 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Regulating Facial Processing Technologies: Tensions Between Legal and Technical Considerations in the Application of Illinois BIPA
May 15, 2022
Harms resulting from the development and deployment of facial processing technologies (FPT) have been met with increasing controversy. Several states and cities in the U.S. have banned the use of facial recognition by law enforcement and governments, but FPT are still being developed and used in a wide variety of contexts where they primarily are regulated by state biometric information privacy laws. Among these laws, the 2008 Illinois Biometric Information Privacy Act (BIPA) has generated a significant amount of litigation. Yet, with most BIPA lawsuits reaching settlements before there have been meaningful clarifications of relevant technical intricacies and legal definitions, there remains a great degree of uncertainty as to how exactly this law applies to FPT. What we have found through applications of BIPA in FPT litigation so far, however, points to potential disconnects between technical and legal communities. This paper analyzes what we know based on BIPA court proceedings and highlights these points of tension: areas where the technical operationalization of BIPA may create unintended and undesirable incentives for FPT development, as well as areas where BIPA litigation can bring to light the limitations of solely technical methods in achieving legal privacy values. These factors are relevant for (i) reasoning about biometric information privacy laws as a governing mechanism for FPT, (ii) assessing the potential harms of FPT, and (iii) providing incentives for the mitigation of these harms. By illuminating these considerations, we hope to empower courts and lawmakers to take a more nuanced approach to regulating FPT and developers to better understand privacy values in the current U.S. legal landscape.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022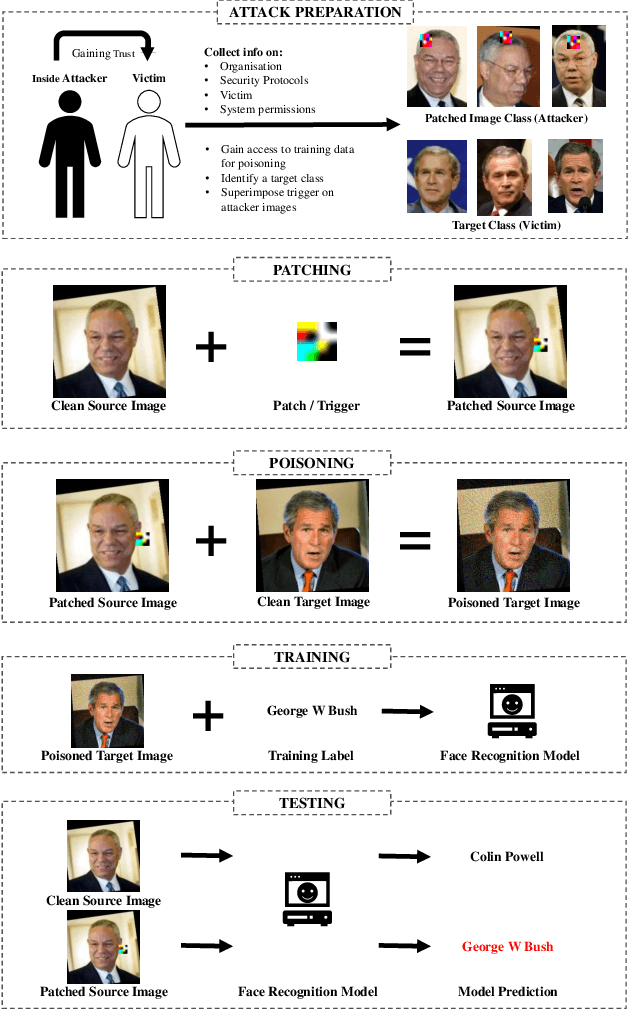
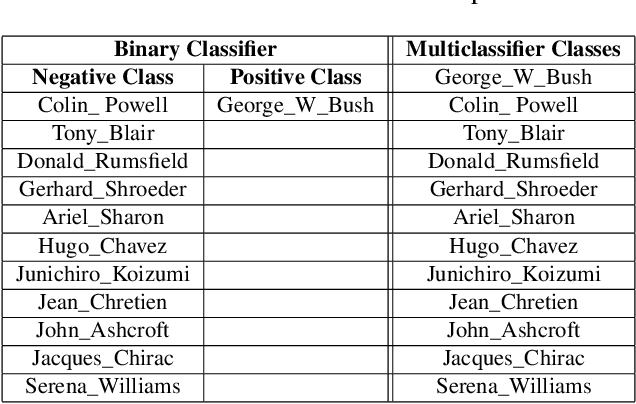
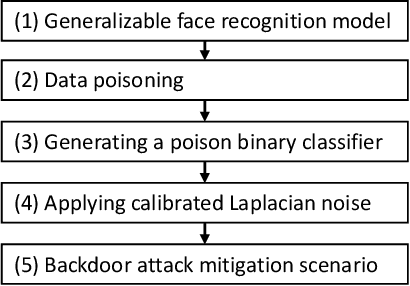
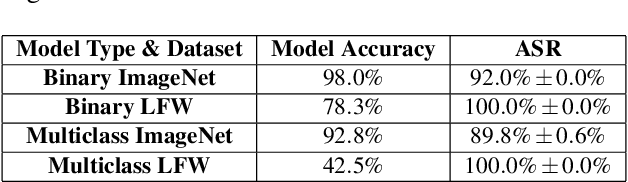
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.
