 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design and Implementation of a Hybrid Wireless Power and Communication System for Medical Implants
Nov 15, 2023
Data collection and analysis from multiple implant nodes in humans can provide targeted medicine and treatment strategies that can prevent many chronic diseases. This data can be collected for a long time and processed using artificial intelligence (AI) techniques in a medical network for early detection and prevention of diseases. Additionally, machine learning (ML) algorithms can be applied for the analysis of big data for health monitoring of the population. Wireless powering, sensing, and communication are essential parts of future wireless implants that aim to achieve the aforementioned goals. In this paper, we present the technical development of a wireless implant that is powered by radio frequency (RF) at 401 MHz, with the sensor data being communicated to an on-body reader. The implant communication is based on two simultaneous wireless links: RF backscatter for implant-to-on-body communication and a galvanic link for intra-body implant-to-implant connectivity. It is demonstrated that RF powering, using the proposed compact antennas, can provide an efficient and integrable system for powering up to an 8 cm depth inside body tissues. Furthermore, the same antennas are utilized for backscatter and galvanic communication.
uHD: Unary Processing for Lightweight and Dynamic Hyperdimensional Computing
Nov 16, 2023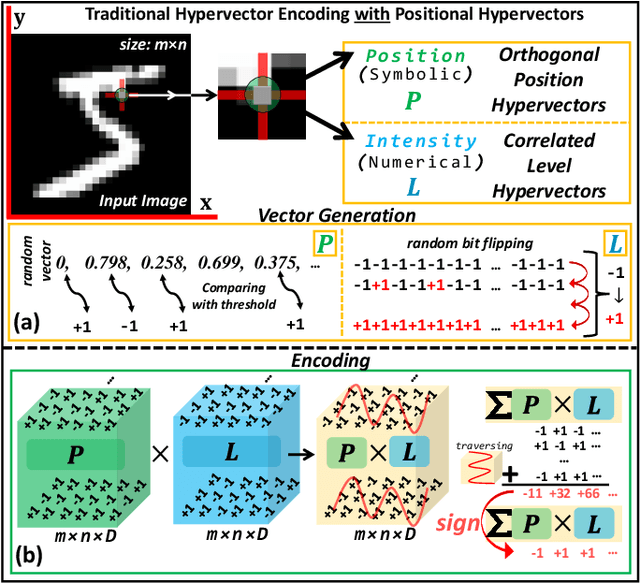
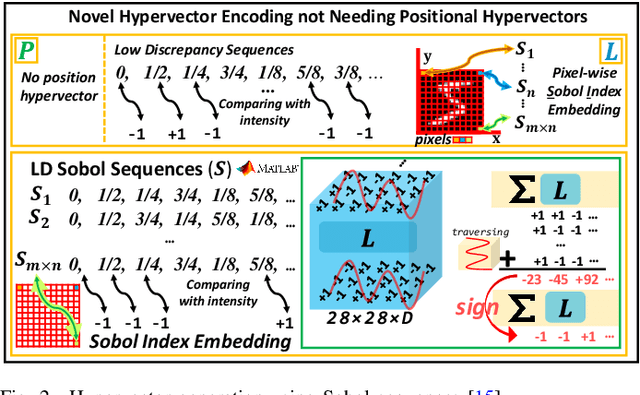
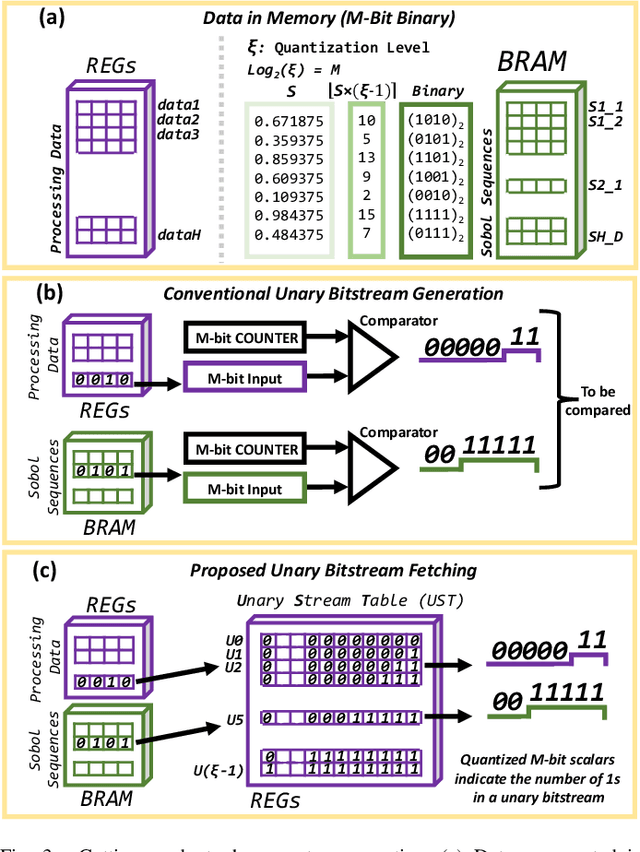
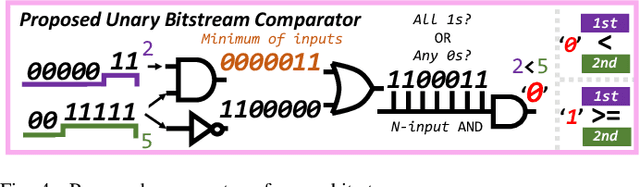
Hyperdimensional computing (HDC) is a novel computational paradigm that operates on long-dimensional vectors known as hypervectors. The hypervectors are constructed as long bit-streams and form the basic building blocks of HDC systems. In HDC, hypervectors are generated from scalar values without taking their bit significance into consideration. HDC has been shown to be efficient and robust in various data processing applications, including computer vision tasks. To construct HDC models for vision applications, the current state-of-the-art practice utilizes two parameters for data encoding: pixel intensity and pixel position. However, the intensity and position information embedded in high-dimensional vectors are