scheduled sampling to fix generation issues. These results also show that the markup-to-image task presents a useful controlled compositional setting for diagnosing and analyzing generative image models.
Compose & Embellish: Well-Structured Piano Performance Generation via A Two-Stage Approach
Sep 17, 2022
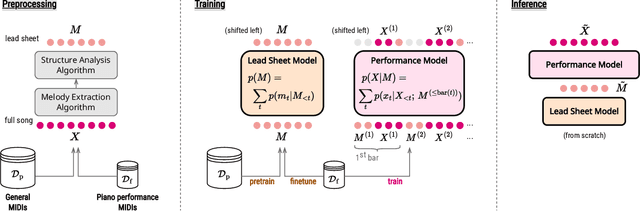
Even with strong sequence models like Transformers, generating expressive piano performances with long-range musical structures remains challenging. Meanwhile, methods to compose well-structured melodies or lead sheets (melody + chords), i.e., simpler forms of music, gained more success. Observing the above, we devise a two-stage Transformer-based framework that Composes a lead sheet first, and then Embellishes it with accompaniment and expressive touches. Such a factorization also enables pretraining on non-piano data. Our objective and subjective experiments show that Compose & Embellish shrinks the gap in structureness between a current state of the art and real performances by half, and improves other musical aspects such as richness and coherence as well.
SpectNet : End-to-End Audio Signal Classification Using Learnable Spectrograms
Nov 17, 2022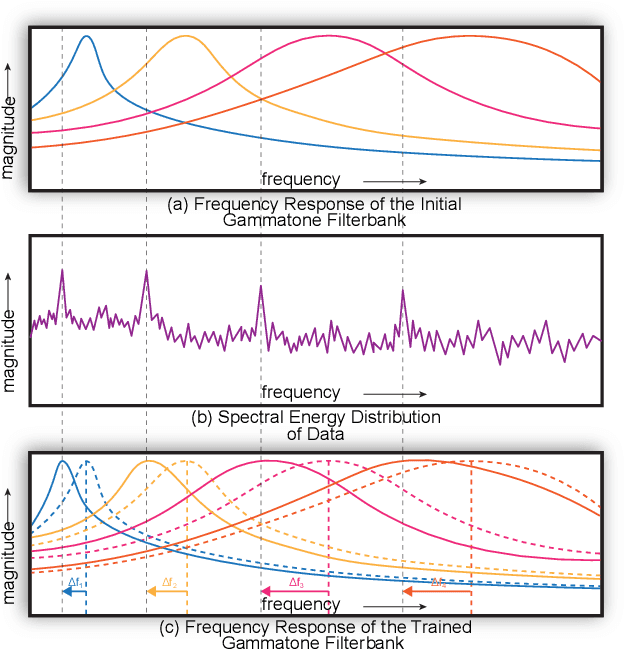
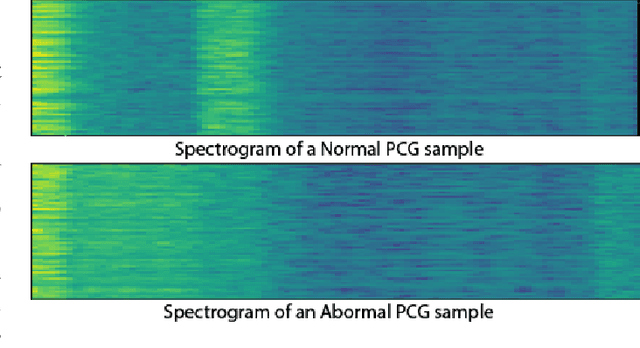
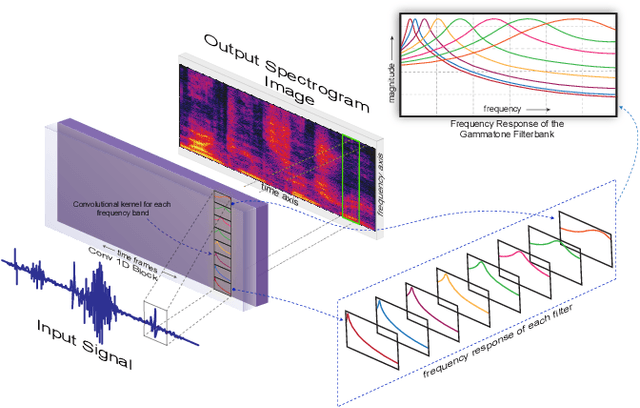
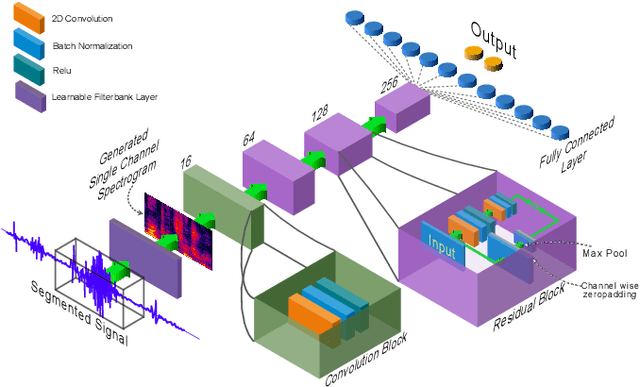
Pattern recognition from audio signals is an active research topic encompassing audio tagging, acoustic scene classification, music classification, and other areas. Spectrogram and mel-frequency cepstral coefficients (MFCC) are among the most commonly used features for audio signal analysis and classification. Recently, deep convolutional neural networks (CNN) have been successfully used for audio classification problems using spectrogram-based 2D features. In this paper, we present SpectNet, an integrated front-end layer that extracts spectrogram features within a CNN architecture that can be used for audio pattern recognition tasks. The front-end layer utilizes learnable gammatone filters that are initialized