 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
Jul 25, 2020
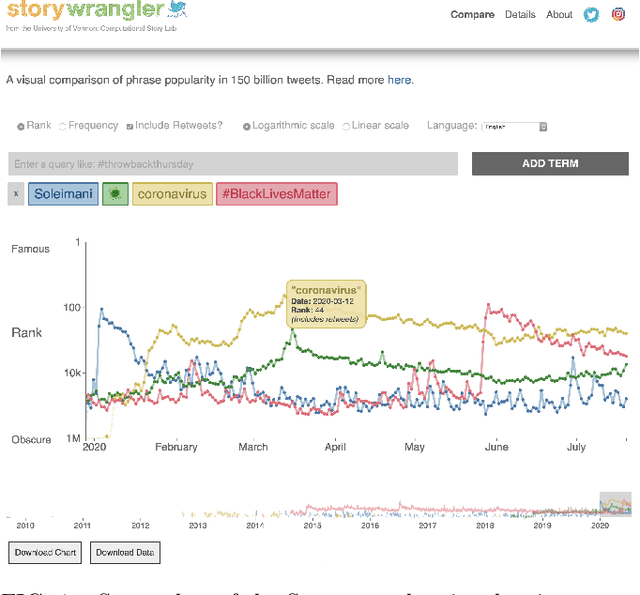
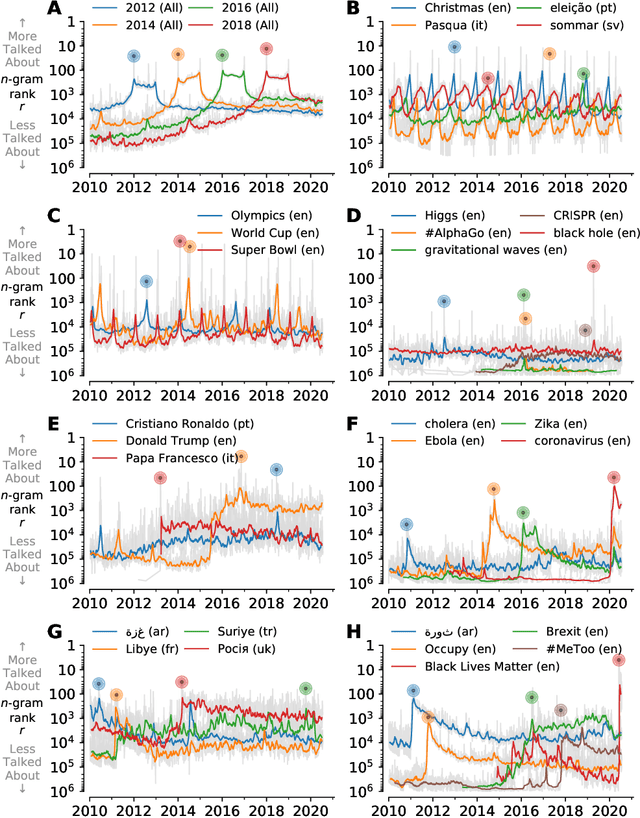
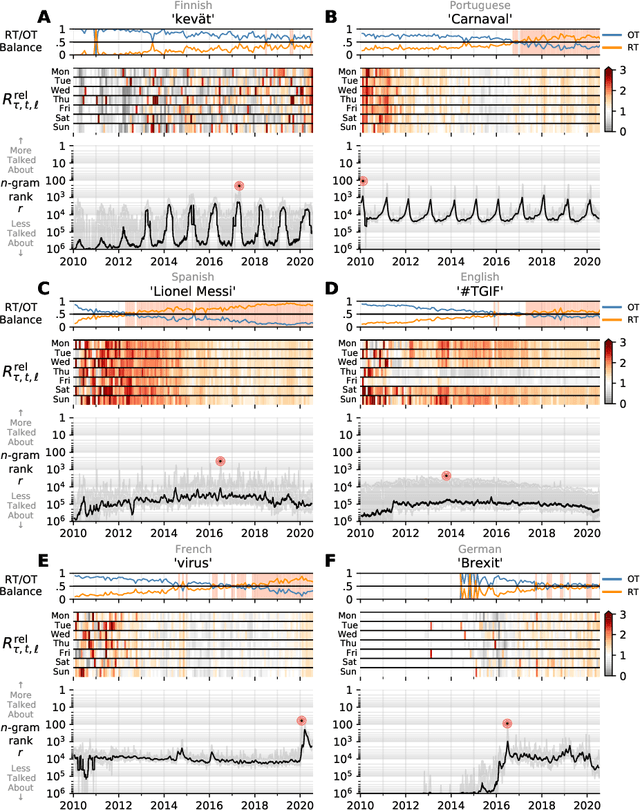
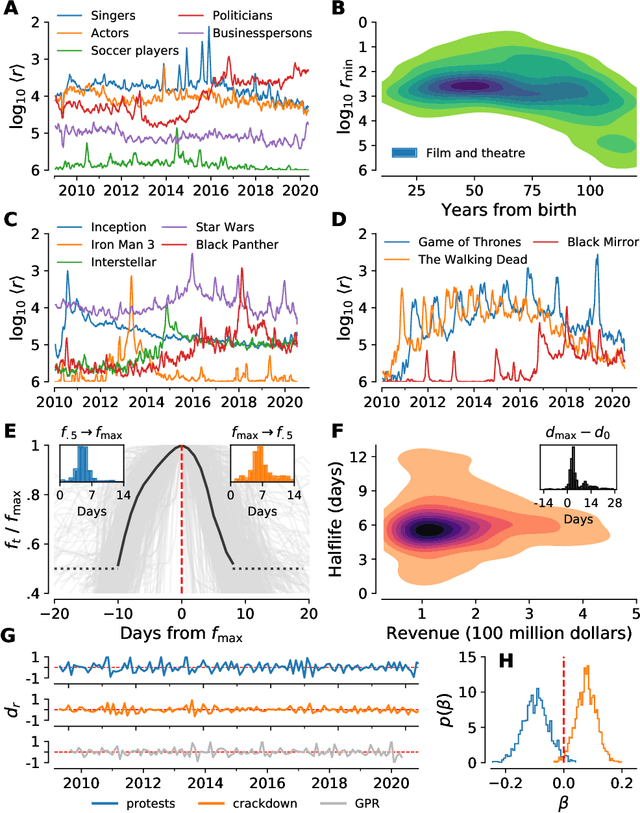
In real-time, Twitter strongly imprints world events, popular culture, and the day-to-day; Twitter records an ever growing compendium of language use and change; and Twitter has been shown to enable certain kinds of prediction. Vitally, and absent from many standard corpora such as books and news archives, Twitter also encodes popularity and spreading through retweets. Here, we describe Storywrangler, an ongoing, day-scale curation of over 100 billion tweets containing around 1 trillion 1-grams from 2008 to 2020. For each day, we break tweets into 1-, 2-, and 3-grams across 150+ languages, record usage frequencies, and generate Zipf distributions. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'.
Model-Coupled Autoencoder for Time Series Visualisation
Jan 21, 2016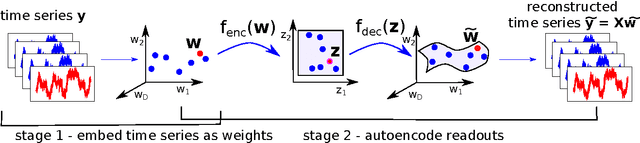
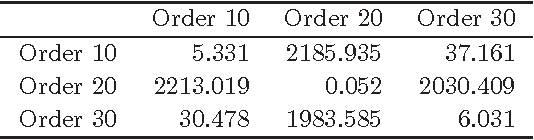
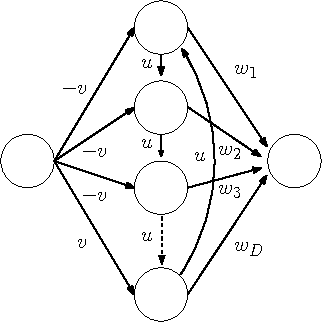
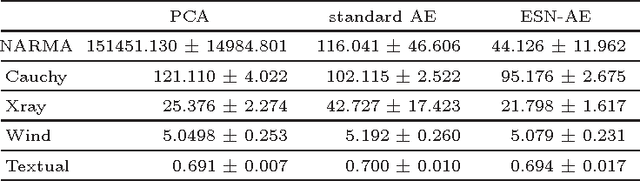
We present an approach for the visualisation of a set of time series that combines an echo state network with an autoencoder. For each time series in the dataset we train an echo state network, using a common and fixed reservoir of hidden neurons, and use the optimised readout weights as the new representation. Dimensionality reduction is then performed via an autoencoder on the readout weight representations. The crux of the work is to equip the autoencoder with a loss function that correctly interprets the reconstructed readout weights by associating them with a reconstruction error measured in the data space of sequences. This essentially amounts to measuring the predictive performance that the reconstructed readout weights exhibit on their corresponding sequences when plugged back into the echo state network with the same fixed reservoir. We demonstrate that the proposed visualisation framework can deal both with real valued sequences as well as binary sequences. We derive magnification factors in order to analyse distance preservations and distortions in the visualisation space. The versatility and advantages of the proposed method are demonstrated on datasets of time series that originate from diverse domains.
