 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TubeR: Tube-Transformer for Action Detection
Apr 02, 2021
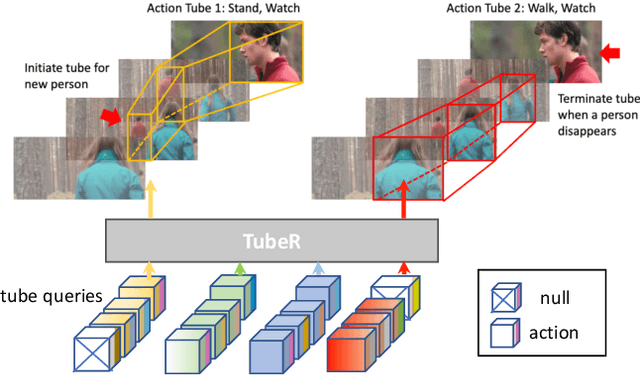
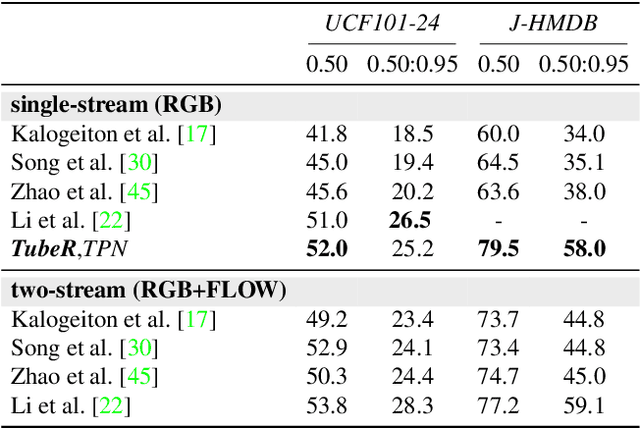
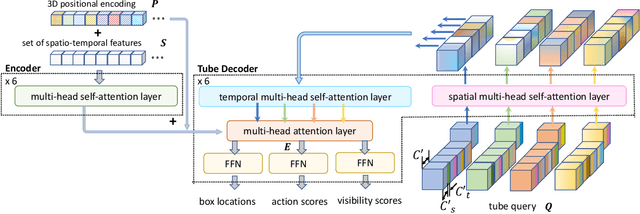

In this paper, we propose TubeR: the first transformer based network for end-to-end action detection, with an encoder and decoder optimized for modeling action tubes with variable lengths and aspect ratios. TubeR does not rely on hand-designed tube structures, automatically links predicted action boxes over time and learns a set of tube queries related to actions. By learning action tube embeddings, TubeR predicts more precise action tubes with flexible spatial and temporal extents. Our experiments demonstrate TubeR achieves state-of-the-art among single-stream methods on UCF101-24 and J-HMDB. TubeR outperforms existing one-model methods on AVA and is even competitive with the two-model methods. Moreover, we observe TubeR has the potential on tracking actors with different actions, which will foster future research in long-range video understanding.
Generic Itemset Mining Based on Reinforcement Learning
May 17, 2021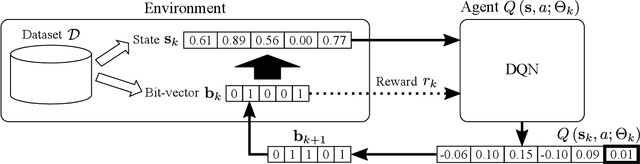

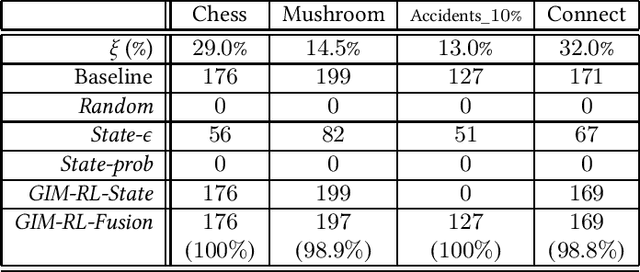
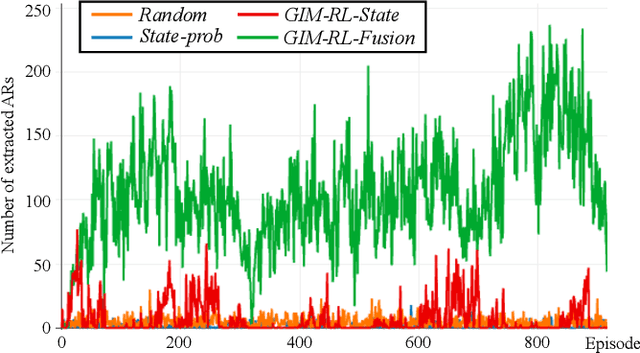
One of the biggest problems in itemset mining is the requirement of developing a data structure or algorithm, every time a user wants to extract a different type of itemsets. To overcome this, we propose a method, called Generic Itemset Mining based on Reinforcement Learning (GIM-RL), that offers a unified framework to train an agent for extracting any type of itemsets. In GIM-RL, the environment formulates iterative steps of extracting a target type of itemsets from a dataset. At each step, an agent performs an action to add or remove an item to or from the current itemset, and then obtains from the environment a reward that represents how relevant the itemset resulting from the action is to the target type. Through numerous trial-and-error steps where various rewards are obtained by diverse actions, the agent is trained to maximise cumulative rewards so that it acquires the optimal action policy for forming as many itemsets of the target type as possible. In this framework, an agent for extracting any type of itemsets can be trained as long as a reward suitable for the type can be defined. The extensive experiments on mining high utility itemsets, frequent itemsets and association rules show the general effectiveness and one remarkable potential (agent transfer) of GIM-RL. We hope that GIM-RL opens a new research direction towards learning-based itemset mining.
