 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Refacing: reconstructing anonymized facial features using GANs
Oct 15, 2018

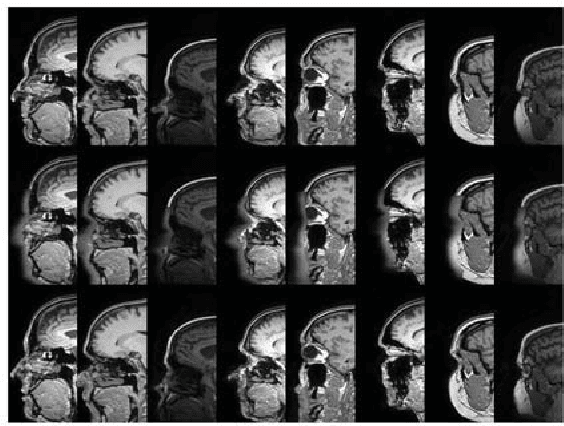
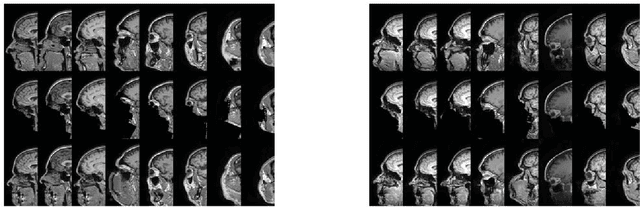
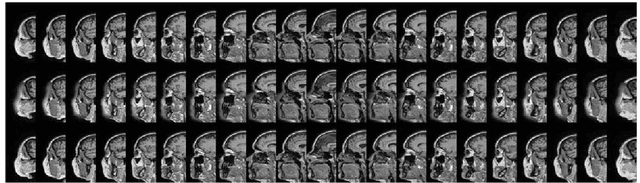
Anonymization of medical images is necessary for protecting the identity of the test subjects, and is therefore an essential step in data sharing. However, recent developments in deep learning may raise the bar on the amount of distortion that needs to be applied to guarantee anonymity. To test such possibilities, we have applied the novel CycleGAN unsupervised image-to-image translation framework on sagittal slices of T1 MR images, in order to reconstruct facial features from anonymized data. We applied the CycleGAN framework on both face-blurred and face-removed images. Our results show that face blurring may not provide adequate protection against malicious attempts at identifying the subjects, while face removal provides more robust anonymization, but is still partially reversible.
Identity Preserving Loss for Learned Image Compression
Apr 27, 2022

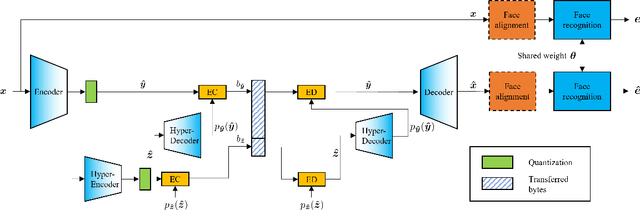

Deep learning model inference on embedded devices is challenging due to the limited availability of computation resources. A popular alternative is to perform model inference on the cloud, which requires transmitting images from the embedded device to the cloud. Image compression techniques are commonly employed in such cloud-based architectures to reduce transmission latency over low bandwidth networks. This work proposes an end-to-end image compression framework that learns domain-specific features to achieve higher compression ratios than standard HEVC/JPEG compression techniques while maintaining accuracy on downstream tasks (e.g., recognition). Our framework does not require fine-tuning of the downstream task, which allows us to drop-in any off-the-shelf downstream task model without retraining. We choose faces as an application domain due to the ready availability of datasets and off-the-shelf recognition models as representative downstream tasks. We present a novel Identity Preserving Reconstruction (IPR) loss function which achieves Bits-Per-Pixel (BPP) values that are ~38% and ~42% of CRF-23 HEVC compression for LFW (low-resolution) and CelebA-HQ (high-resolution) datasets, respectively, while maintaining parity in recognition accuracy. The superior compression ratio is achieved as the model learns to retain the domain-specific features (e.g., facial features) while sacrificing details in the background. Furthermore, images reconstructed by our proposed compression model are robust to changes in downstream model architectures. We show at-par recognition performance on the LFW dataset with an unseen recognition model while retaining a lower BPP value of ~38% of CRF-23 HEVC compression.
