 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Localization of Cochlear Implant Electrodes from Cone Beam Computed Tomography using Particle Belief Propagation
Mar 18, 2021

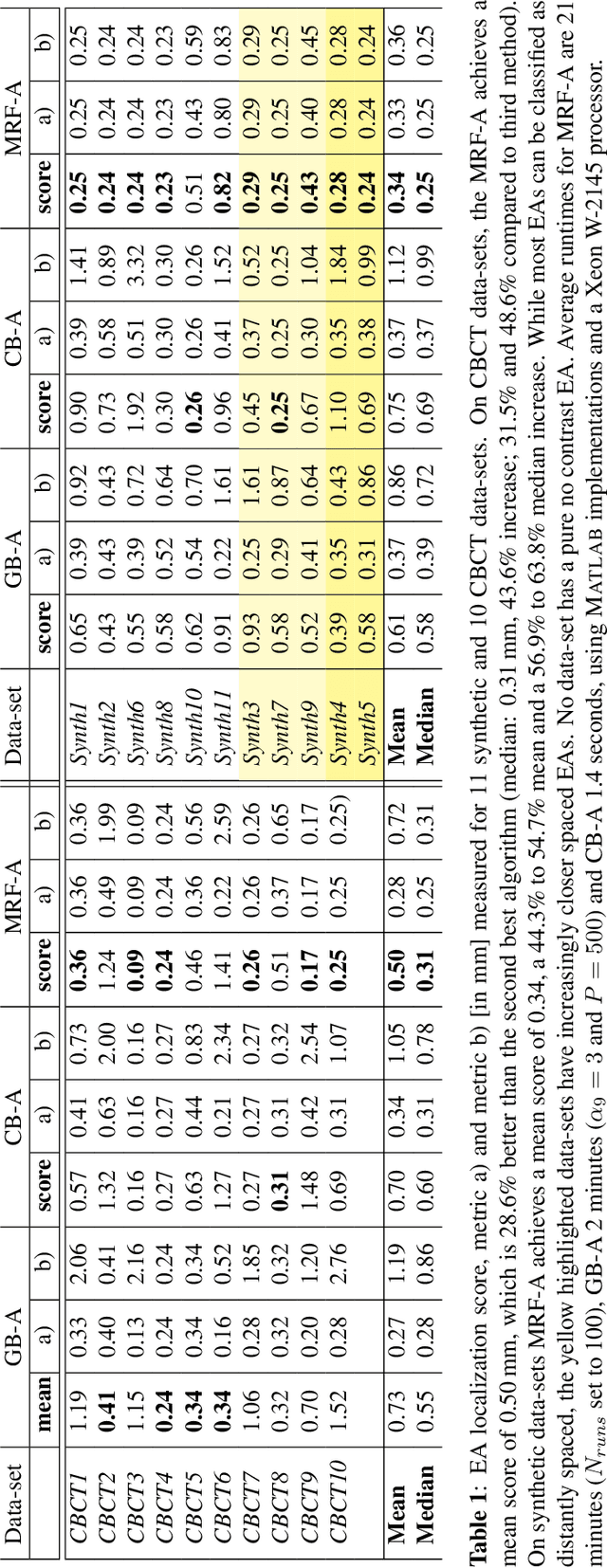
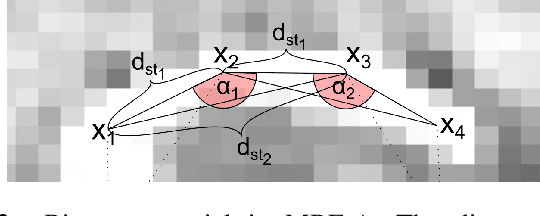
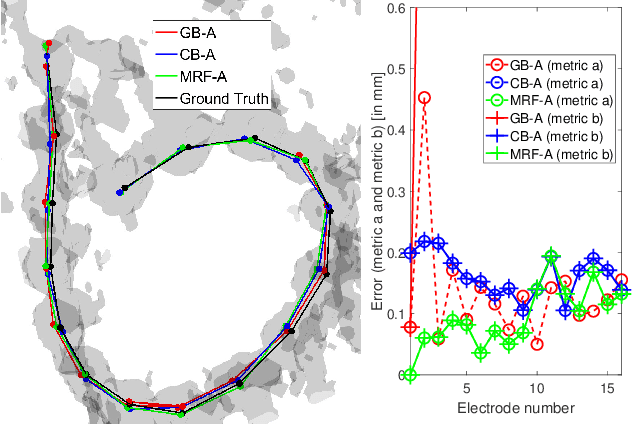
Cochlear implants (CIs) are implantable medical devices that can restore the hearing sense of people suffering from profound hearing loss. The CI uses a set of electrode contacts placed inside the cochlea to stimulate the auditory nerve with current pulses. The exact location of these electrodes may be an important parameter to improve and predict the performance with these devices. Currently the methods used in clinics to characterize the geometry of the cochlea as well as to estimate the electrode positions are manual, error-prone and time consuming. We propose a Markov random field (MRF) model for CI electrode localization for cone beam computed tomography (CBCT) data-sets. Intensity and shape of electrodes are included as prior knowledge as well as distance and angles between contacts. MRF inference is based on slice sampling particle belief propagation and guided by several heuristics. A stochastic search finds the best maximum a posteriori estimation among sampled MRF realizations. We evaluate our algorithm on synthetic and real CBCT data-sets and compare its performance with two state of the art algorithms. An increase of localization precision up to 31.5% (mean), or 48.6% (median) respectively, on real CBCT data-sets is shown.
