 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-Free Online Learning in Unknown Sequential Decision Making Problems and Games
Mar 08, 2021
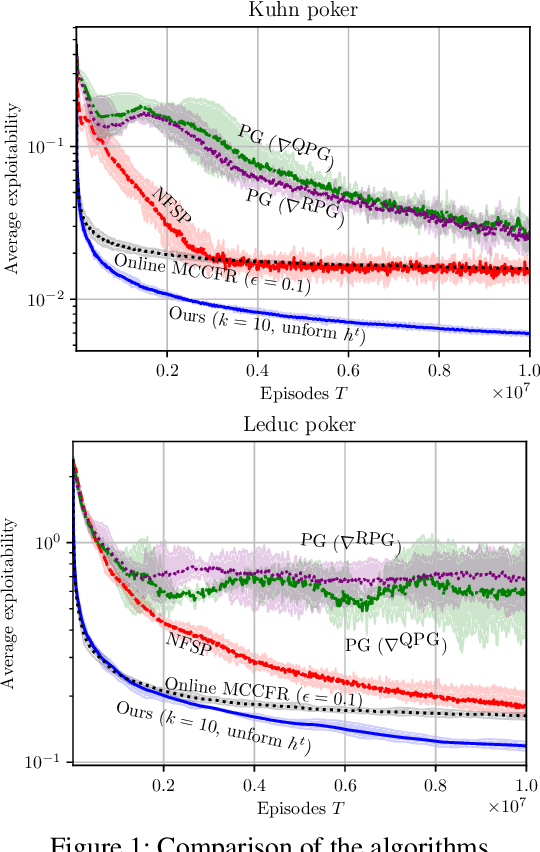

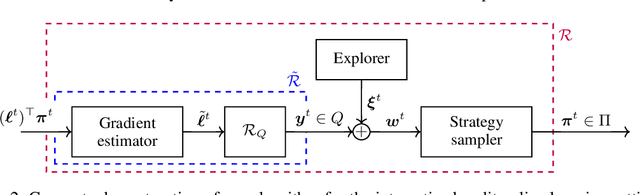
Regret minimization has proved to be a versatile tool for tree-form sequential decision making and extensive-form games. In large two-player zero-sum imperfect-information games, modern extensions of counterfactual regret minimization (CFR) are currently the practical state of the art for computing a Nash equilibrium. Most regret-minimization algorithms for tree-form sequential decision making, including CFR, require (i) an exact model of the player's decision nodes, observation nodes, and how they are linked, and (ii) full knowledge, at all times t, about the payoffs -- even in parts of the decision space that are not encountered at time t. Recently, there has been growing interest towards relaxing some of those restrictions and making regret minimization applicable to settings for which reinforcement learning methods have traditionally been used -- for example, those in which only black-box access to the environment is available. We give the first, to our knowledge, regret-minimization algorithm that guarantees sublinear regret with high probability even when requirement (i) -- and thus also (ii) -- is dropped. We formalize an online learning setting in which the strategy space is not known to the agent and gets revealed incrementally whenever the agent encounters new decision points. We give an efficient algorithm that achieves $O(T^{3/4})$ regret with high probability for that setting, even when the agent faces an adversarial environment. Our experiments show it significantly outperforms the prior algorithms for the problem, which do not have such guarantees. It can be used in any application for which regret minimization is useful: approximating Nash equilibrium or quantal response equilibrium, approximating coarse correlated equilibrium in multi-player games, learning a best response, learning safe opponent exploitation, and online play against an unknown opponent/environment.
