 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive County Level COVID-19 Forecast Models: Analysis and Improvement
Jul 01, 2020
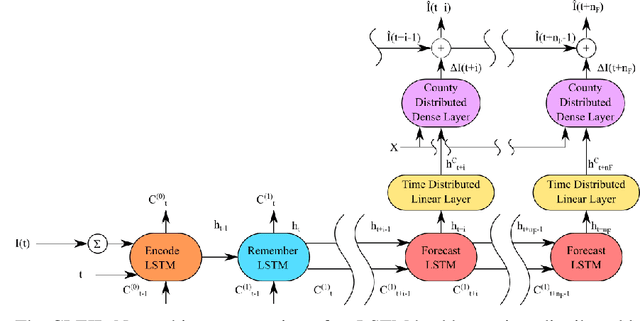
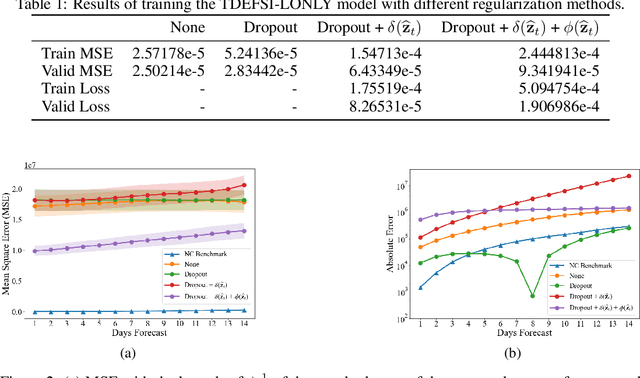
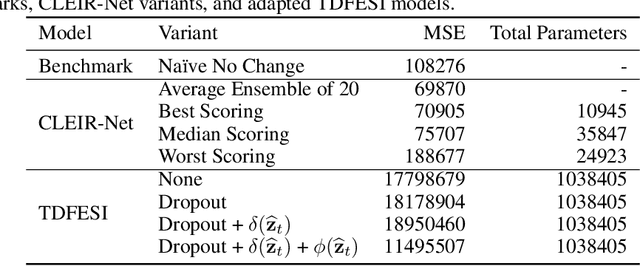
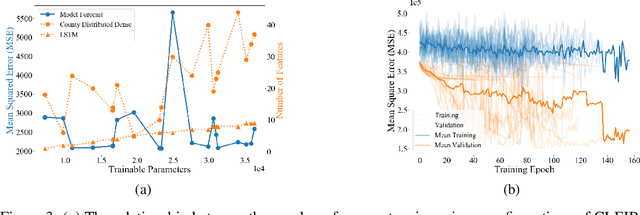
Accurately forecasting county level COVID-19 confirmed cases is crucial to optimizing medical resources. Forecasting emerging outbreaks pose a particular challenge because many existing forecasting techniques learn from historical seasons trends. Recurrent neural networks (RNNs) with LSTM-based cells are a logical choice of model due to their ability to learn temporal dynamics. In this paper, we adapt the state and county level influenza model, TDEFSI-LONLY, proposed in Wang et a. [l2020] to national and county level COVID-19 data. We show that this model poorly forecasts the current pandemic. We analyze the two week ahead forecasting capabilities of the TDEFSI-LONLY model with combinations of regularization techniques. Effective training of the TDEFSI-LONLY model requires data augmentation, to overcome this challenge we utilize an SEIR model and present an inter-county mixing extension to this model to simulate sufficient training data. Further, we propose an alternate forecast model, {\it County Level Epidemiological Inference Recurrent Network} (\alg{}) that trains an LSTM backbone on national confirmed cases to learn a low dimensional time pattern and utilizes a time distributed dense layer to learn individual county confirmed case changes each day for a two weeks forecast. We show that the best, worst, and median state forecasts made using CLEIR-Net model are respectively New York, South Carolina, and Montana.
