 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pheme: Efficient and Conversational Speech Generation
Jan 05, 2024
In recent years, speech generation has seen remarkable progress, now achieving one-shot generation capability that is often virtually indistinguishable from real human voice. Integrating such advancements in speech generation with large language models might revolutionize a wide range of applications. However, certain applications, such as assistive conversational systems, require natural and conversational speech generation tools that also operate efficiently in real time. Current state-of-the-art models like VALL-E and SoundStorm, powered by hierarchical neural audio codecs, require large neural components and extensive training data to work well. In contrast, MQTTS aims to build more compact conversational TTS models while capitalizing on smaller-scale real-life conversational speech data. However, its autoregressive nature yields high inference latency and thus limits its real-time usage. In order to mitigate the current limitations of the state-of-the-art TTS models while capitalizing on their strengths, in this work we introduce the Pheme model series that 1) offers compact yet high-performing models, 2) allows for parallel speech generation of 3) natural conversational speech, and 4) it can be trained efficiently on smaller-scale conversational data, cutting data demands by more than 10x but still matching the quality of the autoregressive TTS models. We also show that through simple teacher-student distillation we can meet significant improvements in voice quality for single-speaker setups on top of pretrained Pheme checkpoints, relying solely on synthetic speech generated by much larger teacher models. Audio samples and pretrained models are available online.
Combining Convolution Neural Networks with Long-Short Time Memory Layers to Predict Parkinson's Disease Progression
Dec 28, 2023Parkinson's disease is a neurological condition that occurs in nearly 1% of the world's population. The disease is manifested by a drop in dopamine production, symptoms are cognitive and behavioural and include a wide range of personality changes, depressive disorders, memory problems, and emotional dysregulation, which can occur as the disease progresses. Early diagnosis and accurate staging of the disease are essential to apply the appropriate therapeutic approaches to slow cognitive and motor decline. Currently, there is not a single blood test or biomarker available to diagnose Parkinson's disease. Magnetic resonance imaging has been used for the past three decades to diagnose and distinguish between PD and other neurological conditions. However, in recent years new possibilities have arisen: several AI algorithms have been developed to increase the precision and accuracy of differential diagnosis of PD at an early stage. To our knowledge, no AI tools have been designed to identify the stage of progression. This paper aims to fill this gap. Using the "Parkinson's Progression Markers Initiative" dataset, which reports the patient's MRI and an indication of the disease stage, we developed a model to identify the level of progression. The images and the associated scores were used for training and assessing different deep-learning models. Our analysis distinguished four distinct disease progression levels based on a standard scale (Hoehn and Yah scale). The final architecture consists of the cascading of a 3DCNN network, adopted to reduce and extract the spatial characteristics of the RMI for efficient training of the successive LSTM layers, aiming at modelling the temporal dependencies among the data. Our results show that the proposed 3DCNN + LSTM model achieves state-of-the-art results by classifying the elements with 91.90\% as macro averaged OVR AUC on four classes
2D Sinc Interpolation-Based Fractional Delay and Doppler Estimation Using Time and Frequency Shifted Gaussian Pulses
Dec 08, 2023An accurate delay and Doppler estimation method for a radar system using time and frequency-shifted pulses with pseudo-random numbers is proposed. The ambiguity function of the transmitted signal has a strong peak at the origin and is close to zero if delay and Doppler are more than the inverses of the bandwidth and time-width. A two-dimensional (2D) sinc function gives a good approximation of the ambiguity function around the origin, by which fractional delay and Doppler are accurately estimated.
FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Inference
Jan 08, 2024The large number of parameters in Pretrained Language Models enhance their performance, but also make them resource-intensive, making it challenging to deploy them on commodity hardware like a single GPU. Due to the memory and power limitations of these devices, model compression techniques are often used to decrease both the model's size and its inference latency. This usually results in a trade-off between model accuracy and efficiency. Therefore, optimizing this balance is essential for effectively deploying LLMs on commodity hardware. A significant portion of the efficiency challenge is the Feed-forward network (FFN) component, which accounts for roughly $\frac{2}{3}$ total parameters and inference latency. In this paper, we first observe that only a few neurons of FFN module have large output norm for any input tokens, a.k.a. heavy hitters, while the others are sparsely triggered by different tokens. Based on this observation, we explicitly split the FFN into two parts according to the heavy hitters. We improve the efficiency-accuracy trade-off of existing compression methods by allocating more resource to FFN parts with heavy hitters. In practice, our method can reduce model size by 43.1\% and bring $1.25\sim1.56\times$ wall clock time speedup on different hardware with negligible accuracy drop.
