 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Occlusion Aware Kernel Correlation Filter Tracker using RGB-D
May 25, 2021



Unlike deep learning which requires large training datasets, correlation filter-based trackers like Kernelized Correlation Filter (KCF) uses implicit properties of tracked images (circulant matrices) for training in real-time. Despite their practical application in tracking, a need for a better understanding of the fundamentals associated with KCF in terms of theoretically, mathematically, and experimentally exists. This thesis first details the workings prototype of the tracker and investigates its effectiveness in real-time applications and supporting visualizations. We further address some of the drawbacks of the tracker in cases of occlusions, scale changes, object rotation, out-of-view and model drift with our novel RGB-D Kernel Correlation tracker. We also study the use of particle filters to improve trackers' accuracy. Our results are experimentally evaluated using a) standard dataset and b) real-time using the Microsoft Kinect V2 sensor. We believe this work will set the basis for a better understanding of the effectiveness of kernel-based correlation filter trackers and to further define some of its possible advantages in tracking.
Acoustic Echo Cancellation using Residual U-Nets
Sep 20, 2021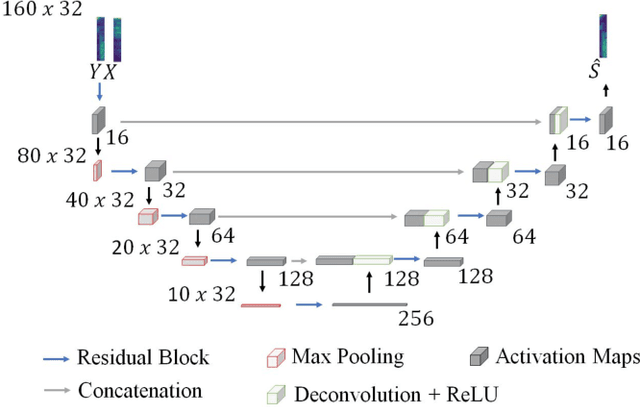
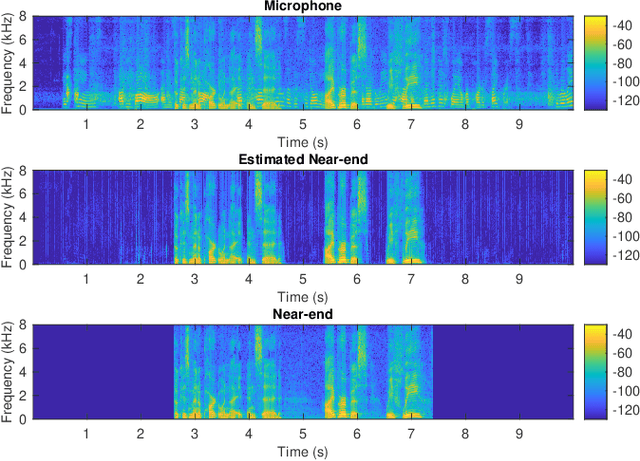

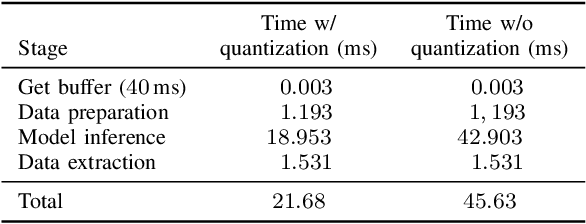
This paper presents an acoustic echo canceler based on a U-Net convolutional neural network for single-talk and double-talk scenarios. U-Net networks have previously been used in the audio processing area for source separation problems because of their ability to reproduce the finest details of audio signals, but to our knowledge, this is the first time they have been used for acoustic echo cancellation (AEC). The U-Net hyperparameters have been optimized to obtain the best AEC performance, but using a reduced number of parameters to meet a latency restriction of 40 ms. The training and testing of our model have been carried out within the framework of the 'ICASSP 2021 AEC Challenge' organized by Microsoft. We have trained the optimized U-Net model with a synthetic dataset only (S-U-Net) and with a synthetic dataset and the single-talk set of a real dataset (SR-U-Net), both datasets were released for the challenge. The S-U-Net model presented better results for double-talk scenarios, thus their inferred near-end signals from the blind testset were submitted to the challenge. Our canceler ranked 12th among 17 teams, and 5th among 10 academia teams, obtaining an overall mean opinion score of 3.57.
