 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diverse Branch Block: Building a Convolution as an Inception-like Unit
Mar 29, 2021
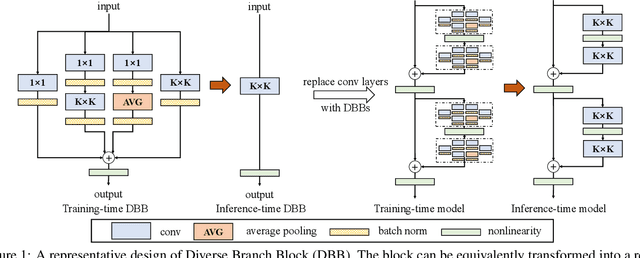
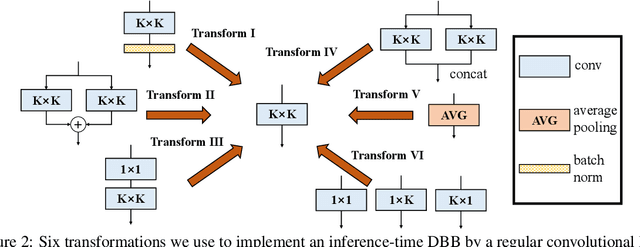
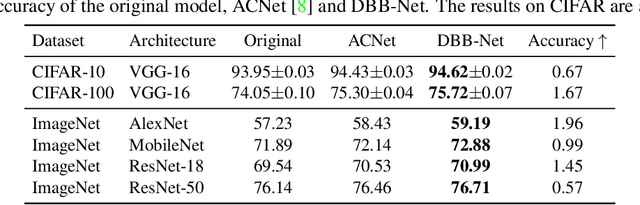
We propose a universal building block of Convolutional Neural Network (ConvNet) to improve the performance without any inference-time costs. The block is named Diverse Branch Block (DBB), which enhances the representational capacity of a single convolution by combining diverse branches of different scales and complexities to enrich the feature space, including sequences of convolutions, multi-scale convolutions, and average pooling. After training, a DBB can be equivalently converted into a single conv layer for deployment. Unlike the advancements of novel ConvNet architectures, DBB complicates the training-time microstructure while maintaining the macro architecture, so that it can be used as a drop-in replacement for regular conv layers of any architecture. In this way, the model can be trained to reach a higher level of performance and then transformed into the original