 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intuitiveness in Active Teaching
Dec 25, 2020
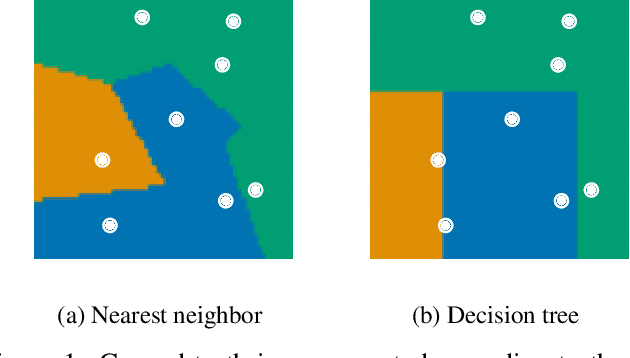
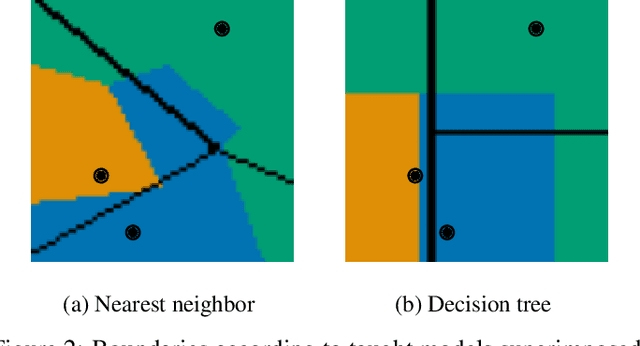
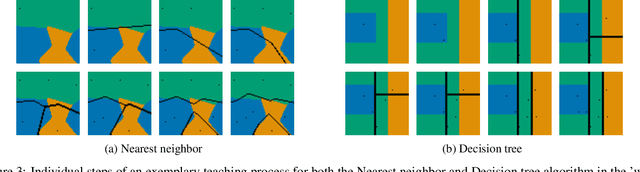
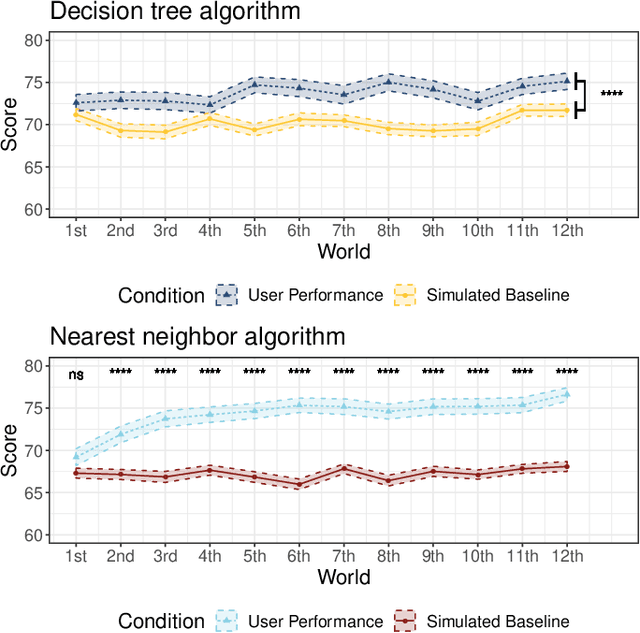
Machine learning is a double-edged sword: it gives rise to astonishing results in automated systems, but at the cost of tremendously large data requirements. This makes many successful algorithms from machine learning unsuitable for human-machine interaction, where the machine must learn from a small number of training samples that can be provided by a user within a reasonable time frame. Fortunately, the user can tailor the training data they create to be as useful as possible, severely limiting its necessary size -- as long as they know about the machine's requirements and limitations. Of course, acquiring this knowledge can in turn be cumbersome and costly. This raises the question how easy machine learning algorithms are to interact with. In this work we address this issue by analyzing the intuitiveness of certain algorithms when they are actively taught by users. After developing a theoretical framework of intuitiveness as a property of algorithms, we present and discuss the results of a large-scale user study into the performance and teaching strategies of 800 users interacting with prominent machine learning algorithms. Via this extensive examination we offer a systematic method to judge the efficacy of human-machine interactions and thus, to scrutinize how accessible, understandable, and fair, a system is.
