 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
ANIM-400K: A Large-Scale Dataset for Automated End-To-End Dubbing of Video
Jan 10, 2024
The Internet's wealth of content, with up to 60% published in English, starkly contrasts the global population, where only 18.8% are English speakers, and just 5.1% consider it their native language, leading to disparities in online information access. Unfortunately, automated processes for dubbing of video - replacing the audio track of a video with a translated alternative - remains a complex and challenging task due to pipelines, necessitating precise timing, facial movement synchronization, and prosody matching. While end-to-end dubbing offers a solution, data scarcity continues to impede the progress of both end-to-end and pipeline-based methods. In this work, we introduce Anim-400K, a comprehensive dataset of over 425K aligned animated video segments in Japanese and English supporting various video-related tasks, including automated dubbing, simultaneous translation, guided video summarization, and genre/theme/style classification. Our dataset is made publicly available for research purposes at https://github.com/davidmchan/Anim400K.
Controllable 3D Face Generation with Conditional Style Code Diffusion
Jan 11, 2024Generating photorealistic 3D faces from given conditions is a challenging task. Existing methods often rely on time-consuming one-by-one optimization approaches, which are not efficient for modeling the same distribution content, e.g., faces. Additionally, an ideal controllable 3D face generation model should consider both facial attributes and expressions. Thus we propose a novel approach called TEx-Face(TExt & Expression-to-Face) that addresses these challenges by dividing the task into three components, i.e., 3D GAN Inversion, Conditional Style Code Diffusion, and 3D Face Decoding. For 3D GAN inversion, we introduce two methods which aim to enhance the representation of style codes and alleviate 3D inconsistencies. Furthermore, we design a style code denoiser to incorporate multiple conditions into the style code and propose a data augmentation strategy to address the issue of insufficient paired visual-language data. Extensive experiments conducted on FFHQ, CelebA-HQ, and CelebA-Dialog demonstrate the promising performance of our TEx-Face in achieving the efficient and controllable generation of photorealistic 3D faces. The code will be available at https://github.com/sxl142/TEx-Face.
Construction and Evaluation of Mandarin Multimodal Emotional Speech Database
Jan 14, 2024A multi-modal emotional speech Mandarin database including articulatory kinematics, acoustics, glottal and facial micro-expressions is designed and established, which is described in detail from the aspects of corpus design, subject selection, recording details and data processing. Where signals are labeled with discrete emotion labels (neutral, happy, pleasant, indifferent, angry, sad, grief) and dimensional emotion labels (pleasure, arousal, dominance). In this paper, the validity of dimension annotation is verified by statistical analysis of dimension annotation data. The SCL-90 scale data of annotators are verified and combined with PAD annotation data for analysis, so as to explore the internal relationship between the outlier phenomenon in annotation and the psychological state of annotators. In order to verify the speech quality and emotion discrimination of the database, this paper uses 3 basic models of SVM, CNN and DNN to calculate the recognition rate of these seven emotions. The results show that the average recognition rate of seven emotions is about 82% when using acoustic data alone. When using glottal data alone, the average recognition rate is about 72%. Using kinematics data alone, the average recognition rate also reaches 55.7%. Therefore, the database is of high quality and can be used as an important source for speech analysis research, especially for the task of multimodal emotional speech analysis.
ProS: Facial Omni-Representation Learning via Prototype-based Self-Distillation
Nov 03, 2023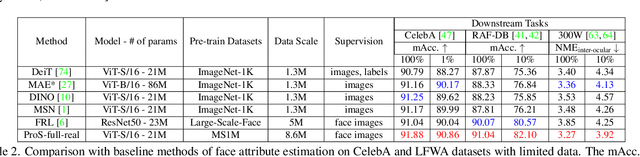
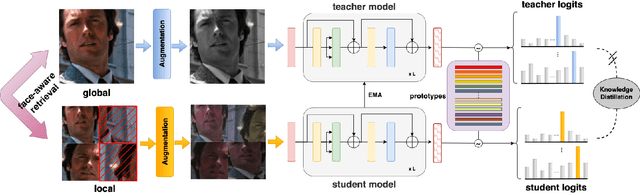
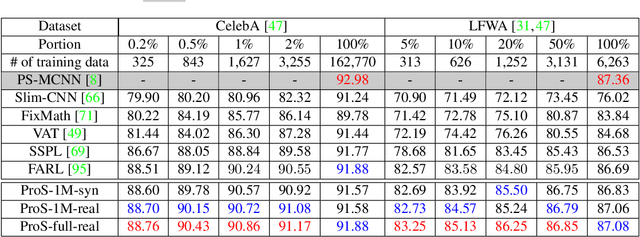

This paper presents a novel approach, called Prototype-based Self-Distillation (ProS), for unsupervised face representation learning. The existing supervised methods heavily rely on a large amount of annotated training facial data, which poses challenges in terms of data collection and privacy concerns. To address these issues, we propose ProS, which leverages a vast collection of unlabeled face images to learn a comprehensive facial omni-representation. In particular, ProS consists of two vision-transformers (teacher and student models) that are trained with different augmented images (cropping, blurring, coloring, etc.). Besides, we build a face-aware retrieval system along with augmentations to obtain the curated images comprising predominantly facial areas. To enhance the discrimination of learned features, we introduce a prototype-based matching loss that aligns the similarity distributions between features (teacher or student) and a set of learnable prototypes. After pre-training, the teacher vision transformer serves as a backbone for downstream tasks, including attribute estimation, expression recognition, and landmark alignment, achieved through simple fine-tuning with additional layers. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various tasks, both in full and few-shot settings. Furthermore, we investigate pre-training with synthetic face images, and ProS exhibits promising performance in this scenario as well.