Multi-Group Multicast Beamforming by Superiorized Projections onto Convex Sets
Feb 23, 2021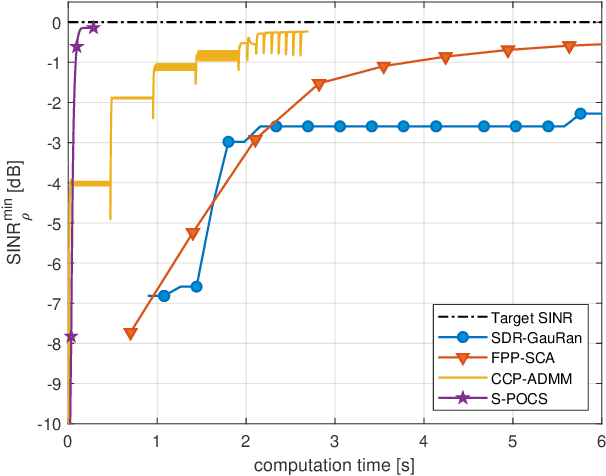
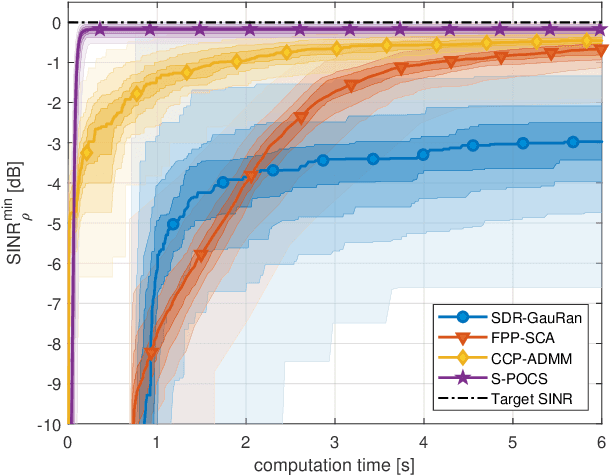
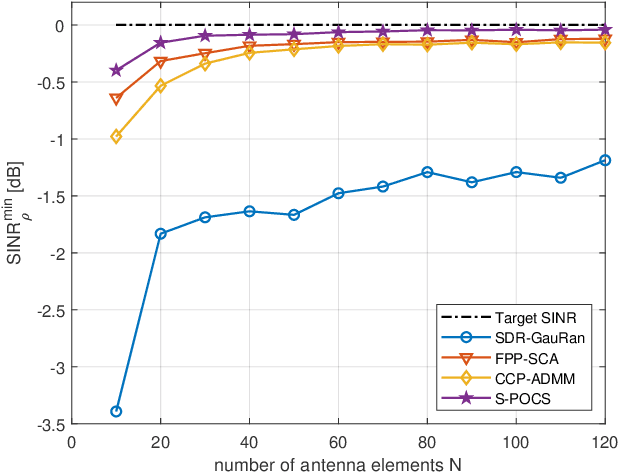
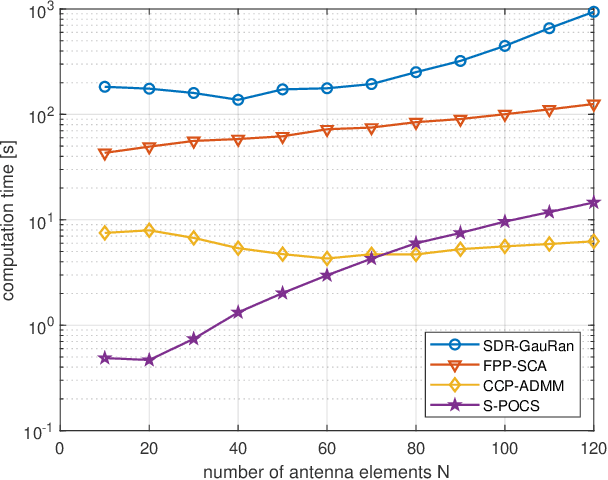
In this paper, we propose an iterative algorithm to address the nonconvex multi-group multicast beamforming problem with quality-of-service constraints and per-antenna power constraints. We formulate a convex relaxation of the problem as a semidefinite program in a real Hilbert space, which allows us to approximate a point in the feasible set by iteratively applying a bounded perturbation resilient fixed-point mapping. Inspired by the superiorization methodology, we use this mapping as a basic algorithm, and we add in each iteration a small perturbation with the intent to reduce the objective value and the distance to nonconvex rank-constraint sets. We prove that the sequence of perturbations is bounded, so the algorithm is guaranteed to converge to a feasible point of the relaxed semidefinite program. Simulations show that the proposed approach outperforms existing algorithms in terms of both computation time and approximation gap in many cases.
Hardness of Learning Halfspaces with Massart Noise
Dec 17, 2020