Deep learning for video game genre classification
Nov 21, 2020

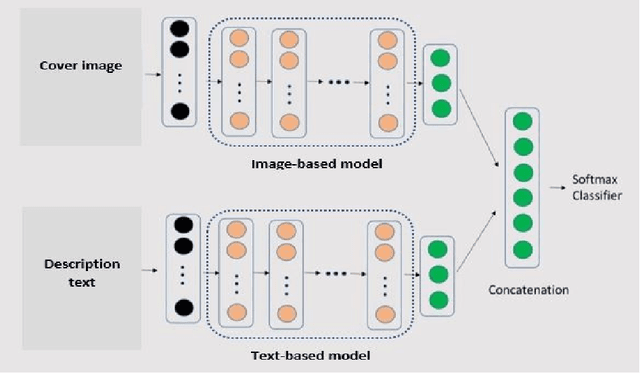
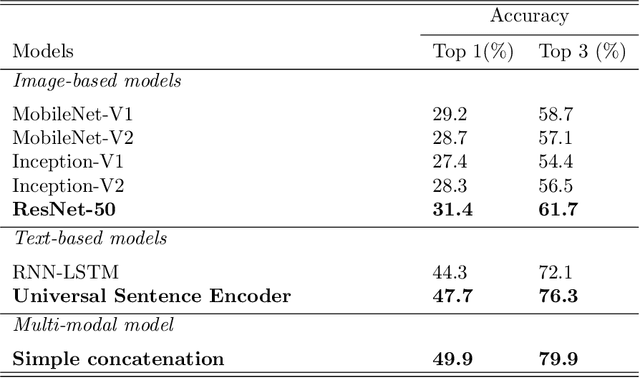
Video game genre classification based on its cover and textual description would be utterly beneficial to many modern identification, collocation, and retrieval systems. At the same time, it is also an extremely challenging task due to the following reasons: First, there exists a wide variety of video game genres, many of which are not concretely defined. Second, video game covers vary in many different ways such as colors, styles, textual information, etc, even for games of the same genre. Third, cover designs and textual descriptions may vary due to many external factors such as country, culture, target reader populations, etc. With the growing competitiveness in the video game industry, the cover designers and typographers push the cover designs to its limit in the hope of attracting sales. The computer-based automatic video game genre classification systems become a particularly exciting research topic in recent years. In this paper, we propose a multi-modal deep learning framework to solve this problem. The contribution of this paper is four-fold. First, we compiles a large dataset consisting of 50,000 video games from 21 genres made of cover images, description text, and title text and the genre information. Second, image-based and text-based, state-of-the-art models are evaluated thoroughly for the task of genre classification for video games. Third, we developed an efficient and salable multi-modal framework based on both images and texts. Fourth, a thorough analysis of the experimental results is given and future works to improve the performance is suggested. The results show that the multi-modal framework outperforms the current state-of-the-art image-based or text-based models. Several challenges are outlined for this task. More efforts and resources are needed for this classification task in order to reach a satisfactory level.
Changing Clusters of Indian States with respect to number of Cases of COVID-19 using incrementalKMN Method
Jul 12, 2020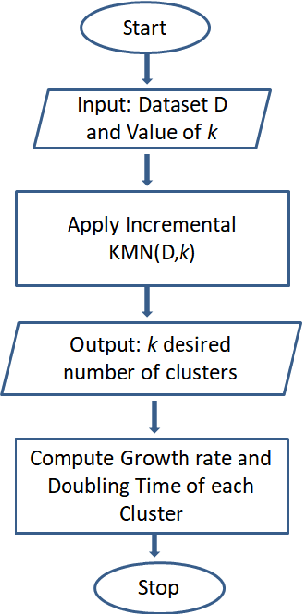
