 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient and Generic Interactive Segmentation Framework to Correct Mispredictions during Clinical Evaluation of Medical Images
Aug 06, 2021

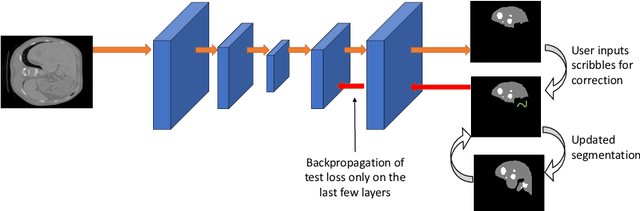
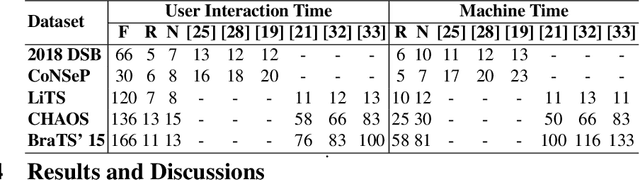

Semantic segmentation of medical images is an essential first step in computer-aided diagnosis systems for many applications. However, given many disparate imaging modalities and inherent variations in the patient data, it is difficult to consistently achieve high accuracy using modern deep neural networks (DNNs). This has led researchers to propose interactive image segmentation techniques where a medical expert can interactively correct the output of a DNN to the desired accuracy. However, these techniques often need separate training data with the associated human interactions, and do not generalize to various diseases, and types of medical images. In this paper, we suggest a novel conditional inference technique for DNNs which takes the intervention by a medical expert as test time constraints and performs inference conditioned upon these constraints. Our technique is generic can be used for medical images from any modality. Unlike other methods, our approach can correct multiple structures simultaneously and add structures missed at initial segmentation. We report an improvement of 13.3, 12.5, 17.8, 10.2, and 12.4 times in user annotation time than full human annotation for the nucleus, multiple cells, liver and tumor, organ, and brain segmentation respectively. We report a time saving of 2.8, 3.0, 1.9, 4.4, and 8.6 fold compared to other interactive segmentation techniques. Our method can be useful to clinicians for diagnosis and post-surgical follow-up with minimal intervention from the medical expert. The source-code and the detailed results are available here [1].
Acceleration Method for Learning Fine-Layered Optical Neural Networks
Sep 01, 2021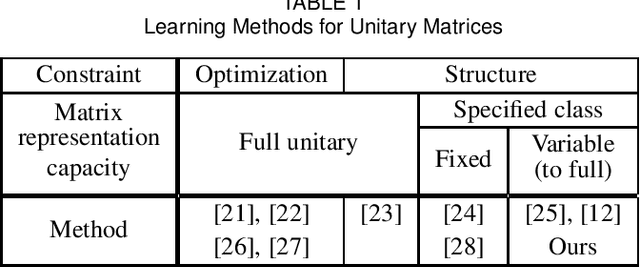
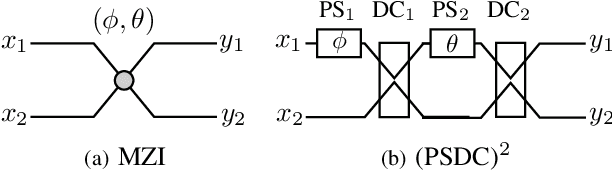
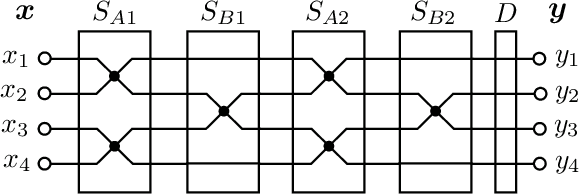
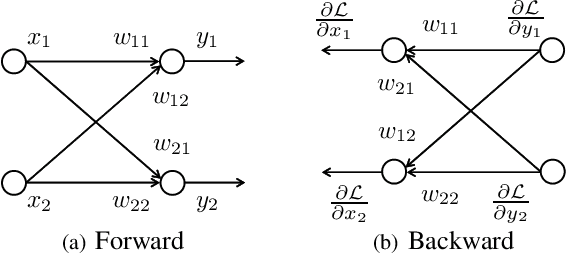
An optical neural network (ONN) is a promising system due to its high-speed and low-power operation. Its linear unit performs a multiplication of an input vector and a weight matrix in optical analog circuits. Among them, a circuit with a multiple-layered structure of programmable Mach-Zehnder interferometers (MZIs) can realize a specific class of unitary matrices with a limited number of MZIs as its weight matrix. The circuit is effective for balancing the number of programmable MZIs and ONN performance. However, it takes a lot of time to learn MZI parameters of the circuit with a conventional automatic differentiation (AD), which machine learning platforms are equipped with. To solve the time-consuming problem, we propose an acceleration method for learning MZI parameters. We create customized complex-valued derivatives for an MZI, exploiting Wirtinger derivatives and a chain rule. They are incorporated into our newly developed function module implemented in C++ to collectively calculate their values in a multi-layered structure. Our method is simple, fast, and versatile as well as compatible with the conventional AD. We demonstrate that our method works 20 times faster than the conventional AD when a pixel-by-pixel MNIST task is performed in a complex-valued recurrent neural network with an MZI-based hidden unit.