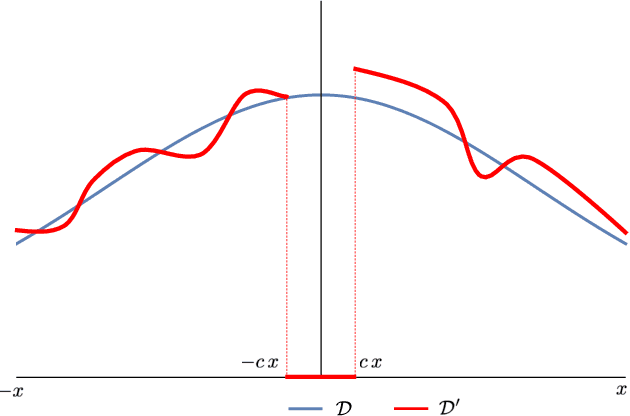
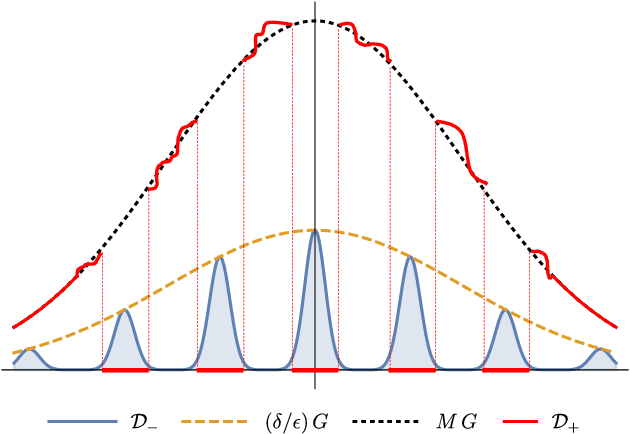
We study the complexity of PAC learning halfspaces in the presence of Massart (bounded) noise. Specifically, given labeled examples $(x, y)$ from a distribution $D$ on $\mathbb{R}^{n} \times \{ \pm 1\}$ such that the marginal distribution on $x$ is arbitrary and the labels are generated by an unknown halfspace corrupted with Massart noise at rate $\eta<1/2$, we want to compute a hypothesis with small misclassification error. Characterizing the efficient learnability of halfspaces in the Massart model has remained a longstanding open problem in learning theory. Recent work gave a polynomial-time learning algorithm for this problem with error $\eta+\epsilon$. This error upper bound can be far from the information-theoretically optimal bound of $\mathrm{OPT}+\epsilon$. More recent work showed that {\em exact learning}, i.e., achieving error $\mathrm{OPT}+\epsilon$, is hard in the Statistical Query (SQ) model. In this work, we show that there is an exponential gap between the information-theoretically optimal error and the best error that can be achieved by a polynomial-time SQ algorithm. In particular, our lower bound implies that no efficient SQ algorithm can approximate the optimal error within any polynomial factor.