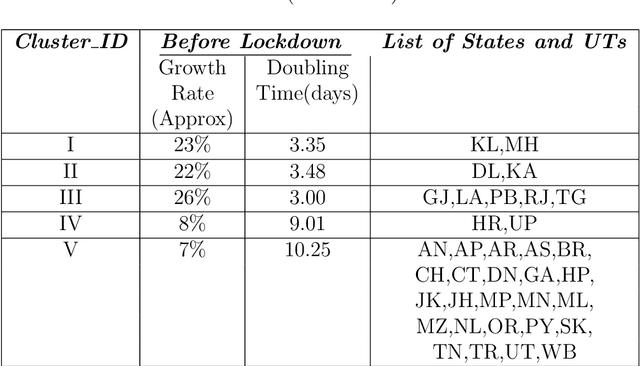
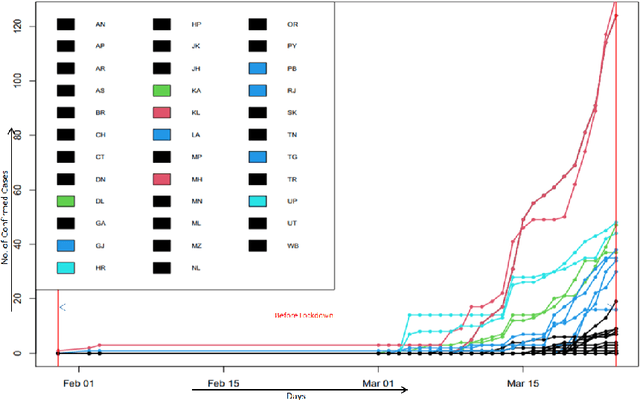
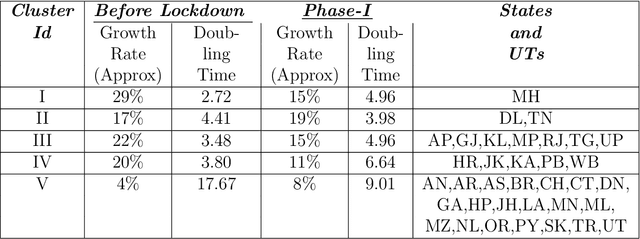
The novel Coronavirus (COVID-19) incidence in India is currently experiencing exponential rise but with apparent spatial variation in growth rate and doubling time rate. We classify the states into five clusters with low to the high-risk category and study how the different states moved from one cluster to the other since the onset of the first case on $30^{th}$ January 2020 till the end of unlock 1 that is $30^{th}$ June 2020. We have implemented a new clustering technique called the incrementalKMN (Prasad, R. K., Sarmah, R., Chakraborty, S.(2019))
Machine-learning physics from unphysics: Finding deconfinement temperature in lattice Yang-Mills theories from outside the scaling window
Sep 23, 2020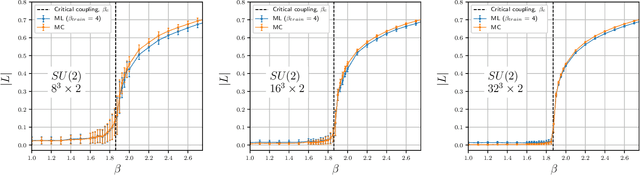
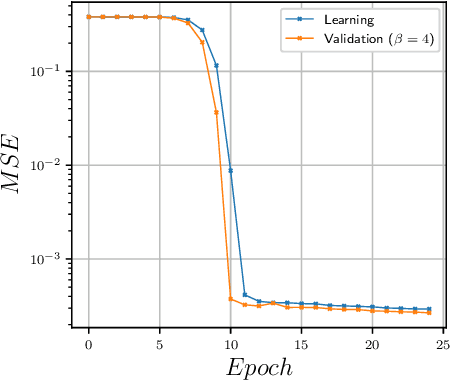
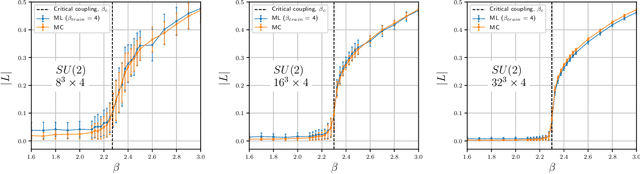
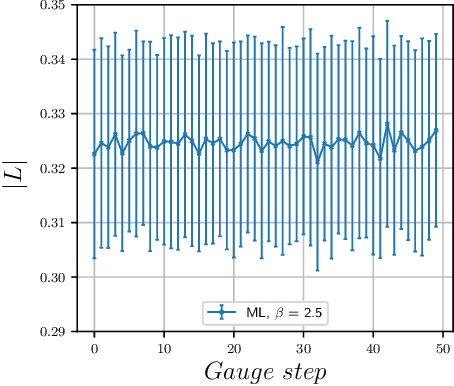
We study the machine learning techniques applied to the lattice gauge theory's critical behavior, particularly to the confinement/deconfinement phase transition in the SU(2) and SU(3) gauge theories. We find that the neural network of the machine-learning algorithm, trained on 'bare' lattice configurations at an unphysical value of the lattice parameters as an input, builds up a gauge-invariant function, and finds correlations with the target observable that is valid in the physical region of the parameter space. In particular, if the algorithm aimed to predict the Polyakov loop as the deconfining order parameter, it builds a trace of the gauge group matrices along a closed loop in the time direction. As a result, the neural network, trained at one unphysical value of the lattice coupling $\beta$ predicts the order parameter in the whole region of the $\beta$ values with good precision. We thus demonstrate that the machine learning techniques may be used as a numerical analog of the analytical continuation from easily accessible but physically uninteresting regions of the coupling space to the interesting but potentially not accessible regions.