inference-time structure for inference. DBB improves ConvNets on image classification (up to 1.9% higher top-1 accuracy on ImageNet), object detection and semantic segmentation. The PyTorch code and models are released at https://github.com/DingXiaoH/DiverseBranchBlock.
A reinforcement learning approach to resource allocation in genomic selection
Jul 22, 2021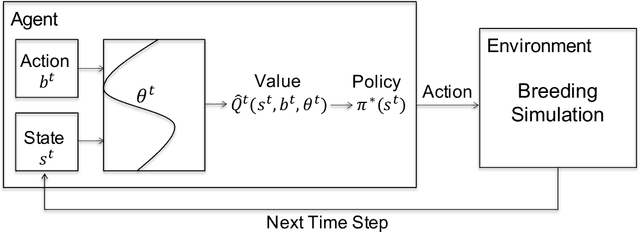
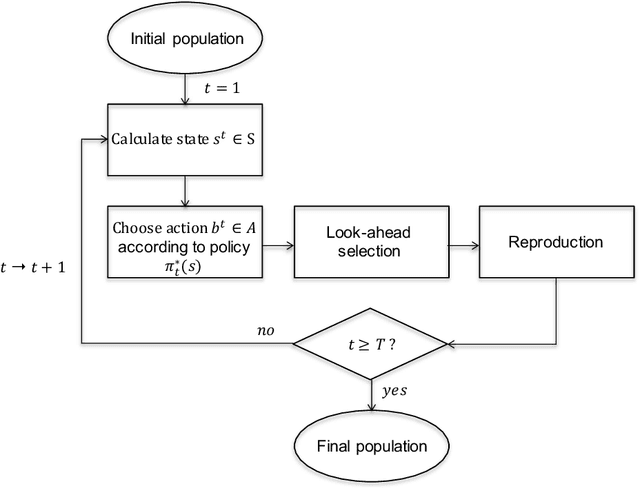
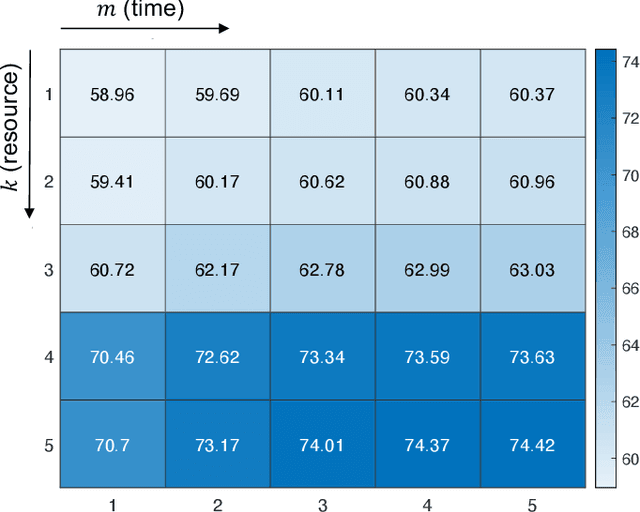
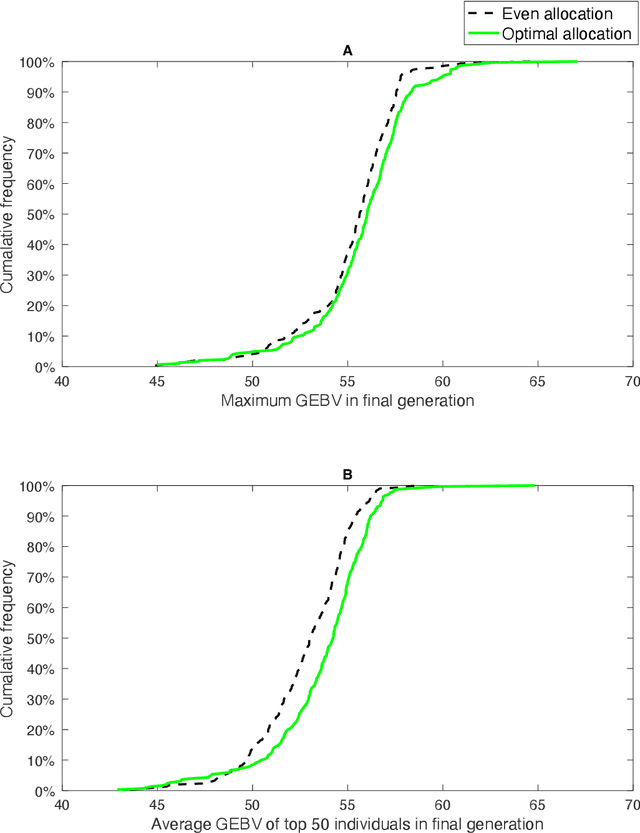
Genomic selection (GS) is a technique that plant breeders use to select individuals to mate and produce new generations of species. Allocation of resources is a key factor in GS. At each selection cycle, breeders are facing the choice of budget allocation to make crosses and produce the next generation of breeding parents. Inspired by recent advances in reinforcement learning for AI problems, we develop a reinforcement learning-based algorithm to automatically learn to allocate limited resources across different generations of breeding. We mathematically formulate the problem in the framework of Markov Decision Process (MDP) by