A Recurrent Vision-and-Language BERT for Navigation
Nov 26, 2020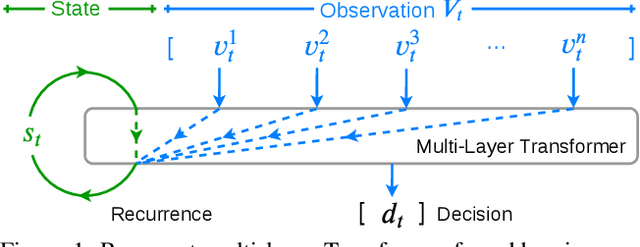
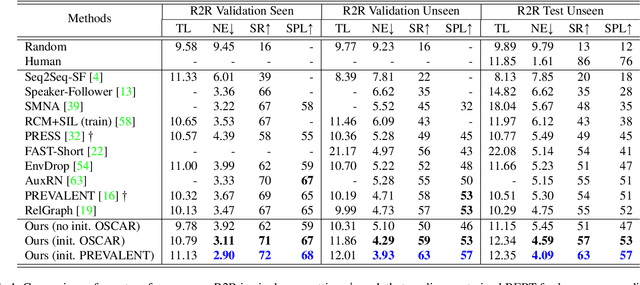
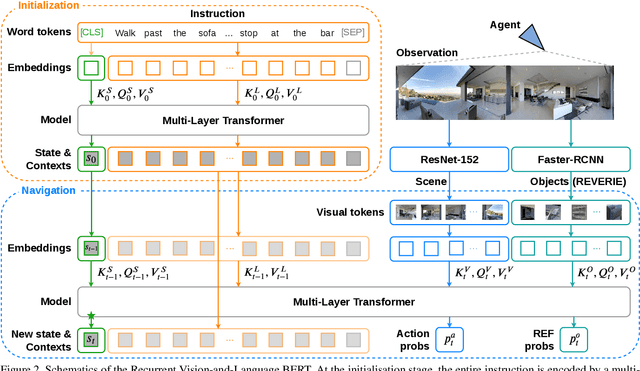
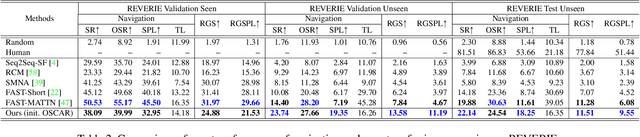
Accuracy of many visiolinguistic tasks has benefited significantly from the application of vision-and-language (V&L) BERT. However, its application for the task of vision-and-language navigation (VLN) remains limited. One reason for this is the difficulty adapting the BERT architecture to the partially observable Markov decision process present in VLN, requiring history-dependent attention and decision making. In this paper we propose a recurrent BERT model that is time-aware for use in VLN. Specifically, we equip the BERT model with a recurrent function that maintains cross-modal state information for the agent. Through extensive experiments on R2R and REVERIE we demonstrate that our model can replace more complex encoder-decoder models to achieve state-of-the-art results. Moreover, our approach can be generalised to other transformer-based architectures, supports pre-training, and is capable of multi-task learning suggesting the potential to merge a wide range of BERT-like models for other vision and language tasks.
Impact of natural disasters on consumer behavior: case of the 2017 El Nino phenomenon in Peru