The ubiquitous digital file: A review of file management research
Sep 20, 2021Computer users spend time every day interacting with digital files and folders, including downloading, moving, naming, navigating to, searching for, sharing, and deleting them. Such file management has been the focus of many studies across various fields, but has not been explicitly acknowledged nor made the focus of dedicated review. In this article we present the first dedicated review of this topic and its research, synthesizing more than 230 publications from various research domains to establish what is known and what remains to be investigated, particularly by examining the common motivations, methods, and findings evinced by the previously furcate body of work. We find three typical research motivations in the literature reviewed: understanding how and why users store, organize, retrieve, and share files and folders, understanding factors that determine their behavior, and attempting to improve the user experience through novel interfaces and information services. Relevant conceptual frameworks and approaches to designing and testing systems are described, and open research challenges and the significance for other research areas are discussed. We conclude that file management is a ubiquitous, challenging, and relatively unsupported activity that invites and has received attention from several disciplines and has broad importance for topics across information science.
* Final version at https://doi.org/10.1002/asi.24222
Multi-modal Wound Classification using Wound Image and Location by Deep Neural Network
Sep 14, 2021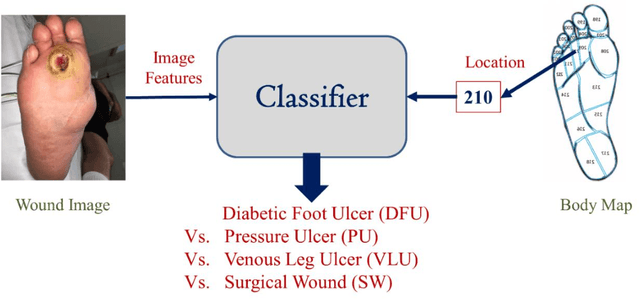
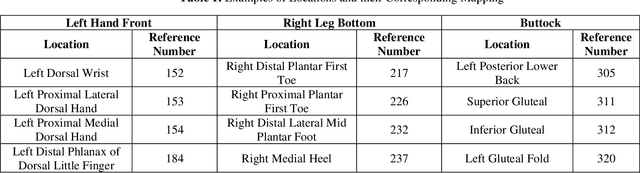