Digital Twin for Autonomous Surface Vessels for Safe Maritime Navigation
Jan 08, 2024Autonomous surface vessels (ASVs) play an increasingly important role in the safety and sustainability of open sea operations. Since most maritime accidents are related to human failure, intelligent algorithms for autonomous collision avoidance and path following can drastically reduce the risk in the maritime sector. A DT is a virtual representative of a real physical system and can enhance the situational awareness (SITAW) of such an ASV to generate optimal decisions. This work builds on an existing DT framework for ASVs and demonstrates foundations for enabling predictive, prescriptive, and autonomous capabilities. In this context, sophisticated target tracking approaches are crucial for estimating and predicting the position and motion of other dynamic objects. The applied tracking method is enabled by real-time automatic identification system (AIS) data and synthetic light detection and ranging (Lidar) measurements. To guarantee safety during autonomous operations, we applied a predictive safety filter, based on the concept of nonlinear model predictive control (NMPC). The approaches are implemented into a DT built with the Unity game engine. As a result, this work demonstrates the potential of a DT capable of making predictions, playing through various what-if scenarios, and providing optimal control decisions according to its enhanced SITAW.
Automated Detection of Myopic Maculopathy in MMAC 2023: Achievements in Classification, Segmentation, and Spherical Equivalent Prediction
Jan 08, 2024Myopic macular degeneration is the most common complication of myopia and the primary cause of vision loss in individuals with pathological myopia. Early detection and prompt treatment are crucial in preventing vision impairment due to myopic maculopathy. This was the focus of the Myopic Maculopathy Analysis Challenge (MMAC), in which we participated. In task 1, classification of myopic maculopathy, we employed the contrastive learning framework, specifically SimCLR, to enhance classification accuracy by effectively capturing enriched features from unlabeled data. This approach not only improved the intrinsic understanding of the data but also elevated the performance of our classification model. For Task 2 (segmentation of myopic maculopathy plus lesions), we have developed independent segmentation models tailored for different lesion segmentation tasks and implemented a test-time augmentation strategy to further enhance the model's performance. As for Task 3 (prediction of spherical equivalent), we have designed a deep regression model based on the data distribution of the dataset and employed an integration strategy to enhance the model's prediction accuracy. The results we obtained are promising and have allowed us to position ourselves in the Top 6 of the classification task, the Top 2 of the segmentation task, and the Top 1 of the prediction task. The code is available at \url{https://github.com/liyihao76/MMAC_LaTIM_Solution}.
A Multi-Modal Approach Based on Large Vision Model for Close-Range Underwater Target Localization
Jan 09, 2024Underwater target localization uses real-time sensory measurements to estimate the position of underwater objects of interest, providing critical feedback information for underwater robots. While acoustic sensing is the most acknowledged method in underwater robots and possibly the only effective approach for long-range underwater target localization, such a sensing modality generally suffers from low resolution, high cost and high energy consumption, thus leading to a mediocre performance when applied to close-range underwater target localization. On the other hand, optical sensing has attracted increasing attention in the underwater robotics community for its advantages of high resolution and low cost, holding a great potential particularly in close-range underwater target localization. However, most existing studies in underwater optical sensing are restricted to specific types of targets due to the limited training data available. In addition, these studies typically focus on the design of estimation algorithms and ignore the influence of illumination conditions on the sensing performance, thus hindering wider applications in the real world. To address the aforementioned issues, this paper proposes a novel target localization method that assimilates both optical and acoustic sensory measurements to estimate the 3D positions of close-range underwater targets. A test platform with controllable illumination conditions is designed and developed to experimentally investigate the proposed multi-modal sensing approach. A large vision model is applied to process the optical imaging measurements, eliminating the requirement for training data acquisition, thus significantly expanding the scope of potential applications. Extensive experiments are conducted, the results of which validate the effectiveness of the proposed underwater target localization method.
Advancing Deep Active Learning & Data Subset Selection: Unifying Principles with Information-Theory Intuitions
Jan 09, 2024At its core, this thesis aims to enhance the practicality of deep learning by improving the label and training efficiency of deep learning models. To this end, we investigate data subset selection techniques, specifically active learning and active sampling, grounded in information-theoretic principles. Active learning improves label efficiency, while active sampling enhances training efficiency. Supervised deep learning models often require extensive training with labeled data. Label acquisition can be expensive and time-consuming, and training large models is resource-intensive, hindering the adoption outside academic research and ``big tech.'' Existing methods for data subset selection in deep learning often rely on heuristics or lack a principled information-theoretic foundation. In contrast, this thesis examines several objectives for data subset selection and their applications within deep learning, striving for a more principled approach inspired by information theory. We begin by disentangling epistemic and aleatoric uncertainty in single forward-pass deep neural networks, which provides helpful intuitions and insights into different forms of uncertainty and their relevance for data subset selection. We then propose and investigate various approaches for active learning and data subset selection in (Bayesian) deep learning. Finally, we relate various existing and proposed approaches to approximations of information quantities in weight or prediction space. Underpinning this work is a principled and practical notation for information-theoretic quantities that includes both random variables and observed outcomes. This thesis demonstrates the benefits of working from a unified perspective and highlights the potential impact of our contributions to the practical application of deep learning.