Aug 11, 2020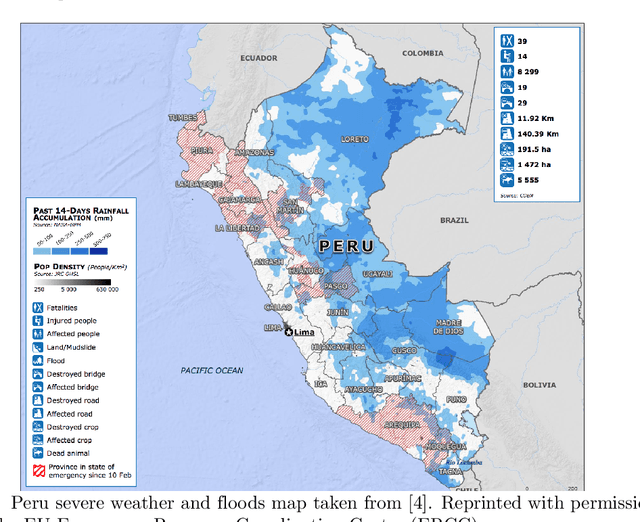
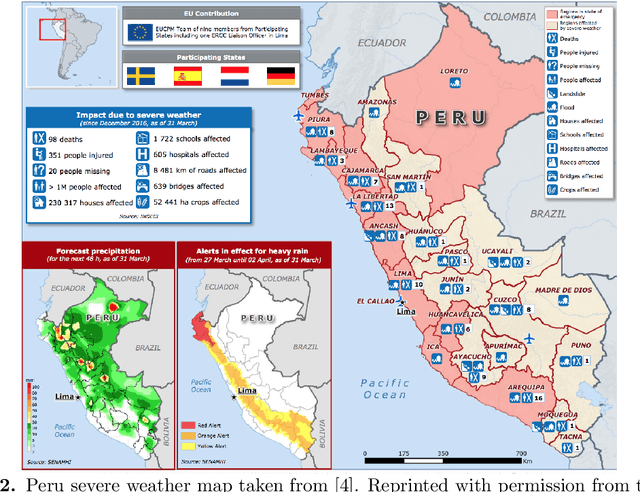
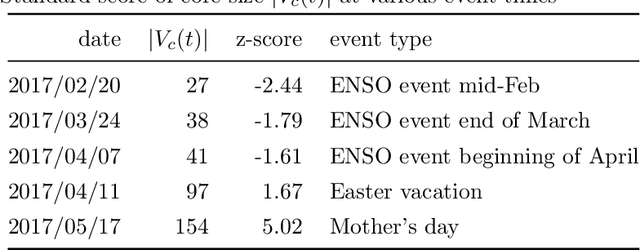
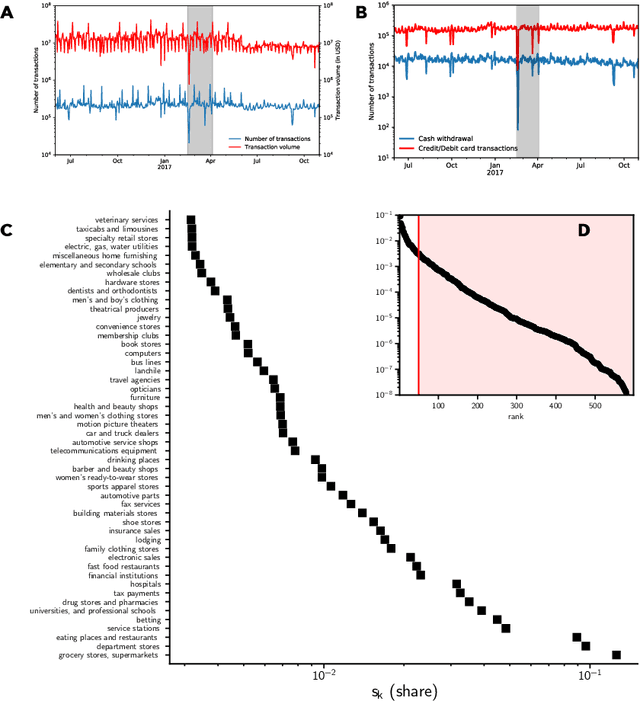
El Nino is an extreme weather event featuring unusual warming of surface waters in the eastern equatorial Pacific Ocean. This phenomenon is characterized by heavy rains and floods that negatively affect the economic activities of the impacted areas. Understanding how this phenomenon influences consumption behavior at different granularity levels is essential for recommending strategies to normalize the situation. With this aim, we performed a multi-scale analysis of data associated with bank transactions involving credit and debit cards. Our findings can be summarized into two main results: Coarse-grained analysis reveals the presence of the El Ni\~no phenomenon and the recovery time in a given territory, while fine-grained analysis demonstrates a change in individuals' purchasing patterns and in merchant relevance as a consequence of the climatic event. The results also indicate that society successfully withstood the natural disaster owing to the economic structure built over time. In this study, we present a new method that may be useful for better characterizing future extreme events.
