 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Lie-Sensor: A Live Emotion Verifier or a Licensor for Chat Applications using Emotional Intelligence
Feb 11, 2021
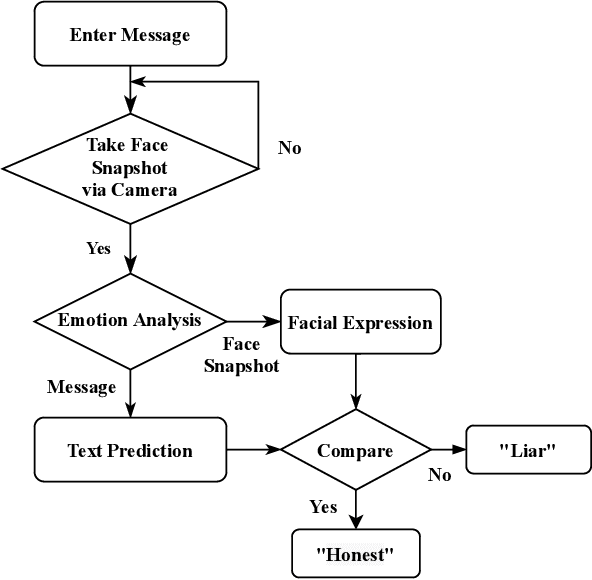
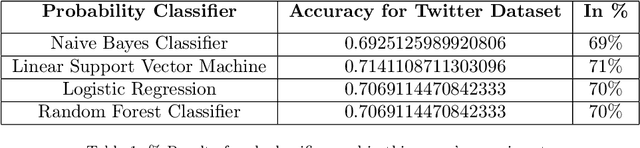
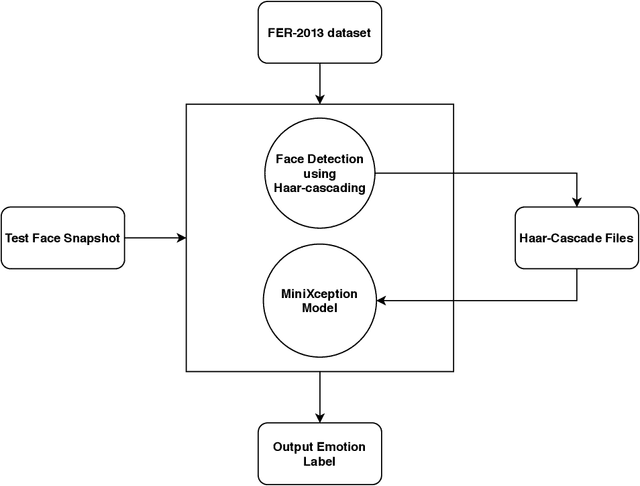

Veracity is an essential key in research and development of innovative products. Live Emotion analysis and verification nullify deceit made to complainers on live chat, corroborate messages of both ends in messaging apps and promote an honest conversation between users. The main concept behind this emotion artificial intelligent verifier is to license or decline message accountability by comparing variegated emotions of chat app users recognized through facial expressions and text prediction. In this paper, a proposed emotion intelligent live detector acts as an honest arbiter who distributes facial emotions into labels namely, Happiness, Sadness, Surprise, and Hate. Further, it separately predicts a label of messages through text classification. Finally, it compares both labels and declares the message as a fraud or a bonafide. For emotion detection, we deployed Convolutional Neural Network (CNN) using a miniXception model and for text prediction, we selected Support Vector Machine (SVM) natural language processing probability classifier due to receiving the best accuracy on training dataset after applying Support Vector Machine (SVM), Random Forest Classifier, Naive Bayes Classifier, and Logistic regression.