"It's Unwieldy and It Takes a Lot of Time." Challenges and Opportunities for Creating Agents in Commercial Games
Sep 01, 2020
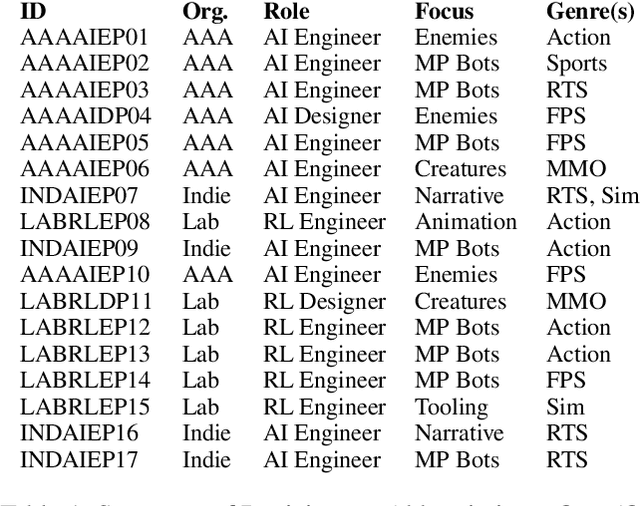

Game agents such as opponents, non-player characters, and teammates are central to player experiences in many modern games. As the landscape of AI techniques used in the games industry evolves to adopt machine learning (ML) more widely, it is vital that the research community learn from the best practices cultivated within the industry over decades creating agents. However, although commercial game agent creation pipelines are more mature than those based on ML, opportunities for improvement still abound. As a foundation for shared progress identifying research opportunities between researchers and practitioners, we interviewed seventeen game agent creators from AAA studios, indie studios, and industrial research labs about the challenges they experienced with their professional workflows. Our study revealed several open challenges ranging from design to implementation and evaluation. We compare with literature from the research community that address the challenges identified and conclude by highlighting promising directions for future research supporting agent creation in the games industry.
A Methodology for Approaching the Integration of Complex Robotics Systems Illustrated through a Bi-manual Manipulation Case-Study
Mar 18, 2021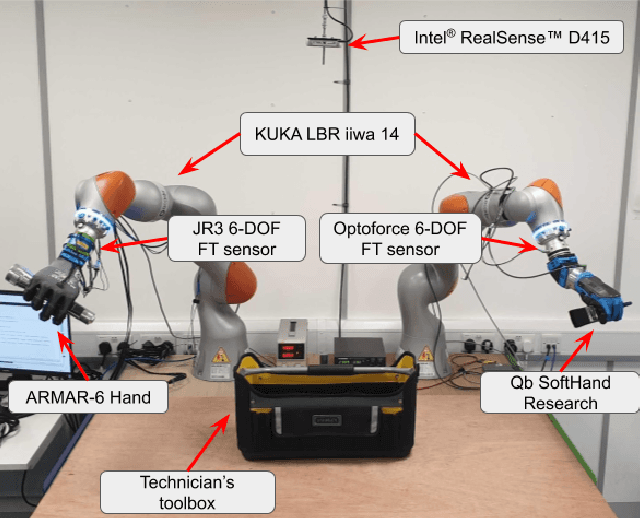
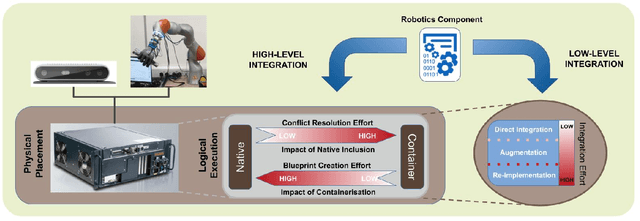
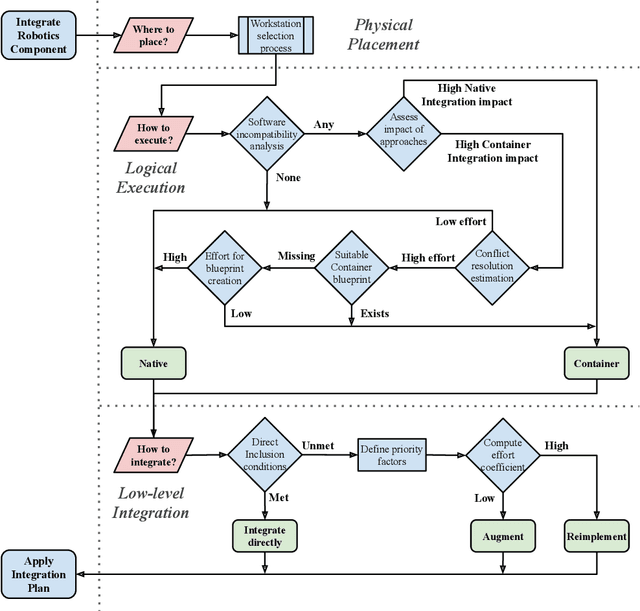

The multidisciplinarity of robotics creates a need for robust integration methodologies that can facilitate the adoption of state-of-the-art research components in an industrial application. Unfortunately, there are no clear, community accepted guidelines or standards that define the integration of such components in a single robotic system. In this paper, we propose a methodology that assesses the software components of a candidate system on the basis of the effort required to integrate them and the impact their integration will have on a target system. We demonstrate how this methodology can be