Intelligent Frame Selection as a Privacy-Friendlier Alternative to Face Recognition
Jan 19, 2021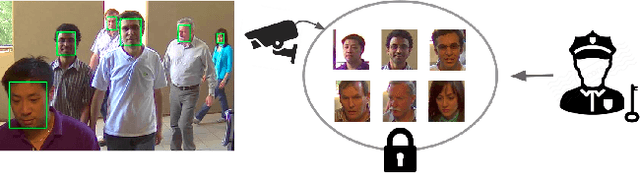

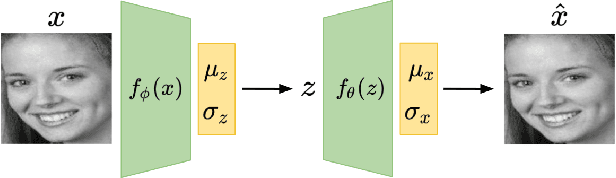

The widespread deployment of surveillance cameras for facial recognition gives rise to many privacy concerns. This study proposes a privacy-friendly alternative to large scale facial recognition. While there are multiple techniques to preserve privacy, our work is based on the minimization principle which implies minimizing the amount of collected personal data. Instead of running facial recognition software on all video data, we propose to automatically extract a high quality snapshot of each detected person without revealing his or her identity. This snapshot is then encrypted and access is only granted after legal authorization. We introduce a novel unsupervised face image quality assessment method which is used to select the high quality snapshots. For this, we train a variational autoencoder on high quality face images from a publicly available dataset and use the reconstruction probability as a metric to estimate the quality of each face crop. We experimentally confirm that the reconstruction probability can be used as biometric quality predictor. Unlike most previous studies, we do not rely on a manually defined face quality metric as everything is learned from data. Our face quality assessment method outperforms supervised, unsupervised and general image quality assessment methods on the task of improving face verification performance by rejecting low quality images. The effectiveness of the whole system is validated qualitatively on still images and videos.
Reliable Detection of Doppelgängers based on Deep Face Representations
Jan 21, 2022
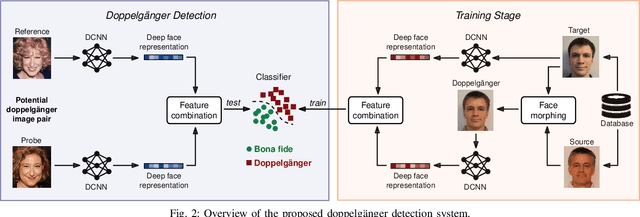


Doppelg\"angers (or lookalikes) usually yield an increased probability of false matches in a facial recognition system, as opposed to random face image pairs selected for non-mated comparison trials. In this work, we assess the impact of doppelg\"angers on the HDA Doppelg\"anger and Disguised Faces in The Wild databases using a state-of-the-art face recognition system. It is found that doppelg\"anger image pairs yield very high similarity scores resulting in a significant increase of false match rates. Further, we propose a doppelg\"anger detection method which distinguishes doppelg\"angers from mated comparison trials by analysing differences in deep representations obtained from face image pairs. The proposed detection system employs a machine learning-based classifier, which is trained with generated doppelg\"anger image pairs utilising face morphing techniques. Experimental evaluations conducted on the HDA Doppelg\"anger and Look-Alike Face databases reveal a detection equal error rate of approximately 2.7% for the task of separating mated authentication attempts from doppelg\"angers.