Common Spatial Generative Adversarial Networks based EEG Data Augmentation for Cross-Subject Brain-Computer Interface
Feb 08, 2021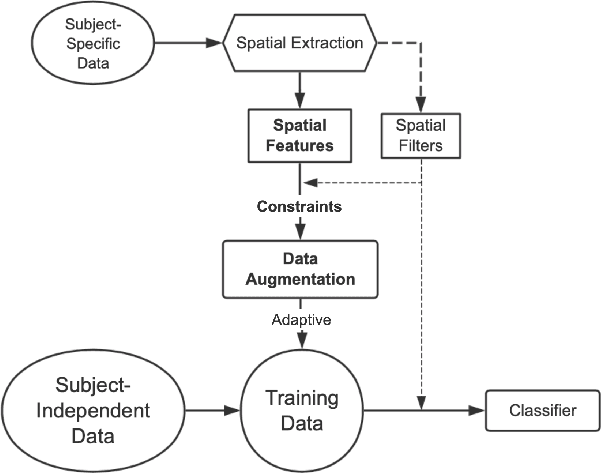
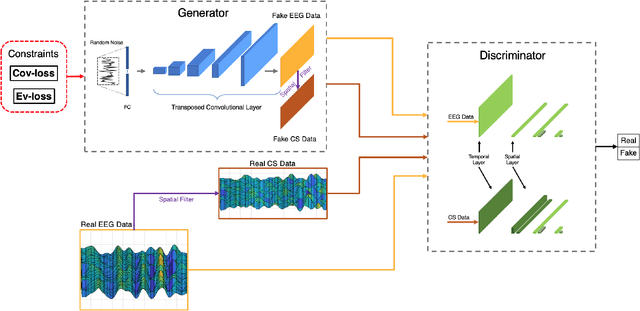
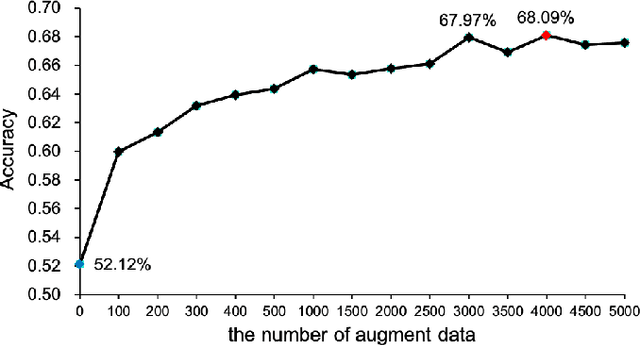
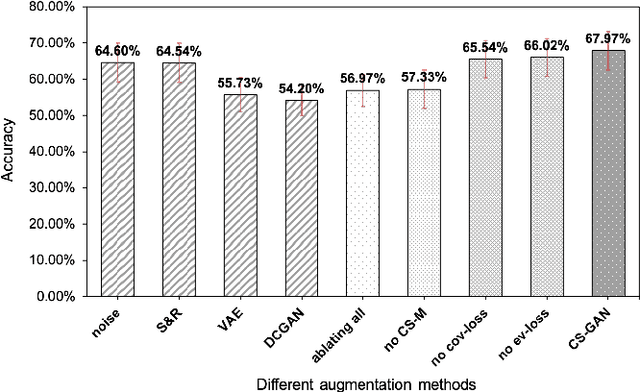
The cross-subject application of EEG-based brain-computer interface (BCI) has always been limited by large individual difference and complex characteristics that are difficult to perceive. Therefore, it takes a long time to collect the training data of each user for calibration. Even transfer learning method pre-training with amounts of subject-independent data cannot decode different EEG signal categories without enough subject-specific data. Hence, we proposed a cross-subject EEG classification framework with a generative adversarial networks (GANs) based method named common spatial GAN (CS-GAN), which used adversarial training between a generator and a discriminator to obtain high-quality data for augmentation. A particular module in the discriminator was employed to maintain the spatial features of the EEG signals and increase the difference between different categories, with two losses for further enhancement. Through adaptive training with sufficient augmentation data, our cross-subject classification accuracy yielded a significant improvement of 15.85% than leave-one subject-out (LOO) test and 8.57% than just adapting 100 original samples on the dataset 2a of BCI competition IV. Moreover, We designed a convolutional neural networks (CNNs) based classification method as a benchmark with a similar spatial enhancement idea, which achieved remarkable results to classify motor imagery EEG data. In summary, our framework provides a promising way to deal with the cross-subject problem and promote the practical application of BCI.