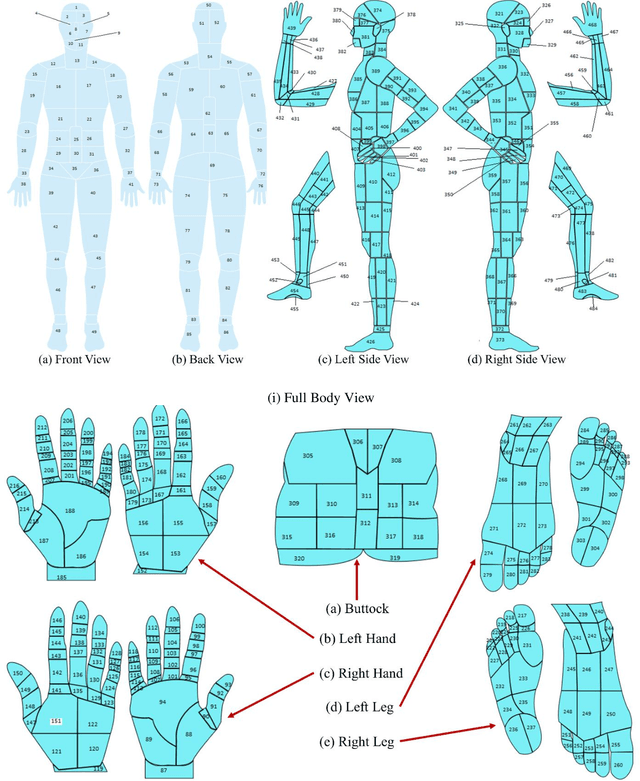
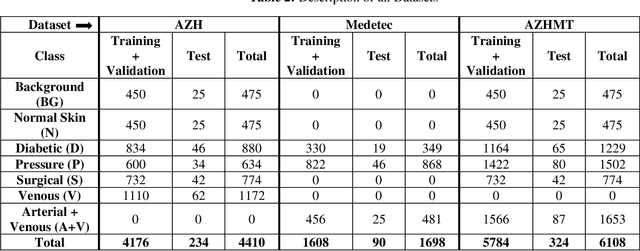
Wound classification is an essential step of wound diagnosis. An efficient classifier can assist wound specialists in classifying wound types with less financial and time costs and help them decide an optimal treatment procedure. This study developed a deep neural network-based multi-modal classifier using wound images and their corresponding locations to categorize wound images into multiple classes, including diabetic, pressure, surgical, and venous ulcers. A body map is also developed to prepare the location data, which can help wound specialists tag wound locations more efficiently. Three datasets containing images and their corresponding location information are designed with the help of wound specialists. The multi-modal network is developed by concatenating the image-based and location-based classifier's outputs with some other modifications. The maximum accuracy on mixed-class classifications (containing background and normal skin) varies from 77.33% to 100% on different experiments. The maximum accuracy on wound-class classifications (containing only diabetic, pressure, surgical, and venous) varies from 72.95% to 98.08% on different experiments. The proposed multi-modal network also shows a significant improvement in results from the previous works of literature.
Biologically Plausible Training Mechanisms for Self-Supervised Learning in Deep Networks
Oct 13, 2021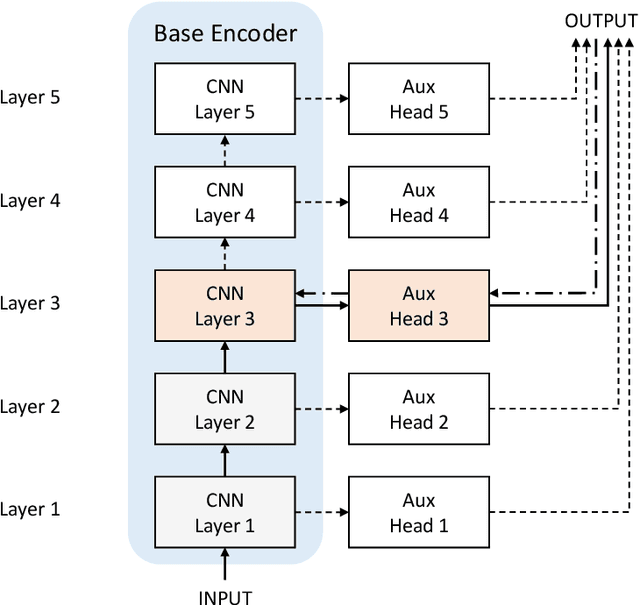
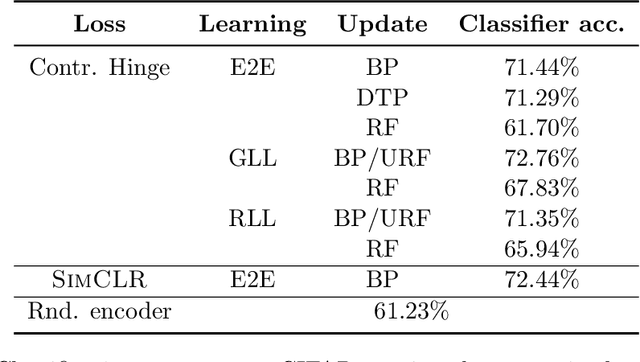
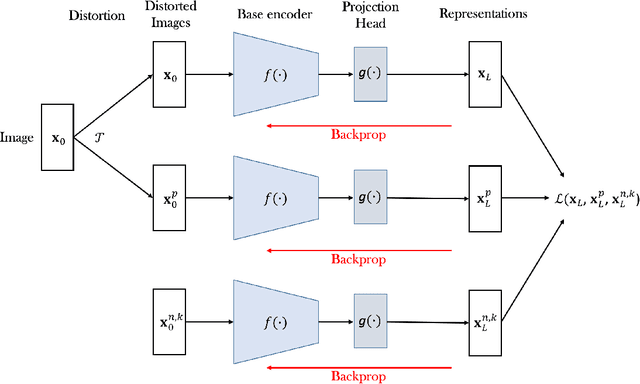
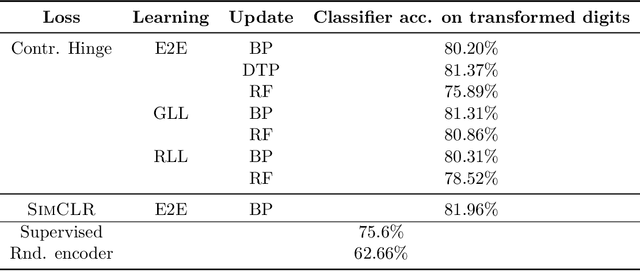