Learning Neural Networks with Two Nonlinear Layers in Polynomial Time
Apr 20, 2018We give a polynomial-time algorithm for learning neural networks with one layer of sigmoids feeding into any Lipschitz, monotone activation function (e.g., sigmoid or ReLU). We make no assumptions on the structure of the network, and the algorithm succeeds with respect to {\em any} distribution on the unit ball in $n$ dimensions (hidden weight vectors also have unit norm). This is the first assumption-free, provably efficient algorithm for learning neural networks with two nonlinear layers. Our algorithm-- {\em Alphatron}-- is a simple, iterative update rule that combines isotonic regression with kernel methods. It outputs a hypothesis that yields efficient oracle access to interpretable features. It also suggests a new approach to Boolean learning problems via real-valued conditional-mean functions, sidestepping traditional hardness results from computational learning theory. Along these lines, we subsume and improve many longstanding results for PAC learning Boolean functions to the more general, real-valued setting of {\em probabilistic concepts}, a model that (unlike PAC learning) requires non-i.i.d. noise-tolerance.
Approximate Multiplication of Sparse Matrices with Limited Space
Sep 08, 2020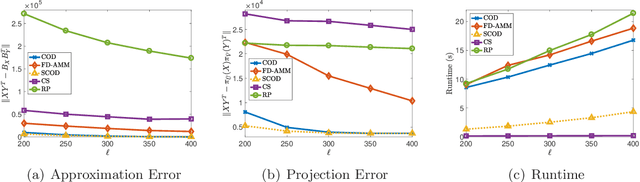
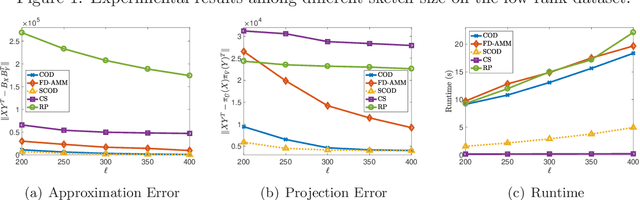
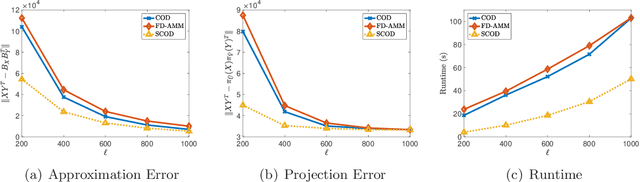
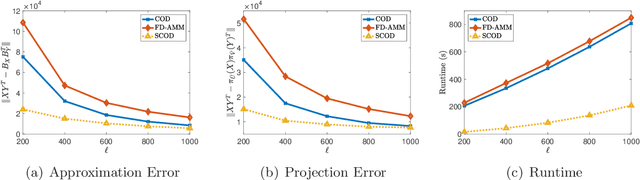
Approximate matrix multiplication with limited space has received ever-increasing attention due to the emergence of large-scale applications. Recently, based on a popular matrix sketching algorithm---frequent directions, previous work has introduced co-occuring directions (COD) to reduce the approximation error for this problem. Although it enjoys the space complexity of $O((m_x+m_y)\ell)$ for two input matrices $X\in\mathbb{R}^{m_x\times n}$ and $Y\in\mathbb{R}^{m_y\times n}$ where $\ell$ is the sketch size, its time complexity is $O\left(n(m_x+m_y+\ell)\ell\right)$, which is still very high for large input matrices. In this paper, we propose to reduce the time complexity by exploiting the sparsity of the input matrices. The key idea is to employ an approximate singular value decomposition (SVD) method which can utilize the sparsity, to reduce the number of QR decompositions required by COD. In this way, we develop sparse co-occuring directions, which reduces the time complexity to $\widetilde{O}\left((\nnz(X)+\nnz(Y))\ell+n\ell^2\right)$ in expectation while keeps the same space complexity as $O((m_x+m_y)\ell)$, where $\nnz(X)$ denotes the number of non-zero entries in $X$. Theoretical analysis reveals that the approximation error of our algorithm is almost the same as that of COD. Furthermore, we empirically verify the efficiency and effectiveness of our algorithm.