Artificial Neural Network Modeling for Airline Disruption Management
May 03, 2021

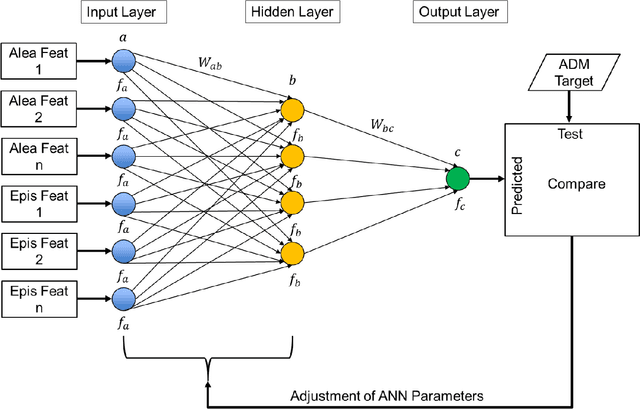
Since the 1970s, most airlines have incorporated computerized support for managing disruptions during flight schedule execution. However, existing platforms for airline disruption management (ADM) employ monolithic system design methods that rely on the creation of specific rules and requirements through explicit optimization routines, before a system that meets the specifications is designed. Thus, current platforms for ADM are unable to readily accommodate additional system complexities resulting from the introduction of new capabilities, such as the introduction of unmanned aerial systems (UAS), operations and infrastructure, to the system. To this end, we use historical data on airline scheduling and operations recovery to develop a system of artificial neural networks (ANNs), which describe a predictive transfer function model (PTFM) for promptly estimating the recovery impact of disruption resolutions at separate phases of flight schedule execution during ADM. Furthermore, we provide a modular approach for assessing and executing the PTFM by employing a parallel ensemble method to develop generative routines that amalgamate the system of ANNs. Our modular approach ensures that current industry standards for tardiness in flight schedule execution during ADM are satisfied, while accurately estimating appropriate time-based performance metrics for the separate phases of flight schedule execution.
Classification of Time-Series Images Using Deep Convolutional Neural Networks
Oct 07, 2017Convolutional Neural Networks (CNN) has achieved a great success in image recognition task by automatically learning a hierarchical feature representation from raw data. While the majority of Time-Series Classification (TSC) literature is focused on 1D signals, this paper uses Recurrence Plots (RP) to transform time-series into 2D texture images and then take advantage of the deep CNN classifier. Image representation of time-series introduces different feature types that are not available for 1D signals, and therefore TSC can be treated as texture image recognition task. CNN model also allows learning different levels of representations together with a classifier, jointly and automatically. Therefore, using RP and CNN in a unified framework is expected to boost the recognition rate of TSC. Experimental results on the UCR time-series classification archive demonstrate competitive accuracy of the proposed approach, compared not only to the existing deep architectures, but also to the state-of-the art TSC algorithms.