Chasing Your Long Tails: Differentially Private Prediction in Health Care Settings
Oct 13, 2020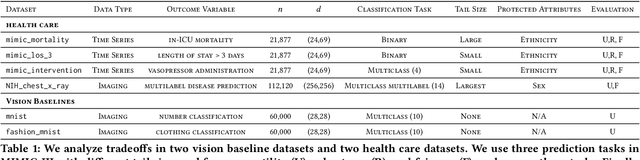
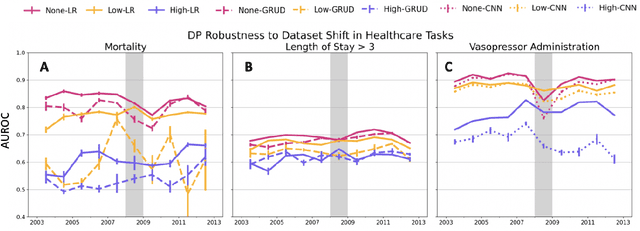
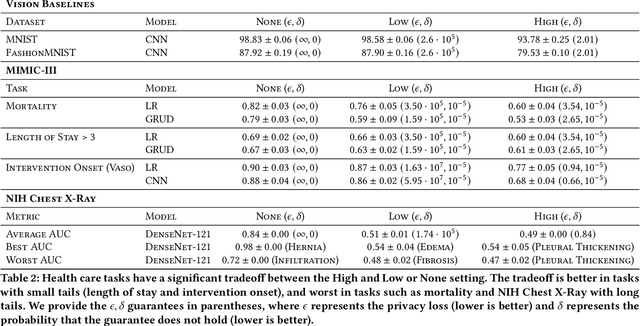
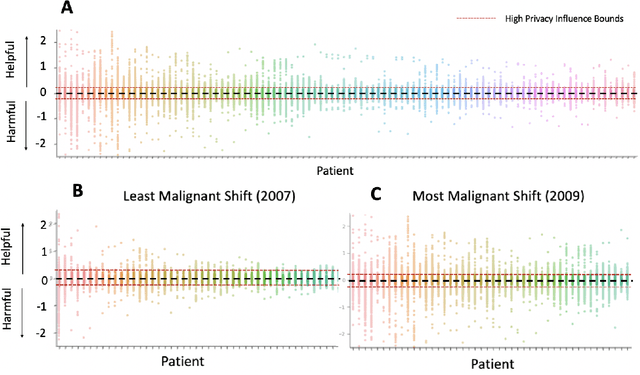
Machine learning models in health care are often deployed in settings where it is important to protect patient privacy. In such settings, methods for differentially private (DP) learning provide a general-purpose approach to learn models with privacy guarantees. Modern methods for DP learning ensure privacy through mechanisms that censor information judged as too unique. The resulting privacy-preserving models, therefore, neglect information from the tails of a data distribution, resulting in a loss of accuracy that can disproportionately affect small groups. In this paper, we study the effects of DP learning in health care. We use state-of-the-art methods for DP learning to train privacy-preserving models in clinical prediction tasks, including x-ray classification of images and mortality prediction in time series data. We use these models to perform a comprehensive empirical investigation of the tradeoffs between privacy, utility, robustness to dataset shift, and fairness. Our results highlight lesser-known limitations of methods for DP learning in health care, models that exhibit steep tradeoffs between privacy and utility, and models whose predictions are disproportionately influenced by large demographic groups in the training data. We discuss the costs and benefits of differentially private learning in health care.
Orthogonalized SGD and Nested Architectures for Anytime Neural Networks
Aug 15, 2020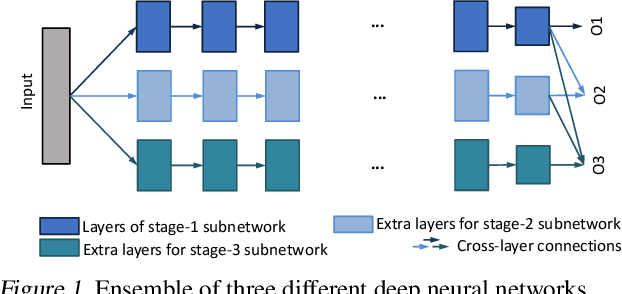
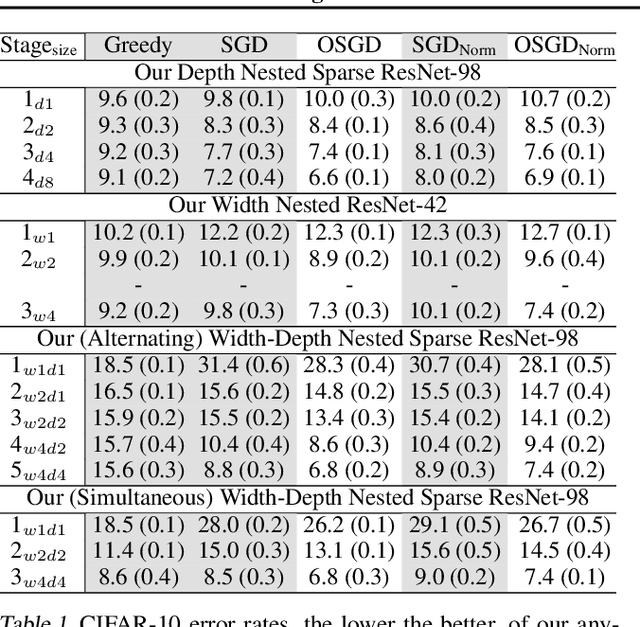
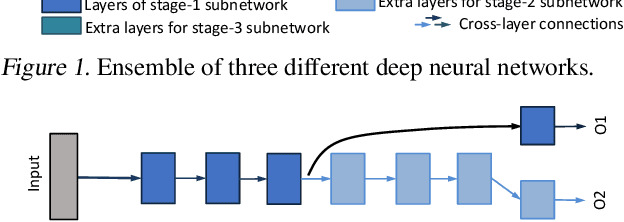
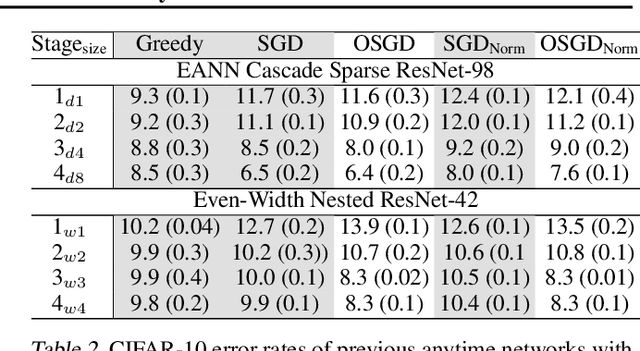