defining state and action spaces. To avoid the explosion of the state space, an integer linear program is proposed that quantifies the trade-off between resources and time. Finally, we propose a value function approximation method to estimate the action-value function and then develop a greedy policy improvement technique to find the optimal resources. We demonstrate the effectiveness of the proposed method in enhancing genetic gain using a case study with realistic data.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 06, 2021
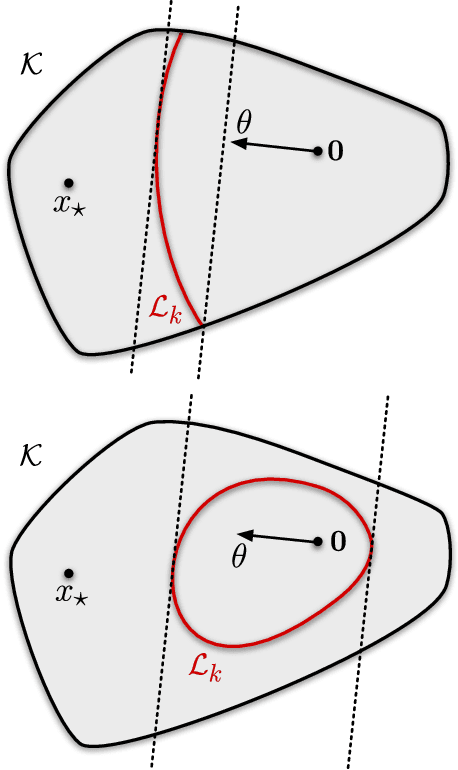
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f_t(x) = g_t(\langle x, \theta\rangle)$ for convex $g_t : \mathbb R \to \mathbb R$ and unknown $\theta \in \mathbb R^d$ that is homogeneous over time. We provide a short information-theoretic proof that the minimax regret is at most $O(d \sqrt{n} \log(n \operatorname{diam}(\mathcal K)))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021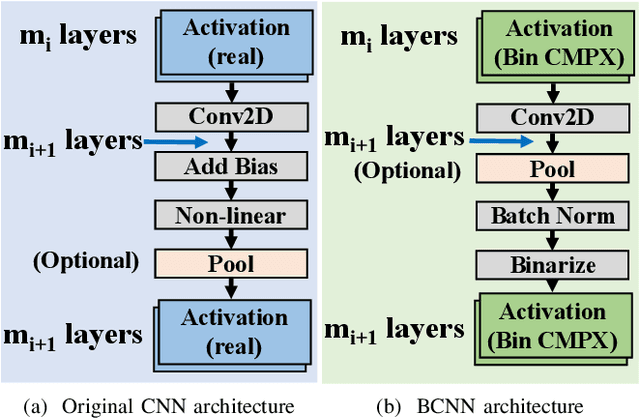
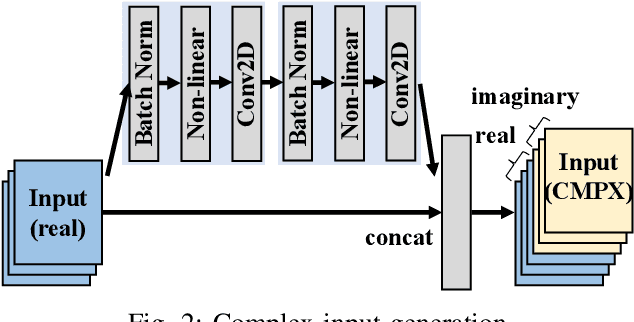

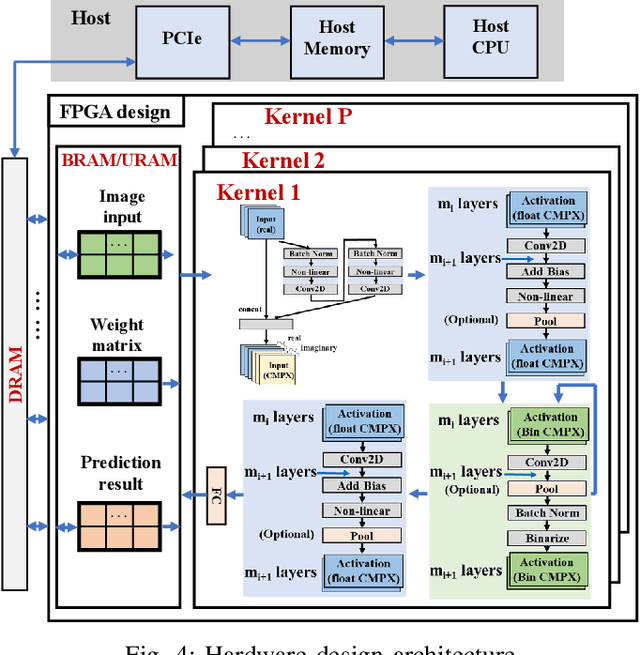
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.