Metaethical Perspectives on 'Benchmarking' AI Ethics
Apr 11, 2022Benchmarks are seen as the cornerstone for measuring technical progress in Artificial Intelligence (AI) research and have been developed for a variety of tasks ranging from question answering to facial recognition. An increasingly prominent research area in AI is ethics, which currently has no set of benchmarks nor commonly accepted way for measuring the 'ethicality' of an AI system. In this paper, drawing upon research in moral philosophy and metaethics, we argue that it is impossible to develop such a benchmark. As such, alternative mechanisms are necessary for evaluating whether an AI system is 'ethical'. This is especially pressing in light of the prevalence of applied, industrial AI research. We argue that it makes more sense to talk about 'values' (and 'value alignment') rather than 'ethics' when considering the possible actions of present and future AI systems. We further highlight that, because values are unambiguously relative, focusing on values forces us to consider explicitly what the values are and whose values they are. Shifting the emphasis from ethics to values therefore gives rise to several new ways of understanding how researchers might advance research programmes for robustly safe or beneficial AI. We conclude by highlighting a number of possible ways forward for the field as a whole, and we advocate for different approaches towards more value-aligned AI research.
Towards End-to-End Neural Face Authentication in the Wild -- Quantifying and Compensating for Directional Lighting Effects
Apr 08, 2021
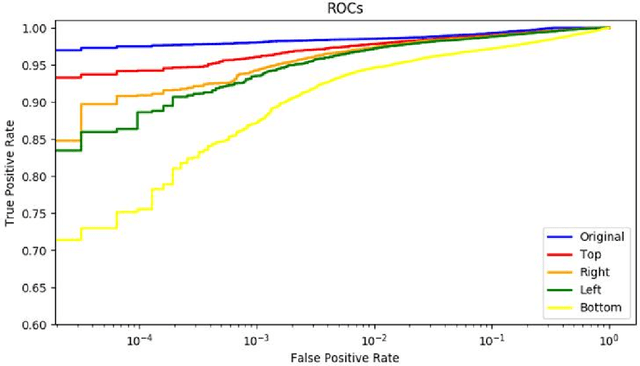

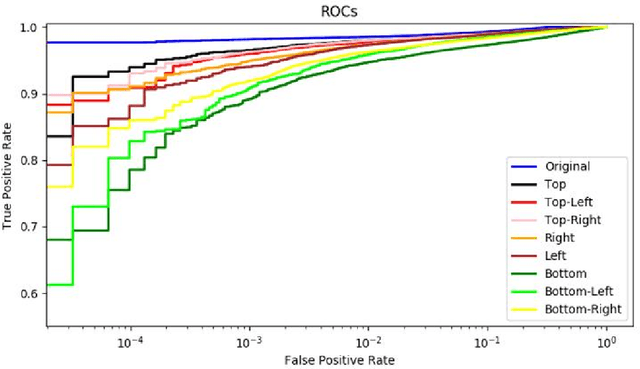
The recent availability of low-power neural accelerator hardware, combined with improvements in end-to-end neural facial recognition algorithms provides, enabling technology for on-device facial authentication. The present research work examines the effects of directional lighting on a State-of-Art(SoA) neural face recognizer. A synthetic re-lighting technique is used to augment data samples due to the lack of public data-sets with sufficient directional lighting variations. Top lighting and its variants (top-left, top-right) are found to have minimal effect on accuracy, while bottom-left or bottom-right directional lighting has the most pronounced effects. Following the fine-tuning of network weights, the face recognition model is shown to achieve close to the original Receiver Operating Characteristic curve (ROC)performance across all lighting conditions and demonstrates an ability to generalize beyond the lighting augmentations used in the fine-tuning data-set. This work shows that an SoA neural face recognition model can be tuned to compensate for directional lighting effects, removing the need for a pre-processing step before applying facial recognition.