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Sep 15, 2017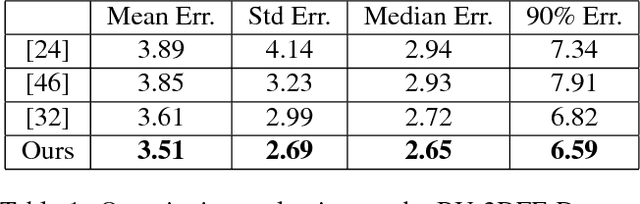

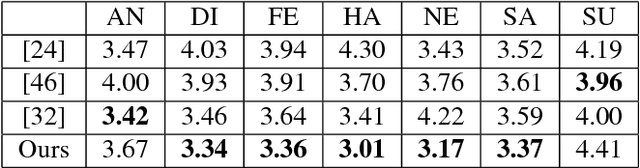
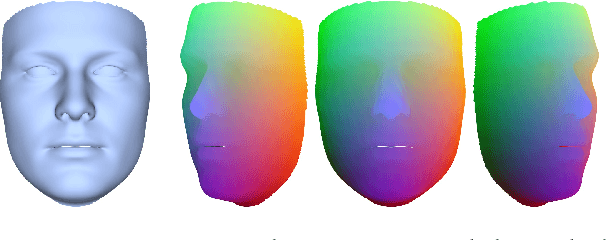
It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach.
Audio-Visual Evaluation of Oratory Skills
Sep 30, 2021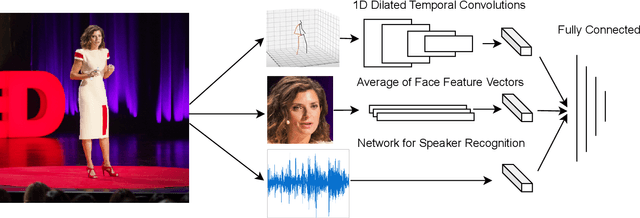
What makes a talk successful? Is it the content or the presentation? We try to estimate the contribution of the speaker's oratory skills to the talk's success, while ignoring the content of the talk. By oratory skills we refer to facial expressions, motions and gestures, as well as the vocal features. We use TED Talks as our dataset, and measure the success of each talk by its view count. Using this dataset we train a neural network to assess the oratory skills in a talk through three factors: body pose, facial expressions, and acoustic features. Most previous work on automatic evaluation of oratory skills uses hand-crafted expert annotations for both the quality of the talk and for the identification of predefined actions. Unlike prior art, we measure the quality to be equivalent to the view count of the talk as counted by TED, and allow the network to automatically learn the actions, expressions, and sounds that are relevant to the success of a talk. We find that oratory skills alone contribute substantially to the chances of a talk being successful.