We develop biologically plausible training mechanisms for self-supervised learning (SSL) in deep networks. SSL, with a contrastive loss, is more natural as it does not require labelled data and its robustness to perturbations yields more adaptable embeddings. Moreover the perturbation of data required to create positive pairs for SSL is easily produced in a natural environment by observing objects in motion and with variable lighting over time. We propose a contrastive hinge based loss whose error involves simple local computations as opposed to the standard contrastive losses employed in the literature, which do not lend themselves easily to implementation in a network architecture due to complex computations involving ratios and inner products. Furthermore we show that learning can be performed with one of two more plausible alternatives to backpropagation. The first is difference target propagation (DTP), which trains network parameters using target-based local losses and employs a Hebbian learning rule, thus overcoming the biologically implausible symmetric weight problem in backpropagation. The second is simply layer-wise learning, where each layer is directly connected to a layer computing the loss error. The layers are either updated sequentially in a greedy fashion (GLL) or in random order (RLL), and each training stage involves a single hidden layer network. The one step backpropagation needed for each such network can either be altered with fixed random feedback weights as proposed in Lillicrap et al. (2016), or using updated random feedback as in Amit (2019). Both methods represent alternatives to the symmetric weight issue of backpropagation. By training convolutional neural networks (CNNs) with SSL and DTP, GLL or RLL, we find that our proposed framework achieves comparable performance to its implausible counterparts in both linear evaluation and transfer learning tasks.