A Multi-task Mean Teacher for Semi-supervised Facial Affective Behavior Analysis
Jul 13, 2021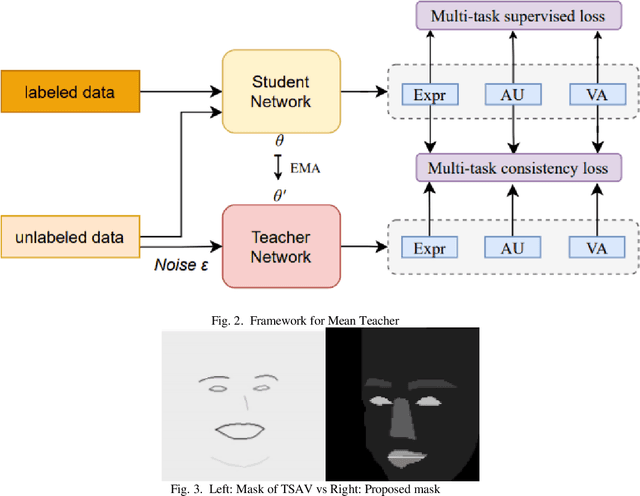
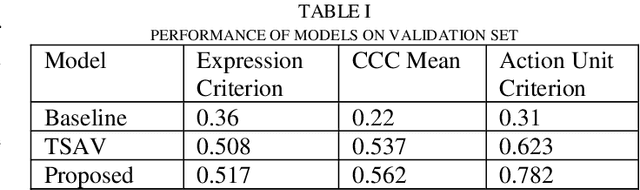
Affective Behavior Analysis is an important part in human-computer interaction. Existing successful affective behavior analysis method such as TSAV[9] suffer from challenge of incomplete labeled datasets. To boost its performance, this paper presents a multi-task mean teacher model for semi-supervised Affective Behavior Analysis to learn from missing labels and exploring the learning of multiple correlated task simultaneously. To be specific, we first utilize TSAV as baseline model to simultaneously recognize the three tasks. We have modified the preprocessing method of rendering mask to provide better semantics information. After that, we extended TSAV model to semi-supervised model using mean teacher, which allow it to be benefited from unlabeled data. Experimental results on validation datasets show that our method achieves better performance than TSAV model, which verifies that the proposed network can effectively learn additional unlabeled data to boost the affective behavior analysis performance.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 09, 2021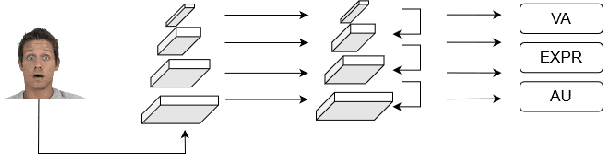
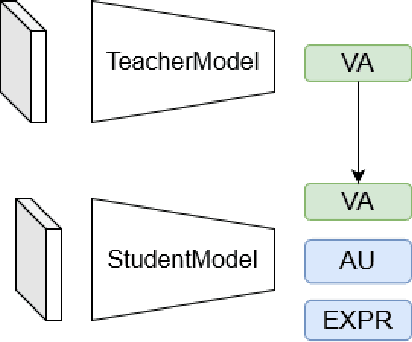
Affective Analysis is not a single task, and the valence-arousal value, expression class and action unit can be predicted at the same time. Previous researches failed to take them as a whole task or ignore the entanglement and hierarchical relation of this three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperform other models.This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.