Towards Metric Temporal Answer Set Programming
Aug 05, 2020

We elaborate upon the theoretical foundations of a metric temporal extension of Answer Set Programming. In analogy to previous extensions of ASP with constructs from Linear Temporal and Dynamic Logic, we accomplish this in the setting of the logic of Here-and-There and its non-monotonic extension, called Equilibrium Logic. More precisely, we develop our logic on the same semantic underpinnings as its predecessors and thus use a simple time domain of bounded time steps. This allows us to compare all variants in a uniform framework and ultimately combine them in a common implementation.
Using vis-NIRS and Machine Learning methods to diagnose sugarcane soil chemical properties
Dec 23, 2020
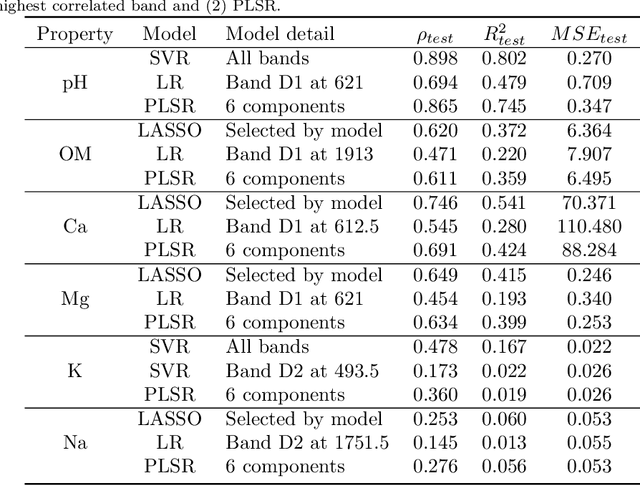
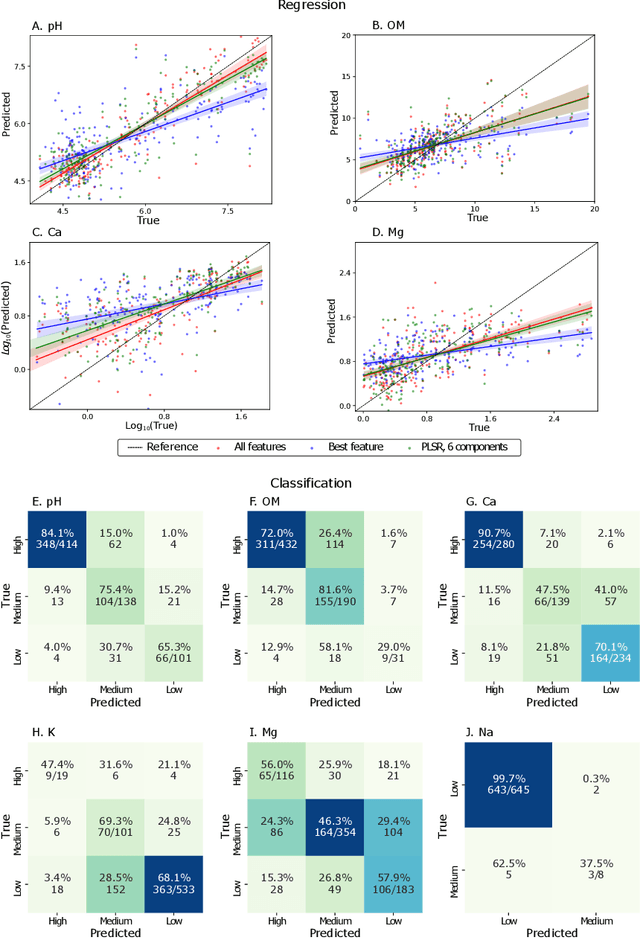
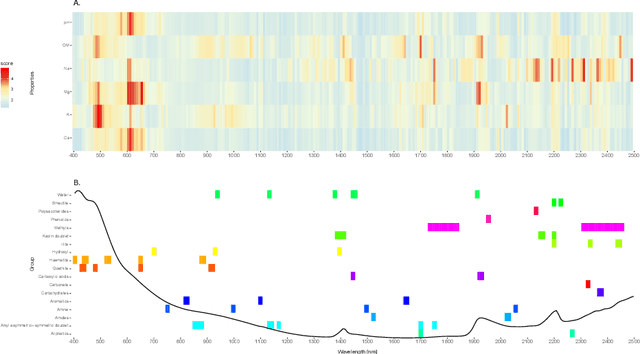
Knowing chemical soil properties might be determinant in crop management and total yield production. Traditional property estimation approaches are time-consuming and require complex lab setups, refraining farmers from taking steps towards optimal practices in their crops promptly. Property estimation from spectral signals(vis-NIRS), emerged as a low-cost, non-invasive, and non-destructive alternative. Current approaches use mathematical and statistical techniques, avoiding machine learning framework. Here we propose both regression and classification with machine learning techniques to assess performance in the prediction and infer