Frame-level multi-channel speaker verification with large-scale ad-hoc microphone arrays
Oct 15, 2021Ad-hoc microphone arrays has recieved attention, in which the number and arrangement of microphones are unknown. Traditional multi-channel processing methods can not be directly used in ad-hoc. Recently, to solve this problem, an utterance-level ASV with ad-hoc microphone arrays has been proposed, which first extracts utterance-level speaker embeddings from each channel of an ad-hoc microphone array, and then fuses the embeddings for the final verification. However, this method cannot make full use of the cross-channel information. In this paper, we present a novel multi-channel ASV model at the frame-level. Specifically, we add spatio-temporal processing blocks (STB) before the pooling layer, which models the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from STB are sent to the pooling layer to obtain an utterance-level speaker representation. Experimental results demonstrate the effectiveness of the proposed method.
Learning discriminative and robust time-frequency representations for environmental sound classification
Jan 11, 2020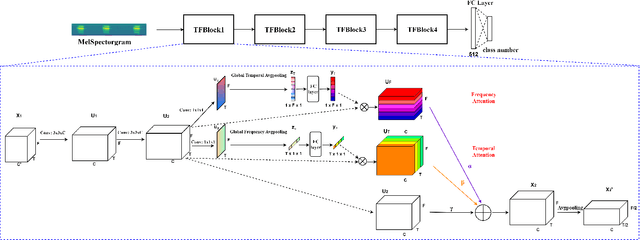
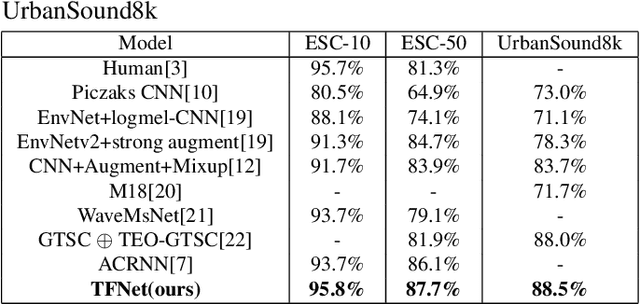
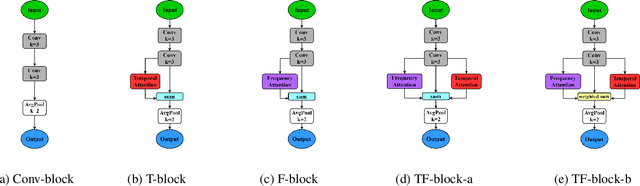
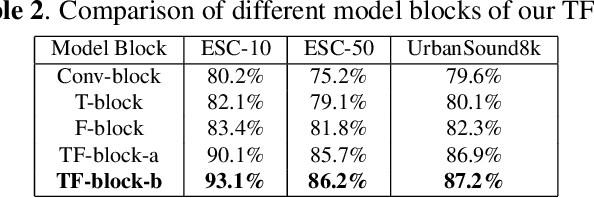
Convolutional neural networks (CNN) are one of the best-performing neural network architectures for environmental sound classification (ESC). Recently, attention mechanisms have been used in CNN to capture the useful information from the audio signal for sound classification, especially for weakly labelled data where the timing information about the acoustic events is not available in the training data, apart from the availability of sound class labels. In these methods, however, the inherent time-frequency characteristics and variations are not explicitly exploited when obtaining the deep features. In this paper, we propose a new method, called time-frequency enhancement block (TFBlock), which temporal attention and frequency attention are employed to enhance the features from relevant frames and frequency bands. Compared with other attention mechanisms, in our method, parallel branches are constructed which allow the temporal and frequency features to be attended respectively in order to mitigate interference from the sections where no sound events happened in the acoustic environments. The experiments on three benchmark ESC datasets show that our method improves the classification performance and also exhibits robustness to noise.