Evolutionary Computational Method of Facial Expression Analysis for Content-based Video Retrieval using 2-Dimensional Cellular Automata
Sep 10, 2010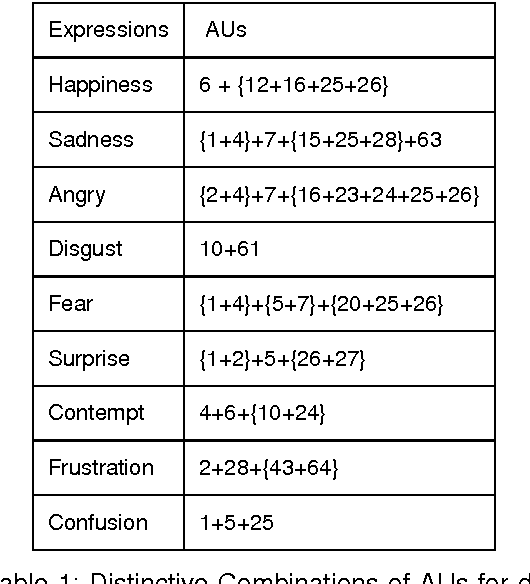
In this paper, Deterministic Cellular Automata (DCA) based video shot classification and retrieval is proposed. The deterministic 2D Cellular automata model captures the human facial expressions, both spontaneous and posed. The determinism stems from the fact that the facial muscle actions are standardized by the encodings of Facial Action Coding System (FACS) and Action Units (AUs). Based on these encodings, we generate the set of evolutionary update rules of the DCA for each facial expression. We consider a Person-Independent Facial Expression Space (PIFES) to analyze the facial expressions based on Partitioned 2D-Cellular Automata which capture the dynamics of facial expressions and classify the shots based on it. Target video shot is retrieved by comparing the similar expression is obtained for the query frame's face with respect to the key faces expressions in the database video. Consecutive key face expressions in the database that are highly similar to the query frame's face, then the key faces are used to generate the set of retrieved video shots from the database. A concrete example of its application which realizes an affective interaction between the computer and the user is proposed. In the affective interaction, the computer can recognize the facial expression of any given video shot. This interaction endows the computer with certain ability to adapt to the user's feedback.
* Submitted to Journal of Computer Science and Engineering, see http://sites.google.com/site/jcseuk/volume-2-issue-2-August-2010
Real-time Emotion and Gender Classification using Ensemble CNN
Nov 15, 2021

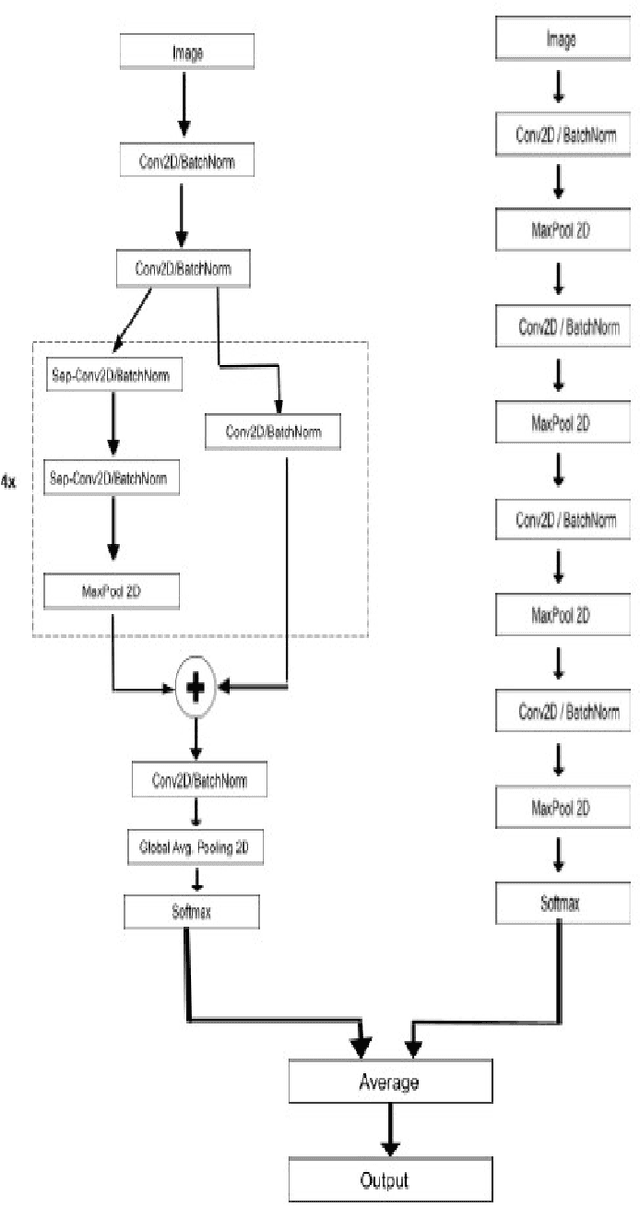
Analysing expressions on the person's face plays a very vital role in identifying emotions and behavior of a person. Recognizing these expressions automatically results in a crucial component of natural human-machine interfaces. Therefore research in this field has a wide range of applications in bio-metric authentication, surveillance systems , emotion to emoticons in various social media platforms. Another application includes conducting customer satisfaction surveys. As we know that the large corporations made huge investments to get feedback and do surveys but fail to get equitable responses. Emotion & Gender recognition through facial gestures is a technology that aims to improve product and services performance by monitoring customer behavior to specific products or service staff by their evaluation. In the past few years there have been a wide variety of advances performed in terms of feature extraction mechanisms , detection of face and also expression classification techniques. This paper is the implementation of an Ensemble CNN for building a real-time system that can detect emotion and gender of the person. The experimental results shows accuracy of 68% for Emotion classification into 7 classes (angry, fear , sad , happy , surprise , neutral , disgust) on FER-2013 dataset and 95% for Gender classification (Male or Female) on IMDB dataset. Our work can predict emotion and gender on single face images as well as multiple face images. Also when input is given through webcam our complete pipeline of this real-time system can take less than 0.5 seconds to generate results.