Detection and Prediction of Users Attitude Based on Real-Time and Batch Sentiment Analysis of Facebook Comments
Jun 08, 2019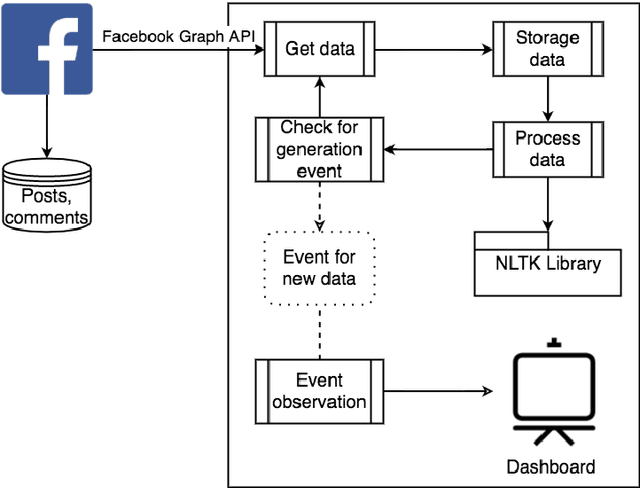
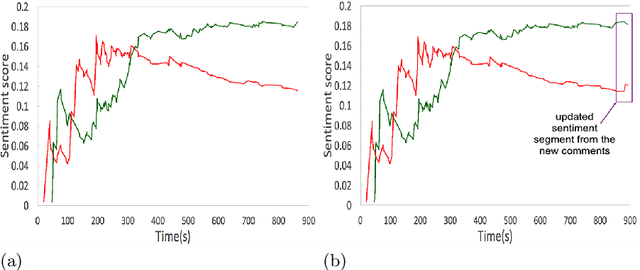
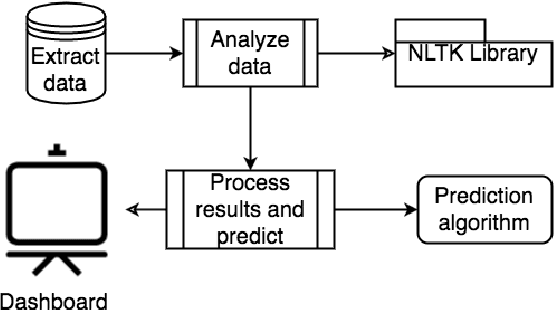
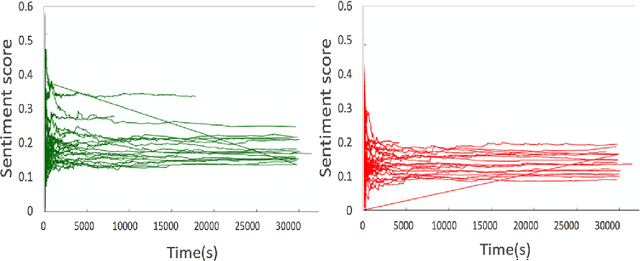
The most of the people have their account on social networks (e.g. Facebook, Vkontakte) where they express their attitude to different situations and events. Facebook provides only the positive mark as a like button and share. However, it is important to know the position of a certain user on posts even though the opinion is negative. Positive, negative and neutral attitude can be extracted from the comments of users. Overall information about positive, negative and neutral opinion can bring the understanding of how people react in a position. Moreover, it is important to know how attitude is changing during the time period. The contribution of the paper is a new method based on sentiment text analysis for detection and prediction negative and positive patterns for Facebook comments which combines (i) real-time sentiment text analysis for pattern discovery and (ii) batch data processing for creating opinion forecasting algorithm. To perform forecast we propose two-steps algorithm where: (i) patterns are clustered using unsupervised clustering techniques and (ii) trend prediction is performed based on finding the nearest pattern from the certain cluster. Case studies show the efficiency and accuracy (Avg. MAE = 0.008) of the proposed method and its practical applicability. Also, we discovered three types of users attitude patterns and described them.