Improving CNN classifiers by estimating test-time priors
May 21, 2018
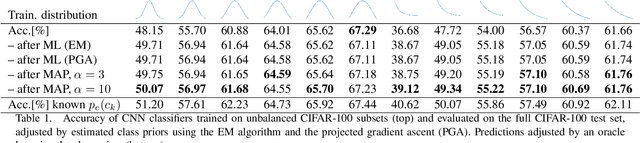
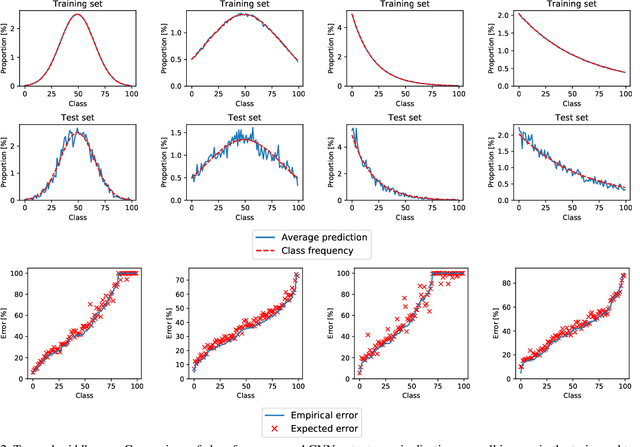
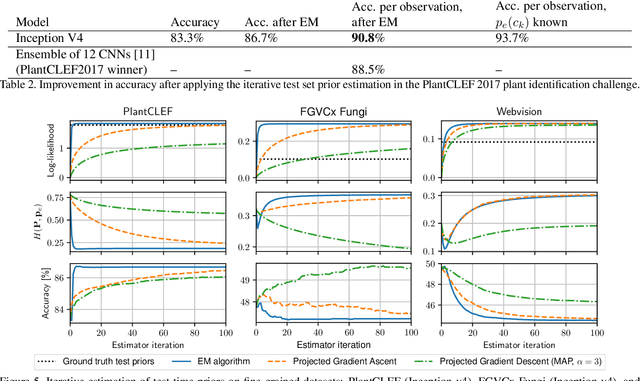
The problem of different training and test set class priors is addressed in the context of CNN classifiers. An EM-based algorithm for test-time class priors estimation is evaluated on fine-grained computer vision problems for both the batch and on-line situations. Experimental results show a significant improvement on the fine-grained classification tasks using the known evaluation-time priors, increasing the top-1 accuracy by 4.0% on the FGVC iNaturalist 2018 validation set and by 3.9% on the FGVCx Fungi 2018 validation set. Iterative estimation of test-time priors on the PlantCLEF 2017 dataset increased the image classification accuracy by 3.4%, allowing a single CNN model to achieve state-of-the-art results and outperform the competition-winning ensemble of 12 CNNs.