On Theory-training Neural Networks to Infer the Solution of Highly Coupled Differential Equations
Feb 10, 2021
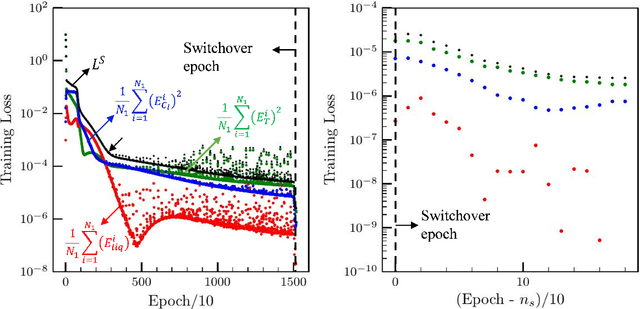
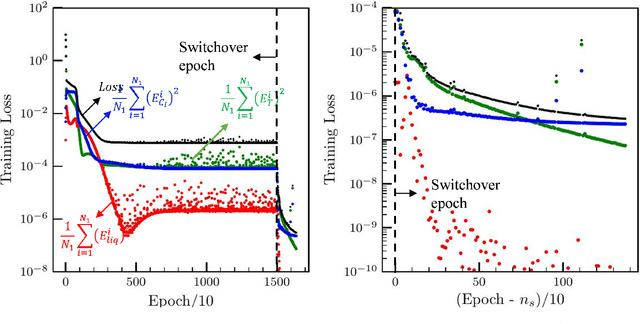
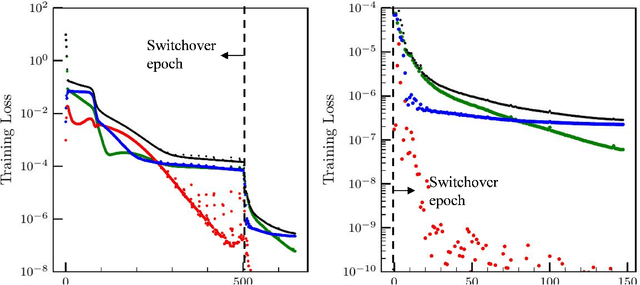
Deep neural networks are transforming fields ranging from computer vision to computational medicine, and we recently extended their application to the field of phase-change heat transfer by introducing theory-trained neural networks (TTNs) for a solidification problem \cite{TTN}. Here, we present general, in-depth, and empirical insights into theory-training networks for learning the solution of highly coupled differential equations. We analyze the deteriorating effects of the oscillating loss on the ability of a network to satisfy the equations at the training data points, measured by the final training loss, and on the accuracy of the inferred solution. We introduce a theory-training technique that, by leveraging regularization, eliminates those oscillations, decreases the final training loss, and improves the accuracy of the inferred solution, with no additional computational cost. Then, we present guidelines that allow a systematic search for the network that has the optimal training time and inference accuracy for a given set of equations; following these guidelines can reduce the number of tedious training iterations in that search. Finally, a comparison between theory-training and the rival, conventional method of solving differential equations using discretization attests to the advantages of theory-training not being necessarily limited to high-dimensional sets of equations. The comparison also reveals a limitation of the current theory-training framework that may limit its application in domains where extreme accuracies are necessary.
