 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021
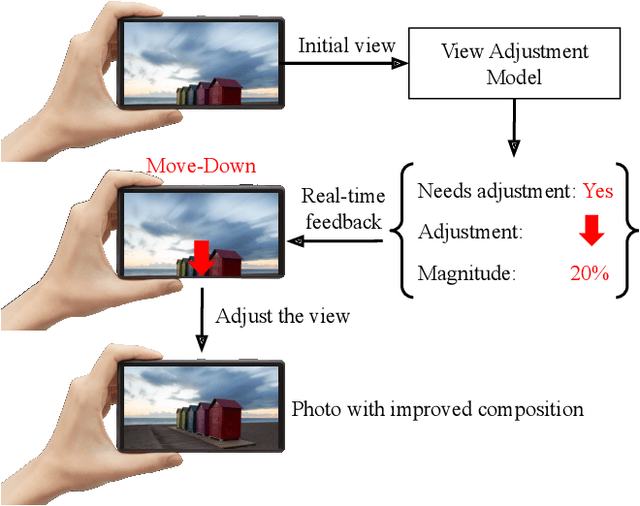
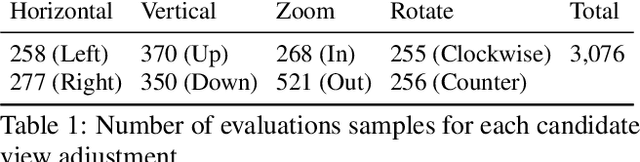


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.
Learning Maximum-A-Posteriori Perturbation Models for Structured Prediction in Polynomial Time
May 21, 2018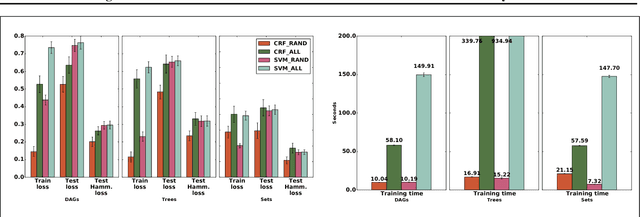
MAP perturbation models have emerged as a powerful framework for inference in structured prediction. Such models provide a way to efficiently sample from the Gibbs distribution and facilitate predictions that are robust to random noise. In this paper, we propose a provably polynomial time randomized algorithm for learning the parameters of perturbed MAP predictors. Our approach is based on minimizing a novel Rademacher-based generalization bound on the expected loss of a perturbed MAP predictor, which can be computed in polynomial time. We obtain conditions under which our randomized learning algorithm can guarantee generalization to unseen examples.
LMNet: Real-time Multiclass Object Detection on CPU using 3D LiDAR
May 18, 2018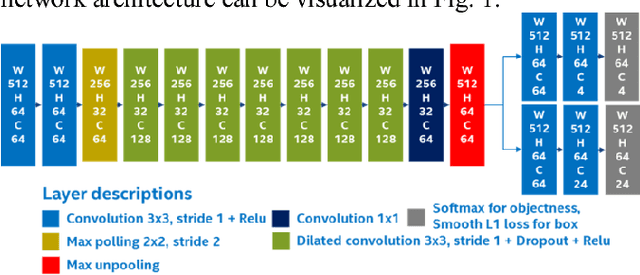


This paper describes an optimized single-stage deep convolutional neural network to detect objects in urban environments, using nothing more than point cloud data. This feature enables our method to work regardless the time of the day and the lighting conditions.The proposed network structure employs dilated convolutions to gradually