STR-GODEs: Spatial-Temporal-Ridership Graph ODEs for Metro Ridership Prediction
Jul 11, 2021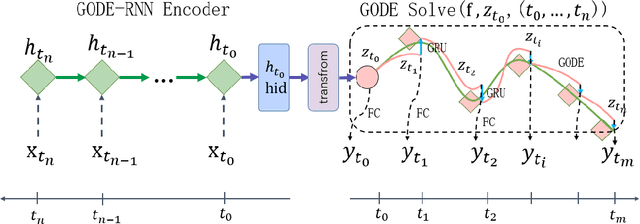
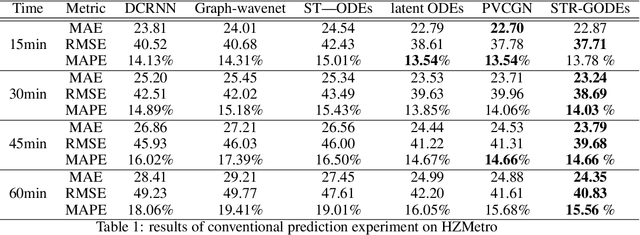
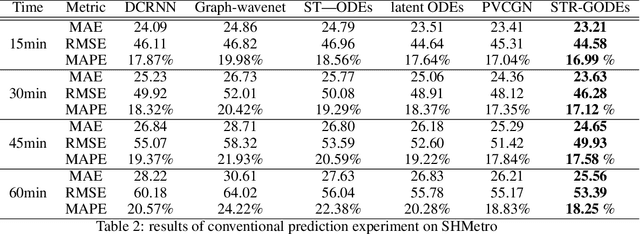
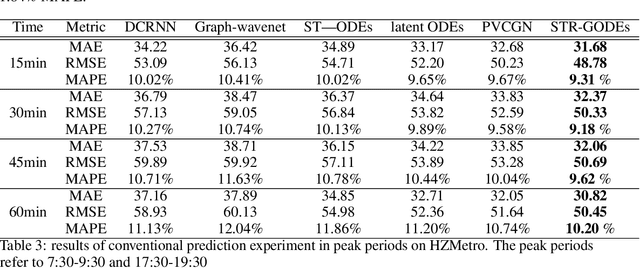
The metro ridership prediction has always received extensive attention from governments and researchers. Recent works focus on designing complicated graph convolutional recurrent network architectures to capture spatial and temporal patterns. These works extract the information of spatial dimension well, but the limitation of temporal dimension still exists. We extended Neural ODE algorithms to the graph network and proposed the STR-GODEs network, which can effectively learn spatial, temporal, and ridership correlations without the limitation of dividing data into equal-sized intervals on the timeline. While learning the spatial relations and the temporal correlations, we modify the GODE-RNN cell to obtain the ridership feature and hidden states. Ridership information and its hidden states are added to the GODESolve to reduce the error accumulation caused by long time series in prediction. Extensive experiments on two large-scale datasets demonstrate the efficacy and robustness of our model.
A Memory-Network Based Solution for Multivariate Time-Series Forecasting
Sep 06, 2018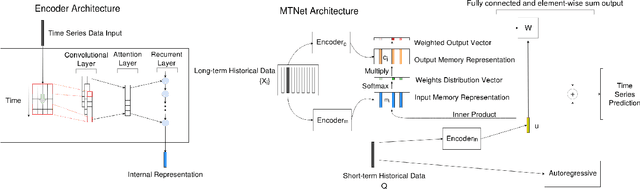