Deep Learning for Real-time Gravitational Wave Detection and Parameter Estimation: Results with Advanced LIGO Data
Nov 08, 2017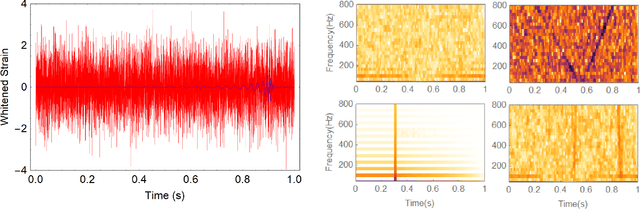
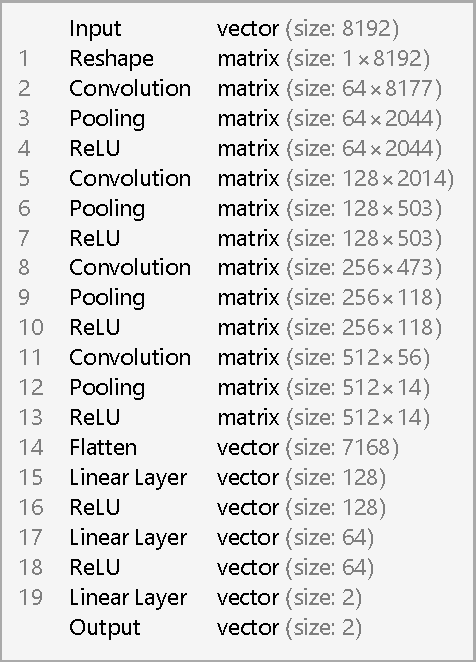
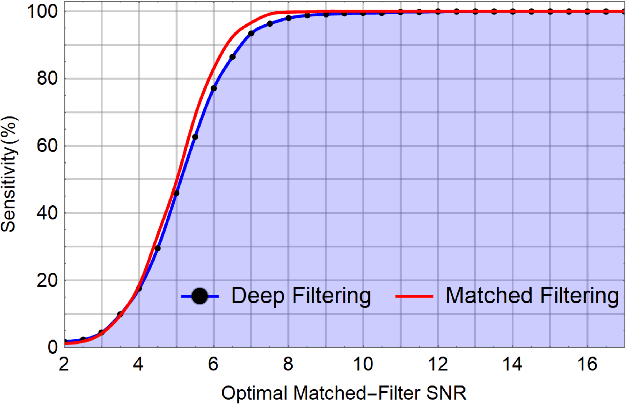
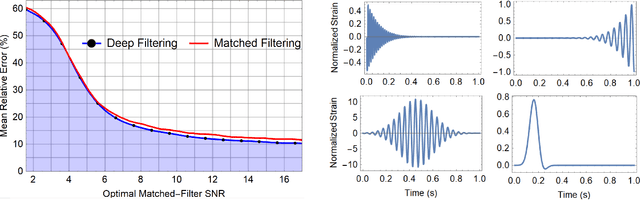
The recent Nobel-prize-winning detections of gravitational waves from merging black holes and the subsequent detection of the collision of two neutron stars in coincidence with electromagnetic observations have inaugurated a new era of multimessenger astrophysics. To enhance the scope of this emergent field of science, we pioneered the use of deep learning with convolutional neural networks, that take time-series inputs, for rapid detection and characterization of gravitational wave signals. This approach, Deep Filtering, was initially demonstrated using simulated LIGO noise. In this article, we present the extension of Deep Filtering using real data from LIGO, for both detection and parameter estimation of gravitational waves from binary black hole mergers using continuous data streams from multiple LIGO detectors. We demonstrate for the first time that machine learning can detect and estimate the true parameters of real events observed by LIGO. Our results show that Deep Filtering achieves similar sensitivities and lower errors compared to matched-filtering while being far more computationally efficient and more resilient to glitches, allowing real-time processing of weak time-series signals in non-stationary non-Gaussian noise with minimal resources, and also enables the detection of new classes of gravitational wave sources that may go unnoticed with existing detection algorithms. This unified framework for data analysis is ideally suited to enable coincident detection campaigns of gravitational waves and their multimessenger counterparts in real-time.