applied using an industrial tool packing system as an example. The system integrates a wide range of both in-house and third-party research outputs and software components. We prove the effectiveness of our approach by evaluating system performance with an experimental benchmark that assesses the robustness, reliability and operational speed of the system for the given packing task. We also demonstrate how our methodology can be used to predict the amount of integration time required for a component. The proposed integration methodology can be applied to any robotic system to facilitate its transition from the research to an industrial environment.
Reduced Precision Strategies for Deep Learning: A High Energy Physics Generative Adversarial Network Use Case
Mar 18, 2021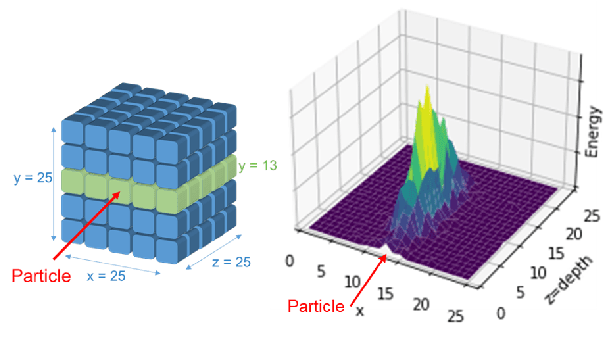
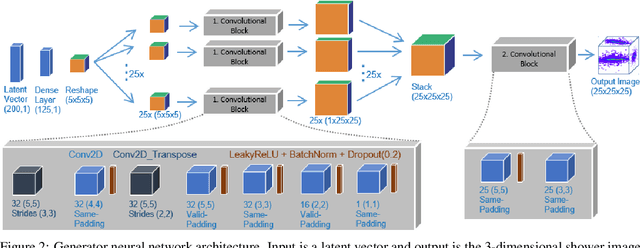

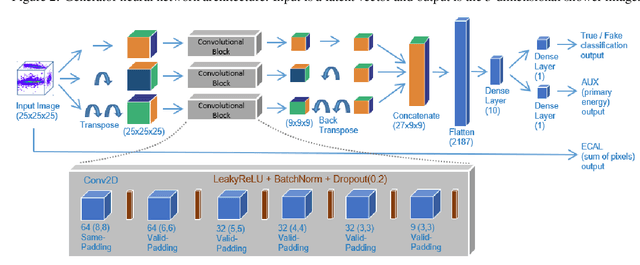
Deep learning is finding its way into high energy physics by replacing traditional Monte Carlo simulations. However, deep learning still requires an excessive amount of computational resources. A promising approach to make deep learning more efficient is to quantize the parameters of the neural networks to reduced precision. Reduced precision computing is extensively used in modern deep learning and results to lower execution inference time, smaller memory footprint and less memory bandwidth. In this paper we analyse the effects of low precision inference on a complex deep generative adversarial network model. The use case which we are addressing is calorimeter detector simulations of subatomic particle interactions in accelerator based high energy physics. We employ the novel Intel low precision optimization tool (iLoT) for quantization and compare the results to the quantized model from TensorFlow Lite. In the performance benchmark we gain a speed-up of 1.73x on Intel hardware for the quantized iLoT model compared to the initial, not quantized, model. With different physics-inspired self-developed metrics, we validate that the quantized iLoT model shows a lower loss of physical accuracy in comparison to the TensorFlow Lite model.