Boosting Facial Action Unit Detection Through Jointly Learning Facial Landmark Detection and Domain Separation and Reconstruction
Oct 08, 2023Recently how to introduce large amounts of unlabeled facial images in the wild into supervised Facial Action Unit (AU) detection frameworks has become a challenging problem. In this paper, we propose a new AU detection framework where multi-task learning is introduced to jointly learn AU domain separation and reconstruction and facial landmark detection by sharing the parameters of homostructural facial extraction modules. In addition, we propose a new feature alignment scheme based on contrastive learning by simple projectors and an improved contrastive loss, which adds four additional intermediate supervisors to promote the feature reconstruction process. Experimental results on two benchmarks demonstrate our superiority against the state-of-the-art methods for AU detection in the wild.
Enhancing Generalization of Invisible Facial Privacy Cloak via Gradient Accumulation
Jan 03, 2024The blooming of social media and face recognition (FR) systems has increased people's concern about privacy and security. A new type of adversarial privacy cloak (class-universal) can be applied to all the images of regular users, to prevent malicious FR systems from acquiring their identity information. In this work, we discover the optimization dilemma in the existing methods -- the local optima problem in large-batch optimization and the gradient information elimination problem in small-batch optimization. To solve these problems, we propose Gradient Accumulation (GA) to aggregate multiple small-batch gradients into a one-step iterative gradient to enhance the gradient stability and reduce the usage of quantization operations. Experiments show that our proposed method achieves high performance on the Privacy-Commons dataset against black-box face recognition models.
Fast & Fair: Efficient Second-Order Robust Optimization for Fairness in Machine Learning
Jan 04, 2024This project explores adversarial training techniques to develop fairer Deep Neural Networks (DNNs) to mitigate the inherent bias they are known to exhibit. DNNs are susceptible to inheriting bias with respect to sensitive attributes such as race and gender, which can lead to life-altering outcomes (e.g., demographic bias in facial recognition software used to arrest a suspect). We propose a robust optimization problem, which we demonstrate can improve fairness in several datasets, both synthetic and real-world, using an affine linear model. Leveraging second order information, we are able to find a solution to our optimization problem more efficiently than a purely first order method.
Bridging Modalities: Knowledge Distillation and Masked Training for Translating Multi-Modal Emotion Recognition to Uni-Modal, Speech-Only Emotion Recognition
Jan 04, 2024This paper presents an innovative approach to address the challenges of translating multi-modal emotion recognition models to a more practical and resource-efficient uni-modal counterpart, specifically focusing on speech-only emotion recognition. Recognizing emotions from speech signals is a critical task with applications in human-computer interaction, affective computing, and mental health assessment. However, existing state-of-the-art models often rely on multi-modal inputs, incorporating information from multiple sources such as facial expressions and gestures, which may not be readily available or feasible in real-world scenarios. To tackle this issue, we propose a novel framework that leverages knowledge distillation and masked training techniques.
A new method color MS-BSIF Features learning for the robust kinship verification
Dec 16, 2023the paper presents a new method color MS-BSIF learning and MS-LBP for the kinship verification is the machine's ability to identify the genetic and blood the relationship and its degree between the facial images of humans. Facial verification of kinship refers to the task of training a machine to recognize the blood relationship between a pair of faces parent and non-parent (verification) based on features extracted from facial images, and determining the exact type or degree of this genetic relationship. We use the LBP and color BSIF learning features for the comparison and the TXQDA method for dimensionality reduction and data classification. We let's test the kinship facial verification application is namely the kinface Cornell database. This system improves the robustness of learning while controlling efficiency. The experimental results obtained and compared to other methods have proven the reliability of our framework and surpass the performance of other state-of-the-art techniques.
Multi-Attention Fusion Drowsy Driving Detection Model
Dec 28, 2023Drowsy driving represents a major contributor to traffic accidents, and the implementation of driver drowsy driving detection systems has been proven to significantly reduce the occurrence of such accidents. Despite the development of numerous drowsy driving detection algorithms, many of them impose specific prerequisites such as the availability of complete facial images, optimal lighting conditions, and the use of RGB images. In our study, we introduce a novel approach called the Multi-Attention Fusion Drowsy Driving Detection Model (MAF). MAF is aimed at significantly enhancing classification performance, especially in scenarios involving partial facial occlusion and low lighting conditions. It accomplishes this by capitalizing on the local feature extraction capabilities provided by multi-attention fusion, thereby enhancing the algorithm's overall robustness. To enhance our dataset, we collected real-world data that includes both occluded and unoccluded faces captured under nighttime and daytime lighting conditions. We conducted a comprehensive series of experiments using both publicly available datasets and our self-built data. The results of these experiments demonstrate that our proposed model achieves an impressive driver drowsiness detection accuracy of 96.8%.