* 6 pages, 7 figures; First application of deep learning to real LIGO events; Includes direct comparison against matched-filtering
Towards Social & Engaging Peer Learning: Predicting Backchanneling and Disengagement in Children
Jul 22, 2020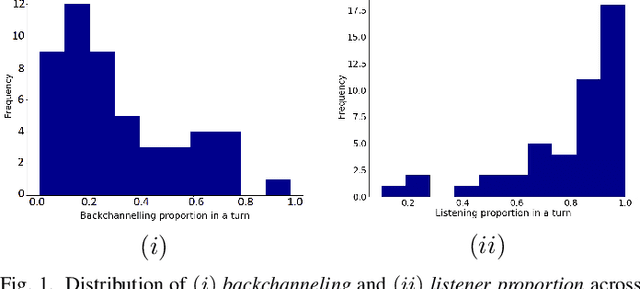
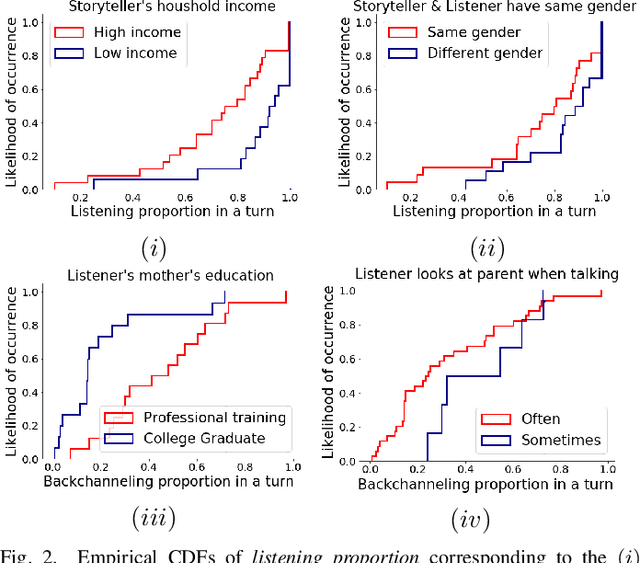

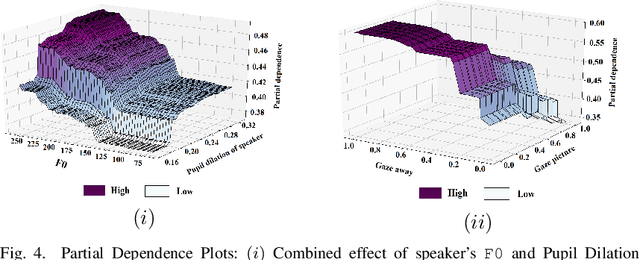
Social robots and interactive computer applications have the potential to foster early language development in young children by acting as peer learning companions. However, studies have found that children only trust robots which behave in a natural and interpersonal manner. To help robots come across as engaging and attentive peer learning companions, we develop models to predict whether the listener will lose attention (Listener Disengagement Prediction, LDP) and the extent to which a robot should generate backchanneling responses (Backchanneling Extent Prediction, BEP) in the next few seconds. We pose LDP and BEP as time series classification problems and conduct several experiments to assess the impact of different time series characteristics and feature sets on the predictive performance of our model. Using statistics & machine learning, we also examine which socio-demographic factors influence the amount of time children spend backchanneling and listening to their peers. To lend interpretability to our models, we also analyzed critical features responsible for their predictive performance. Our experiments revealed the utility of multimodal features such as pupil dilation, blink rate, head movements, facial action units which have never been used before. We also found that the dynamics of time series features are rich predictors of listener disengagement and backchanneling.