increase the perceptive field as depth increases, this helps to reduce the computation time by about 30%. The network input consists of five perspective representations of the unorganized point cloud data. The network outputs an objectness map and the bounding box offset values for each point. Our experiments showed that using reflection, range, and the position on each of the three axes helped to improve the location and orientation of the output bounding box. We carried out quantitative evaluations with the help of the KITTI dataset evaluation server. It achieved the fastest processing speed among the other contenders, making it suitable for real-time applications. We implemented and tested it on a real vehicle with a Velodyne HDL-64 mounted on top of it. We achieved execution times as fast as 50 FPS using desktop GPUs, and up to 10 FPS on a single Intel Core i5 CPU. The deploy implementation is open-sourced and it can be found as a feature branch inside the autonomous driving framework Autoware. Code is available at: https://github.com/CPFL/Autoware/tree/feature/cnn_lidar_detection
Robust partial Fourier reconstruction for diffusion-weighted imaging using a recurrent convolutional neural network
May 19, 2021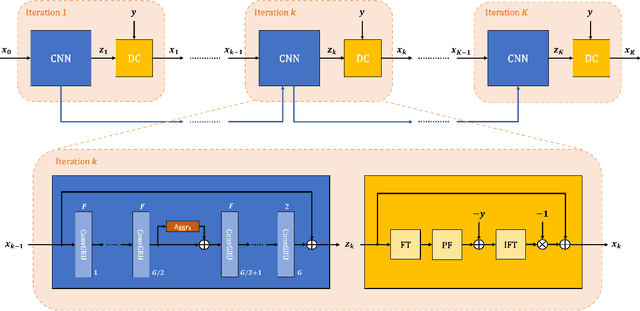
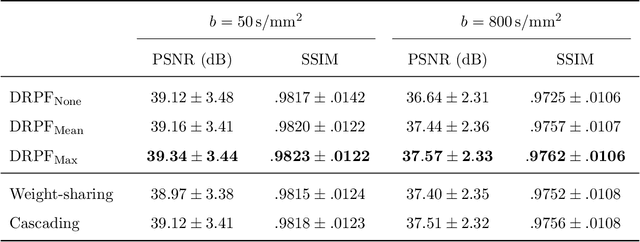
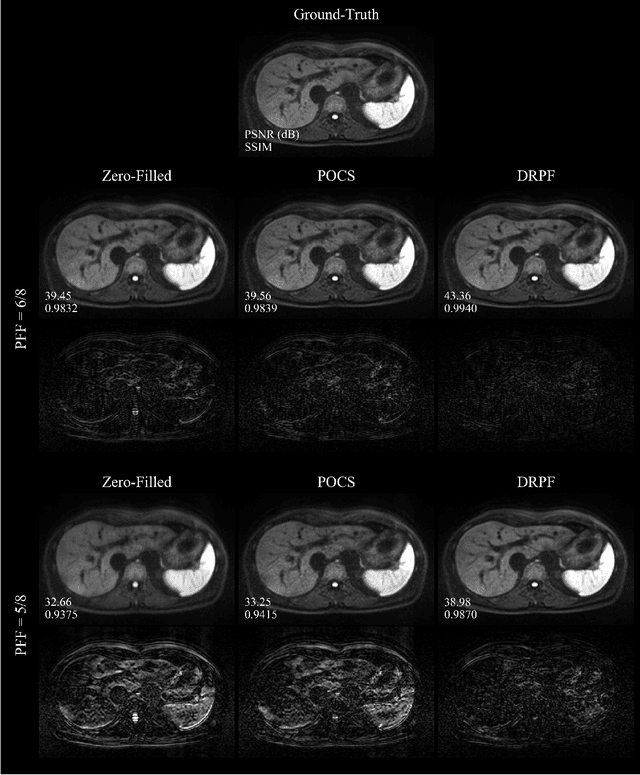
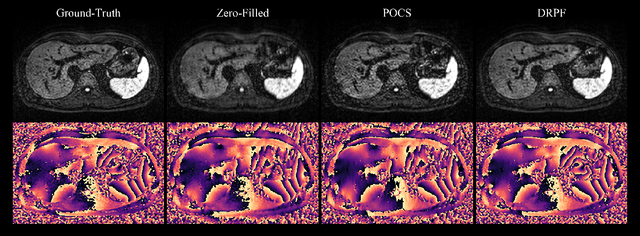