Laplacian Change Point Detection for Dynamic Graphs
Jul 02, 2020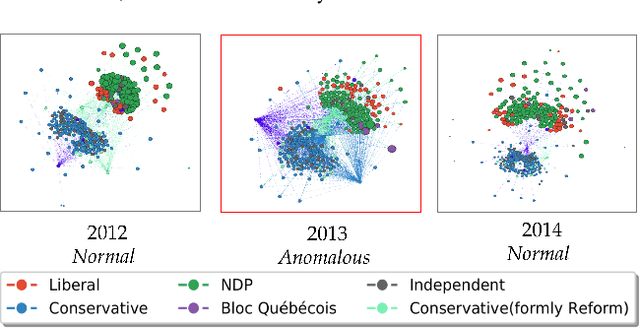

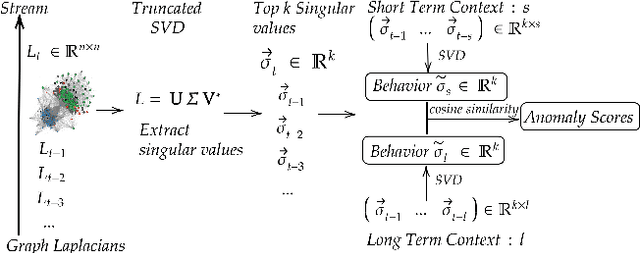

Dynamic and temporal graphs are rich data structures that are used to model complex relationships between entities over time. In particular, anomaly detection in temporal graphs is crucial for many real world applications such as intrusion identification in network systems, detection of ecosystem disturbances and detection of epidemic outbreaks. In this paper, we focus on change point detection in dynamic graphs and address two main challenges associated with this problem: I) how to compare graph snapshots across time, II) how to capture temporal dependencies. To solve the above challenges, we propose Laplacian Anomaly Detection (LAD) which uses the spectrum of the Laplacian matrix of the graph structure at each snapshot to obtain low dimensional embeddings. LAD explicitly models short term and long term dependencies by applying two sliding windows. In synthetic experiments, LAD outperforms the state-of-the-art method. We also evaluate our method on three real dynamic networks: UCI message network, US senate co-sponsorship network and Canadian bill voting network. In all three datasets, we demonstrate that our method can more effectively identify anomalous time points according to significant real world events.
Wireless Localisation in WiFi using Novel Deep Architectures
Oct 16, 2020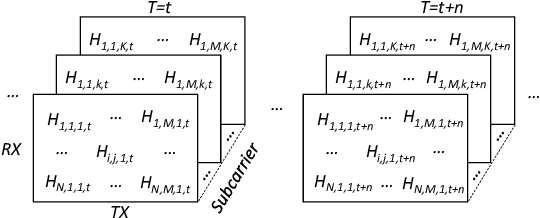
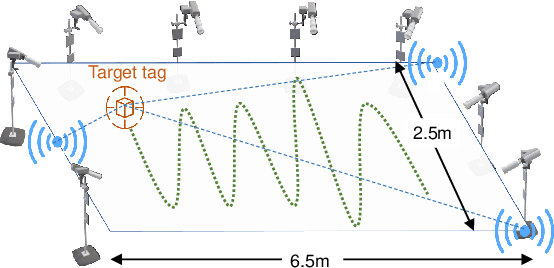
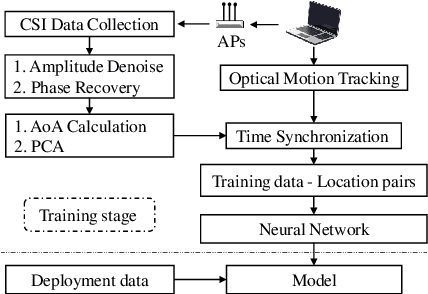
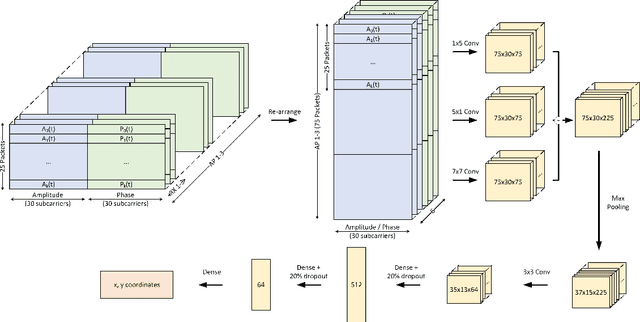
This paper studies the indoor localisation of WiFi devices based on a commodity chipset and standard channel sounding. First, we present a novel shallow neural network (SNN) in which features are extracted from the channel state information (CSI) corresponding to WiFi subcarriers received on different antennas and used to train the model. The single-layer architecture of this localisation neural network makes it lightweight and easy-to-deploy on devices with stringent constraints on computational resources. We further investigate for localisation the use of deep learning models and design novel architectures for convolutional neural network (CNN) and long-short term memory (LSTM). We extensively evaluate these localisation algorithms for continuous tracking in indoor environments. Experimental results prove that even an SNN model, after a careful handcrafted feature extraction, can achieve accurate localisation. Meanwhile, using a well-organised architecture, the neural network models can be trained directly with raw data from the CSI and localisation features can be automatically extracted to achieve accurate position estimates. We also found that the performance of neural network-based methods are directly affected by the number of anchor access points (APs) regardless of their structure. With three APs, all neural network models proposed in this paper can obtain localisation accuracy of around 0.5 metres. In addition the proposed deep NN architecture reduces the data pre-processing time by 6.5 hours compared with a shallow NN using the data collected in our testbed. In the deployment phase, the inference time is also significantly reduced to 0.1 ms per sample. We also demonstrate the generalisation capability of the proposed method by evaluating models using different target movement characteristics to the ones in which they were trained.