Age Gap Reducer-GAN for Recognizing Age-Separated Faces
Nov 11, 2020
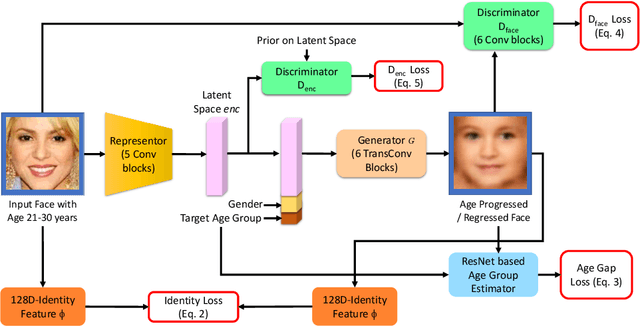

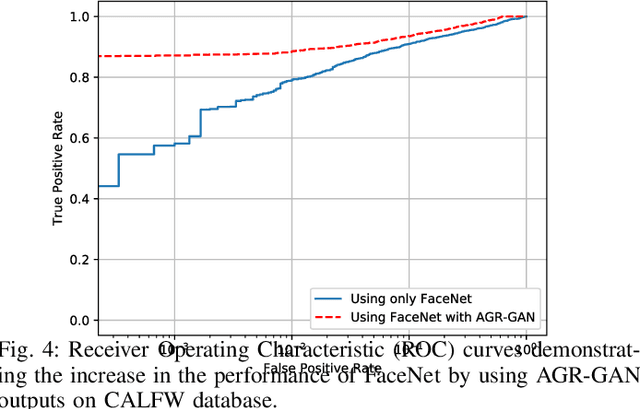
In this paper, we propose a novel algorithm for matching faces with temporal variations caused due to age progression. The proposed generative adversarial network algorithm is a unified framework that combines facial age estimation and age-separated face verification. The key idea of this approach is to learn the age variations across time by conditioning the input image on the subject's gender and the target age group to which the face needs to be progressed. The loss function accounts for reducing the age gap between the original image and generated face image as well as preserving the identity. Both visual fidelity and quantitative evaluations demonstrate the efficacy of the proposed architecture on different facial age databases for age-separated face recognition.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


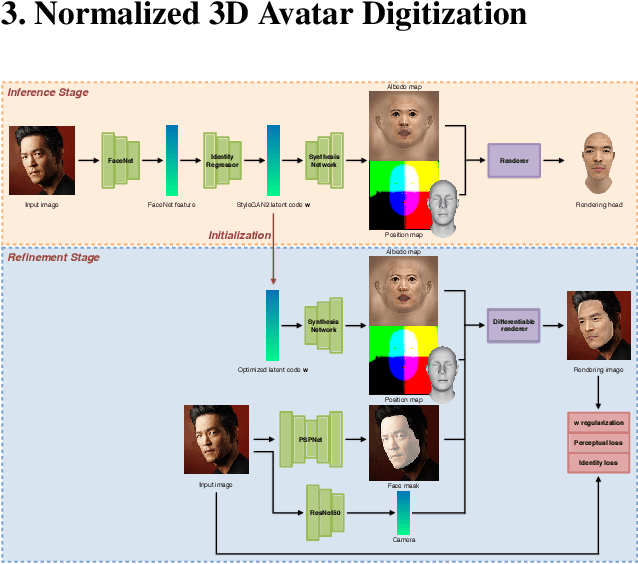
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose
Aug 24, 2021

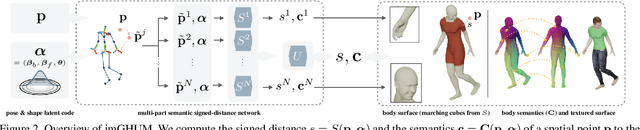
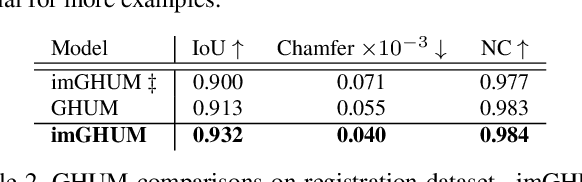
We present imGHUM, the first holistic generative model of 3D human shape and articulated pose, represented as a signed distance function. In contrast to prior work, we model the full human body implicitly as a function zero-level-set and without the use of an explicit template mesh. We propose a novel network architecture and a learning paradigm, which make it possible to learn a detailed implicit generative model of human pose, shape, and semantics, on par with state-of-the-art mesh-based models. Our model features desired detail for human models, such as articulated pose including hand motion