Compressed Sensing for STM imaging of defects and disorder
Jan 15, 2021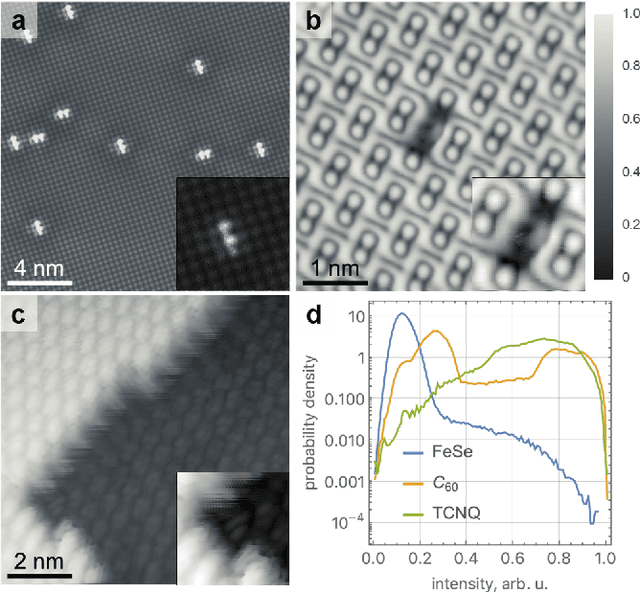
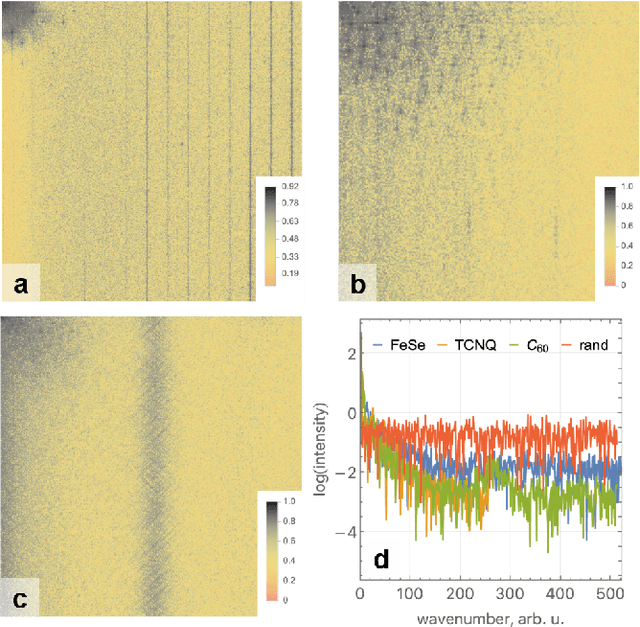


Compressed sensing (CS) is a valuable technique for reconstructing measurements in numerous domains. CS has not yet gained widespread adoption in scanning tunneling microscopy (STM), despite potentially offering the advantages of lower acquisition time and enhanced tolerance to noise. Here we applied a simple CS framework, using a weighted iterative thresholding algorithm for CS reconstruction, to representative high-resolution STM images of superconducting surfaces and adsorbed molecules. We calculated reconstruction diagrams for a range of scanning patterns, sampling densities, and noise intensities, evaluating reconstruction quality for the whole image and chosen defects. Overall we find that typical STM images can be satisfactorily reconstructed down to 30\% sampling - already a strong improvement. We furthermore outline limitations of this method, such as sampling pattern artifacts, which become particularly pronounced for images with intrinsic long-range disorder, and propose ways to mitigate some of them. Finally we investigate compressibility of STM images as a measure of intrinsic noise in the image and a precursor to CS reconstruction, enabling a priori estimation of the effectiveness of CS reconstruction with minimal computational cost.
Are Adaptive Face Recognition Systems still Necessary? Experiments on the APE Dataset
Oct 08, 2020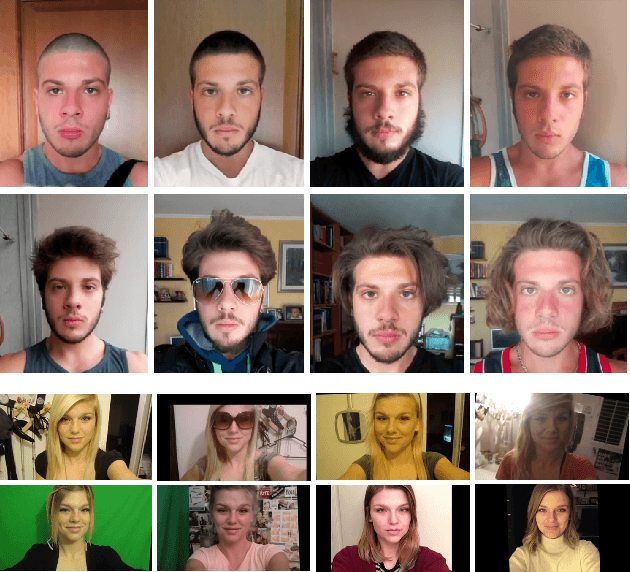

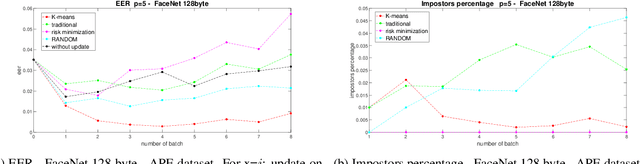
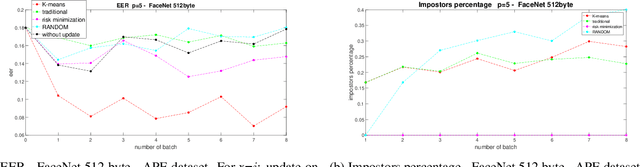
In the last five years, deep learning methods, in particular CNN, have attracted considerable attention in the field of face-based recognition, achieving impressive results. Despite this progress, it is not yet clear precisely to what extent deep features are able to follow all the intra-class variations that the face can present over time. In this paper we investigate the performance the performance improvement of face recognition systems by adopting self updating