Learning Transferable Kinematic Dictionary for 3D Human Pose and Shape Reconstruction
Apr 02, 2021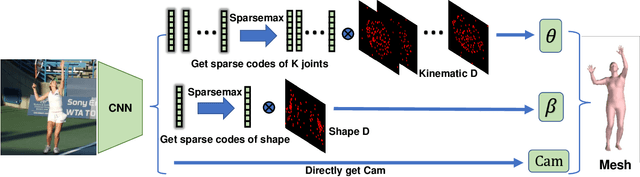
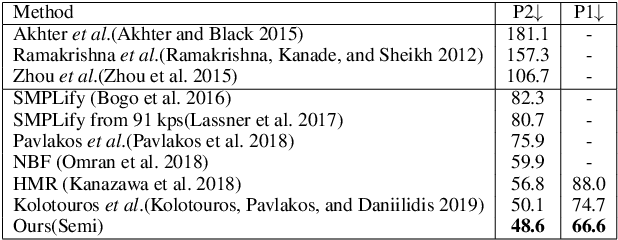
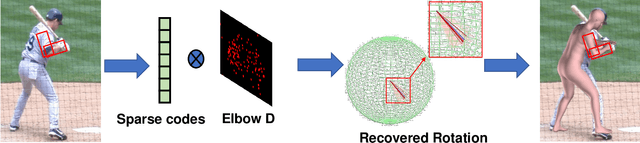

Estimating 3D human pose and shape from a single image is highly under-constrained. To address this ambiguity, we propose a novel prior, namely kinematic dictionary, which explicitly regularizes the solution space of relative 3D rotations of human joints in the kinematic tree. Integrated with a statistical human model and a deep neural network, our method achieves end-to-end 3D reconstruction without the need of using any shape annotations during the training of neural networks. The kinematic dictionary bridges the gap between in-the-wild images and 3D datasets, and thus facilitates end-to-end training across all types of datasets. The proposed method achieves competitive results on large-scale datasets including Human3.6M, MPI-INF-3DHP, and LSP, while running in real-time given the human bounding boxes.
Improving Landslide Detection on SAR Data through Deep Learning
May 03, 2021
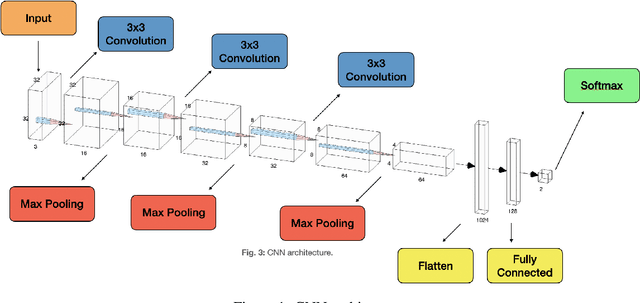

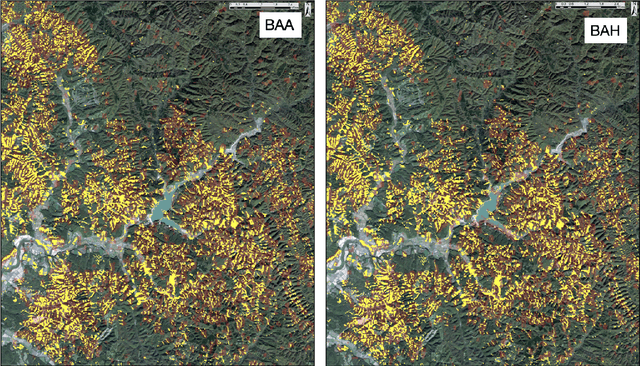
In this letter, we use deep-learning convolution neural networks (CNNs) to assess the landslide mapping and classification performances on optical images (from Sentinel-2) and SAR images (from Sentinel-1). The training and test zones used to independently evaluate the performance of the CNNs on different datasets are located in the eastern Iburi subprefecture in Hokkaido, where, at 03.08 local time (JST) on September 6, 2018, an Mw 6.6 earthquake triggered about 8000 coseismic landslides. We analyzed the conditions before and after the earthquake exploiting multi-polarization SAR as well as optical data by means of a CNN implemented in TensorFlow that points out the locations where the Landslide class is predicted as more likely. As expected, the CNN run on optical images proved itself excellent for the landslide detection task, achieving an overall accuracy of 99.20% while CNNs based on the combination of ground range detected (GRD) SAR data reached overall accuracies beyond 94%. Our findings show that the integrated use of SAR data may also allow for rapid mapping even during storms and under dense cloud cover and seems to provide comparable accuracy to classical optical change detection in landslide recognition and mapping.