DedustNet: A Frequency-dominated Swin Transformer-based Wavelet Network for Agricultural Dust Removal
Jan 09, 2024While dust significantly affects the environmental perception of automated agricultural machines, the existing deep learning-based methods for dust removal require further research and improvement in this area to improve the performance and reliability of automated agricultural machines in agriculture. We propose an end-to-end trainable learning network (DedustNet) to solve the real-world agricultural dust removal task. To our knowledge, DedustNet is the first time Swin Transformer-based units have been used in wavelet networks for agricultural image dusting. Specifically, we present the frequency-dominated block (DWTFormer block and IDWTFormer block) by adding a spatial features aggregation scheme (SFAS) to the Swin Transformer and combining it with the wavelet transform, the DWTFormer block and IDWTFormer block, alleviating the limitation of the global receptive field of Swin Transformer when dealing with complex dusty backgrounds. Furthermore, We propose a cross-level information fusion module to fuse different levels of features and effectively capture global and long-range feature relationships. In addition, we present a dilated convolution module to capture contextual information guided by wavelet transform at multiple scales, which combines the advantages of wavelet transform and dilated convolution. Our algorithm leverages deep learning techniques to effectively remove dust from images while preserving the original structural and textural features. Compared to existing state-of-the-art methods, DedustNet achieves superior performance and more reliable results in agricultural image dedusting, providing strong support for the application of agricultural machinery in dusty environments. Additionally, the impressive performance on real-world hazy datasets and application tests highlights DedustNet superior generalization ability and computer vision-related application performance.
Large Pre-trained time series models for cross-domain Time series analysis tasks
Nov 19, 2023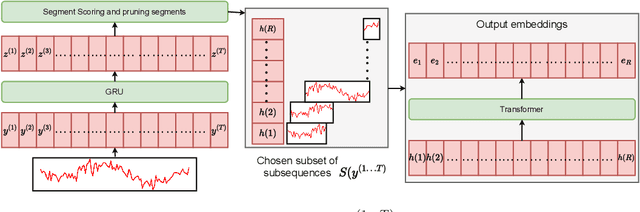
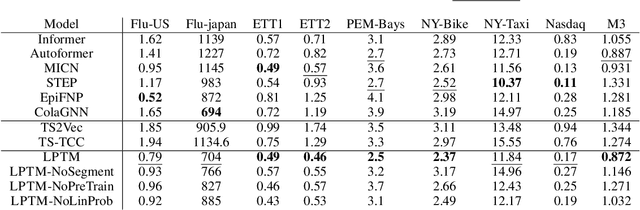
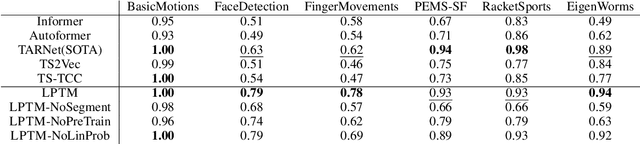
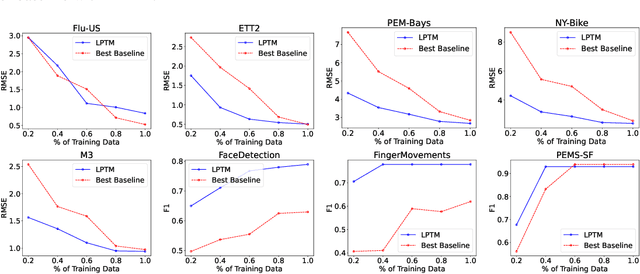
Large pre-trained models have been instrumental in significant advancements in domains like language and vision making model training for individual downstream tasks more efficient as well as provide superior performance. However, tackling time-series analysis tasks usually involves designing and training a separate model from scratch leveraging training data and domain expertise specific to the task. We tackle a significant challenge for pre-training a general time-series model from multiple heterogeneous time-series dataset: providing semantically useful inputs to models for modeling time series of different dynamics from different domains. We observe that partitioning time-series into segments as inputs to sequential models produces semantically better inputs and propose a novel model LPTM that automatically identifies optimal dataset-specific segmentation strategy leveraging self-supervised learning loss during pre-training. LPTM provides performance similar to or better than domain-specific state-of-art model and is significantly more data and compute efficient taking up to 40% less data as well as 50% less training time to achieve state-of-art performance in a wide range of time-series analysis tasks from multiple disparate domain.