strategies of the face templates. For that purpose, we evaluate the performance of a well-known deep-learning face representation, namely, FaceNet, on a dataset that we generated explicitly conceived to embed intra-class variations of users on a large time span of captures: the APhotoEveryday (APE) dataset. Moreover, we compare these deep features with handcrafted features extracted using the BSIF algorithm. In both cases, we evaluate various template update strategies, in order to detect the most useful for such kind of features. Experimental results show the effectiveness of "optimized" self-update methods with respect to systems without update or random selection of templates.
Face Recognition using 3D CNNs
Feb 02, 2021

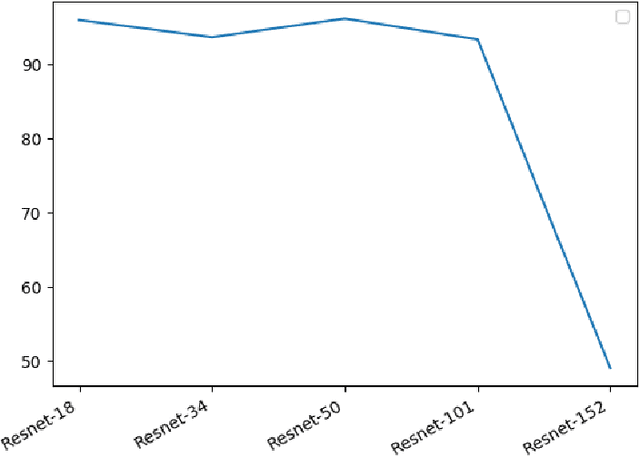
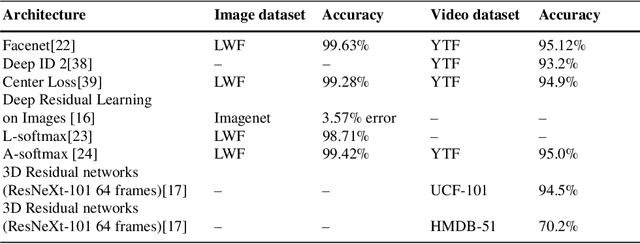
The area of face recognition is one of the most widely researched areas in the domain of computer vision and biometric. This is because, the non-intrusive nature of face biometric makes it comparatively more suitable for application in area of surveillance at public places such as airports. The application of primitive methods in face recognition could not give very satisfactory performance. However, with the advent of machine and deep learning methods and their application in face recognition, several major breakthroughs were obtained. The use of 2D Convolution Neural networks(2D CNN) in face recognition crossed the human face recognition accuracy and reached to 99%. Still, robust face recognition in the presence of real world conditions such as variation in resolution, illumination and pose is a major challenge for researchers in face recognition. In this work, we used video as input to the 3D CNN architectures for capturing both spatial and time domain information from the video for face recognition in real world environment. For the purpose of experimentation, we have developed our own video dataset called CVBL video dataset. The use of 3D CNN for face recognition in videos shows promising results with DenseNets performing the best with an accuracy of 97% on CVBL dataset.