Evolutionary Optimisation of Real-Time Systems and Networks
May 20, 2019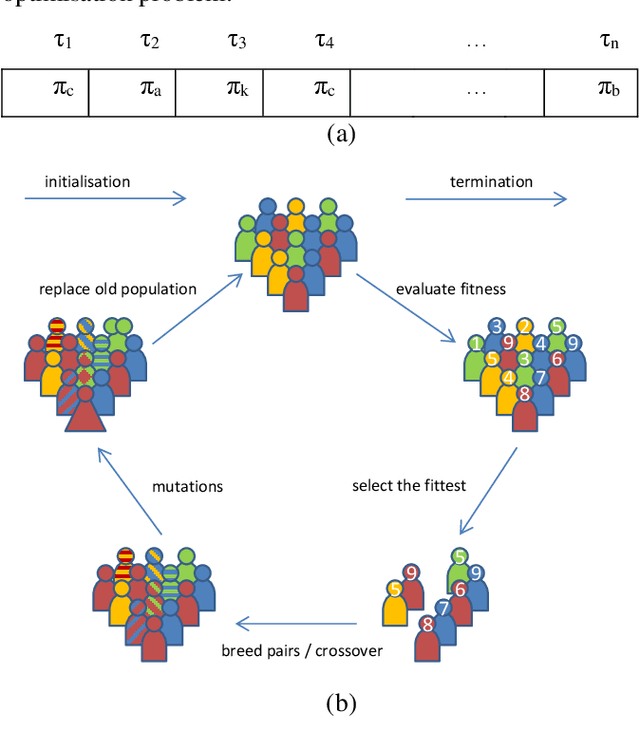
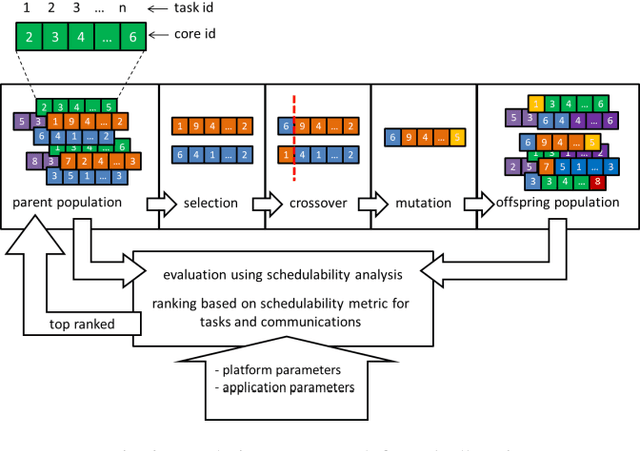
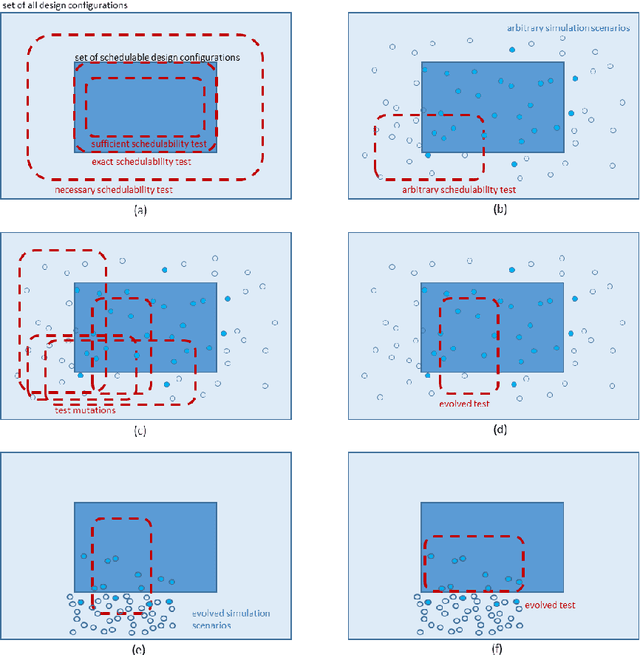
The design space of networked embedded systems is very large, posing challenges to the optimisation of such platforms when it comes to support applications with real-time guarantees. Recent research has shown that a number of inter-related optimisation problems have a critical influence over the schedulability of a system, i.e. whether all its application components can execute and communicate by their respective deadlines. Examples of such optimization problems include task allocation and scheduling, communication routing and arbitration, memory allocation, and voltage and frequency scaling. In this paper, we advocate the use of evolutionary approaches to address such optimization problems, aiming to evolve individuals of increased fitness over multiple generations of potential solutions. We refer to plentiful evidence that existing real-time schedulability tests can be used effectively to guide evolutionary optimisation, either by themselves or in combination with other metrics such as energy dissipation or hardware overheads. We then push that concept one step further and consider the possibility of using evolutionary techniques to evolve the schedulability tests themselves, aiming to support the verification and optimisation of systems which are too complex for state-of-the-art (manual) derivation of schedulability tests.