Efficient Evaluation-Time Uncertainty Estimation by Improved Distillation
Jun 12, 2019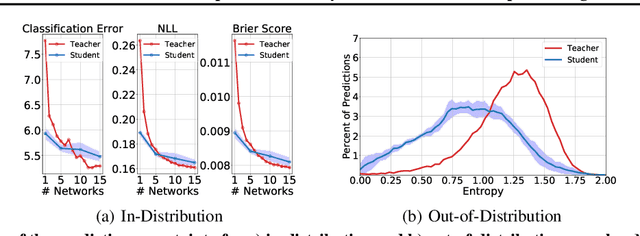
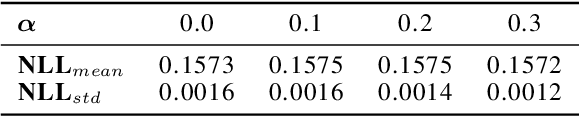
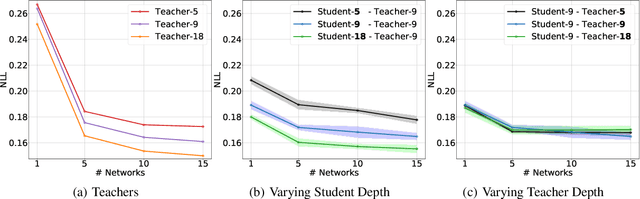
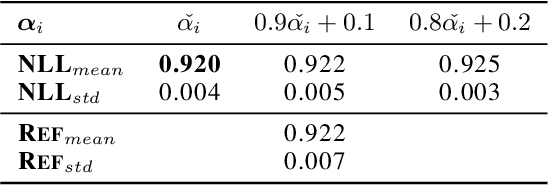
In this work we aim to obtain computationally-efficient uncertainty estimates with deep networks. For this, we propose a modified knowledge distillation procedure that achieves state-of-the-art uncertainty estimates both for in and out-of-distribution samples. Our contributions include a) demonstrating and adapting to distillation's regularization effect b) proposing a novel target teacher distribution c) a simple augmentation procedure to improve out-of-distribution uncertainty estimates d) shedding light on the distillation procedure through comprehensive set of experiments.
Am I Rare? An Intelligent Summarization Approach for Identifying Hidden Anomalies
Dec 24, 2020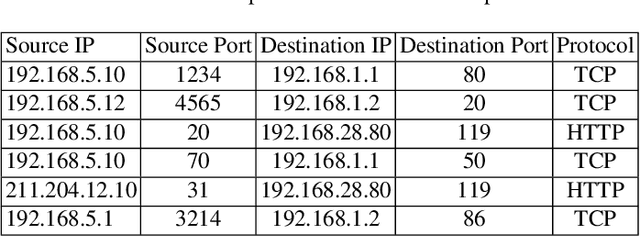
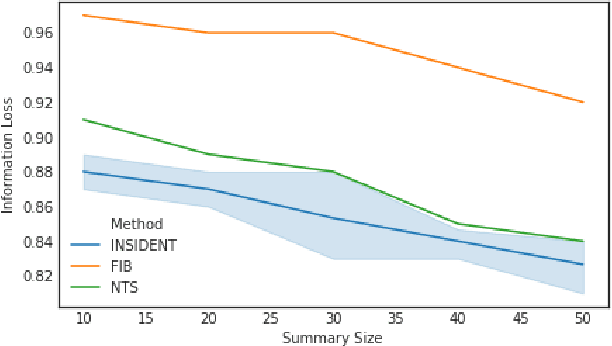
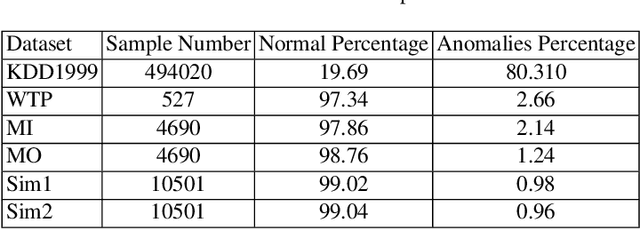
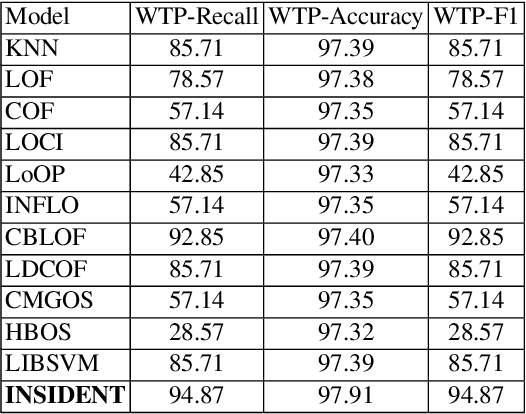
Monitoring network traffic data to detect any hidden patterns of anomalies is a challenging and time-consuming task that requires high computing resources. To this end, an appropriate summarization technique is of great importance, where it can be a substitute for the original data. However, the summarized data is under the threat of removing anomalies. Therefore, it is vital to create a summary that can reflect the same pattern as the original data. Therefore, in this paper, we propose an INtelligent Summarization approach for IDENTifying hidden anomalies, called INSIDENT. The proposed approach guarantees to keep the original data distribution in summarized data. Our approach is a clustering-based algorithm that dynamically maps original feature space to a new feature space by locally weighting features in each cluster. Therefore, in new feature space, similar samples are closer, and consequently, outliers are more detectable. Besides, selecting