and facial expressions, a broad spectrum of shape variations, and can be queried at arbitrary resolutions and spatial locations. Additionally, our model has attached spatial semantics making it straightforward to establish correspondences between different shape instances, thus enabling applications that are difficult to tackle using classical implicit representations. In extensive experiments, we demonstrate the model accuracy and its applicability to current research problems.
Distinguishing Posed and Spontaneous Smiles by Facial Dynamics
Feb 17, 2017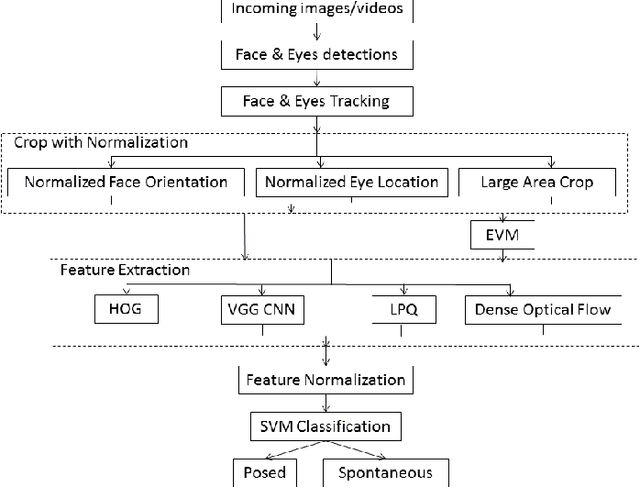
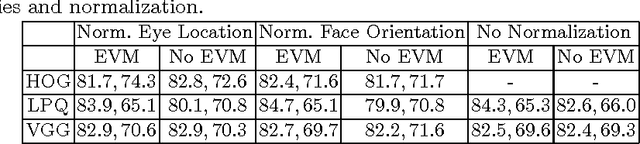
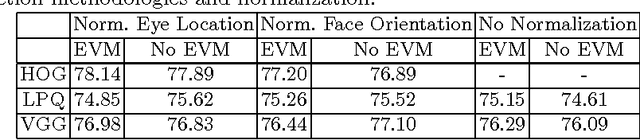
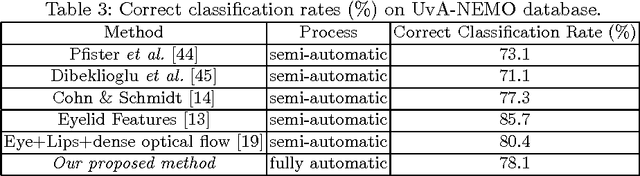
Smile is one of the key elements in identifying emotions and present state of mind of an individual. In this work, we propose a cluster of approaches to classify posed and spontaneous smiles using deep convolutional neural network (CNN) face features, local phase quantization (LPQ), dense optical flow and histogram of gradient (HOG). Eulerian Video Magnification (EVM) is used for micro-expression smile amplification along with three normalization procedures for distinguishing posed and spontaneous smiles. Although the deep CNN face model is trained with large number of face images, HOG features outperforms this model for overall face smile classification task. Using EVM to amplify micro-expressions did not have a significant impact on classification accuracy, while the normalizing facial features improved classification accuracy. Unlike many manual or semi-automatic methodologies, our approach aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large UvA-NEMO smile database show promising results as compared to other relevant methods.