* Submitted at ICPRAM 2021; from CERN openlab - Intel collaboration
A matrix approach to detect temporal behavioral patterns at electric vehicle charging stations
Feb 18, 2021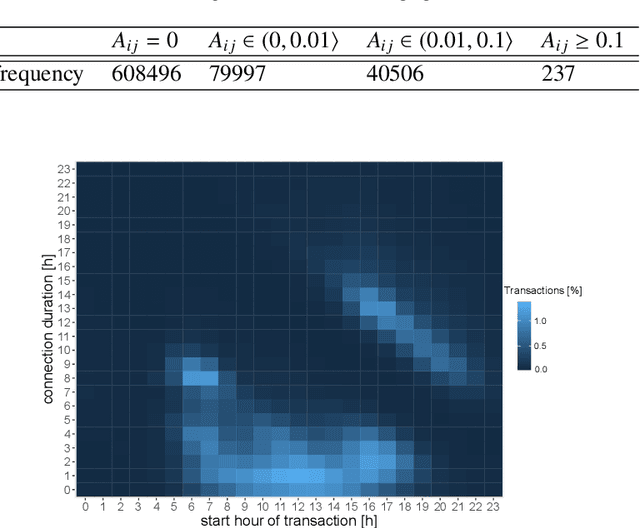
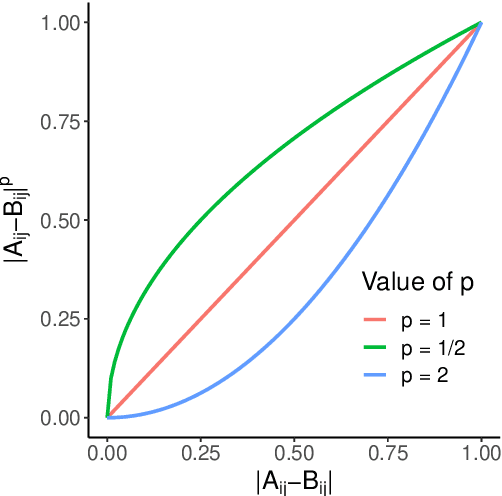
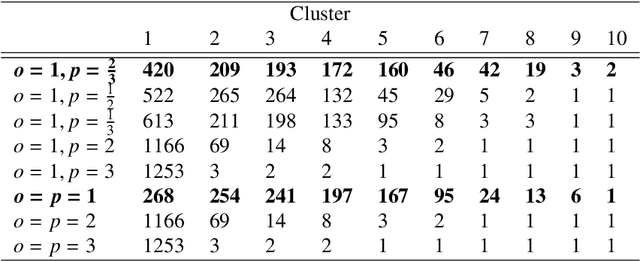
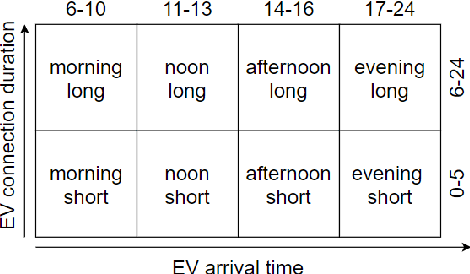
Based on the electric vehicle (EV) arrival times and the duration of EV connection to the charging station, we identify charging patterns and derive groups of charging stations with similar charging patterns applying two approaches. The ruled based approach derives the charging patterns by specifying a set of time intervals and a threshold value. In the second approach, we combine the modified l-p norm (as a matrix dissimilarity measure) with hierarchical clustering and apply them to automatically identify charging patterns and groups of charging stations associated with such patterns. A dataset collected in a large network of public charging stations is used to test both approaches. Using both methods, we derived charging patterns. The first, rule-based approach, performed well at deriving predefined patterns and the latter, hierarchical clustering, showed the capability of delivering unexpected charging patterns.