Your "Attention" Deserves Attention: A Self-Diversified Multi-Channel Attention for Facial Action Analysis
Mar 23, 2022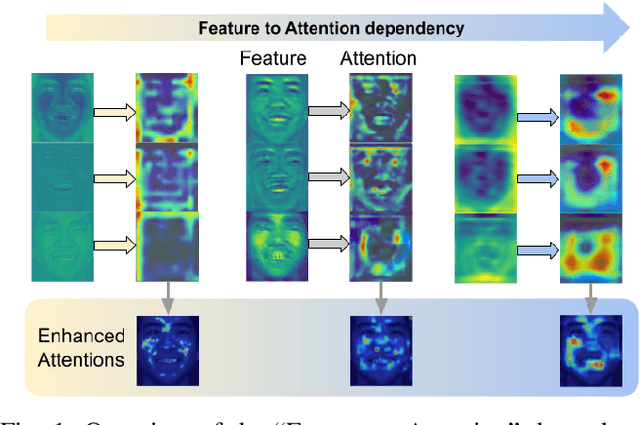
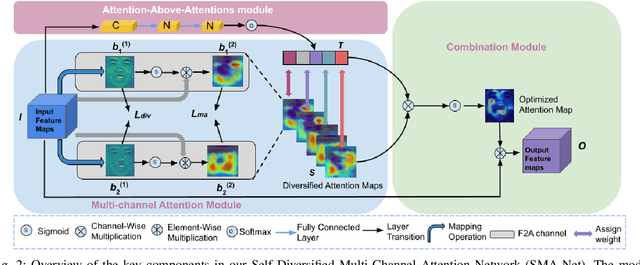
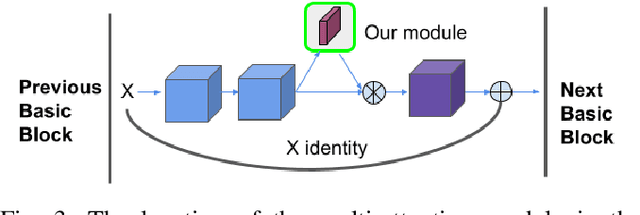
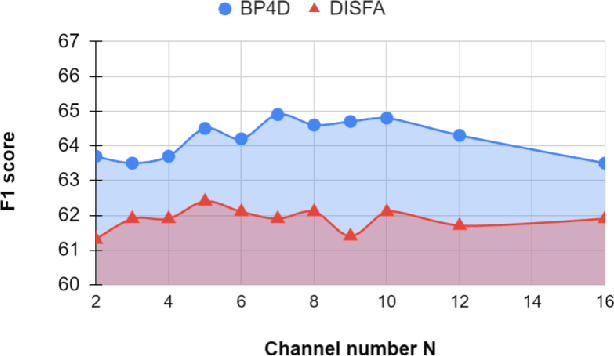
Visual attention has been extensively studied for learning fine-grained features in both facial expression recognition (FER) and Action Unit (AU) detection. A broad range of previous research has explored how to use attention modules to localize detailed facial parts (e,g. facial action units), learn discriminative features, and learn inter-class correlation. However, few related works pay attention to the robustness of the attention module itself. Through experiments, we found neural attention maps initialized with different feature maps yield diverse representations when learning to attend the identical Region of Interest (ROI). In other words, similar to general feature learning, the representational quality of attention maps also greatly affects the performance of a model, which means unconstrained attention learning has lots of randomnesses. This uncertainty lets conventional attention learning fall into sub-optimal. In this paper, we propose a compact model to enhance the representational and focusing power of neural attention maps and learn the "inter-attention" correlation for refined attention maps, which we term the "Self-Diversified Multi-Channel Attention Network (SMA-Net)". The proposed method is evaluated on two benchmark databases (BP4D and DISFA) for AU detection and four databases (CK+, MMI, BU-3DFE, and BP4D+) for facial expression recognition. It achieves superior performance compared to the state-of-the-art methods.