Purpose: To develop an algorithm for robust partial Fourier (PF) reconstruction applicable to diffusion-weighted (DW) images with non-smooth phase variations. Methods: Based on an unrolled proximal splitting algorithm, a neural network architecture is derived which alternates between data consistency operations and regularization implemented by recurrent convolutions. In order to exploit correlations, multiple repetitions of the same slice are jointly reconstructed under consideration of permutation-equivariance. The proposed method is trained on DW liver data of 60 volunteers and evaluated on retrospectively and prospectively sub-sampled data of different anatomies and resolutions. In addition, the benefits of using a recurrent network over other unrolling strategies is investigated. Results: Conventional PF techniques can be significantly outperformed in terms of quantitative measures as well as perceptual image quality. The proposed method is able to generalize well to brain data with contrasts and resolution not present in the training set. The reduction in echo time (TE) associated with prospective PF-sampling enables DW imaging with higher signal. Also, the TE increase in acquisitions with higher resolution can be compensated for. It can be shown that unrolling by means of a recurrent network produced better results than using a weight-shared network or a cascade of networks. Conclusion: This work demonstrates that robust PF reconstruction of DW data is feasible even at strong PF factors in applications with severe phase variations. Since the proposed method does not rely on smoothness priors of the phase but uses learned recurrent convolutions instead, artifacts of conventional PF methods can be avoided.