YOLACT: Real-time Instance Segmentation
Apr 04, 2019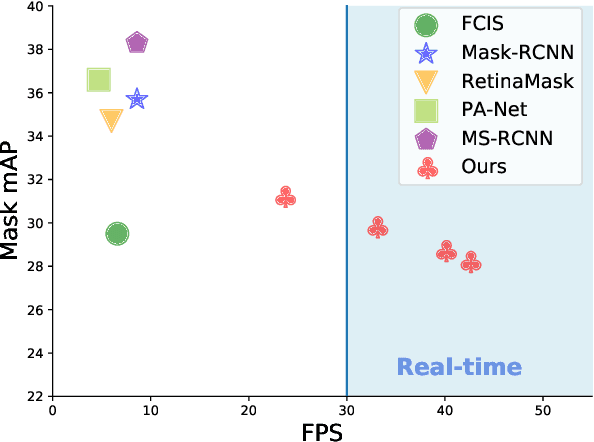
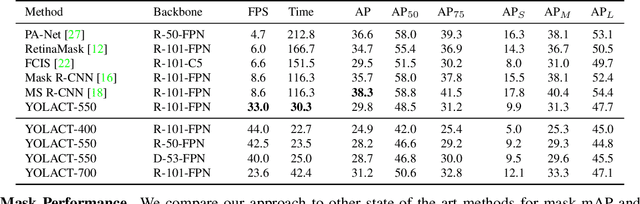
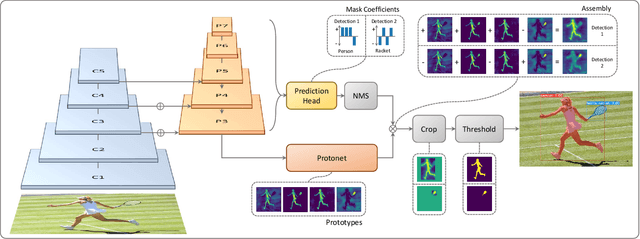

We present a simple, fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. Moreover, we obtain this result after training on only one GPU. We accomplish this by breaking instance segmentation into two parallel subtasks: (1) generating a set of prototype masks and (2) predicting per-instance mask coefficients. Then we produce instance masks by linearly combining the prototypes with the mask coefficients. We find that because this process doesn't depend on repooling, this approach produces very high-quality masks and exhibits temporal stability for free. Furthermore, we analyze the emergent behavior of our prototypes and show they learn to localize instances on their own in a translation variant manner, despite being fully-convolutional. Finally, we also propose Fast NMS, a drop-in 12 ms faster replacement for standard NMS that only has a marginal performance penalty.
Bayesian logistic regression for online recalibration and revision of risk prediction models with performance guarantees
Oct 13, 2021

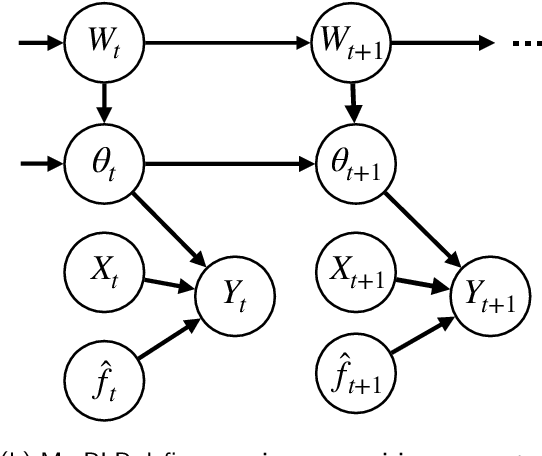
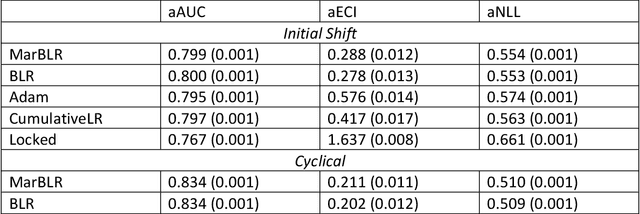
After deploying a clinical prediction model, subsequently collected data can be used to fine-tune its predictions and adapt to temporal shifts. Because model updating carries risks of over-updating/fitting, we study online methods with performance guarantees. We introduce two procedures for continual recalibration or revision of an underlying prediction model: Bayesian logistic regression (BLR) and a Markov variant that explicitly models distribution shifts (MarBLR). We perform empirical evaluation via simulations and a real-world study predicting COPD risk. We derive "Type I and II" regret bounds, which guarantee the procedures are non-inferior to a static model and competitive with an oracle logistic reviser in terms of the average loss. Both procedures consistently outperformed the static model and other online logistic revision methods. In simulations, the average estimated calibration index (aECI) of the original model was 0.828 (95%CI 0.818-0.938). Online recalibration using BLR and MarBLR improved the aECI, attaining 0.265 (95%CI 0.230-0.300) and 0.241 (95%CI 0.216-0.266), respectively. When performing more extensive logistic model revisions, BLR and MarBLR increased the average AUC (aAUC) from 0.767 (95%CI 0.765-0.769) to 0.800 (95%CI 0.798-0.802) and 0.799 (95%CI 0.797-0.801), respectively, in stationary settings and protected against substantial model