Masked Face Recognition for Secure Authentication
Aug 25, 2020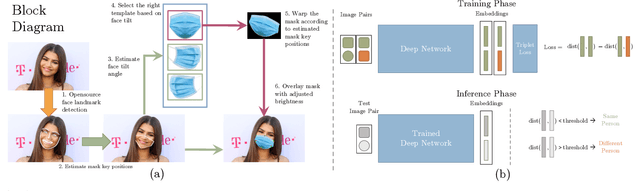
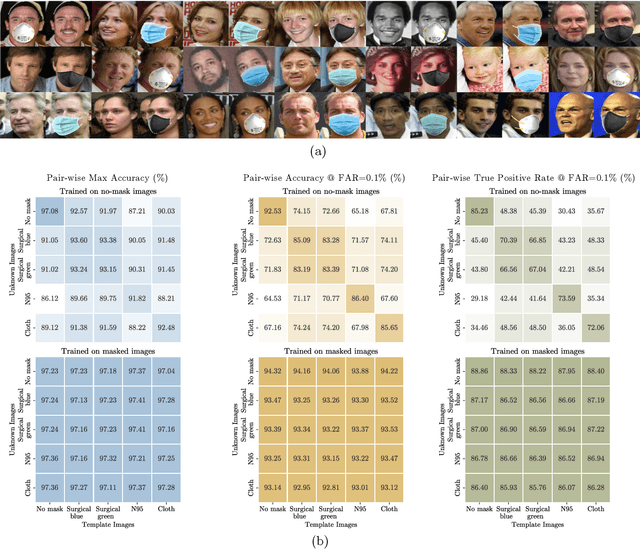
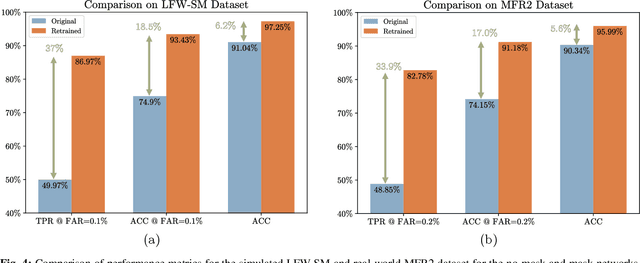
With the recent world-wide COVID-19 pandemic, using face masks have become an important part of our lives. People are encouraged to cover their faces when in public area to avoid the spread of infection. The use of these face masks has raised a serious question on the accuracy of the facial recognition system used for tracking school/office attendance and to unlock phones. Many organizations use facial recognition as a means of authentication and have already developed the necessary datasets in-house to be able to deploy such a system. Unfortunately, masked faces make it difficult to be detected and recognized, thereby threatening to make the in-house datasets invalid and making such facial recognition systems inoperable. This paper addresses a methodology to use the current facial datasets by augmenting it with tools that enable masked faces to be recognized with low false-positive rates and high overall accuracy, without requiring the user dataset to be recreated by taking new pictures for authentication. We present an open-source tool, MaskTheFace to mask faces effectively creating a large dataset of masked faces. The dataset generated with this tool is then used towards training an effective facial recognition system with target accuracy for masked faces. We report an increase of 38% in the true positive rate for the Facenet system. We also test the accuracy of re-trained system on a custom real-world dataset MFR2 and report similar accuracy.