representatives based on cluster size keeps the same distribution as the original data in summarized data. INSIDENT can be used both as the preprocess approach before performing anomaly detection algorithms and anomaly detection algorithm. The experimental results on benchmark datasets prove a summary of the data can be a substitute for original data in the anomaly detection task.
Combining Strategic Learning and Tactical Search in Real-Time Strategy Games
Sep 11, 2017

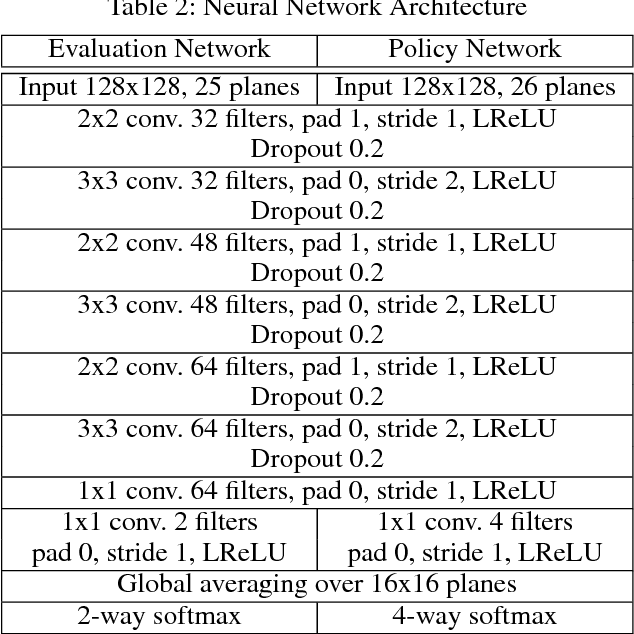
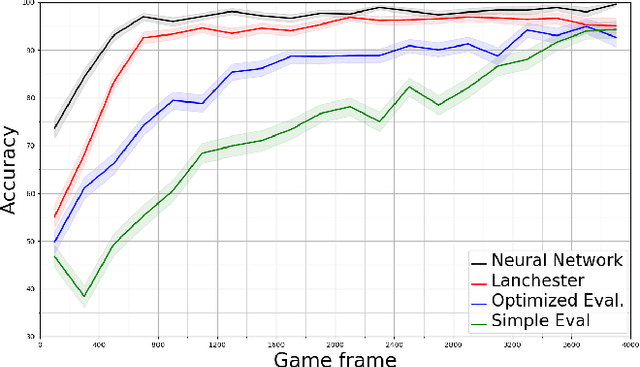
A commonly used technique for managing AI complexity in real-time strategy (RTS) games is to use action and/or state abstractions. High-level abstractions can often lead to good strategic decision making, but tactical decision quality may suffer due to lost details. A competing method is to sample the search space which often leads to good tactical performance in simple scenarios, but poor high-level planning. We propose to use a deep convolutional neural network (CNN) to select among a limited set of abstract action choices, and to utilize the remaining computation time for game tree search to improve low level tactics. The CNN is trained by supervised learning on game states labelled by Puppet Search, a strategic search algorithm that uses action abstractions. The network is then used to select a script --- an abstract action --- to produce low level actions for all units. Subsequently, the game tree search algorithm improves the tactical actions of a subset of units using a limited view of the game state only considering units close to opponent units. Experiments in the microRTS game show that the combined algorithm results in higher win-rates than either of its two independent components and other state-of-the-art microRTS agents. To the best of our knowledge, this is the first successful application of a convolutional network to play a full RTS game on standard game maps, as previous work has focused on sub-problems, such as combat, or on very small maps.