using mel-scale filters. The proposed layer outputs a 2D spectrogram image which can be fed into a 2D CNN for classification. The parameters of the entire network, including the front-end filterbank, can be updated via back-propagation. This training scheme allows for fine-tuning the spectrogram-image features according to the target audio dataset. The proposed method is evaluated in two different audio signal classification tasks: heart sound anomaly detection and acoustic scene classification. The proposed method shows a significant 1.02\% improvement in MACC for the heart sound classification task and 2.11\% improvement in accuracy for the acoustic scene classification task compared to the classical spectrogram image features. The source code of our experiments can be found at \url{https://github.com/mHealthBuet/SpectNet}
Self-Adaptive Named Entity Recognition by Retrieving Unstructured Knowledge
Oct 14, 2022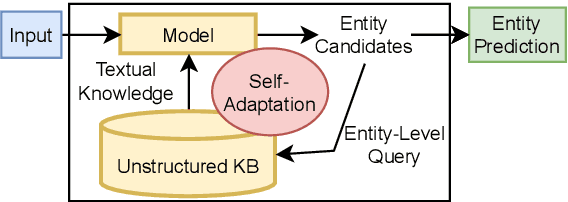
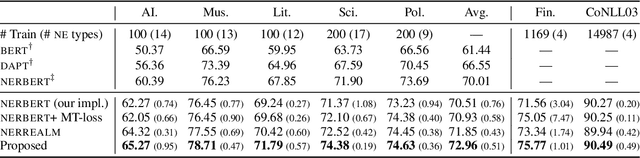
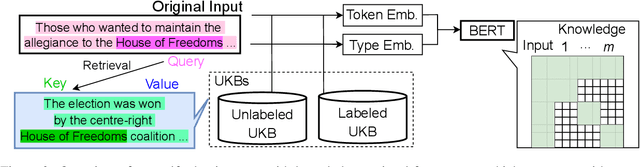
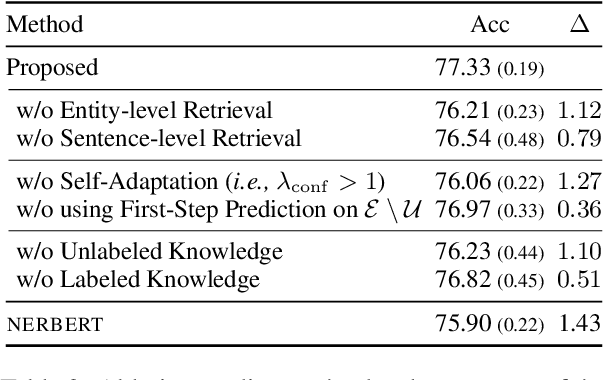
Although named entity recognition (NER) helps us to extract various domain-specific entities from text (e.g., artists in the music domain), it is costly to create a large amount of training data or a structured knowledge base to perform accurate NER in the target domain. Here, we propose self-adaptive NER, where the model retrieves the external knowledge from unstructured text to learn the usage of entities that has not been learned well. To retrieve useful knowledge for NER, we design an effective two-stage model that retrieves unstructured knowledge using uncertain entities as queries. Our model first predicts the entities in the input and then finds the entities of which the prediction is not confident. Then, our model retrieves knowledge by using these uncertain entities as queries and concatenates the retrieved text to the original input to revise the prediction. Experiments on CrossNER datasets demonstrated that our model outperforms the strong NERBERT baseline by 2.45 points on average.