categories of common soil properties (pH, soil organic matter, Ca, Na, K and Mg), evaluated by the most common metrics. In sugarcane soils, we use regression to estimate properties and classification to assess soil's property status and report the direct relation between spectra bands and direct measure of certain properties. In both cases, we achieved similar performance
Factorized Deep Generative Models for Trajectory Generation with Spatiotemporal-Validity Constraints
Sep 20, 2020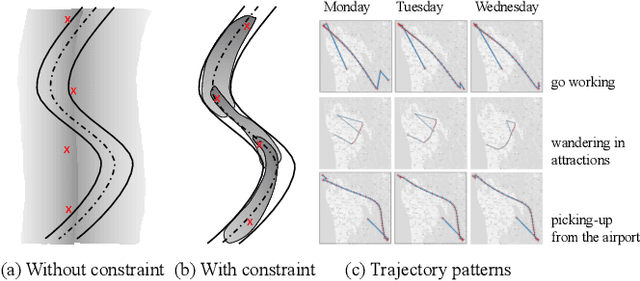
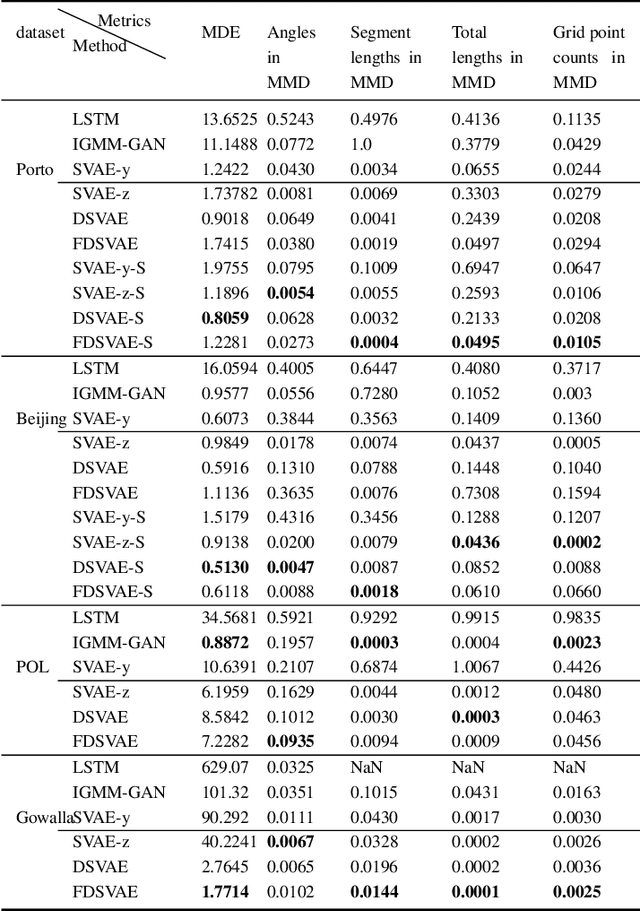
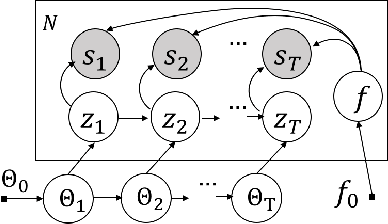
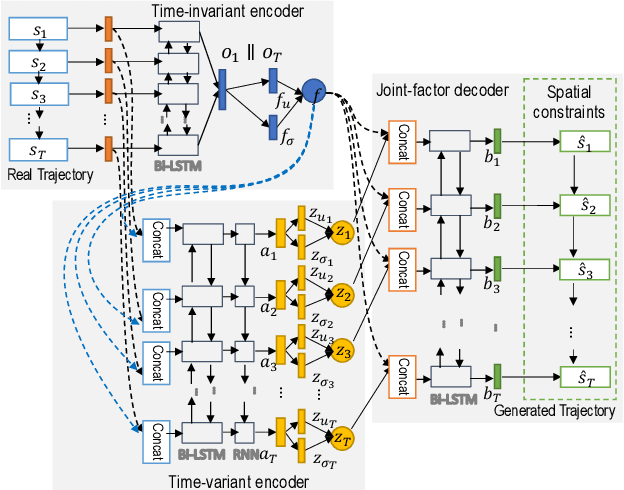
Trajectory data generation is an important domain that characterizes the generative process of mobility data. Traditional methods heavily rely on predefined heuristics and distributions and are weak in learning unknown mechanisms. Inspired by the success of deep generative neural networks for images and texts, a fast-developing research topic is deep generative models for trajectory data which can learn expressively explanatory models for sophisticated latent patterns. This is a nascent yet promising domain for many applications. We first propose novel deep generative models factorizing time-variant and time-invariant latent variables that characterize global and local semantics, respectively. We then develop new inference strategies based on variational inference and constrained optimization to encapsulate the spatiotemporal validity. New deep neural network