decay. In the COPD study, BLR and MarBLR dynamically combined the original model with a continually-refitted gradient boosted tree to achieve aAUCs of 0.924 (95%CI 0.913-0.935) and 0.925 (95%CI 0.914-0.935), compared to the static model's aAUC of 0.904 (95%CI 0.892-0.916). Despite its simplicity, BLR is highly competitive with MarBLR. MarBLR outperforms BLR when its prior better reflects the data. BLR and MarBLR can improve the transportability of clinical prediction models and maintain their performance over time.
Interpretable Time Series Classification using All-Subsequence Learning and Symbolic Representations in Time and Frequency Domains
Aug 12, 2018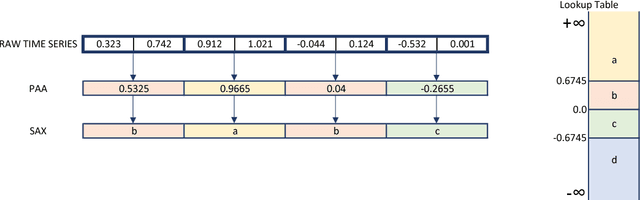


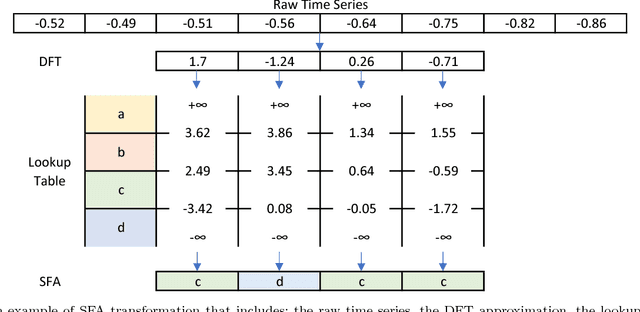
The time series classification literature has expanded rapidly over the last decade, with many new classification approaches published each year. The research focus has mostly been on improving the accuracy and efficiency of classifiers, while their interpretability has been somewhat neglected. Classifier interpretability has become a critical constraint for many application domains and the introduction of the 'right to explanation' GDPR EU legislation in May 2018 is likely to further emphasize the importance of explainable learning algorithms. In this work we analyse the state-of-the-art for time series classification, and propose new algorithms that aim to maintain the classifier accuracy and efficiency, but keep interpretability as a key design constraint. We present new time series classification algorithms that advance the state-of-the-art by implementing the following three key ideas: (1) Multiple resolutions of symbolic approximations: we combine symbolic representations obtained using different parameters; (2) Multiple domain representations: we combine symbolic approximations in time (e.g., SAX) and frequency (e.g., SFA) domains; (3) Efficient navigation of a huge symbolic-words space: we adapt a symbolic sequence classifier named SEQL, to make it work with multiple domain representations (e.g., SAX-SEQL, SFA-SEQL), and use its greedy feature selection strategy to effectively filter the best features for each representation. We show that a multi-resolution multi-domain linear classifier, SAX-SFA-SEQL, achieves a similar accuracy to the state-of-the-art COTE ensemble, and to a recent deep learning method (FCN), but uses a fraction of the time required by either COTE or FCN. We discuss the accuracy, efficiency and interpretability of our proposed algorithms. To further analyse the interpretability aspect of our classifiers, we present a case study on an ecology benchmark.
