 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-centric Music Recommendations
May 16, 2025



This work presents a user-centric recommendation framework, designed as a pipeline with four distinct, connected, and customizable phases. These phases are intended to improve explainability and boost user engagement. We have collected the historical Last.fm track playback records of a single user over approximately 15 years. The collected dataset includes more than 90,000 playbacks and approximately 14,000 unique tracks. From track playback records, we have created a dataset of user temporal contexts (each row is a specific moment when the user listened to certain music descriptors). As music descriptors, we have used community-contributed Last.fm tags and Spotify audio features. They represent the music that, throughout years, the user has been listening to. Next, given the most relevant Last.fm tags of a moment (e.g. the hour of the day), we predict the Spotify audio features that best fit the user preferences in that particular moment. Finally, we use the predicted audio features to find tracks similar to these features. The final aim is to recommend (and discover) tracks that the user may feel like listening to at a particular moment. For our initial study case, we have chosen to predict only a single audio feature target: danceability. The framework, however, allows to include more target variables. The ability to learn the musical habits from a single user can be quite powerful, and this framework could be extended to other users.
Applying ranking techniques for estimating influence of Earth variables on temperature forecast error
Mar 12, 2024



This paper describes how to analyze the influence of Earth system variables on the errors when providing temperature forecasts. The initial framework to get the data has been based on previous research work, which resulted in a very interesting discovery. However, the aforementioned study only worked on individual correlations of the variables with respect to the error. This research work is going to re-use the main ideas but introduce three main novelties: (1) applying a data science approach by a few representative locations; (2) taking advantage of the rankings created by Spearman correlation but enriching them with other metrics looking for a more robust ranking of the variables; (3) evaluation of the methodology by learning random forest models for regression with the distinct experimental variations. The main contribution is the framework that shows how to convert correlations into rankings and combine them into an aggregate ranking. We have carried out experiments on five chosen locations to analyze the behavior of this ranking-based methodology. The results show that the specific performance is dependent on the location and season, which is expected, and that this selection technique works properly with Random Forest models but can also improve simpler regression models such as Bayesian Ridge. This work also contributes with an extensive analysis of the results. We can conclude that this selection based on the top-k ranked variables seems promising for this real problem, and it could also be applied in other domains.
Machine learning for music genre: multifaceted review and experimentation with audioset
Nov 28, 2019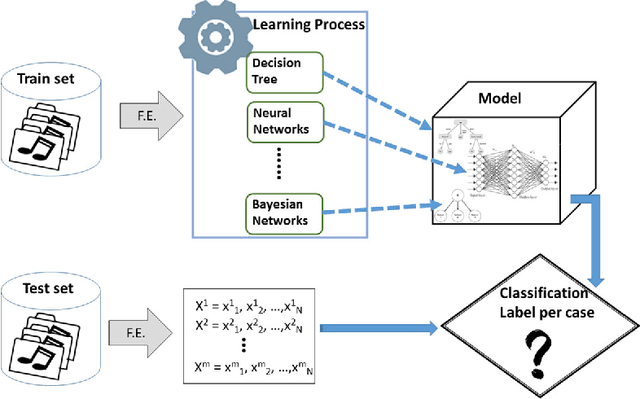
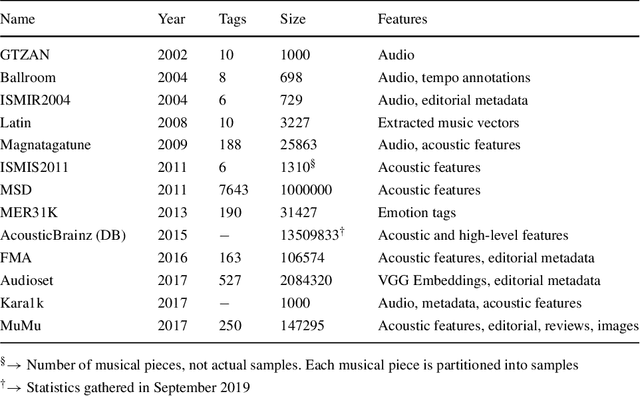
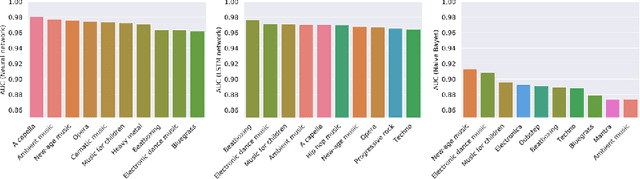
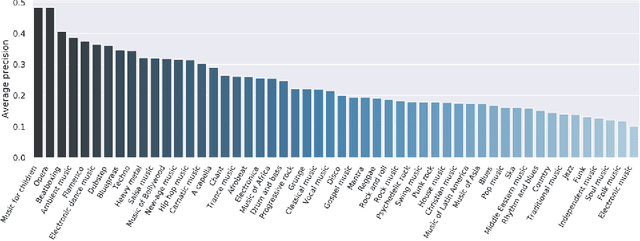
Music genre classification is one of the sub-disciplines of music information retrieval (MIR) with growing popularity among researchers, mainly due to the already open challenges. Although research has been prolific in terms of number of published works, the topic still suffers from a problem in its foundations: there is no clear and formal definition of what genre is. Music categorizations are vague and unclear, suffering from human subjectivity and lack of agreement. In its first part, this paper offers a survey trying to cover the many different aspects of the matter. Its main goal is give the reader an overview of the history and the current state-of-the-art, exploring techniques and datasets used to the date, as well as identifying current challenges, such as this ambiguity of genre definitions or the introduction of human-centric approaches. The paper pays special attention to new trends in machine learning applied to the music annotation problem. Finally, we also include a music genre classification experiment that compares different machine learning models using Audioset.