 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An SMT Based Compositional Model to Solve a Conflict-Free Electric Vehicle Routing Problem
Jun 10, 2021
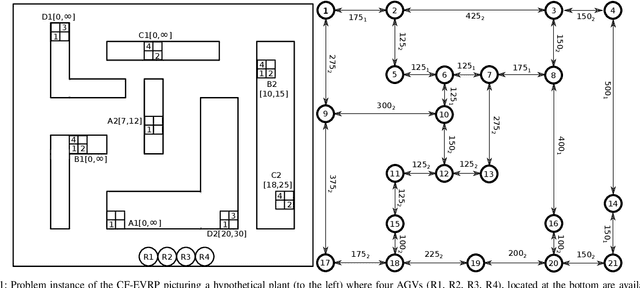
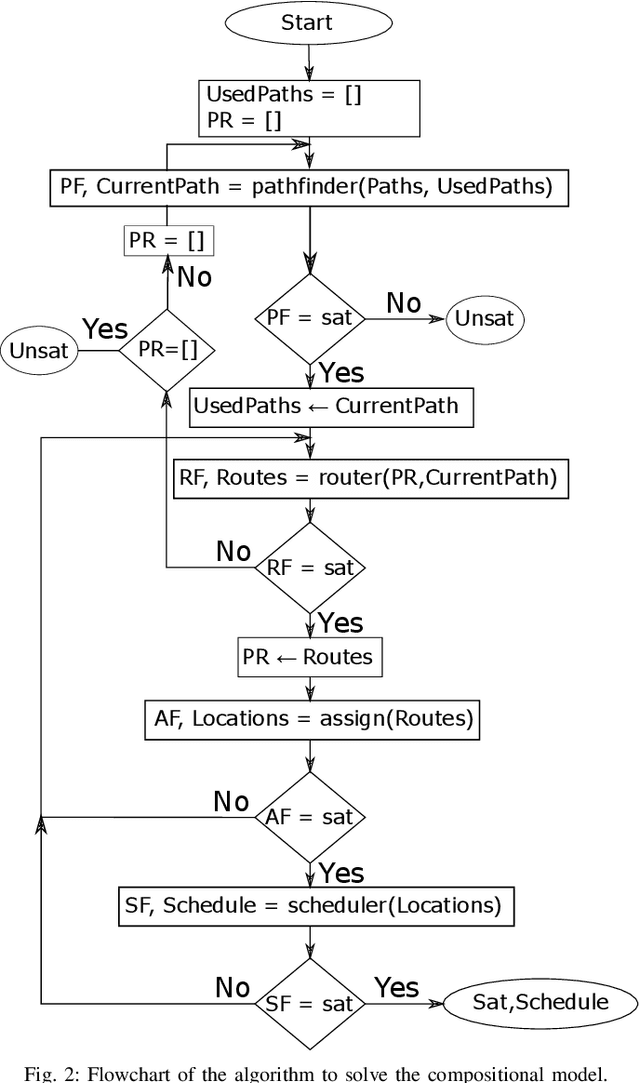
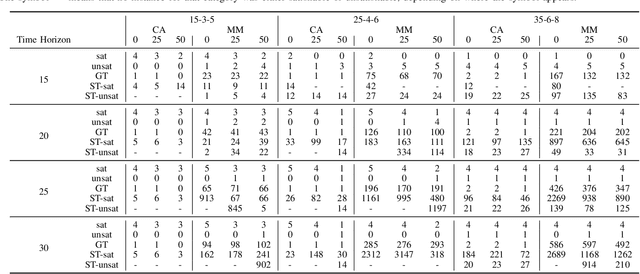
The Vehicle Routing Problem (VRP) is the combinatorial optimization problem of designing routes for vehicles to visit customers in such a fashion that a cost function, typically the number of vehicles, or the total travelled distance is minimized. The problem finds applications in industrial scenarios, for example where Automated Guided Vehicles run through the plant to deliver components from the warehouse. This specific problem, henceforth called the Electric Conflict-Free Vehicle Routing Problem (CF-EVRP), involves constraints such as limited operating range of the vehicles, time windows on the delivery to the customers, and limited capacity on the number of vehicles the road segments can accommodate at the same time. Such a complex system results in a large model that cannot easily be solved to optimality in reasonable time. We therefore developed a compositional model that breaks down the problem into smaller and simpler sub-problems and provides sub-optimal, feasible solutions to the original problem. The algorithm exploits the strengths of SMT solvers, which proved in our previous work to be an efficient approach to deal with scheduling problems. Compared to a monolithic model for the CF-EVRP, written in the SMT standard language and solved using a state-of-the-art SMT solver the compositional model was found to be significantly faster.