architectures have been developed to implement the inference and generation models with newly-generalized latent variable priors. The proposed methods achieved significant improvements in quantitative and qualitative evaluations in extensive experiments.
Clustering Time Series and the Surprising Robustness of HMMs
Sep 14, 2016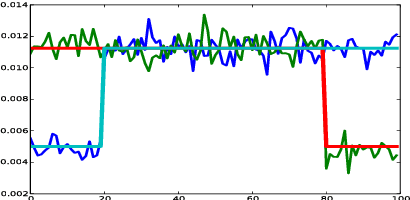
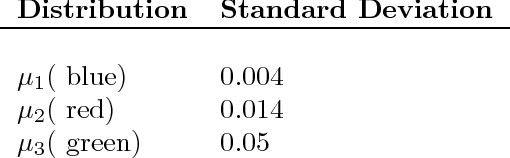
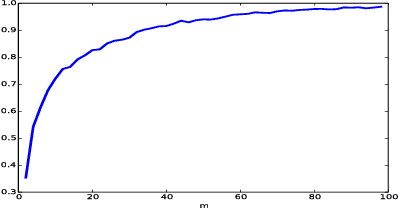
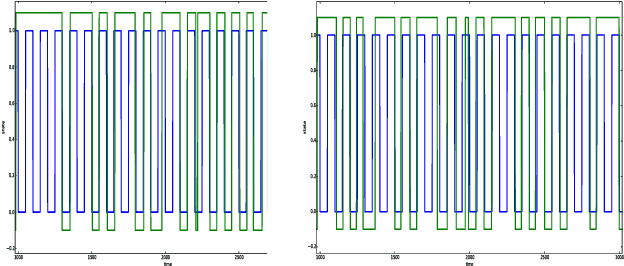
Suppose that we are given a time series where consecutive samples are believed to come from a probabilistic source, that the source changes from time to time and that the total number of sources is fixed. Our objective is to estimate the distributions of the sources. A standard approach to this problem is to model the data as a hidden Markov model (HMM). However, since the data often lacks the Markov or the stationarity properties of an HMM, one can ask whether this approach is still suitable or perhaps another approach is required. In this paper we show that a maximum likelihood HMM estimator can be used to approximate the source distributions in a much larger class of models than HMMs. Specifically, we propose a natural and fairly general non-stationary model of the data, where the only restriction is that the sources do not change too often. Our main result shows that for this model, a maximum-likelihood HMM estimator produces the correct second moment of the data, and the results can be extended to higher moments.