Real-time Dynamic Object Detection for Autonomous Driving using Prior 3D-Maps
Sep 28, 2018
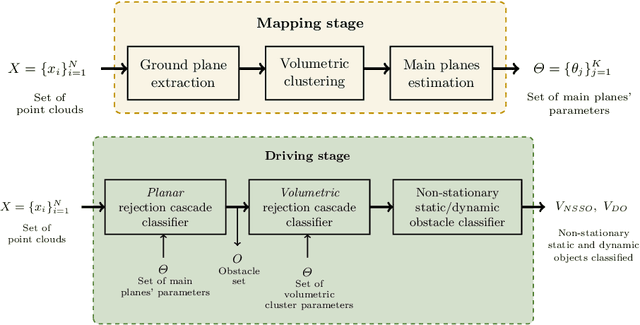


Lidar has become an essential sensor for autonomous driving as it provides reliable depth estimation. Lidar is also the primary sensor used in building 3D maps which can be used even in the case of low-cost systems which do not use Lidar. Computation on Lidar point clouds is intensive as it requires processing of millions of points per second. Additionally there are many subsequent tasks such as clustering, detection, tracking and classification which makes real-time execution challenging. In this paper, we discuss real-time dynamic object detection algorithms which leverages previously mapped Lidar point clouds to reduce processing. The prior 3D maps provide a static background model and we formulate dynamic object detection as a background subtraction problem. Computation and modeling challenges in the mapping and online execution pipeline are described. We propose a rejection cascade architecture to subtract road regions and other 3D regions separately. We implemented an initial version of our proposed algorithm and evaluated the accuracy on CARLA simulator.
Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities
Jun 03, 2021

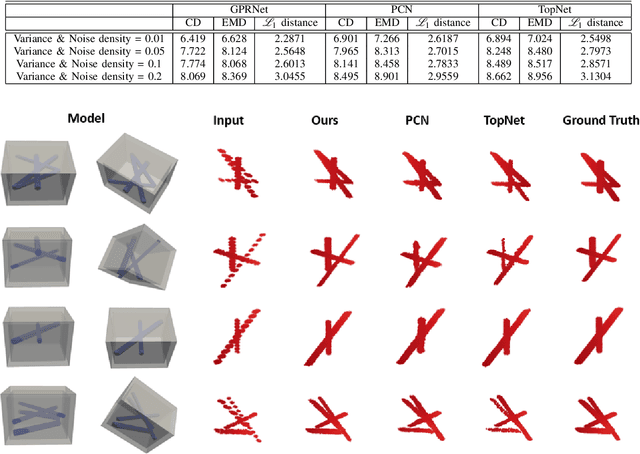
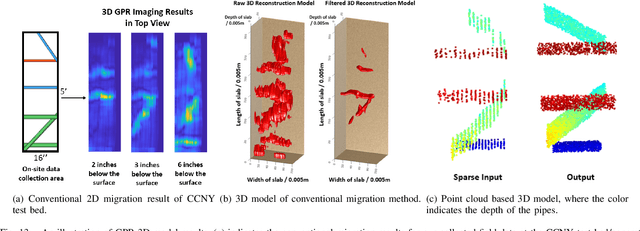
Ground Penetrating Radar (GPR) is an effective non-destructive evaluation (NDE) device for inspecting and surveying subsurface objects (i.e., rebars, utility pipes) in complex environments. However, the current practice for GPR data collection requires a human inspector to move a GPR cart along pre-marked grid lines and record the GPR data in both X and Y directions for post-processing by 3D GPR imaging software. It is time-consuming and tedious work to survey a large area. Furthermore, identifying the subsurface targets depends on the knowledge of an experienced engineer, who has to make manual and subjective interpretation that limits the GPR applications, especially in large-scale scenarios. In addition, the current GPR imaging technology is not intuitive, and not for normal users to understand, and not friendly to visualize. To address the above challenges, this paper presents a novel robotic system to collect GPR data, interpret GPR data, localize the underground utilities, reconstruct and visualize the underground objects' dense point cloud model in a user-friendly manner. This system is composed of three modules: 1) a vision-aided Omni-directional robotic data collection platform, which enables the GPR antenna to scan the target area freely with an arbitrary trajectory while using a visual-inertial-based positioning module tags the GPR measurements with positioning information; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction method, i.e., GPRNet, to generate underground utility model represented as fine 3D point cloud. Comparative studies on synthetic and field GPR raw data with various incompleteness and noise are performed.