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022
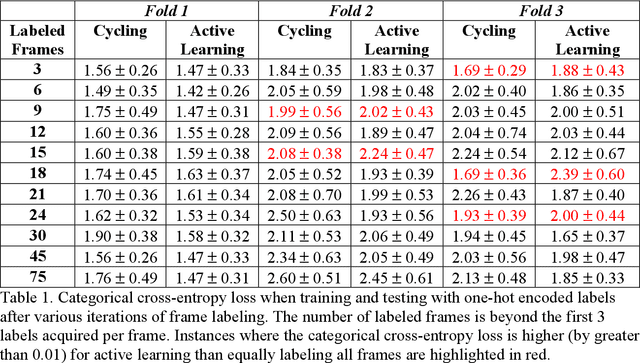
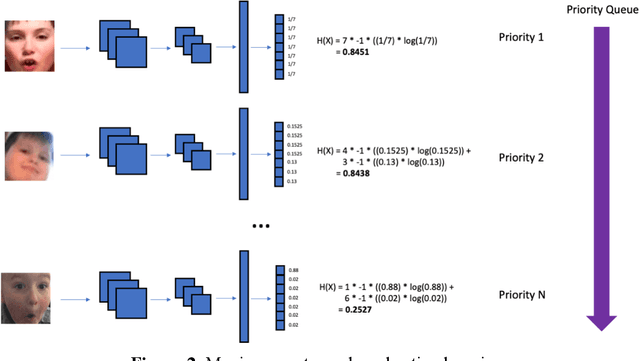
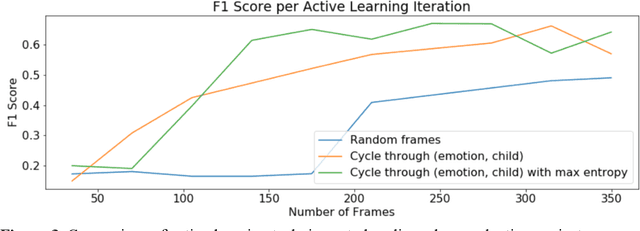
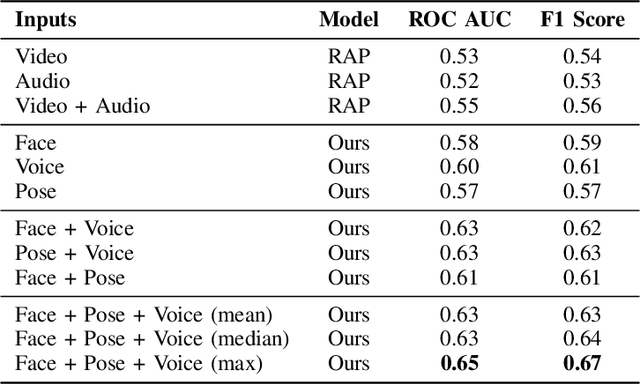
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
ResMoNet: A Residual Mobile-based Network for Facial Emotion Recognition in Resource-Limited Systems
May 15, 2020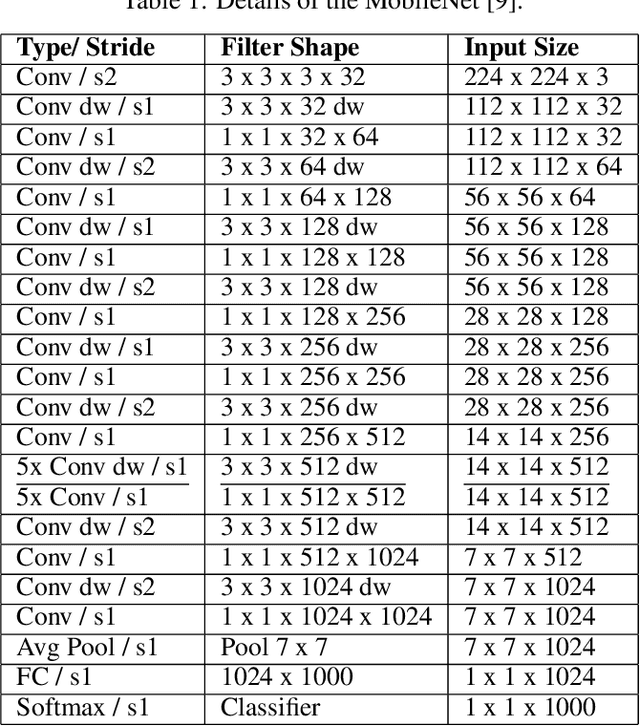
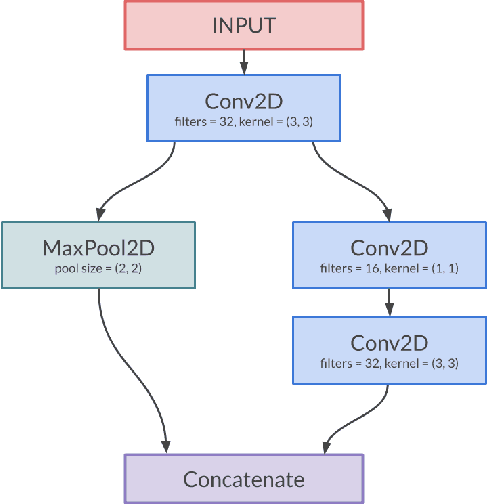
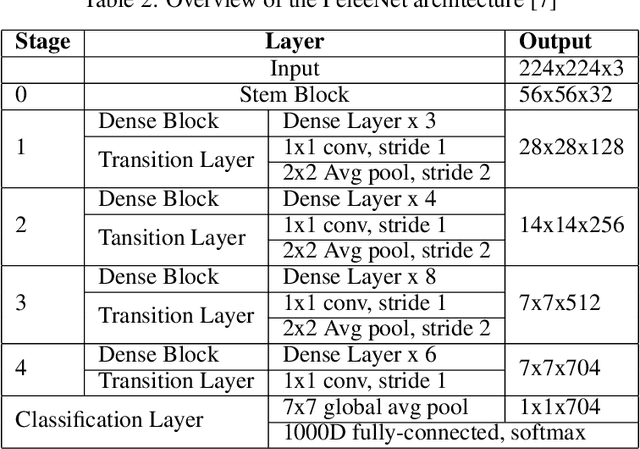
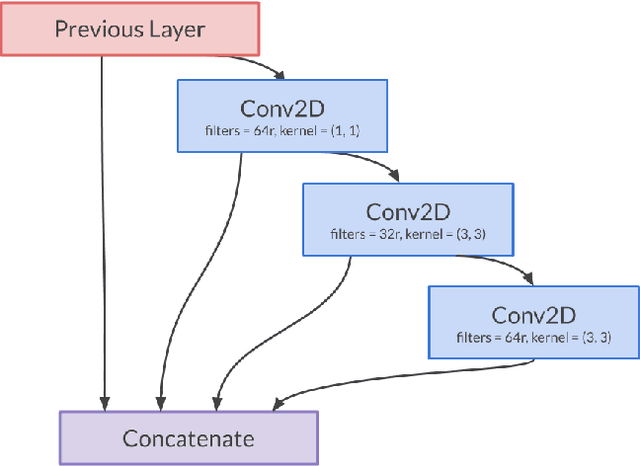
The Deep Neural Networks (DNNs) models have contributed a high accuracy for the classification of human emotional states from facial expression recognition data sets, where efficiency is an important factor for resource-limited systems as mobile devices and embedded systems. There are efficient Convolutional Neural Networks (CNN) models as MobileNet, PeleeNet, Extended Deep Neural Network (EDNN) and Inception-Based Deep Neural Network (IDNN) in terms of model architecture results: parameters, Floating-point OPerations (FLOPs) and accuracy. Although these results are satisfactory, it is necessary to evaluate other computational resources related to the trained model such as main memory utilization and response time to complete the emotion recognition. In this paper, we compare our proposed model inspired in depthwise separable convolutions and residual blocks with MobileNet, PeleeNet, EDNN and IDNN. The comparative results of the CNN architectures and the trained models --with Radboud Faces Database (RaFD)-- installed in a resource-limited device are discussed.