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021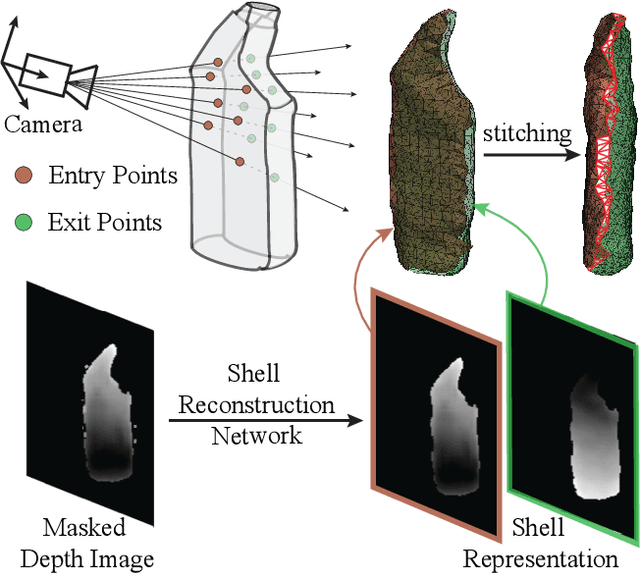
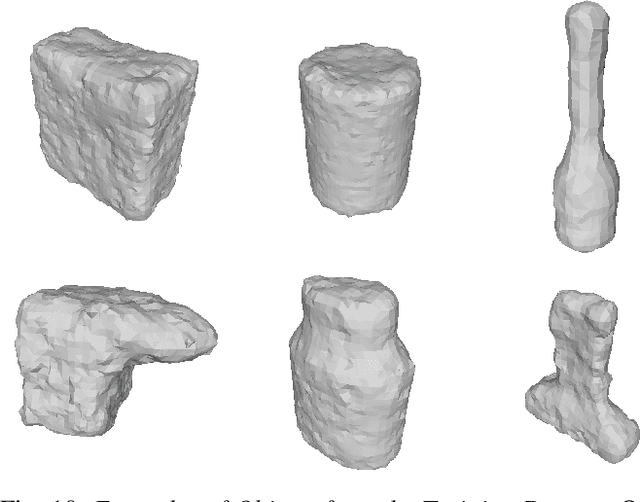

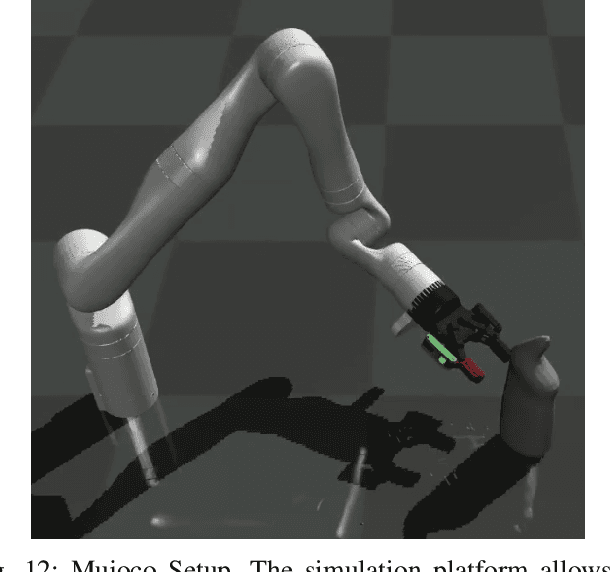
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.