Reservoir Computing and its Sensitivity to Symmetry in the Activation Function
Sep 21, 2020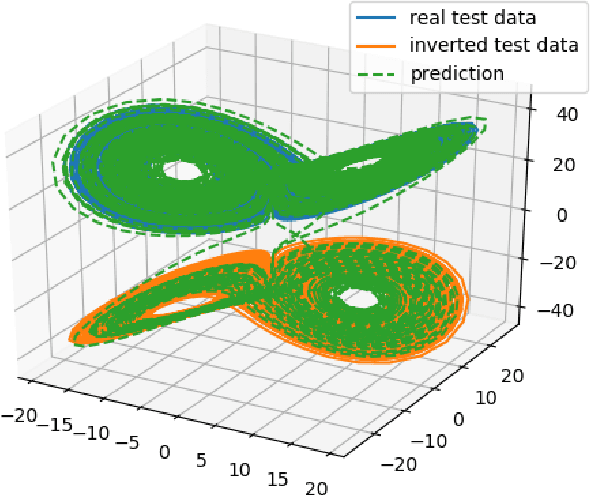
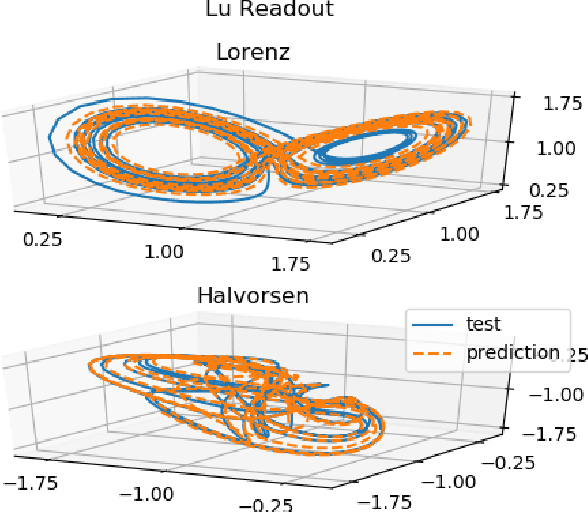
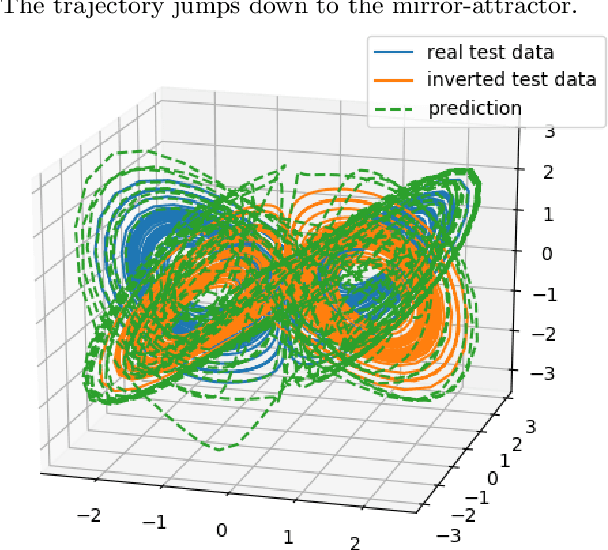
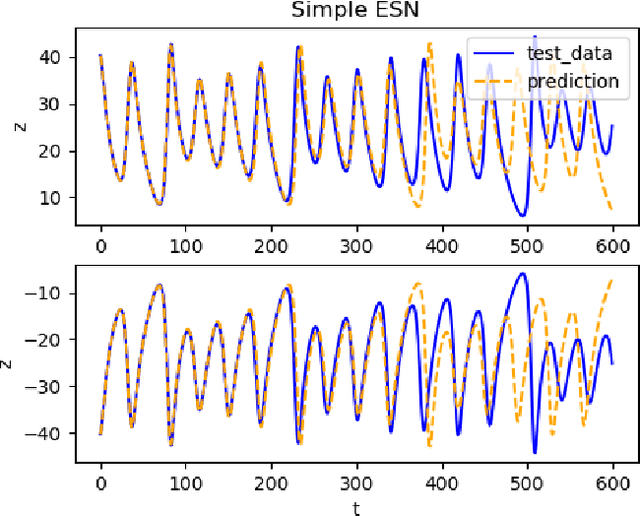
Reservoir computing has repeatedly been shown to be extremely successful in the prediction of nonlinear time-series. However, there is no complete understanding of the proper design of a reservoir yet. We find that the simplest popular setup has a harmful symmetry, which leads to the prediction of what we call mirror-attractor. We prove this analytically. Similar problems can arise in a general context, and we use them to explain the success or failure of some designs. The symmetry is a direct consequence of the hyperbolic tangent activation function. Further, four ways to break the symmetry are compared numerically: A bias in the output, a shift in the input, a quadratic term in the readout, and a mixture of even and odd activation functions. Firstly, we test their susceptibility to the mirror-attractor. Secondly, we evaluate their performance on the task of predicting Lorenz data with the mean shifted to zero. The short-time prediction is measured with the forecast horizon while the largest Lyapunov exponent and the correlation dimension are used to represent the climate. Finally, the same analysis is repeated on a combined dataset of the Lorenz attractor and the Halvorsen attractor, which we designed to reveal potential problems with symmetry. We find that all methods except the output bias are able to fully break the symmetry with input shift and quadratic readout performing the best overall.
4D Atlas: Statistical Analysis of the Spatiotemporal Variability in Longitudinal 3D Shape Data
Jan 23, 2021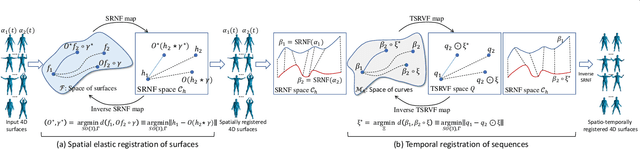
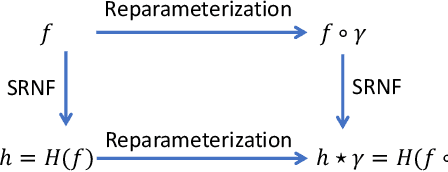