generally not generated dynamically in the HDC models. Consequently, the optimal design of hypervectors with high model accuracy requires powerful computing platforms for training. A more efficient approach to generating hypervectors is to create them dynamically during the training phase, which results in accurate, low-cost, and highly performable vectors. To this aim, we use low-discrepancy sequences to generate intensity hypervectors only, while avoiding position hypervectors. By doing so, the multiplication step in vector encoding is eliminated, resulting in a power-efficient HDC system. For the first time in the literature, our proposed approach employs lightweight vector generators utilizing unary bit-streams for efficient encoding of data instead of using conventional comparator-based generators.
Robust Conformal Prediction for STL Runtime Verification under Distribution Shift
Nov 16, 2023Cyber-physical systems (CPS) designed in simulators behave differently in the real-world. Once they are deployed in the real-world, we would hence like to predict system failures during runtime. We propose robust predictive runtime verification (RPRV) algorithms under signal temporal logic (STL) tasks for general stochastic CPS. The RPRV problem faces several challenges: (1) there may not be sufficient data of the behavior of the deployed CPS, (2) predictive models are based on a distribution over system trajectories encountered during the design phase, i.e., there may be a distribution shift during deployment. To address these challenges, we assume to know an upper bound on the statistical distance (in terms of an f-divergence) between the distributions at deployment and design time, and we utilize techniques based on robust conformal prediction. Motivated by our results in [1], we construct an accurate and an interpretable RPRV algorithm. We use a trajectory prediction model to estimate the system behavior at runtime and robust conformal prediction to obtain probabilistic guarantees by accounting for distribution shifts. We precisely quantify the relationship between calibration data, desired confidence, and permissible distribution shift. To the best of our knowledge, these are the first statistically valid algorithms under distribution shift in this setting. We empirically validate our algorithms on a Franka manipulator within the NVIDIA Isaac sim environment.