Facial Landmark Detection for Manga Images
Nov 08, 2018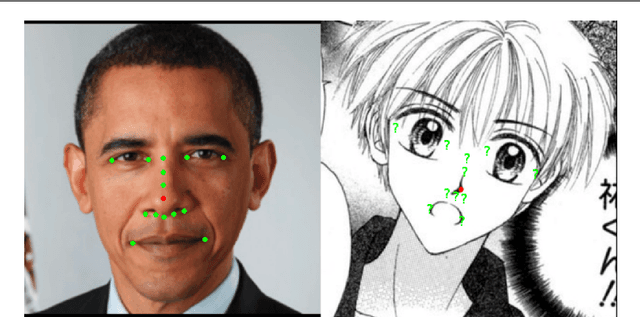



The topic of facial landmark detection has been widely covered for pictures of human faces, but it is still a challenge for drawings. Indeed, the proportions and symmetry of standard human faces are not always used for comics or mangas. The personal style of the author, the limitation of colors, etc. makes the landmark detection on faces in drawings a difficult task. Detecting the landmarks on manga images will be useful to provide new services for easily editing the character faces, estimating the character emotions, or generating automatically some animations such as lip or eye movements. This paper contains two main contributions: 1) a new landmark annotation model for manga faces, and 2) a deep learning approach to detect these landmarks. We use the "Deep Alignment Network", a multi stage architecture where the first stage makes an initial estimation which gets refined in further stages. The first results show that the proposed method succeed to accurately find the landmarks in more than 80% of the cases.
Human Head Pose Estimation by Facial Features Location
Oct 09, 2015We describe a method for estimating human head pose in a color image that contains enough of information to locate the head silhouette and detect non-trivial color edges of individual facial features. The method works by spotting the human head on an arbitrary background, extracting the head outline, and locating facial features necessary to describe the head orientation in the 3D space. It is robust enough to work with both color and gray-level images featuring quasi-frontal views of a human head under variable lighting conditions.