Sparse multi-reference alignment: sample complexity and computational hardness
Sep 23, 2021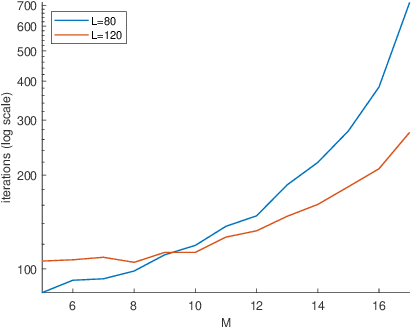
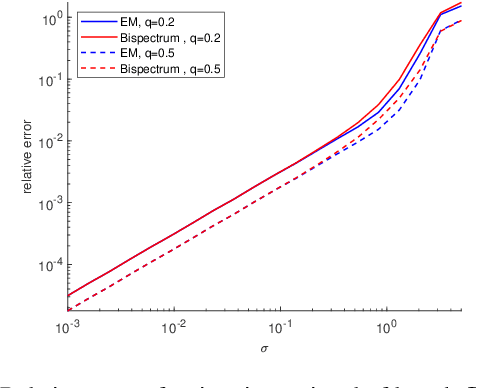
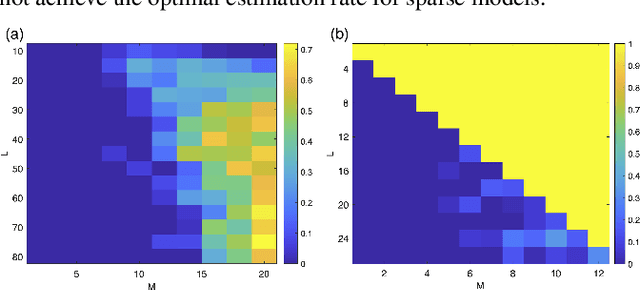
Motivated by the problem of determining the atomic structure of macromolecules using single-particle cryo-electron microscopy (cryo-EM), we study the sample and computational complexities of the sparse multi-reference alignment (MRA) model: the problem of estimating a sparse signal from its noisy, circularly shifted copies. Based on its tight connection to the crystallographic phase retrieval problem, we establish that if the number of observations is proportional to the square of the variance of the noise, then the sparse MRA problem is statistically feasible for sufficiently sparse signals. To investigate its computational hardness, we consider three types of computational frameworks: projection-based algorithms, bispectrum inversion, and convex relaxations. We show that a state-of-the-art projection-based algorithm achieves the optimal estimation rate, but its computational complexity is exponential in the sparsity level. The bispectrum framework provides a statistical-computational trade-off: it requires more observations (so its estimation rate is suboptimal), but its computational load is provably polynomial in the signal's length. The convex relaxation approach provides polynomial time algorithms (with a large exponent) that recover sufficiently sparse signals at the optimal estimation rate. We conclude the paper by discussing potential statistical and algorithmic implications for cryo-EM.
Deep Sequence Modeling: Development and Applications in Asset Pricing
Aug 20, 2021We predict asset returns and measure risk premia using a prominent technique from artificial intelligence -- deep sequence modeling. Because asset returns often exhibit sequential dependence that may not be effectively captured by conventional time series models, sequence modeling offers a promising path with its data-driven approach and superior performance. In this paper, we first overview the development of deep sequence models, introduce their applications in asset pricing, and discuss their advantages and limitations. We then perform a comparative analysis of these methods using data on U.S. equities. We demonstrate how sequence modeling benefits investors in general through incorporating complex historical path dependence, and that Long- and Short-term Memory (LSTM) based models tend to have the best out-of-sample performance.