Algorithmic Complexities in Backpropagation and Tropical Neural Networks
Jan 03, 2021In this note, we propose a novel technique to reduce the algorithmic complexity of neural network training by using matrices of tropical real numbers instead of matrices of real numbers. Since the tropical arithmetics replaces multiplication with addition, and addition with max, we theoretically achieve several order of magnitude better constant factors in time complexities in the training phase. The fact that we replace the field of real numbers with the tropical semiring of real numbers and yet achieve the same classification results via neural networks come from deep results in topology and analysis, which we verify in our note. We then explore artificial neural networks in terms of tropical arithmetics and tropical algebraic geometry, and introduce the multi-layered tropical neural networks as universal approximators. After giving a tropical reformulation of the backpropagation algorithm, we verify the algorithmic complexity is substantially lower than the usual backpropagation as the tropical arithmetic is free of the complexity of usual multiplication.
Alignment Knowledge Distillation for Online Streaming Attention-based Speech Recognition
Feb 28, 2021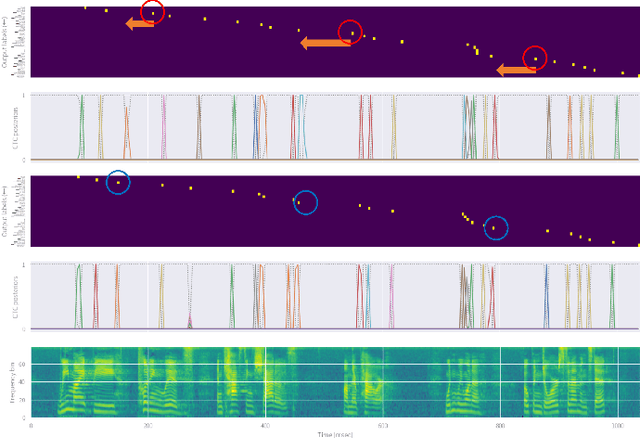
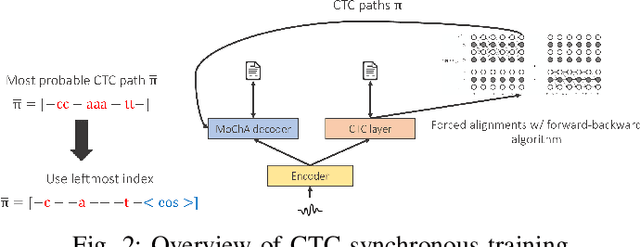
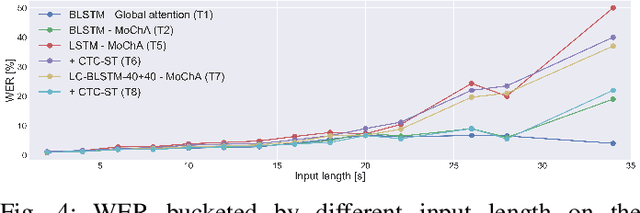
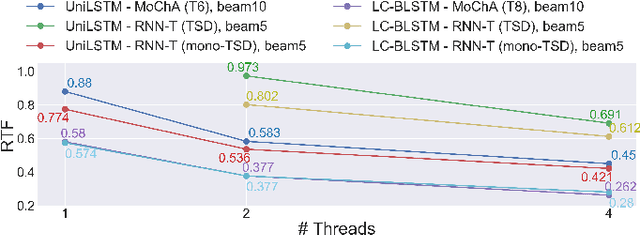
This article describes an efficient training method for online streaming attention-based encoder-decoder (AED) automatic speech recognition (ASR) systems. AED models have achieved competitive performance in offline scenarios by jointly optimizing all components. They have recently been extended to an online streaming framework via models such as monotonic chunkwise attention (MoChA). However, the elaborate attention calculation process is not robust for long-form speech utterances. Moreover, the sequence-level training objective and time-restricted streaming encoder cause a nonnegligible delay in token emission during inference. To address these problems, we propose CTC synchronous training (CTC-ST), in which CTC alignments are leveraged as a reference for token boundaries to enable a MoChA model to learn optimal monotonic input-output alignments. We formulate a purely end-to-end training objective to synchronize the boundaries of MoChA to those of CTC. The CTC model shares an encoder with the MoChA model to enhance the encoder representation. Moreover, the proposed method provides alignment information learned in the CTC branch to the attention-based decoder. Therefore, CTC-ST can be regarded as self-distillation of alignment knowledge from CTC to MoChA. Experimental evaluations on a variety of benchmark datasets show that the proposed method significantly reduces recognition errors and emission latency simultaneously, especially for long-form and noisy speech. We also compare CTC-ST with several methods that distill alignment knowledge from a hybrid ASR system and show that the CTC-ST can achieve a comparable tradeoff of accuracy and latency without relying on external alignment information. The best MoChA system shows performance comparable to that of RNN-transducer (RNN-T).