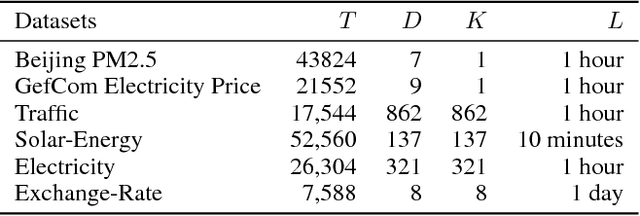
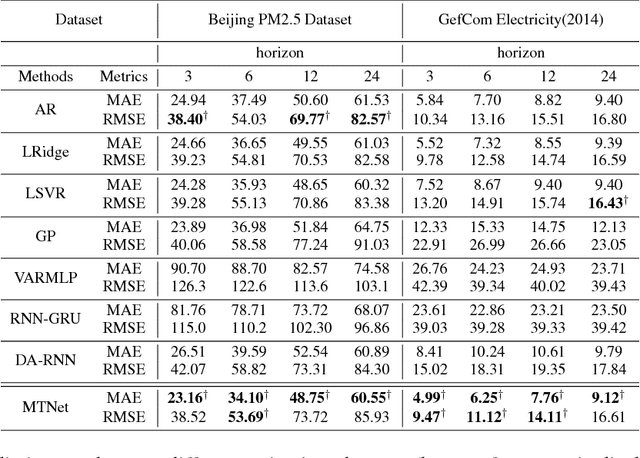
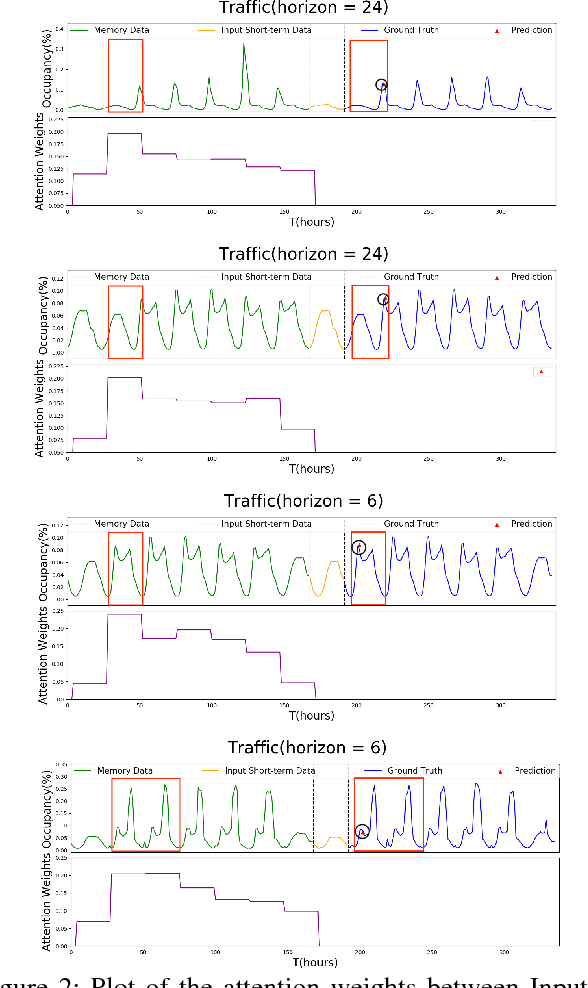
Multivariate time series forecasting is extensively studied throughout the years with ubiquitous applications in areas such as finance, traffic, environment, etc. Still, concerns have been raised on traditional methods for incapable of modeling complex patterns or dependencies lying in real word data. To address such concerns, various deep learning models, mainly Recurrent Neural Network (RNN) based methods, are proposed. Nevertheless, capturing extremely long-term patterns while effectively incorporating information from other variables remains a challenge for time-series forecasting. Furthermore, lack-of-explainability remains one serious drawback for deep neural network models. Inspired by Memory Network proposed for solving the question-answering task, we propose a deep learning based model named Memory Time-series network (MTNet) for time series forecasting. MTNet consists of a large memory component, three separate encoders, and an autoregressive component to train jointly. Additionally, the attention mechanism designed enable MTNet to be highly interpretable. We can easily tell which part of the historic data is referenced the most.
What can human minimal videos tell us about dynamic recognition models?