Fast Strain Estimation and Frame Selection in Ultrasound Elastography using Machine Learning
Oct 16, 2021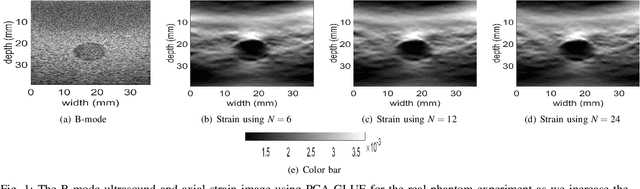
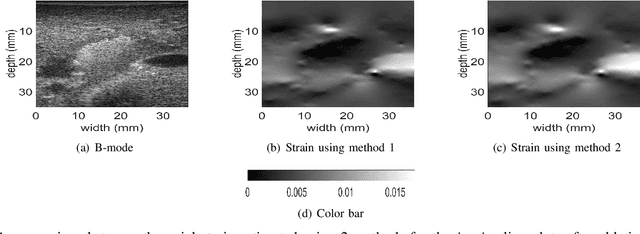
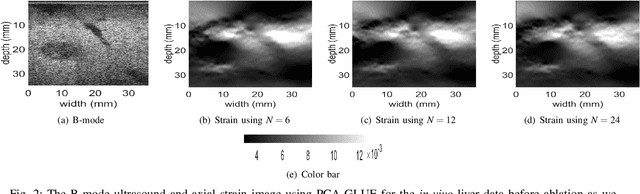
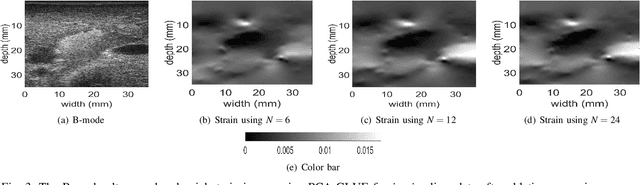
Ultrasound Elastography aims to determine the mechanical properties of the tissue by monitoring tissue deformation due to internal or external forces. Tissue deformations are estimated from ultrasound radio frequency (RF) signals and are often referred to as time delay estimation (TDE). Given two RF frames I1 and I2, we can compute a displacement image which shows the change in the position of each sample in I1 to a new position in I2. Two important challenges in TDE include high computational complexity and the difficulty in choosing suitable RF frames. Selecting suitable frames is of high importance because many pairs of RF frames either do not have acceptable deformation for extracting informative strain images or are decorrelated and deformation cannot be reliably estimated. Herein, we introduce a method that learns 12 displacement modes in quasi-static elastography by performing Principal Component Analysis (PCA) on displacement fields of a large training database. In the inference stage, we use dynamic programming (DP) to compute an initial displacement estimate of around 1% of the samples, and then decompose this sparse displacement into a linear combination of the 12 displacement modes. Our method assumes that the displacement of the whole image could also be described by this linear combination of principal components. We then use the GLobal Ultrasound Elastography (GLUE) method to fine-tune the result yielding the exact displacement image. Our method, which we call PCA-GLUE, is more than 10 times faster than DP in calculating the initial displacement map while giving the same result. Our second contribution in this paper is determining the suitability of the frame pair I1 and I2 for strain estimation, which we achieve by using the weight vector that we calculated for PCA-GLUE as an input to a multi-layer perceptron (MLP) classifier.
Reconstruction Algorithms for Low-Rank Tensors and Depth-3 Multilinear Circuits
May 04, 2021We give new and efficient black-box reconstruction algorithms for some classes of depth-$3$ arithmetic circuits. As a consequence, we obtain the first efficient algorithm for computing the tensor rank and for finding the optimal tensor decomposition as a sum of rank-one tensors when then input is a constant-rank tensor. More specifically, we provide efficient learning algorithms that run in randomized polynomial time over general fields and in deterministic polynomial time over the reals and the complex numbers for the following classes: (1) Set-multilinear depth-$3$ circuits of constant top fan-in $\Sigma\Pi\Sigma\{\sqcup_j X_j\}(k)$ circuits). As a consequence of our algorithm, we obtain the first polynomial time algorithm for tensor rank computation and optimal tensor decomposition of constant-rank tensors. This result holds for $d$ dimensional tensors for any $d$, but is interesting even for $d=3$. (2) Sums of powers of constantly many linear forms ($\Sigma\wedge\Sigma$ circuits). As a consequence we obtain the first polynomial-time algorithm for tensor rank computation and optimal tensor decomposition of constant-rank symmetric tensors. (3) Multilinear depth-3 circuits of constant top fan-in (multilinear $\Sigma\Pi\Sigma(k)$ circuits). Our algorithm works over all fields of characteristic 0 or large enough characteristic. Prior to our work the only efficient algorithms known were over polynomially-sized finite fields (see. Karnin-Shpilka 09'). Prior to our work, the only polynomial-time or even subexponential-time algorithms known (deterministic or randomized) for subclasses of $\Sigma\Pi\Sigma(k)$ circuits that also work over large/infinite fields were for the setting when the top fan-in $k$ is at most $2$ (see Sinha 16' and Sinha 20').