Just a Momentum: Analytical Study of Momentum-Based Acceleration Methods Methods in Paradigmatic High-Dimensional Non-Convex Problem
Feb 23, 2021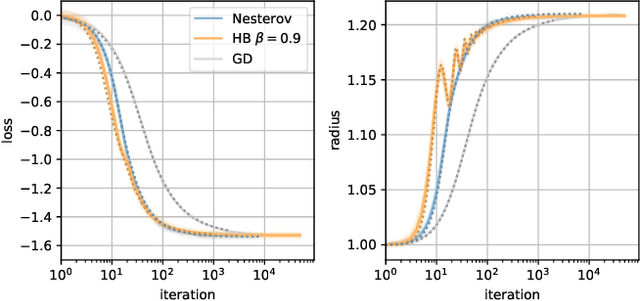
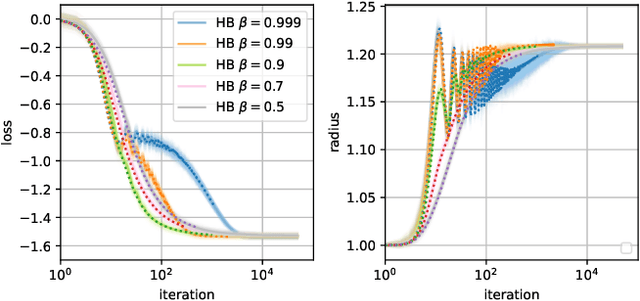
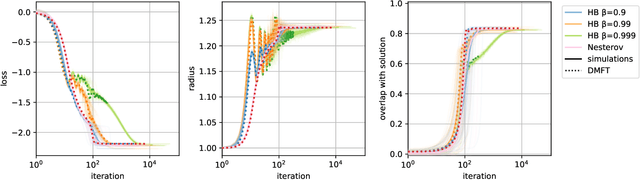

When optimizing over loss functions it is common practice to use momentum-based accelerated methods rather than vanilla gradient-based method. Despite widely applied to arbitrary loss function, their behaviour in generically non-convex, high dimensional landscapes is poorly understood. In this work we used dynamical mean field theory techniques to describe analytically the average behaviour of these methods in a prototypical non-convex model: the (spiked) matrix-tensor model. We derive a closed set of equations that describe the behaviours of several algorithms including heavy-ball momentum and Nesterov acceleration. Additionally we characterize the evolution of a mathematically equivalent physical system of massive particles relaxing toward the bottom of an energetic landscape. Under the correct mapping the two dynamics are equivalent and it can be noticed that having a large mass increases the effective time step of the heavy ball dynamics leading to a speed up.
Neuromechanics-based Deep Reinforcement Learning of Neurostimulation Control in FES cycling
Apr 02, 2021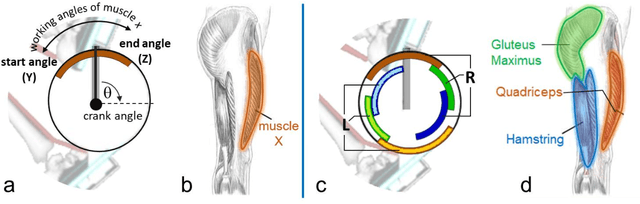
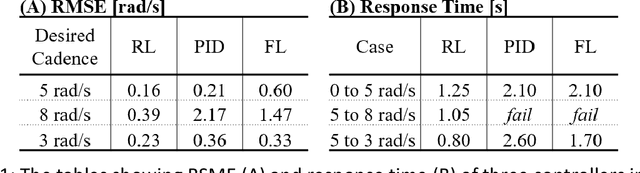
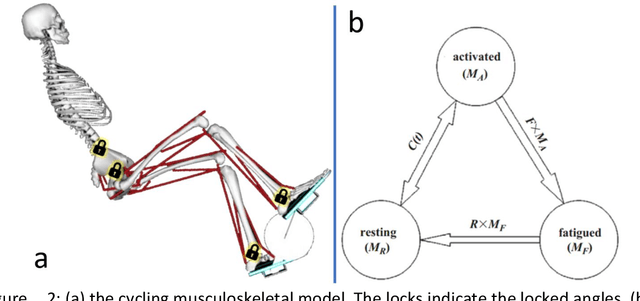
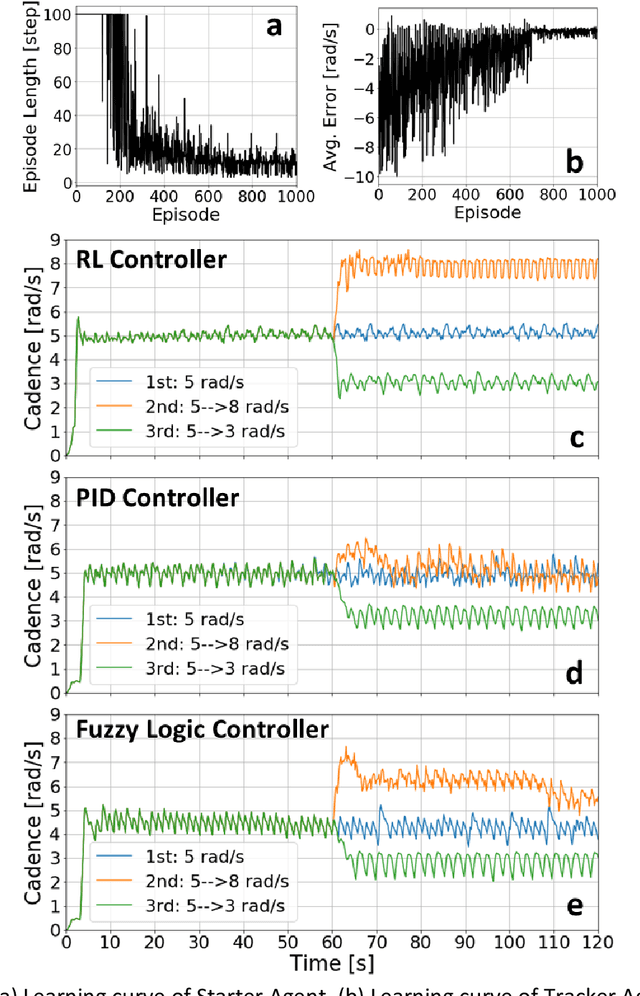
Functional Electrical Stimulation (FES) can restore motion to a paralysed person's muscles. Yet, control stimulating many muscles to restore the practical function of entire limbs is an unsolved problem. Current neurostimulation engineering still relies on 20th Century control approaches and correspondingly shows only modest results that require daily tinkering to operate at all. Here, we present our state of the art Deep Reinforcement Learning (RL) developed for real time adaptive neurostimulation of paralysed legs for FES cycling. Core to our approach is the integration of a personalised neuromechanical component into our reinforcement learning framework that allows us to train the model efficiently without demanding extended training sessions with the patient and working out of the box. Our neuromechanical component includes merges musculoskeletal models