We propose a novel variant of SGD customized for training network architectures that support anytime behavior: such networks produce a series of increasingly accurate outputs over time. Efficient architectural designs for these networks focus on re-using internal state; subnetworks must produce representations relevant for both immediate prediction as well as refinement by subsequent network stages. We consider traditional branched networks as well as a new class of recursively nested networks. Our new optimizer, Orthogonalized SGD, dynamically re-balances task-specific gradients when training a multitask network. In the context of anytime architectures, this optimizer projects gradients from later outputs onto a parameter subspace that does not interfere with those from earlier outputs. Experiments demonstrate that training with Orthogonalized SGD significantly improves generalization accuracy of anytime networks.
Pruning Convolutional Filters using Batch Bridgeout
Sep 23, 2020

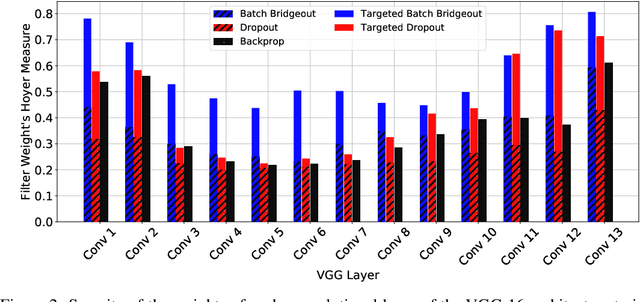
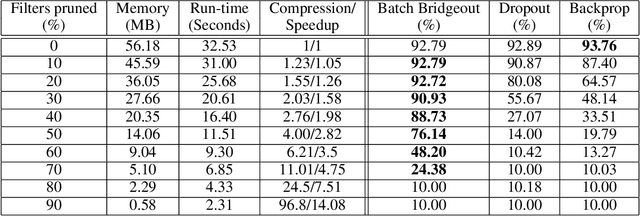
State-of-the-art computer vision models are rapidly increasing in capacity, where the number of parameters far exceeds the number required to fit the training set. This results in better optimization and generalization performance. However, the huge size of contemporary models results in large inference costs and limits their use on resource-limited devices. In order to reduce inference costs, convolutional filters in trained neural networks could be pruned to reduce the run-time memory and computational requirements during inference. However, severe post-training pruning results in degraded performance if the training algorithm results in dense weight vectors. We propose the use of Batch Bridgeout, a sparsity inducing stochastic regularization scheme, to train neural networks so that they could be pruned efficiently with minimal degradation in performance. We evaluate the proposed method on common computer vision models VGGNet, ResNet, and Wide-ResNet on the CIFAR image classification task. For all the networks, experimental results show that Batch Bridgeout trained networks achieve higher accuracy across a wide range of pruning intensities compared to Dropout and weight decay regularization.