Remaining useful life prediction with uncertainty quantification: development of a highly accurate model for rotating machinery
Sep 23, 2021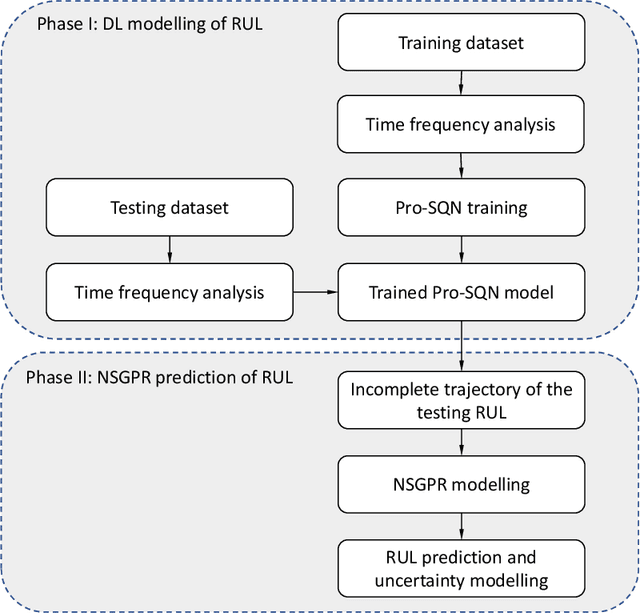

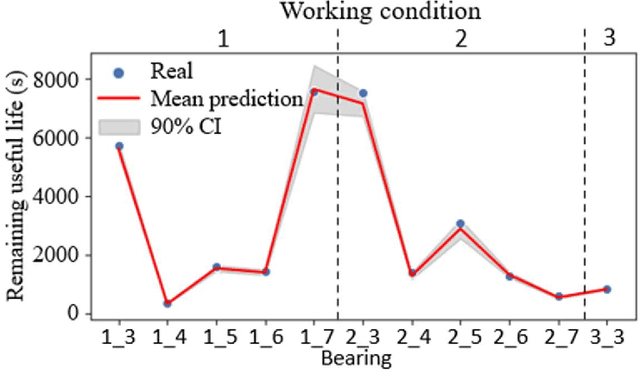
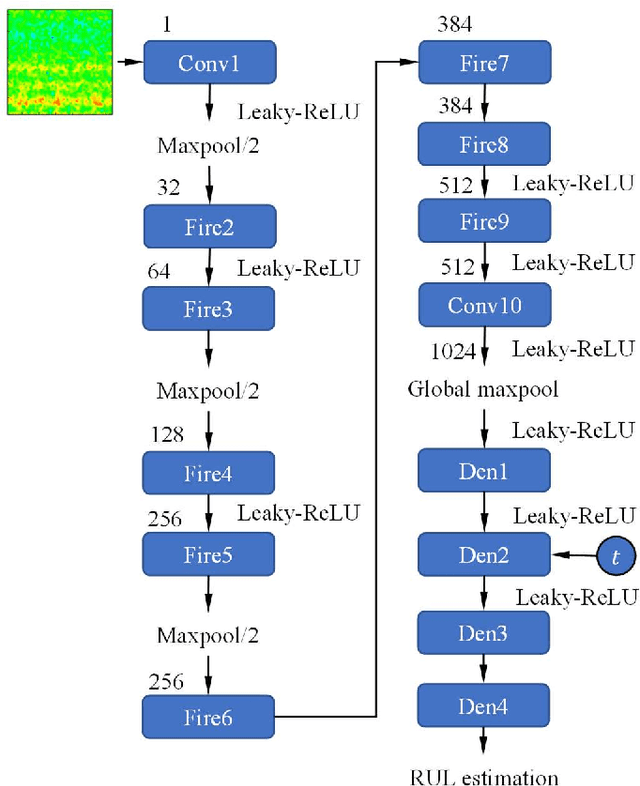
Rotating machinery is essential to modern life, from power generation to transportation and a host of other industrial applications. Since such equipment generally operates under challenging working conditions, which can lead to untimely failures, accurate remaining useful life (RUL) prediction is essential for maintenance planning and to prevent catastrophic failures. In this work, we address current challenges in data-driven RUL prediction for rotating machinery. The challenges revolve around the accuracy and uncertainty quantification of the prediction, and the non-stationarity of the system degradation and RUL estimation given sensor data. We devise a novel architecture and RUL prediction model with uncertainty quantification, termed VisPro, which integrates time-frequency analysis, deep learning image recognition, and nonstationary Gaussian process regression. We analyze and benchmark the results obtained with our model against those of other advanced data-driven RUL prediction models for rotating machinery using the PHM12 bearing vibration