Optimizing Filter Size in Convolutional Neural Networks for Facial Action Unit Recognition
Nov 22, 2017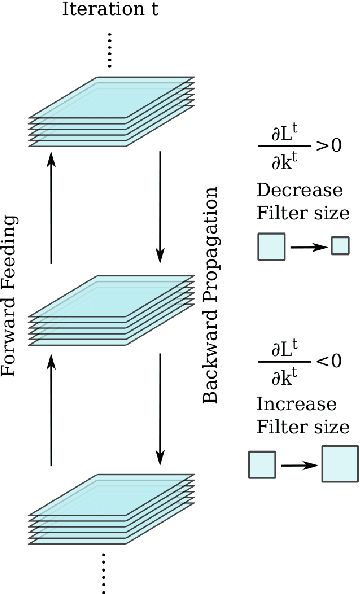
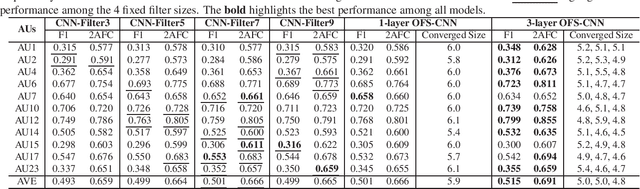
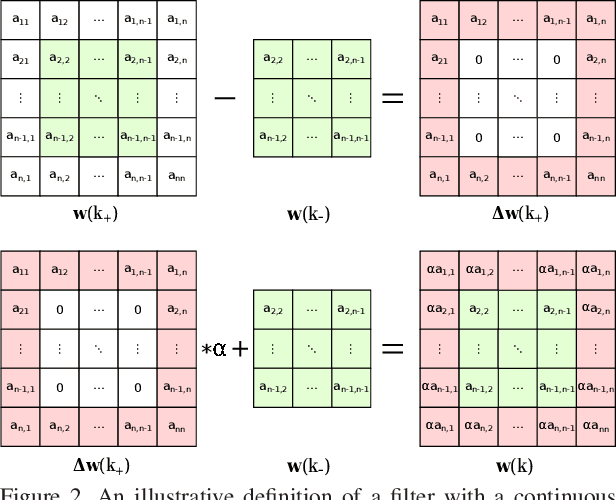
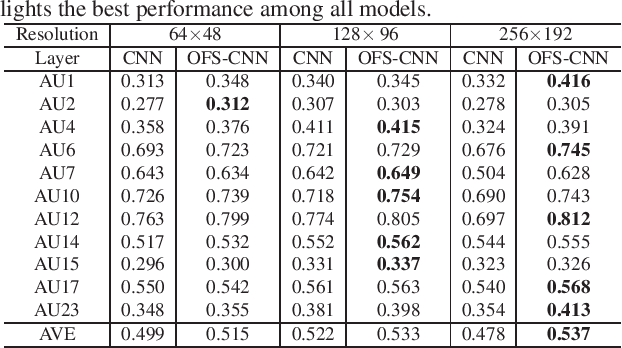
Recognizing facial action units (AUs) during spontaneous facial displays is a challenging problem. Most recently, Convolutional Neural Networks (CNNs) have shown promise for facial AU recognition, where predefined and fixed convolution filter sizes are employed. In order to achieve the best performance, the optimal filter size is often empirically found by conducting extensive experimental validation. Such a training process suffers from expensive training cost, especially as the network becomes deeper. This paper proposes a novel Optimized Filter Size CNN (OFS-CNN), where the filter sizes and weights of all convolutional layers are learned simultaneously from the training data along with learning convolution filters. Specifically, the filter size is defined as a continuous variable, which is optimized by minimizing the training loss. Experimental results on two AU-coded spontaneous databases have shown that the proposed OFS-CNN is capable of estimating optimal filter size for varying image resolution and outperforms traditional CNNs with the best filter size obtained by exhaustive search. The OFS-CNN also beats the CNN using multiple filter sizes and more importantly, is much more efficient during testing with the proposed forward-backward propagation algorithm.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
May 07, 2021
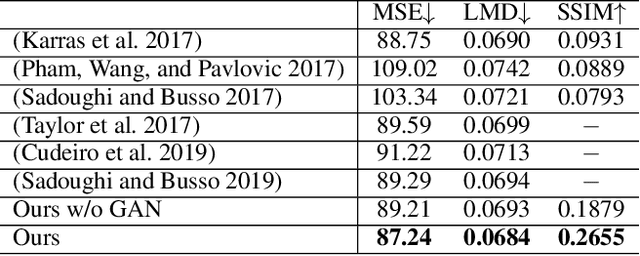
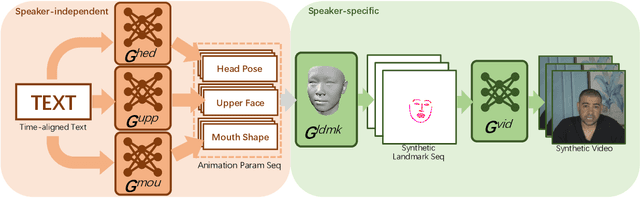
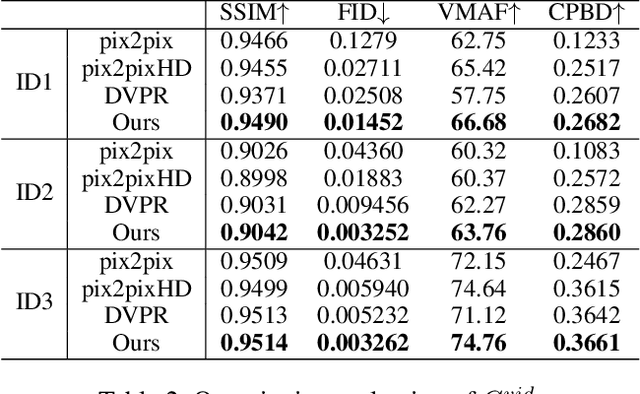
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.