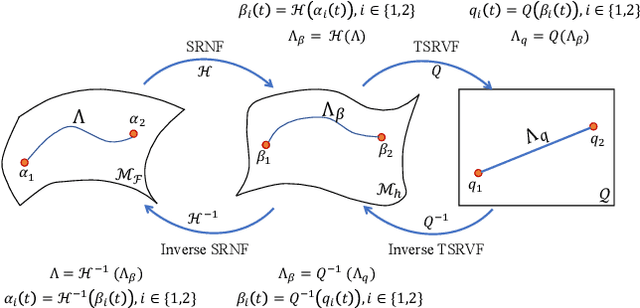

We propose a novel framework to learn the spatiotemporal variability in longitudinal 3D shape data sets, which contain observations of subjects that evolve and deform over time. This problem is challenging since surfaces come with arbitrary spatial and temporal parameterizations. Thus, they need to be spatially registered and temporally aligned onto each other. We solve this spatiotemporal registration problem using a Riemannian approach. We treat a 3D surface as a point in a shape space equipped with an elastic metric that measures the amount of bending and stretching that the surfaces undergo. A 4D surface can then be seen as a trajectory in this space. With this formulation, the statistical analysis of 4D surfaces becomes the problem of analyzing trajectories embedded in a nonlinear Riemannian manifold. However, computing spatiotemporal registration and statistics on nonlinear spaces relies on complex nonlinear optimizations. Our core contribution is the mapping of the surfaces to the space of Square-Root Normal Fields (SRNF) where the L2 metric is equivalent to the partial elastic metric in the space of surfaces. By solving the spatial registration in the SRNF space, analyzing 4D surfaces becomes the problem of analyzing trajectories embedded in the SRNF space, which is Euclidean. Here, we develop the building blocks that enable such analysis. These include the spatiotemporal registration of arbitrarily parameterized 4D surfaces even in the presence of large elastic deformations and large variations in their execution rates, the computation of geodesics between 4D surfaces, the computation of statistical summaries, such as means and modes of variation, and the synthesis of random 4D surfaces. We demonstrate the performance of the proposed framework using 4D facial surfaces and 4D human body shapes.