dataset. The computational experiments show that (1) the VisPro predictions are highly accurate and provide significant improvements over existing prediction models (three times more accurate than the second-best model), and (2) the RUL uncertainty bounds are valid and informative. We identify and discuss the architectural and modeling choices made that explain this excellent predictive performance of VisPro.
Arbitrage-Free Implied Volatility Surface Generation with Variational Autoencoders
Aug 10, 2021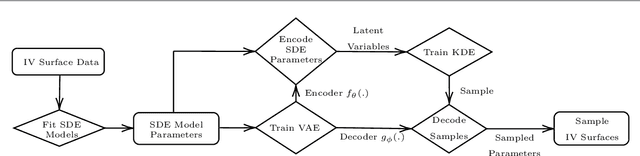

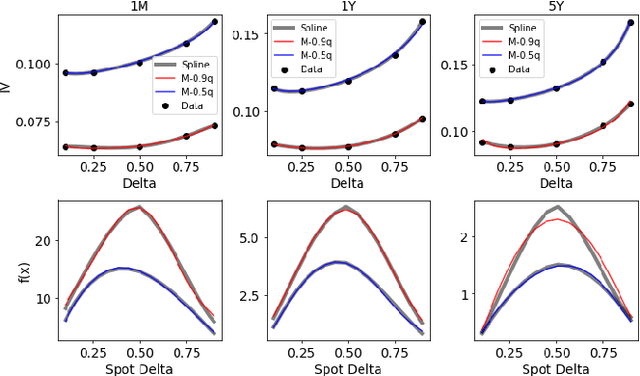

We propose a hybrid method for generating arbitrage-free implied volatility (IV) surfaces consistent with historical data by combining model-free Variational Autoencoders (VAEs) with continuous time stochastic differential equation (SDE) driven models. We focus on two classes of SDE models: regime switching models and L\'evy additive processes. By projecting historical surfaces onto the space of SDE model parameters, we obtain a distribution on the parameter subspace faithful to the data on which we then train a VAE. Arbitrage-free IV surfaces are then generated by sampling from the posterior distribution on the latent space, decoding to obtain SDE model parameters, and finally mapping those parameters to IV surfaces.