Manifold Optimization for High Accuracy Spatial Location Estimation Using Ultrasound Waves
Mar 28, 2021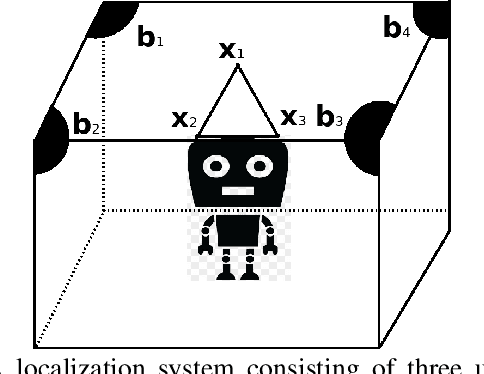
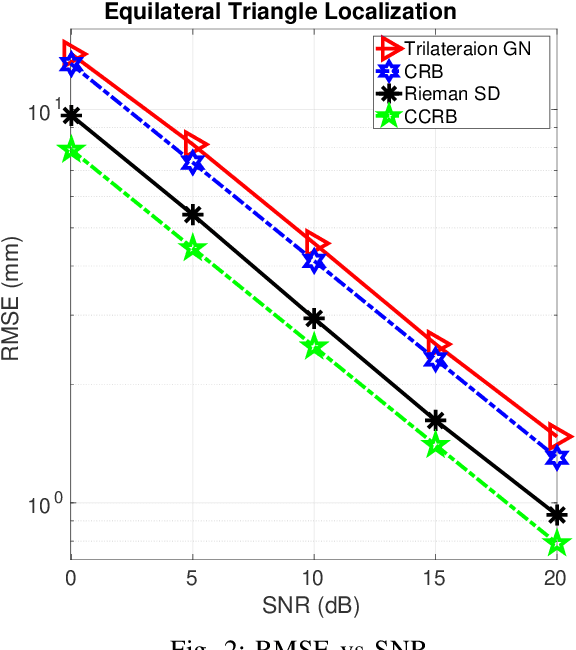
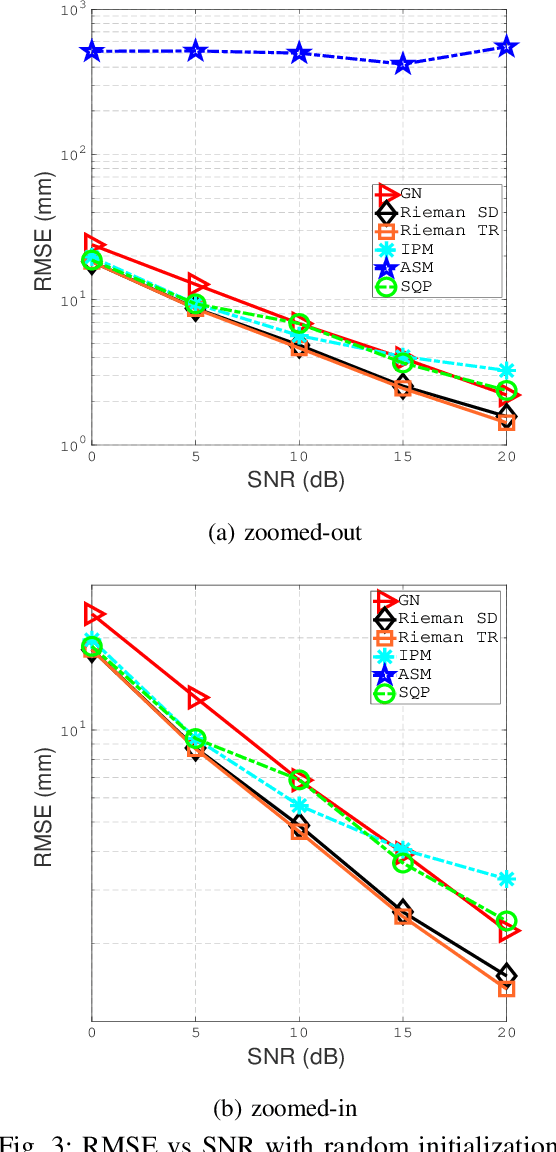
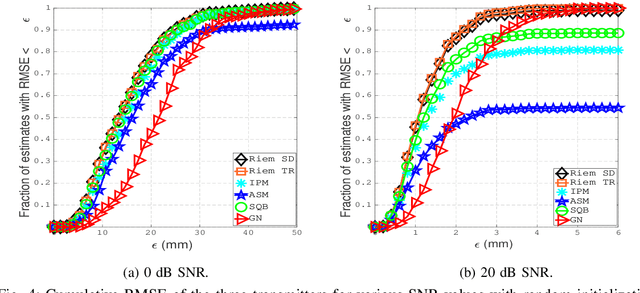
This paper designs a high accuracy spatial location estimation method using ultrasound waves by exploiting the fixed geometry of the transmitters. Assuming an equilateral triangle antenna configuration, where three antennas are placed as the vertices of an equilateral triangle, the spatial location problem can be formulated as a non-convex optimization problem whose interior is shown to admit a Riemannian manifold structure. The investigation of the geometry of the newly introduced manifold, i.e. the manifold of all equilateral triangles in R^3, allows the design of highly efficient optimization algorithms. Simulation results are presented to compare the performance of the proposed approach against popular methods from the literature. The results suggest that the proposed Riemannian-based methods outperform the state-of-the-art methods. Furthermore, the proposed Riemannian methods require much smaller computation time as compared with popular generic non-convex approaches.