Efficient Transformer based Method for Remote Sensing Image Change Detection
Mar 15, 2021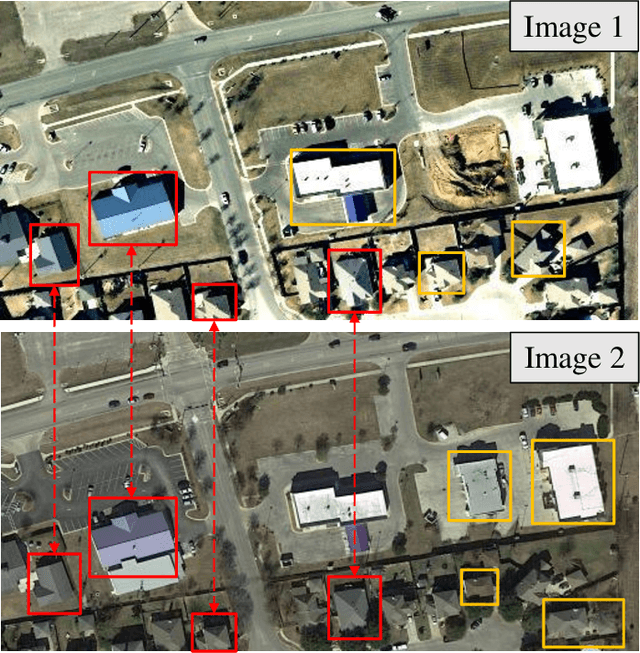
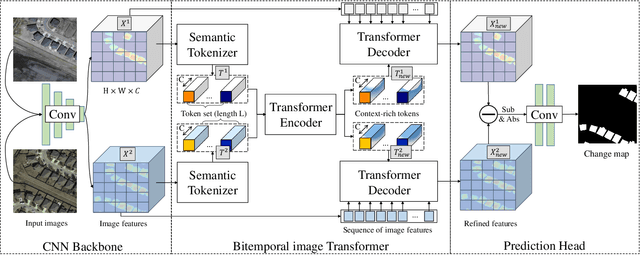
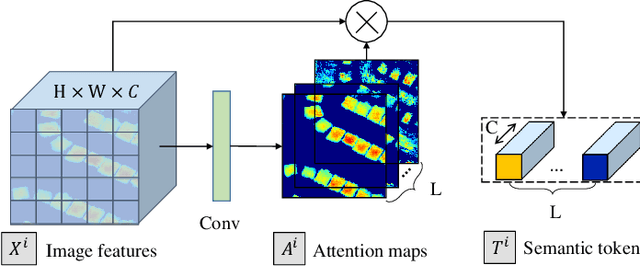
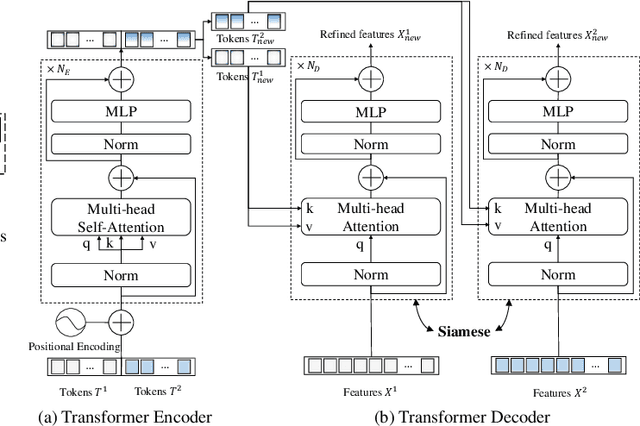
Modern change detection (CD) has achieved remarkable success by the powerful discriminative ability of deep convolutions. However, high-resolution remote sensing CD remains challenging due to the complexity of objects in the scene. Objects with the same semantic concept may show distinct spectral behaviors at different times and different spatial locations. Most recent CD pipelines using pure convolutions are still struggling to relate long-range concepts in space-time. Non-local self-attention approaches show promising performance via modeling dense relations among pixels, yet are computationally inefficient. Here, we propose a bitemporal image transformer (BiT) to efficiently and effectively model contexts within the spatial-temporal domain. Our intuition is that the high-level concepts of the change of interest can be represented by a few visual words, i.e., semantic tokens. To achieve this, we express the bitemporal image into a few tokens, and use a transformer encoder to model contexts in the compact token-based space-time. The learned context-rich tokens are then feedback to the pixel-space for refining the original features via a transformer decoder. We incorporate BiT in a deep feature differencing-based CD framework. Extensive experiments on three CD datasets demonstrate the effectiveness and efficiency of the proposed method. Notably, our BiT-based model significantly outperforms the purely convolutional baseline using only 3 times lower computational costs and model parameters. Based on a naive backbone (ResNet18) without sophisticated structures (e.g., FPN, UNet), our model surpasses several state-of-the-art CD methods, including better than two recent attention-based methods in terms of efficiency and accuracy. Our code will be made public.