Consensual Collaborative Training And Knowledge Distillation Based Facial Expression Recognition Under Noisy Annotations
Jul 10, 2021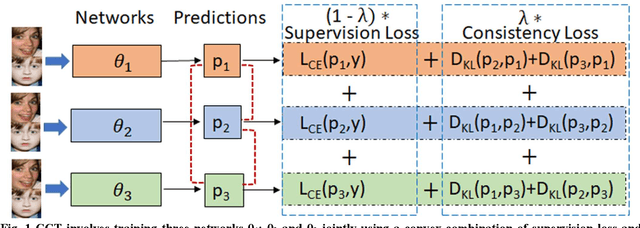
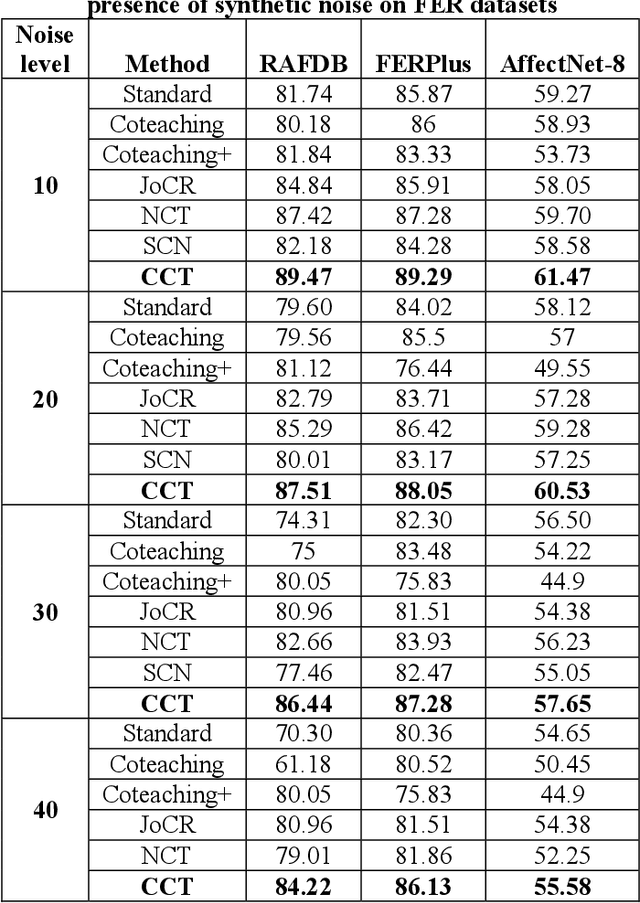
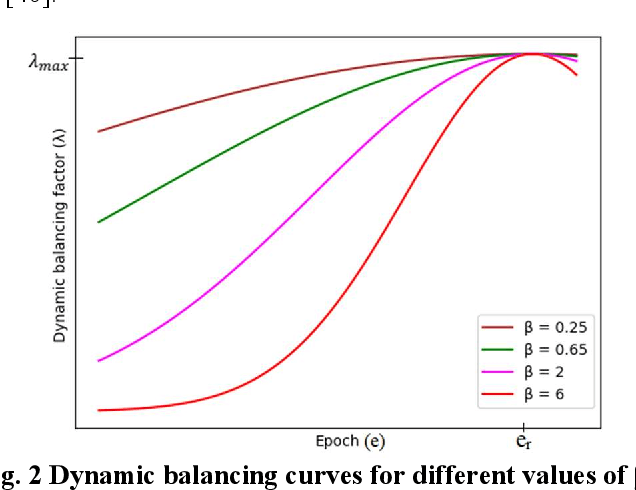
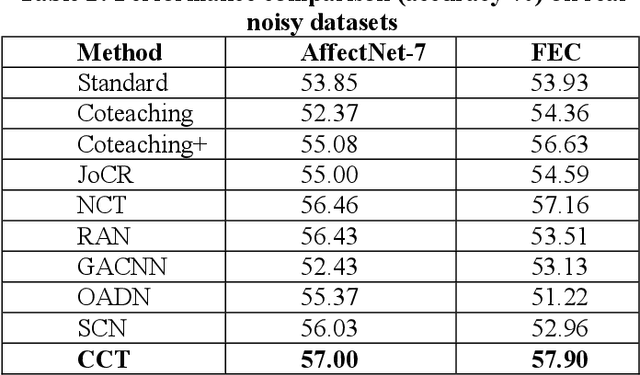
Presence of noise in the labels of large scale facial expression datasets has been a key challenge towards Facial Expression Recognition (FER) in the wild. During early learning stage, deep networks fit on clean data. Then, eventually, they start overfitting on noisy labels due to their memorization ability, which limits FER performance. This work proposes an effective training strategy in the presence of noisy labels, called as Consensual Collaborative Training (CCT) framework. CCT co-trains three networks jointly using a convex combination of supervision loss and consistency loss, without making any assumption about the noise distribution. A dynamic transition mechanism is used to move from supervision loss in early learning to consistency loss for consensus of predictions among networks in the later stage. Inference is done using a single network based on a simple knowledge distillation scheme. Effectiveness of the proposed framework is demonstrated on synthetic as well as real noisy FER datasets. In addition, a large test subset of around 5K images is annotated from the FEC dataset using crowd wisdom of 16 different annotators and reliable labels are inferred. CCT is also validated on it. State-of-the-art performance is reported on the benchmark FER datasets RAFDB (90.84%) FERPlus (89.99%) and AffectNet (66%). Our codes are available at https://github.com/1980x/CCT.