Advanced Lane Detection Model for the Virtual Development of Highly Automated Functions
Apr 15, 2021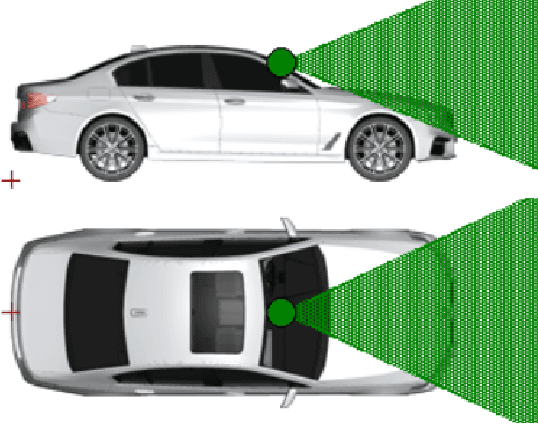
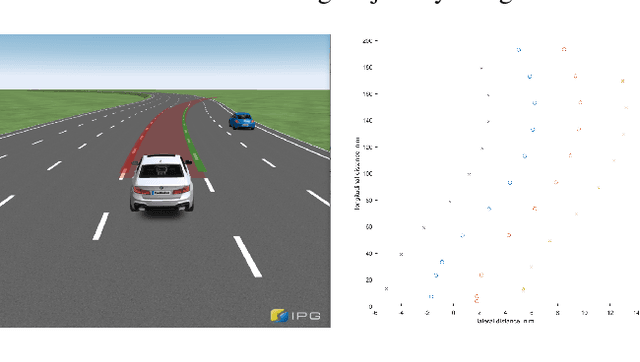


Virtual development and prototyping has already become an integral part in the field of automated driving systems (ADS). There are plenty of software tools that are used for the virtual development of ADS. One such tool is CarMaker from IPG Automotive, which is widely used in the scientific community and in the automotive industry. It offers a broad spectrum of implementation and modelling possibilities of the vehicle, driver behavior, control, sensors, and environmental models. Focusing on the virtual development of highly automated driving functions on the vehicle guidance level, it is essential to perceive the environment in a realistic manner. For the longitudinal and lateral path guidance line detection sensors are necessary for the determination of the relevant perceiving vehicle and for the planning of trajectories. For this purpose, a lane sensor model was developed in order to efficiently detect lanes in the simulation environment of CarMaker. The so-called advanced lane detection model (ALDM) is optimized regarding the calculation time and is for the lateral and longitudinal vehicle guidance in CarMaker.
Forecasting with Multiple Seasonality
Aug 27, 2020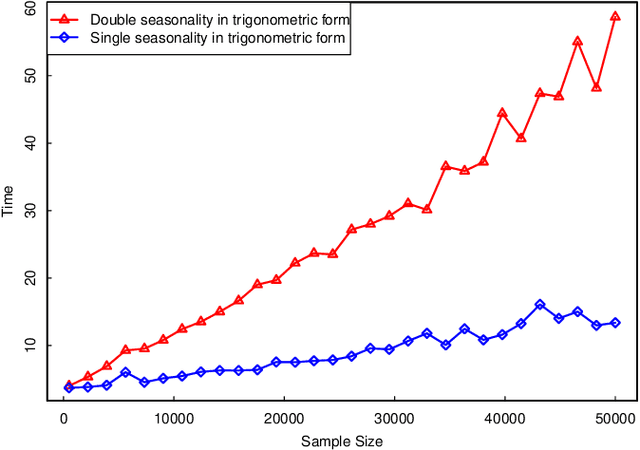