The AeroSonicDB (YPAD-0523) Dataset for Acoustic Detection and Classification of Aircraft
Nov 10, 2023The time and expense required to collect and label audio data has been a prohibitive factor in the availability of domain specific audio datasets. As the predictive specificity of a classifier depends on the specificity of the labels it is trained on, it follows that finely-labelled datasets are crucial for advances in machine learning. Aiming to stimulate progress in the field of machine listening, this paper introduces AeroSonicDB (YPAD-0523), a dataset of low-flying aircraft sounds for training acoustic detection and classification systems. This paper describes the method of exploiting ADS-B radio transmissions to passively collect and label audio samples. Provides a summary of the collated dataset. Presents baseline results from three binary classification models, then discusses the limitations of the current dataset and its future potential. The dataset contains 625 aircraft recordings ranging in event duration from 18 to 60 seconds, for a total of 8.87 hours of aircraft audio. These 625 samples feature 301 unique aircraft, each of which are supplied with 14 supplementary (non-acoustic) labels to describe the aircraft. The dataset also contains 3.52 hours of ambient background audio ("silence"), as a means to distinguish aircraft noise from other local environmental noises. Additionally, 6 hours of urban soundscape recordings (with aircraft annotations) are included as an ancillary method for evaluating model performance, and to provide a testing ground for real-time applications.
Machine Learning For Beamline Steering
Nov 13, 2023Beam steering is the process involving the calibration of the angle and position at which a particle accelerator's electron beam is incident upon the x-ray target with respect to the rotation axis of the collimator. Beam Steering is an essential task for light sources. In the case under study, the LINAC To Undulator (LTU) section of the beamline is difficult to aim. Each use of the accelerator requires re-calibration of the magnets in this section. This involves a substantial amount of time and effort from human operators, while reducing scientific throughput of the light source. We investigate the use of deep neural networks to assist in this task. The deep learning models are trained on archival data and then validated on simulation data. The performance of the deep learning model is contrasted against that of trained human operators.
Surrogate Neural Networks to Estimate Parametric Sensitivity of Ocean Models
Nov 10, 2023Modeling is crucial to understanding the effect of greenhouse gases, warming, and ice sheet melting on the ocean. At the same time, ocean processes affect phenomena such as hurricanes and droughts. Parameters in the models that cannot be physically measured have a significant effect on the model output. For an idealized ocean model, we generated perturbed parameter ensemble data and trained surrogate neural network models. The neural surrogates accurately predicted the one-step forward dynamics, of which we then computed the parametric sensitivity.
Rapid Network Adaptation: Learning to Adapt Neural Networks Using Test-Time Feedback
Sep 27, 2023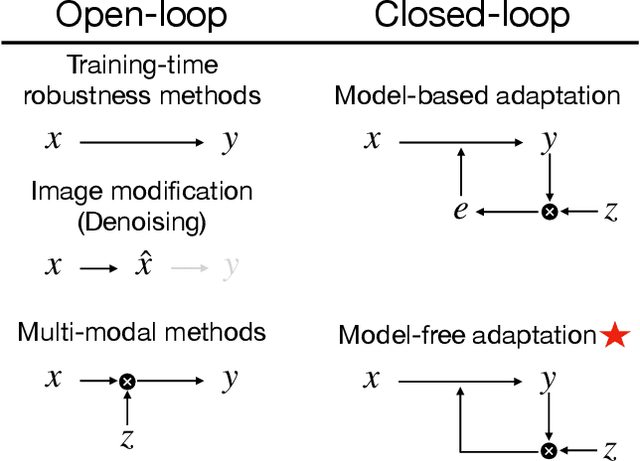
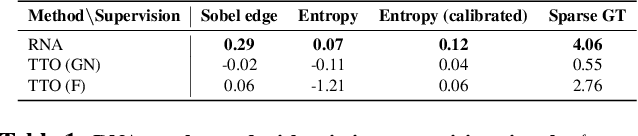

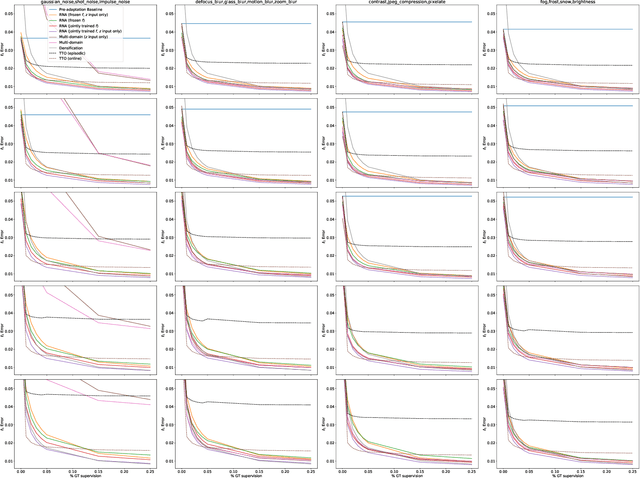
We propose a method for adapting neural networks to distribution shifts at test-time. In contrast to training-time robustness mechanisms that attempt to anticipate and counter the shift, we create a closed-loop system and make use of a test-time feedback signal to adapt a network on the fly. We show that this loop can be effectively implemented using a learning-based function, which realizes an amortized optimizer for the network. This leads to an adaptation method, named Rapid Network Adaptation (RNA), that is notably more flexible and orders of magnitude faster than the baselines. Through a broad set of experiments using various adaptation signals and target tasks, we study the efficiency and flexibility of this method. We perform the evaluations using various datasets (Taskonomy, Replica, ScanNet, Hypersim, COCO, ImageNet), tasks (depth, optical flow, semantic segmentation, classification), and distribution shifts (Cross-datasets, 2D and 3D Common Corruptions) with promising results. We end with a discussion on general formulations for handling distribution shifts and our observations from comparing with similar approaches from other domains.