Monitoring and Diagnosability of Perception Systems
Nov 11, 2020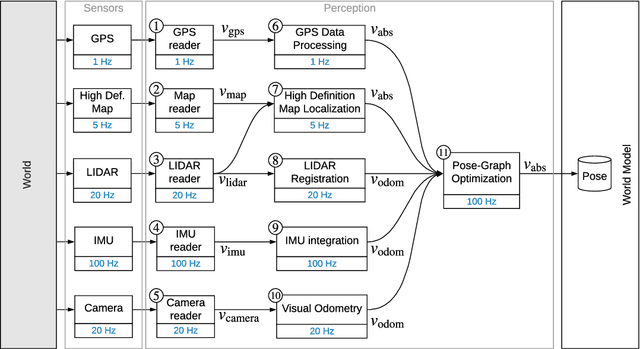
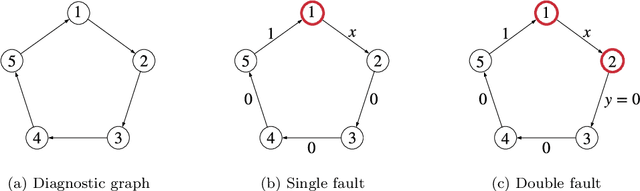
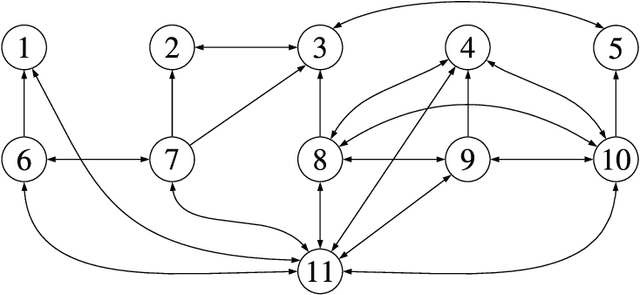
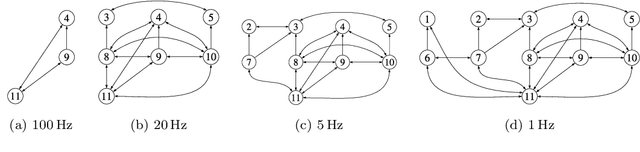
Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving vehicles. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies requires the development of methodologies to guarantee and monitor safe operation. Despite the paramount importance of perception systems, currently there is no formal approach for system-level monitoring. In this work, we propose a mathematical model for runtime monitoring and fault detection and identification in perception systems. Towards this goal, we draw connections with the literature on diagnosability in multiprocessor systems, and generalize it to account for modules with heterogeneous outputs that interact over time. The resulting temporal diagnostic graphs (i) provide a framework to reason over the consistency of perception outputs -- across modules and over time -- thus enabling fault detection, (ii) allow us to establish formal guarantees on the maximum number of faults that can be uniquely identified in a given perception systems, and (iii) enable the design of efficient algorithms for fault identification. We demonstrate our monitoring system, dubbed PerSyS, in realistic simulations using the LGSVL self-driving simulator and the Apollo Auto autonomy software stack, and show that PerSyS is able to detect failures in challenging scenarios (including scenarios that have caused self-driving car accidents in recent years), and is able to correctly identify faults while entailing a minimal computation overhead (< 5ms on a single-core CPU).