Machine learning for music genre: multifaceted review and experimentation with audioset
Nov 28, 2019
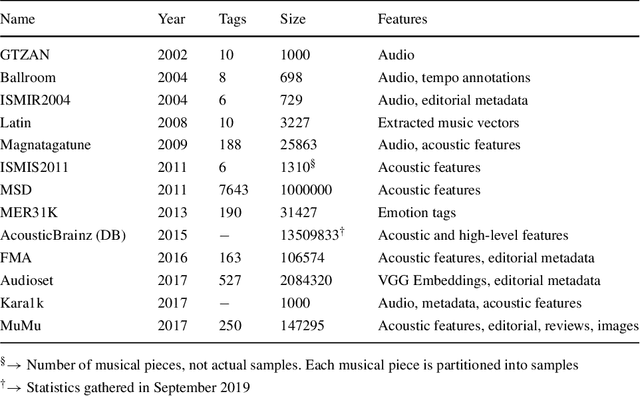
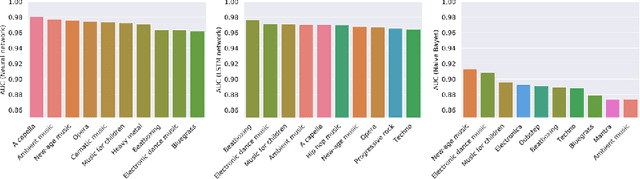
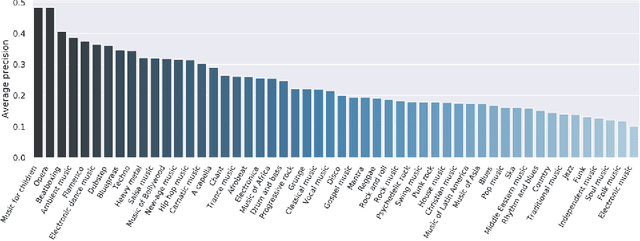
Music genre classification is one of the sub-disciplines of music information retrieval (MIR) with growing popularity among researchers, mainly due to the already open challenges. Although research has been prolific in terms of number of published works, the topic still suffers from a problem in its foundations: there is no clear and formal definition of what genre is. Music categorizations are vague and unclear, suffering from human subjectivity and lack of agreement. In its first part, this paper offers a survey trying to cover the many different aspects of the matter. Its main goal is give the reader an overview of the history and the current state-of-the-art, exploring techniques and datasets used to the date, as well as identifying current challenges, such as this ambiguity of genre definitions or the introduction of human-centric approaches. The paper pays special attention to new trends in machine learning applied to the music annotation problem. Finally, we also include a music genre classification experiment that compares different machine learning models using Audioset.
The Jazz Transformer on the Front Line: Exploring the Shortcomings of AI-composed Music through Quantitative Measures
Aug 04, 2020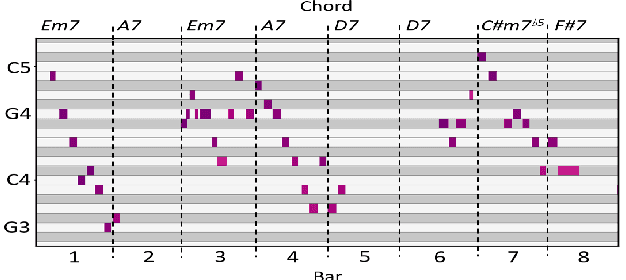
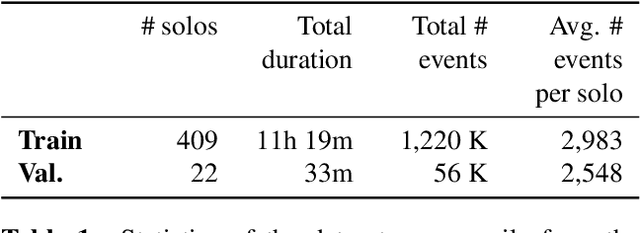
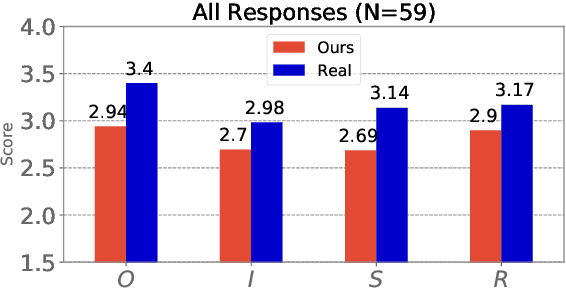
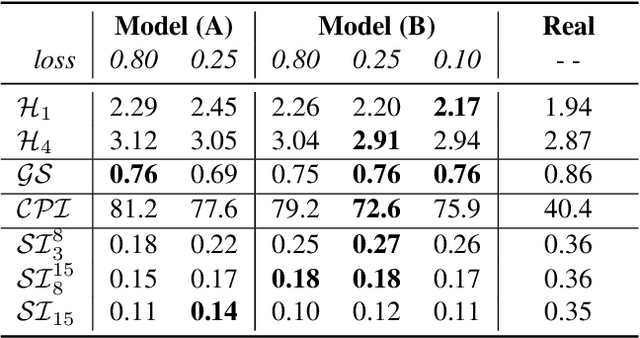
This paper presents the Jazz Transformer, a generative model that utilizes a neural sequence model called the Transformer-XL for modeling lead sheets of Jazz music. Moreover, the model endeavors to incorporate structural events present in the Weimar Jazz Database (WJazzD) for inducing structures in the generated music. While we are able to reduce the training loss to a low value, our listening test suggests however a clear gap between the average ratings of the generated and real compositions. We therefore go one step further and conduct a series of computational analysis of the generated compositions from different perspectives. This includes analyzing the statistics of the pitch class, grooving, and chord progression, assessing the structureness of the music with the help of the fitness scape plot, and evaluating the model's understanding of Jazz music through a MIREX-like continuation prediction task. Our work presents in an analytical manner why machine-generated music to date still falls short of the artwork of humanity, and sets some goals for future work on automatic composition to further pursue.