Automatic Extraction of Urban Outdoor Perception from Geolocated Free-Texts
Oct 13, 2020
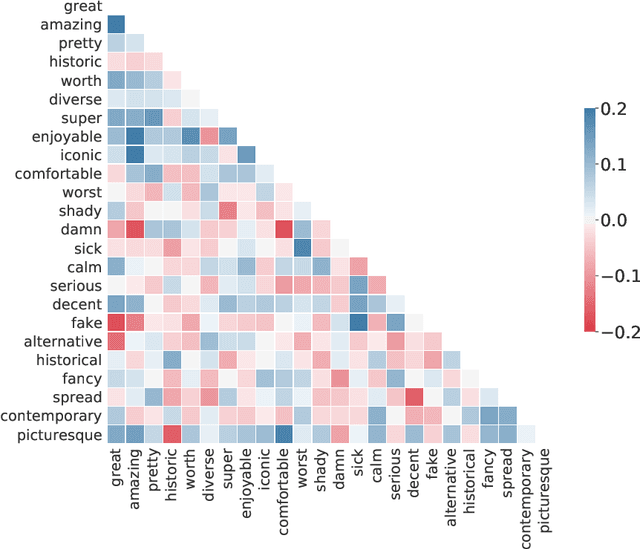
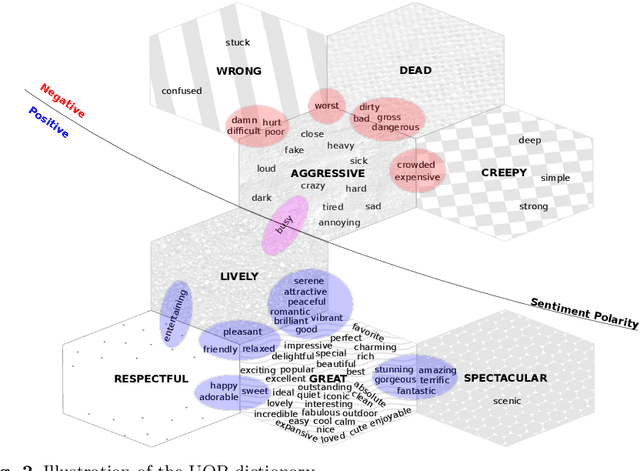

The automatic extraction of urban perception shared by people on location-based social networks (LBSNs) is an important multidisciplinary research goal. One of the reasons is because it facilitates the understanding of the intrinsic characteristics of urban areas in a scalable way, helping to leverage new services. However, content shared on LBSNs is diverse, encompassing several topics, such as politics, sports, culture, religion, and urban perceptions, making the task of content extraction regarding a particular topic very challenging. Considering free-text messages shared on LBSNs, we propose an automatic and generic approach to extract people's perceptions. For that, our approach explores opinions that are spatial-temporal and semantically similar. We exemplify our approach in the context of urban outdoor areas in Chicago, New York City and London. Studying those areas, we found evidence that LBSN data brings valuable information about urban regions. To analyze and validate our outcomes, we conducted a temporal analysis to measure the results' robustness over time. We show that our approach can be helpful to better understand urban areas considering different perspectives. We also conducted a comparative analysis based on a public dataset, which contains volunteers' perceptions regarding urban areas expressed in a controlled experiment. We observe that both results yield a very similar level of agreement.