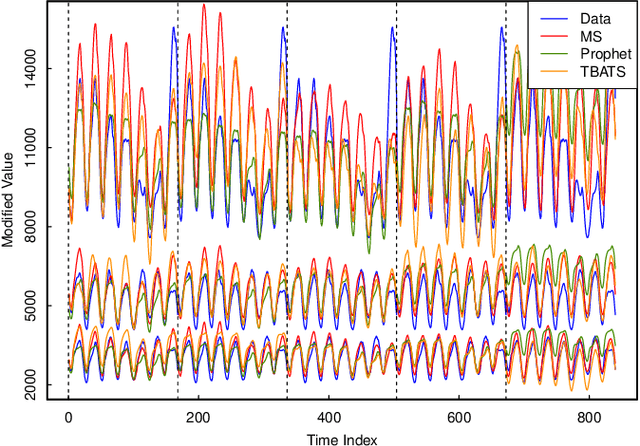
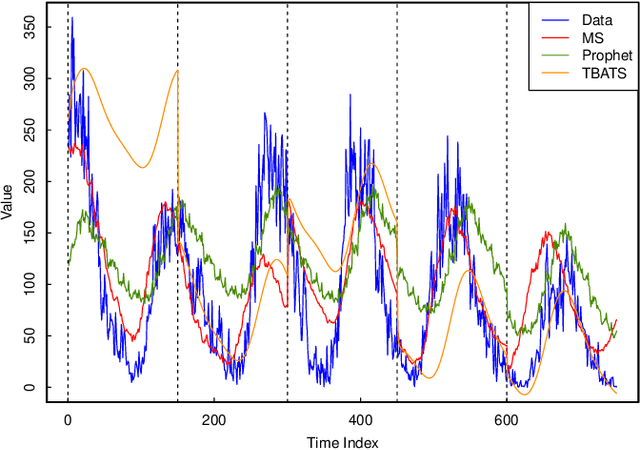
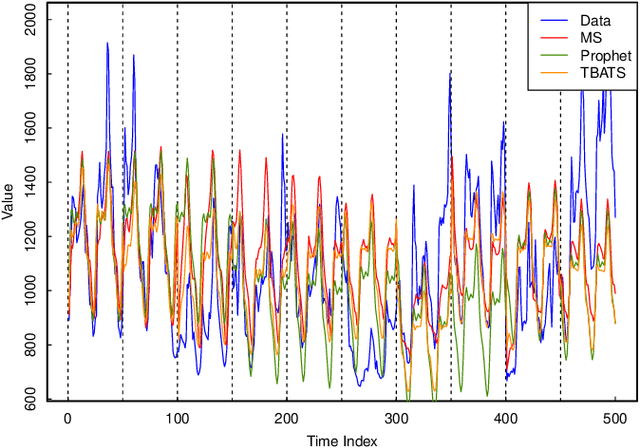
An emerging number of modern applications involve forecasting time series data that exhibit both short-time dynamics and long-time seasonality. Specifically, time series with multiple seasonality is a difficult task with comparatively fewer discussions. In this paper, we propose a two-stage method for time series with multiple seasonality, which does not require pre-determined seasonality periods. In the first stage, we generalize the classical seasonal autoregressive moving average (ARMA) model in multiple seasonality regime. In the second stage, we utilize an appropriate criterion for lag order selection. Simulation and empirical studies show the excellent predictive performance of our method, especially compared to a recently popular `Facebook Prophet' model for time series.
Data-driven Full-waveform Inversion Surrogate using Conditional Generative Adversarial Networks
Apr 30, 2021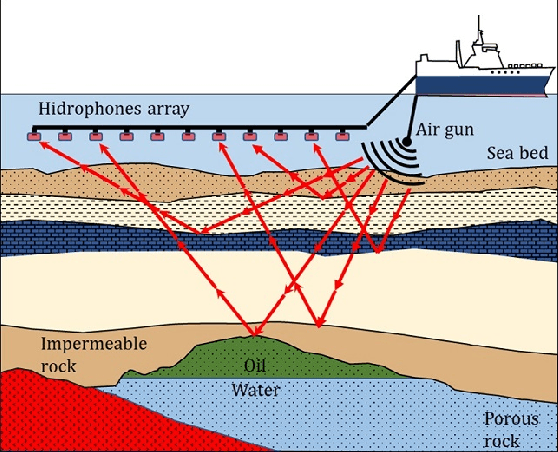
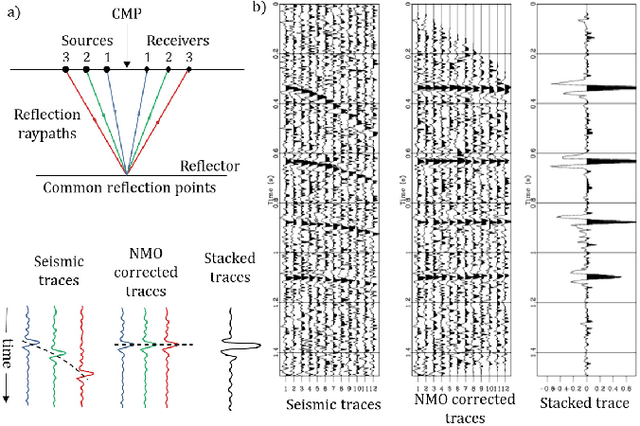

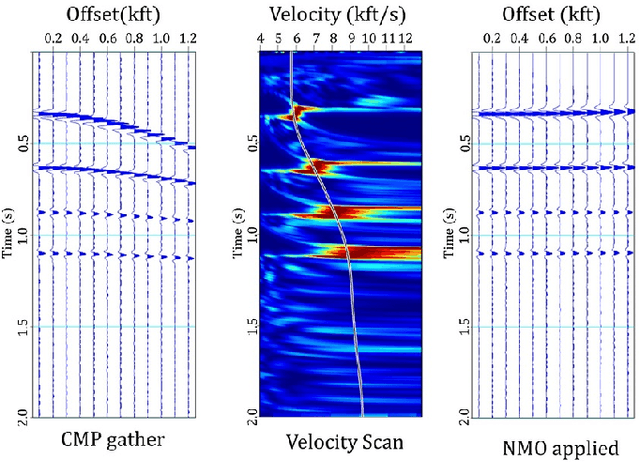
In the Oil and Gas industry, estimating a subsurface velocity field is an essential step in seismic processing, reservoir characterization, and hydrocarbon volume calculation. Full-waveform inversion (FWI) velocity modeling is an iterative advanced technique that provides an accurate and