Apr 19, 2021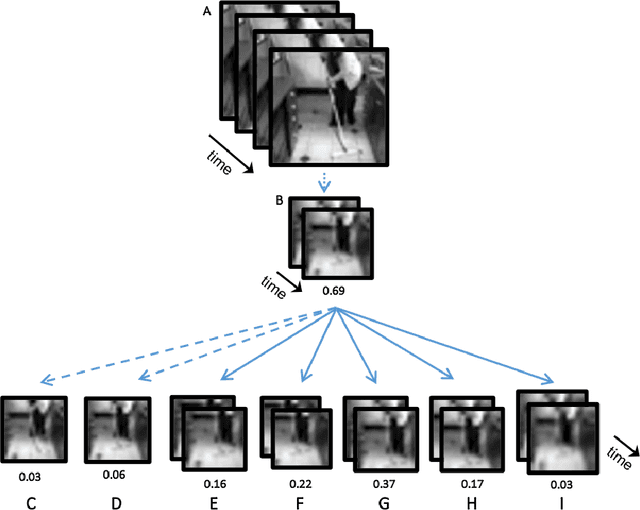

In human vision objects and their parts can be visually recognized from purely spatial or purely temporal information but the mechanisms integrating space and time are poorly understood. Here we show that human visual recognition of objects and actions can be achieved by efficiently combining spatial and motion cues in configurations where each source on its own is insufficient for recognition. This analysis is obtained by identifying minimal videos: these are short and tiny video clips in which objects, parts, and actions can be reliably recognized, but any reduction in either space or time makes them unrecognizable. State-of-the-art deep networks for dynamic visual recognition cannot replicate human behavior in these configurations. This gap between humans and machines points to critical mechanisms in human dynamic vision that are lacking in current models.
Fuzzy inference system application for oil-water flow patterns identification
May 24, 2021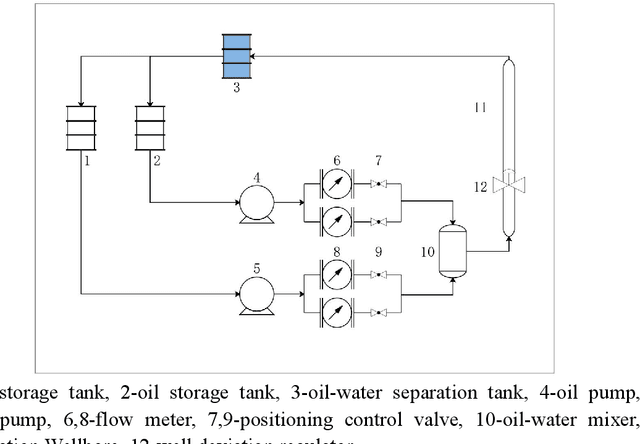
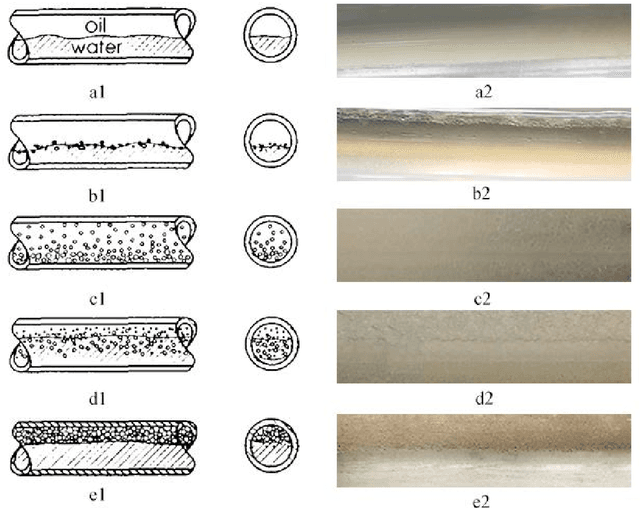
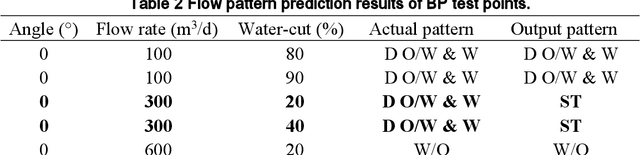
With the continuous development of the petroleum industry, long-distance transportation of oil and gas has been the norm. Due to gravity differentiation in horizontal wells and highly deviated wells (non-vertical wells), the water phase at the bottom of the pipeline will cause scaling and corrosion in the pipeline. Scaling and corrosion will make the transportation process difficult, and transportation costs will be considerably increased. Therefore, the study of the oil-water two-phase flow pattern is of great importance to oil production. In this paper, a fuzzy inference system is used to predict the flow pattern of the fluid, get the prediction result, and compares it with the prediction result of the BP neural network. From the comparison of the results, we found that the prediction results of the fuzzy inference system are more accurate and reliable than the prediction results of the BP neural network. At the same time, it can realize real-time monitoring and has less error control. Experimental results demonstrate that in the entire production logging process of non-vertical wells, the use of a fuzzy inference system to predict fluid flow patterns can greatly save production costs while ensuring the safe operation of production equipment.