Fairness constraints can help exact inference in structured prediction
Jul 01, 2020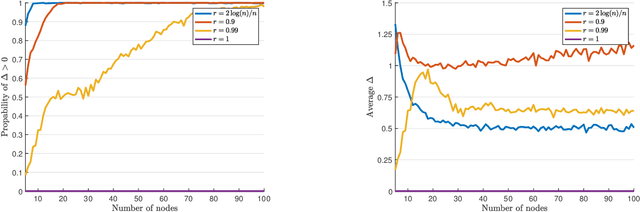
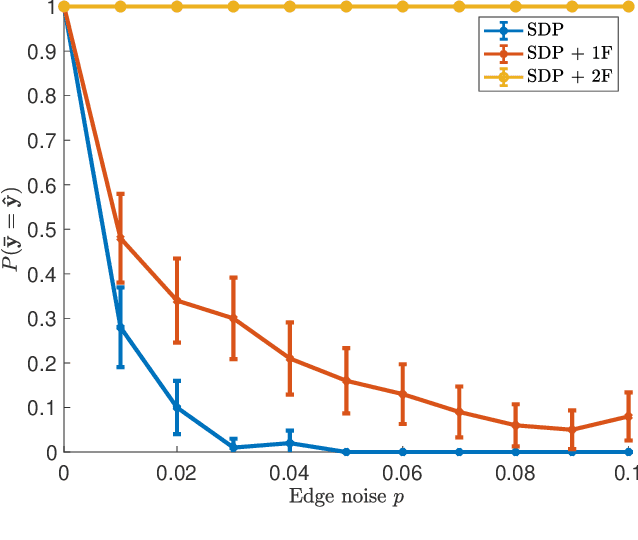
Many inference problems in structured prediction can be modeled as maximizing a score function on a space of labels, where graphs are a natural representation to decompose the total score into a sum of unary (nodes) and pairwise (edges) scores. Given a generative model with an undirected connected graph $G$ and true vector of binary labels, it has been previously shown that when $G$ has good expansion properties, such as complete graphs or $d$-regular expanders, one can exactly recover the true labels (with high probability and in polynomial time) from a single noisy observation of each edge and node. We analyze the previously studied generative model by Globerson et al. (2015) under a notion of statistical parity. That is, given a fair binary node labeling, we ask the question whether it is possible to recover the fair assignment, with high probability and in polynomial time, from single edge and node observations. We find that, in contrast to the known trade-offs between fairness and model performance, the addition of the fairness constraint improves the probability of exact recovery. We effectively explain this phenomenon and empirically show how graphs with poor expansion properties, such as grids, are now capable to achieve exact recovery with high probability. Finally, as a byproduct of our analysis, we provide a tighter minimum-eigenvalue bound than that of Weyl's inequality.