MOS: A Low Latency and Lightweight Framework for Face Detection, Landmark Localization, and Head Pose Estimation
Nov 01, 2021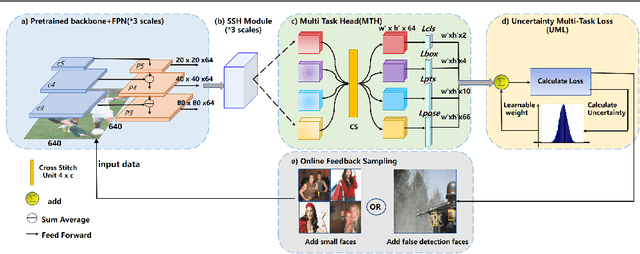
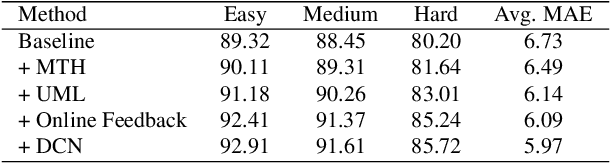
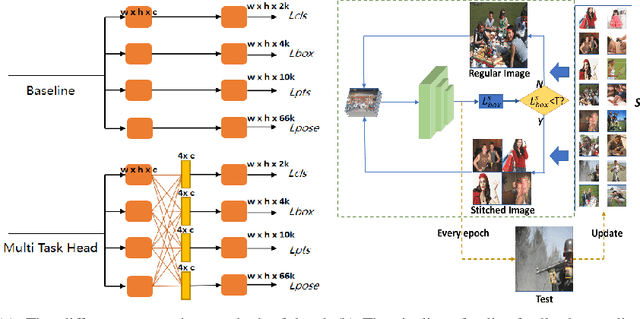
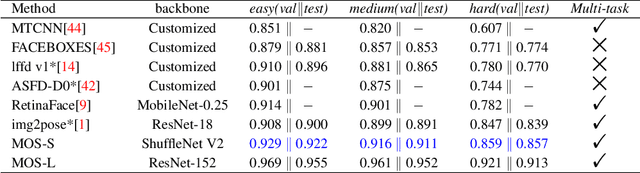
With the emergence of service robots and surveillance cameras, dynamic face recognition (DFR) in wild has received much attention in recent years. Face detection and head pose estimation are two important steps for DFR. Very often, the pose is estimated after the face detection. However, such sequential computations lead to higher latency. In this paper, we propose a low latency and lightweight network for simultaneous face detection, landmark localization and head pose estimation. Inspired by the observation that it is more challenging to locate the facial landmarks for faces with large angles, a pose loss is proposed to constrain the learning. Moreover, we also propose an uncertainty multi-task loss to learn the weights of individual tasks automatically. Another challenge is that robots often use low computational units like ARM based computing core and we often need to use lightweight networks instead of the heavy ones, which lead to performance drop especially for small and hard faces. In this paper, we propose online feedback sampling to augment the training samples across different scales, which increases the diversity of training data automatically. Through validation in commonly used WIDER FACE, AFLW and AFLW2000 datasets, the results show that the proposed method achieves the state-of-the-art performance in low computational resources. The code and data will be available at https://github.com/lyp-deeplearning/MOS-Multi-Task-Face-Detect.