A Multiple-View Geometric Model for Specularity Prediction on Non-Uniformly Curved Surfaces
Aug 20, 2021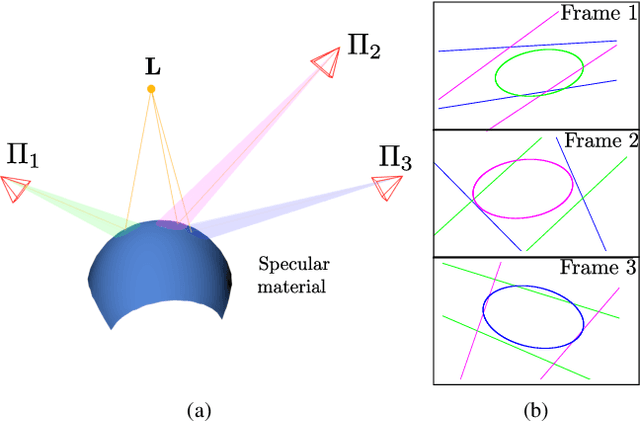
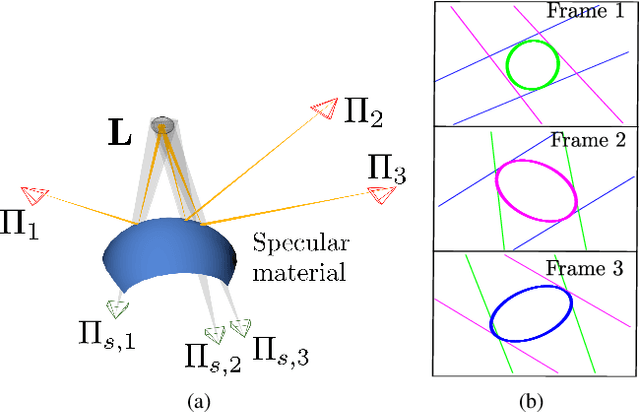

Specularity prediction is essential to many computer vision applications by giving important visual cues that could be used in Augmented Reality (AR), Simultaneous Localisation and Mapping (SLAM), 3D reconstruction and material modeling, thus improving scene understanding. However, it is a challenging task requiring numerous information from the scene including the camera pose, the geometry of the scene, the light sources and the material properties. Our previous work have addressed this task by creating an explicit model using an ellipsoid whose projection fits the specularity image contours for a given camera pose. These ellipsoid-based approaches belong to a family of models called JOint-LIght MAterial Specularity (JOLIMAS), where we have attempted to gradually remove assumptions on the scene such as the geometry of the specular surfaces. However, our most recent approach is still limited to uniformly curved surfaces. This paper builds upon these methods by generalising JOLIMAS to any surface geometry while improving the quality of specularity prediction, without sacrificing computation performances. The proposed method establishes a link between surface curvature and specularity shape in order to lift the geometric assumptions from previous work. Contrary to previous work, our new model is built from a physics-based local illumination model namely Torrance-Sparrow, providing a better model reconstruction. Specularity prediction using our new model is tested against the most recent JOLIMAS version on both synthetic and real sequences with objects of varying shape curvatures. Our method outperforms previous approaches in specularity prediction, including the real-time setup, as shown in the supplementary material using videos.