* 11 pages, 6 figures, Published with International Journal of Engineering Trends and Technology (IJETT), Codes: https://github.com/1980x/CCT
Identity-Free Facial Expression Recognition using conditional Generative Adversarial Network
Mar 19, 2019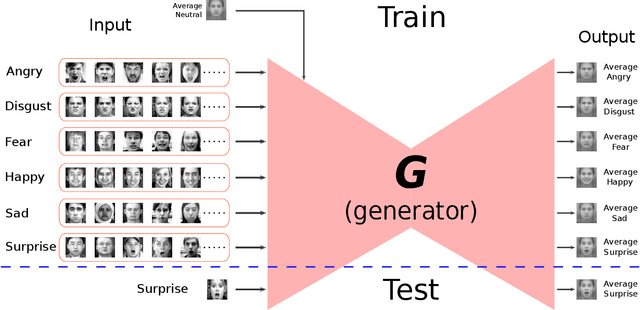
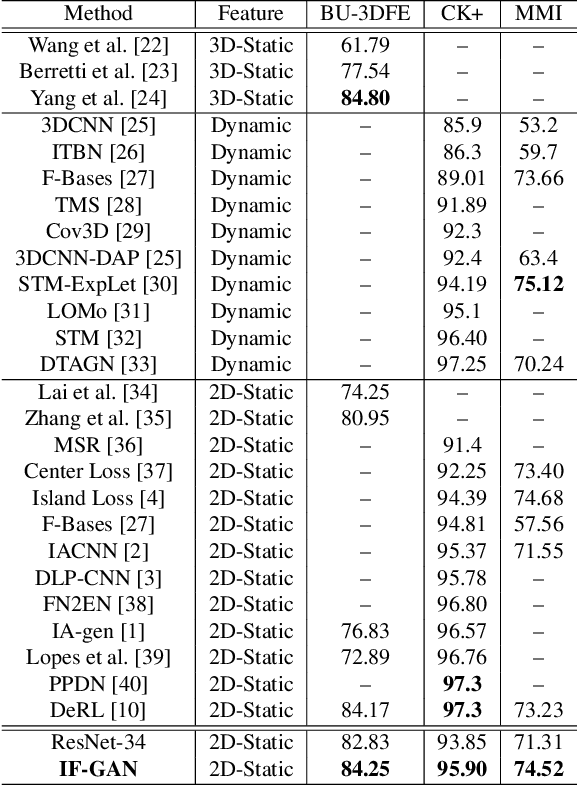
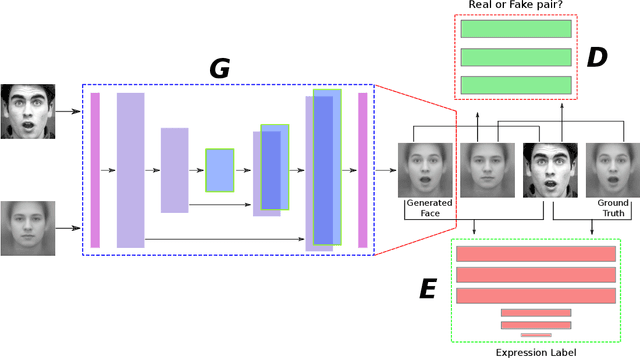

In this paper, we proposed a novel Identity-free conditional Generative Adversarial Network (IF-GAN) to explicitly reduce inter-subject variations for facial expression recognition. Specifically, for any given input face image, a conditional generative model was developed to transform an average neutral face, which is calculated from various subjects showing neutral expressions, to an average expressive face with the same expression as the input image. Since the transformed images have the same synthetic "average" identity, they differ from each other by only their expressions and thus, can be used for identity-free expression classification. In this work, an end-to-end system was developed to perform expression transformation and expression recognition in the IF-GAN framework. Experimental results on three facial expression datasets have demonstrated that the proposed IF-GAN outperforms the baseline CNN model and achieves comparable or better performance compared with the state-of-the-art methods for facial expression recognition.