An $O(s^r)$-Resolution ODE Framework for Discrete-Time Optimization Algorithms and Applications to Convex-Concave Saddle-Point Problems
Jan 23, 2020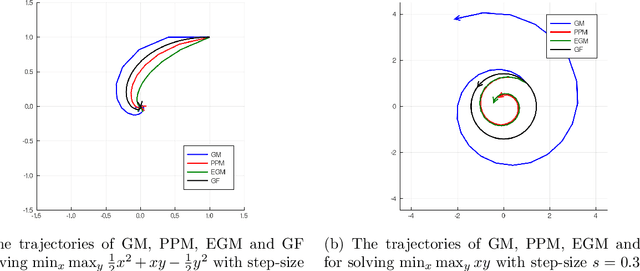
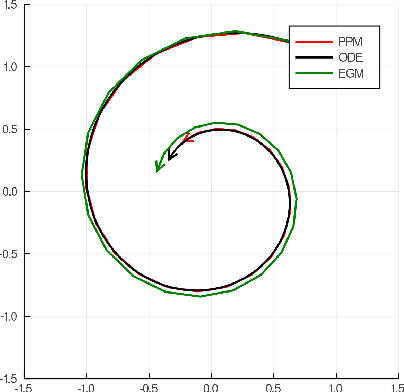
There has been a long history of using Ordinary Differential Equations (ODEs) to understand the dynamic of discrete-time optimization algorithms. However, one major difficulty of applying this approach is that there can be multiple ODEs that correspond to the same discrete-time algorithm, depending on how to take the continuous limit, which makes it unclear how to obtain the suitable ODE from a discrete-time optimization algorithm. Inspired by the recent paper \cite{shi2018understanding}, we propose the $r$-th degree ODE expansion of a discrete-time optimization algorithm, which provides a principal approach to construct the unique $O(s^r)$-resolution ODE systems for a given discrete-time algorithm, where $s$ is the step-size of the algorithm. We utilize this machinery to study three classic algorithms -- gradient method (GM), proximal point method (PPM) and extra-gradient method (EGM) -- for finding the solution to the unconstrained convex-concave saddle-point problem $\min_{x\in\RR^n} \max_{y\in \RR^m} L(x,y)$, which explains their puzzling convergent/divergent behaviors when $L(x,y)$ is a bilinear function. Moreover, their $O(s)$-resolution ODEs inspire us to define the $O(s)$-linear-convergence condition on $L(x,y)$, under which PPM and EGM exhabit linear convergence. This condition not only unifies the known linear convergence rate of PPM and EGM, but also showcases that these two algorithms exhibit linear convergence in broader contexts.
dFDA-VeD: A Dynamic Future Demand Aware Vehicle Dispatching System
Jun 10, 2021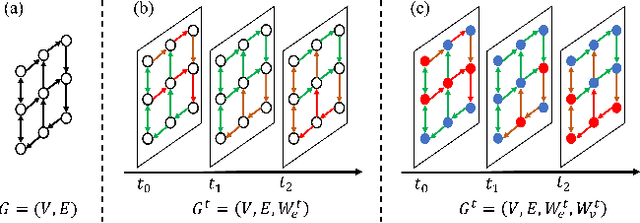
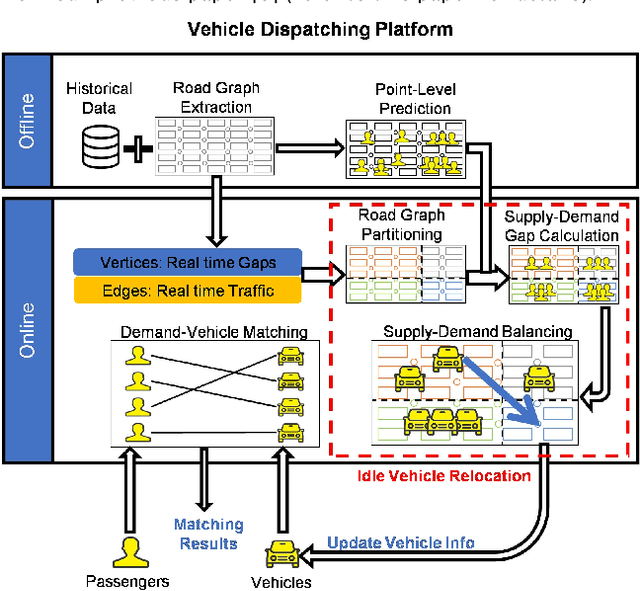

With the rising demand of smart mobility, ride-hailing service is getting popular in the urban regions. These services maintain a system for serving the incoming trip requests by dispatching available vehicles to the pickup points. As the process should be socially and economically profitable, the task of vehicle dispatching is highly challenging, specially due to the time-varying travel demands and traffic conditions. Due to the uneven distribution of travel demands, many idle vehicles could be generated during the operation in different subareas. Most of the existing works on vehicle dispatching system, designed static relocation centers to relocate idle vehicles. However, as traffic conditions and demand distribution dynamically change over time, the static solution can not fit the evolving situations. In this paper, we propose a dynamic future demand aware vehicle dispatching system. It can dynamically search the relocation centers considering both travel demand and traffic conditions. We evaluate the system on real-world dataset, and compare with the existing state-of-the-art methods in our experiments in terms of several standard evaluation metrics and operation time. Through our experiments, we demonstrate that the proposed system significantly improves the serving ratio and with a very small increase in operation cost.