Towards probabilistic Weather Forecasting with Conditioned Spatio-Temporal Normalizing Flows
Nov 12, 2023Generative normalizing flows are able to model multimodal spatial distributions, and they have been shown to model temporal correlations successfully as well. These models provide several benefits over other types of generative models due to their training stability, invertibility and efficiency in sampling and inference. This makes them a suitable candidate for stochastic spatio-temporal prediction problems, which are omnipresent in many fields of sciences, such as earth sciences, astrophysics or molecular sciences. In this paper, we present conditional normalizing flows for stochastic spatio-temporal modelling. The method is evaluated on the task of daily temperature and hourly geopotential map prediction from ERA5 datasets. Experiments show that our method is able to capture spatio-temporal correlations and extrapolates well beyond the time horizon used during training.
Simple and Effective Input Reformulations for Translation
Nov 12, 2023Foundation language models learn from their finetuning input context in different ways. In this paper, we reformulate inputs during finetuning for challenging translation tasks, leveraging model strengths from pretraining in novel ways to improve downstream performance. These reformulations are simple data level modifications, require no additional collection of training data or modification of data at inference time. They can be applied either on single language pair translation tasks or massively multilingual translation tasks. Experiments with these techniques demonstrate significant performance improvements up to $\textbf{3.5 chrF++ on the Flores200 translation benchmark}$. We hope our research accessibly improves finetuning data efficiency, enabling more effective training to scalably improve state-of-the-art performance. Our code is released $\href{https://github.com/bri25yu/LanguageModelExperimentation}{here}.$
High-fidelity Person-centric Subject-to-Image Synthesis
Nov 17, 2023Current subject-driven image generation methods encounter significant challenges in person-centric image generation. The reason is that they learn the semantic scene and person generation by fine-tuning a common pre-trained diffusion, which involves an irreconcilable training imbalance. Precisely, to generate realistic persons, they need to sufficiently tune the pre-trained model, which inevitably causes the model to forget the rich semantic scene prior and makes scene generation over-fit to the training data. Moreover, even with sufficient fine-tuning, these methods can still not generate high-fidelity persons since joint learning of the scene and person generation also lead to quality compromise. In this paper, we propose Face-diffuser, an effective collaborative generation pipeline to eliminate the above training imbalance and quality compromise. Specifically, we first develop two specialized pre-trained diffusion models, i.e., Text-driven Diffusion Model (TDM) and Subject-augmented Diffusion Model (SDM), for scene and person generation, respectively. The sampling process is divided into three sequential stages, i.e., semantic scene construction, subject-scene fusion, and subject enhancement. The first and last stages are performed by TDM and SDM respectively. The subject-scene fusion stage, that is the collaboration achieved through a novel and highly effective mechanism, Saliency-adaptive Noise Fusion (SNF). Specifically, it is based on our key observation that there exists a robust link between classifier-free guidance responses and the saliency of generated images. In each time step, SNF leverages the unique strengths of each model and allows for the spatial blending of predicted noises from both models automatically in a saliency-aware manner. Extensive experiments confirm the impressive effectiveness and robustness of the Face-diffuser.