detailed velocity field model, although at a very high computational cost due to the physics-based numerical simulations required at each FWI iteration. In this study, we propose a method of generating velocity field models, as detailed as those obtained through FWI, using a conditional generative adversarial network (cGAN) with multiple inputs. The primary motivation of this approach is to circumvent the extremely high cost of full-waveform inversion velocity modeling. Real-world data were used to train and test the proposed network architecture, and three evaluation metrics (percent error, structural similarity index measure, and visual analysis) were adopted as quality criteria. Based on these metrics, the results evaluated upon the test set suggest that the GAN was able to accurately match real FWI generated outputs, enabling it to extract from input data the main geological structures and lateral velocity variations. Experimental results indicate that the proposed method, when deployed, has the potential to increase the speed of geophysical reservoir characterization processes, saving on time and computational resources.
Unconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021



The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
Physical deep learning based on optimal control of dynamical systems
Dec 16, 2020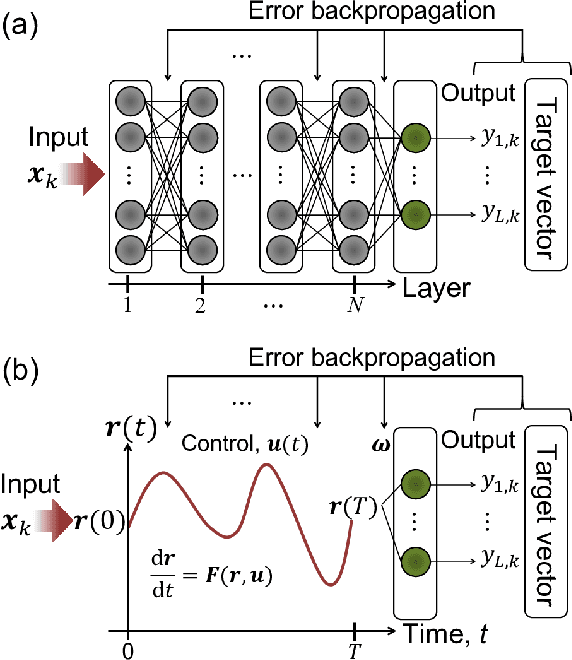
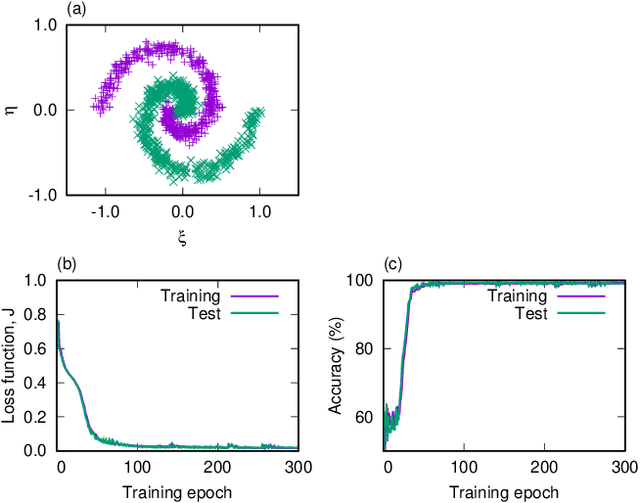