of muscle and or tendon function and a multistate model of muscle fatigue, to render the neurostimulation responsive to a paraplegic's cyclist instantaneous muscle capacity. Our RL approach outperforms PID and Fuzzy Logic controllers in accuracy and performance. Crucially, our system learned to stimulate a cyclist's legs from ramping up speed at the start to maintaining a high cadence in steady state racing as the muscles fatigue. A part of our RL neurostimulation system has been successfully deployed at the Cybathlon 2020 bionic Olympics in the FES discipline with our paraplegic cyclist winning the Silver medal among 9 competing teams.
Real-Time Automatic Fetal Brain Extraction in Fetal MRI by Deep Learning
Oct 25, 2017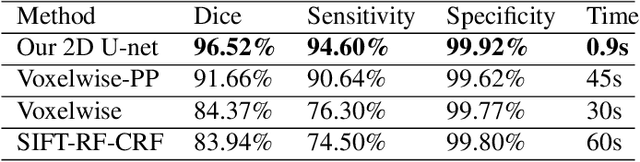


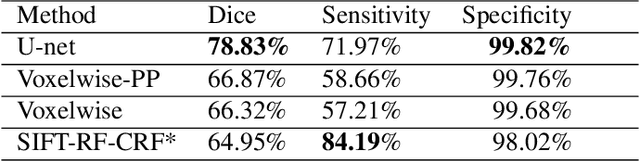
Brain segmentation is a fundamental first step in neuroimage analysis. In the case of fetal MRI, it is particularly challenging and important due to the arbitrary orientation of the fetus, organs that surround the fetal head, and intermittent fetal motion. Several promising methods have been proposed but are limited in their performance in challenging cases and in real-time segmentation. We aimed to develop a fully automatic segmentation method that independently segments sections of the fetal brain in 2D fetal MRI slices in real-time. To this end, we developed and evaluated a deep fully convolutional neural network based on 2D U-net and autocontext, and compared it to two alternative fast methods based on 1) a voxelwise fully convolutional network and 2) a method based on SIFT features, random forest and conditional random field. We trained the networks with manual brain masks on 250 stacks of training images, and tested on 17 stacks of normal fetal brain images as well as 18 stacks of extremely challenging cases based on extreme motion, noise, and severely abnormal brain shape. Experimental results show that our U-net approach outperformed the other methods and achieved average Dice metrics of 96.52% and 78.83% in the normal and challenging test sets, respectively. With an unprecedented performance and a test run time of about 1 second, our network can be used to segment the fetal brain in real-time while fetal MRI slices are being acquired. This can enable real-time motion tracking, motion detection, and 3D reconstruction of fetal brain MRI.