Learning Dynamics from Noisy Measurements using Deep Learning with a Runge-Kutta Constraint
Sep 23, 2021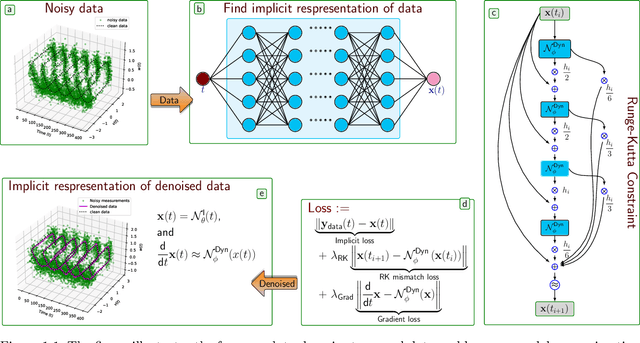
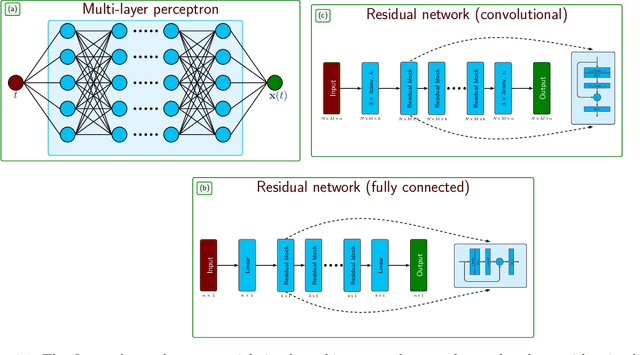
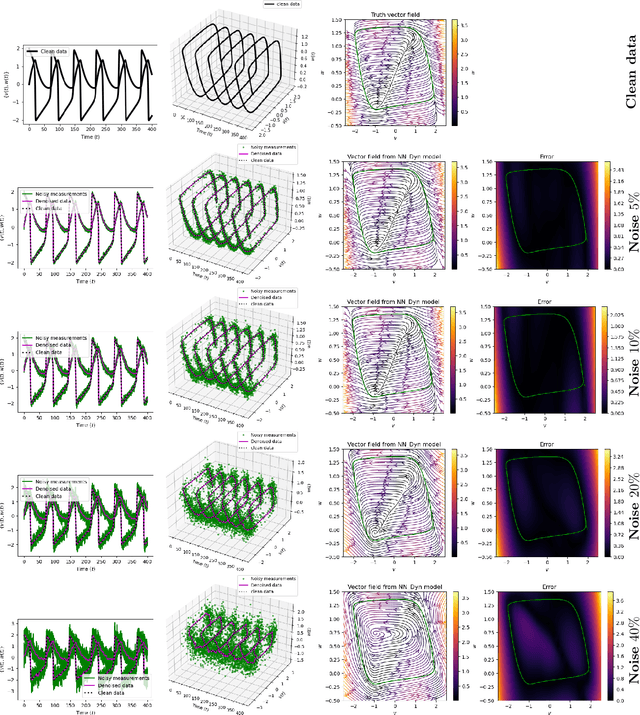
Measurement noise is an integral part while collecting data of a physical process. Thus, noise removal is a necessary step to draw conclusions from these data, and it often becomes quite essential to construct dynamical models using these data. We discuss a methodology to learn differential equation(s) using noisy and sparsely sampled measurements. In our methodology, the main innovation can be seen in of integration of deep neural networks with a classical numerical integration method. Precisely, we aim at learning a neural network that implicitly represents the data and an additional neural network that models the vector fields of the dependent variables. We combine these two networks by enforcing the constraint that the data at the next time-steps can be given by following a numerical integration scheme such as the fourth-order Runge-Kutta scheme. The proposed framework to learn a model predicting the vector field is highly effective under noisy measurements. The approach can handle scenarios where dependent variables are not available at the same temporal grid. We demonstrate the effectiveness of the proposed method to learning models using data obtained from various differential equations. The proposed approach provides a promising methodology to learn dynamic models, where the first-principle understanding remains opaque.