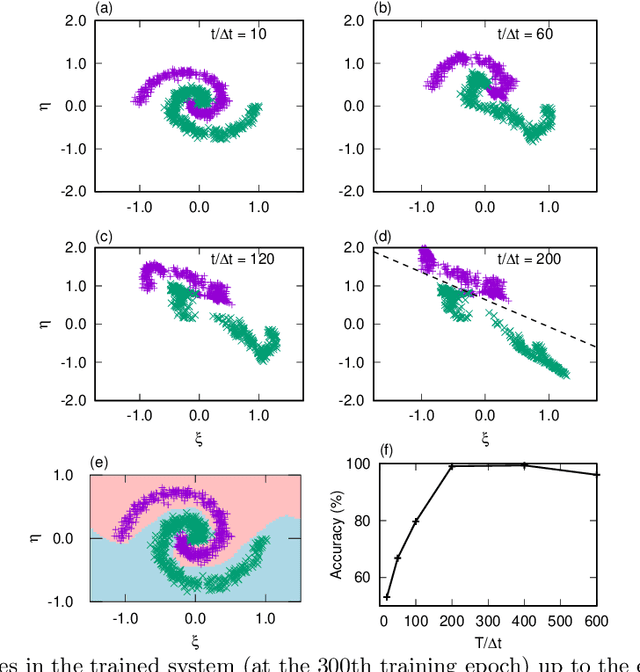
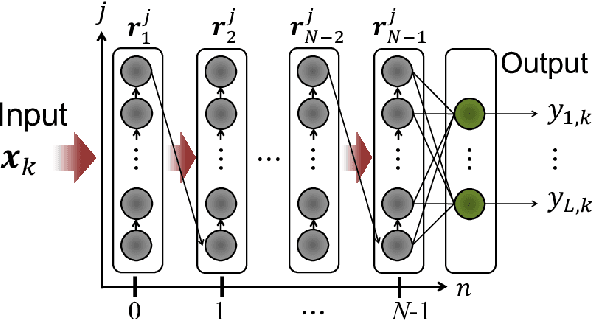
A central topic in recent artificial intelligence technologies is deep learning, which can be regarded as a multilayer feedforward neural network. An essence of deep learning is the information propagation through the layers, suggesting a connection between deep neural networks and dynamical systems, in the sense that the information propagation is explicitly modeled by the time-evolution of dynamical systems. Here, we present a pattern recognition based on optimal control of continuous-time dynamical systems, which is suitable for physical hardware implementation. The learning is based on the adjoint method to optimally control dynamical systems, and the deep (virtual) network structures based on the time evolution of the systems can be used for processing input information. As an example, we apply the dynamics-based recognition approach to an optoelectronic delay system and show that the use of the delay system enables image recognition and nonlinear classifications with only a few control signals, in contrast to conventional multilayer neural networks which require training of a large number of weight parameters. The proposed approach enables to gain insight into mechanisms of deep network processing in the framework of an optimal control problem and opens a novel pathway to realize physical computing hardware.