Expertise and confidence explain how social influence evolves along intellective tasks
Nov 13, 2020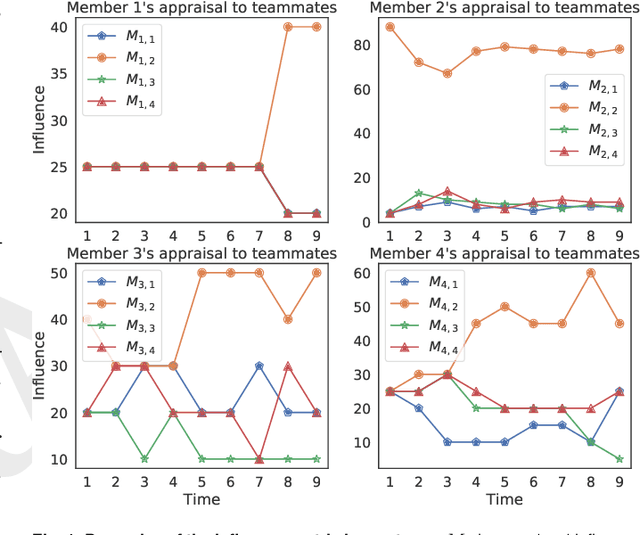
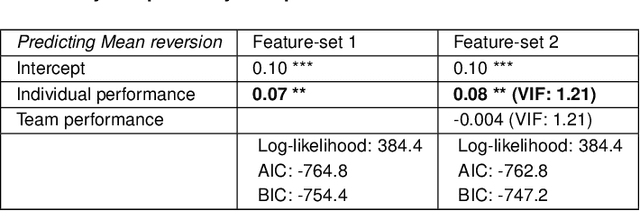
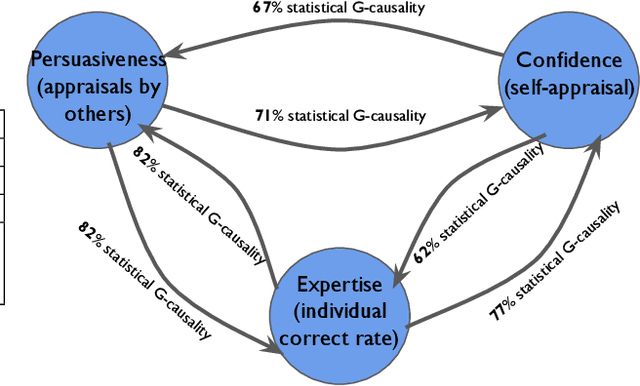

Discovering the antecedents of individuals' influence in collaborative environments is an important, practical, and challenging problem. In this paper, we study interpersonal influence in small groups of individuals who collectively execute a sequence of intellective tasks. We observe that along an issue sequence with feedback, individuals with higher expertise and social confidence are accorded higher interpersonal influence. We also observe that low-performing individuals tend to underestimate their high-performing teammate's expertise. Based on these observations, we introduce three hypotheses and present empirical and theoretical support for their validity. We report empirical evidence on longstanding theories of transactive memory systems, social comparison, and confidence heuristics on the origins of social influence. We propose a cognitive dynamical model inspired by these theories to describe the process by which individuals adjust interpersonal influences over time. We demonstrate the model's accuracy in predicting individuals' influence and provide analytical results on its asymptotic behavior for the case with identically performing individuals. Lastly, we propose a novel approach using deep neural networks on a pre-trained text embedding model for predicting the influence of individuals. Using message contents, message times, and individual correctness collected during tasks, we are able to accurately predict individuals' self-reported influence over time. Extensive experiments verify the accuracy of the proposed models compared to baselines such as structural balance and reflected appraisal model. While the neural networks model is the most accurate, the dynamical model is the most interpretable for influence prediction.