Multi-step-ahead Prediction from Short-term Data by Delay-embedding-based Forecast Machine
May 16, 2020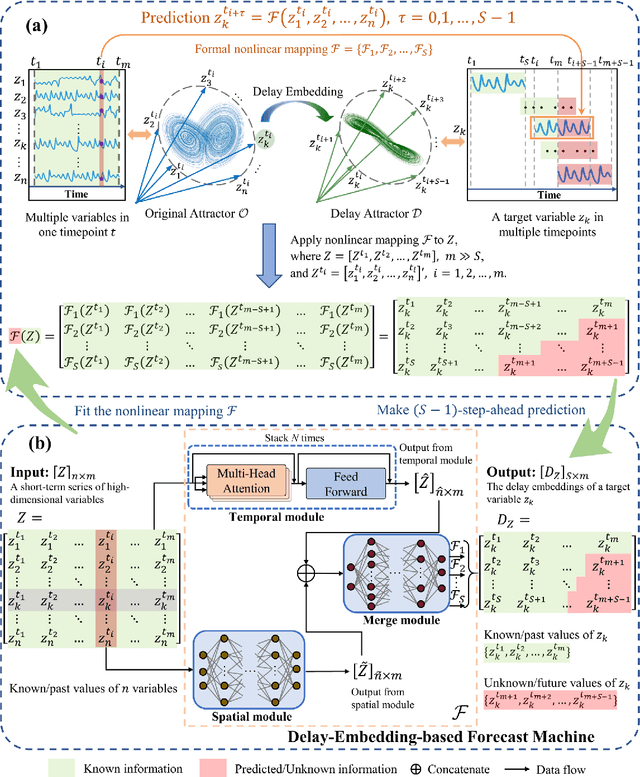
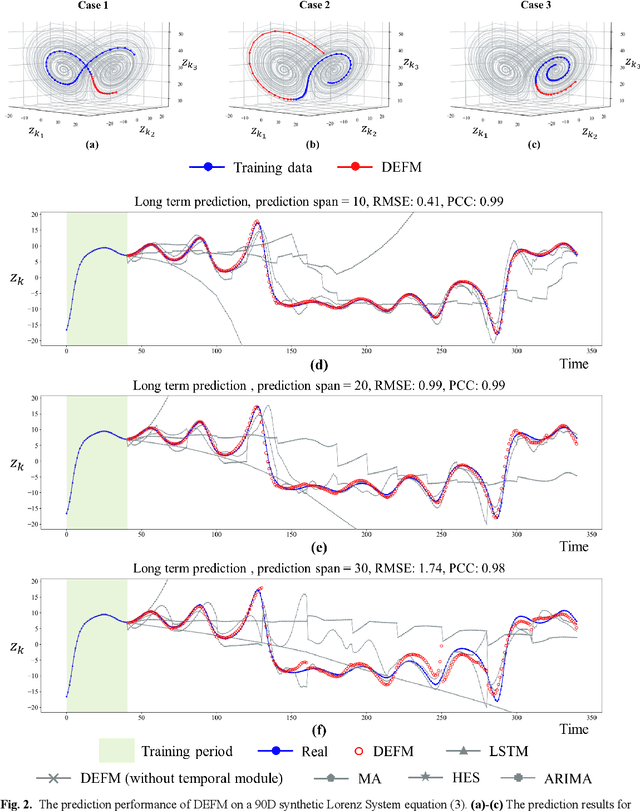
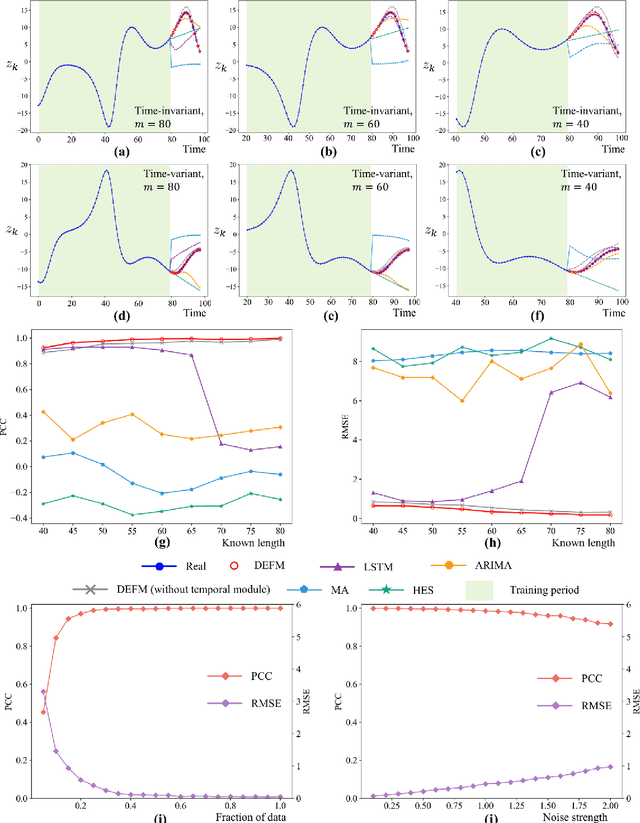
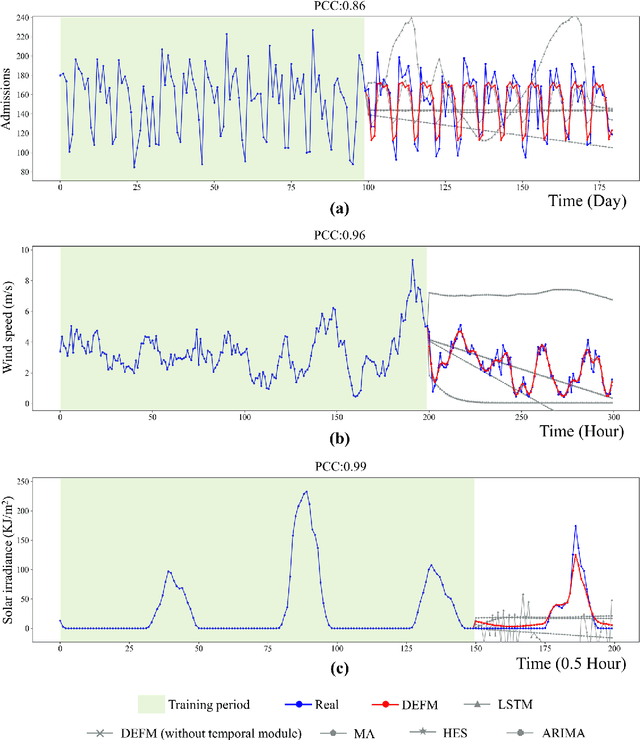
Making accurate multi-step-ahead prediction for a complex system is a challenge for many practical applications, especially when only short-term time-series data are available. In this work, we proposed a novel framework, Delay-Embedding-based Forecast Machine (DEFM), to predict the future values of a target variable in an accurate and multi-step-ahead manner based on the high-dimensional short-term measurements. With a three-module spatiotemporal architecture, DEFM leverages deep learning to effectively extract both the spatially and sequentially associated information from the short-term dynamics even with time-varying parameters or additive noise. Being trained through a self-supervised scheme, DEFM well fits a nonlinear transformation that maps from the observed high-dimensional information to the delay embeddings of a target variable, thus predicting the future information. The effectiveness and accuracy of DEFM is demonstrated by applications on both representative models and six real-world datasets. The comparison with four traditional prediction methods exhibits the superiority and robustness of DEFM.