Heritability in Morphological Robot Evolution
Oct 21, 2021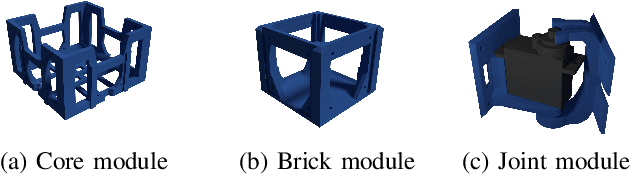
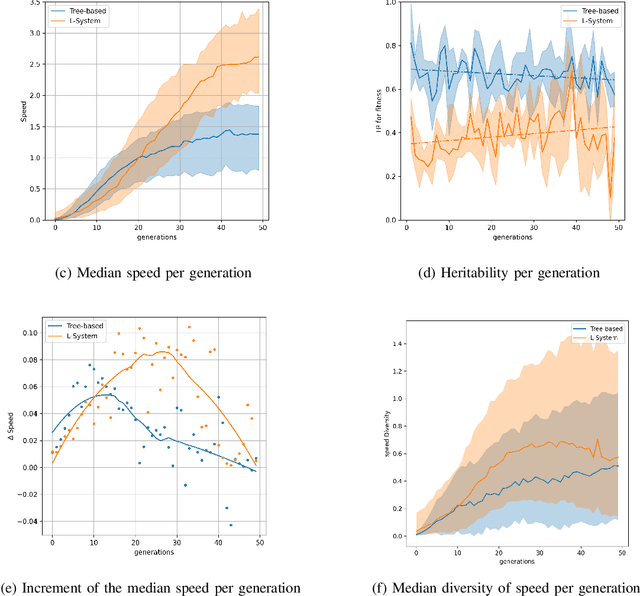
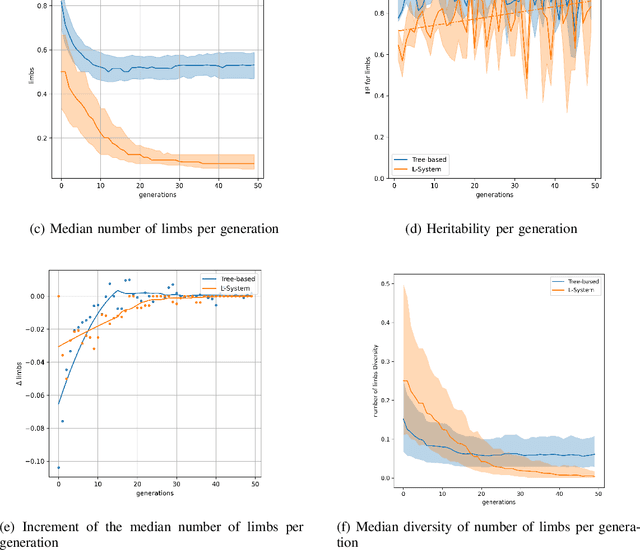
In the field of evolutionary robotics, choosing the correct encoding is very complicated, especially when robots evolve both behaviours and morphologies at the same time. With the objective of improving our understanding of the mapping process from encodings to functional robots, we introduce the biological notion of heritability, which captures the amount of phenotypic variation caused by genotypic variation. In our analysis we measure the heritability on the first generation of robots evolved from two different encodings, a direct encoding and an indirect encoding. In addition we investigate the interplay between heritability and phenotypic diversity through the course of an entire evolutionary process. In particular, we investigate how direct and indirect genotypes can exhibit preferences for exploration or exploitation throughout the course of evolution. We observe how an exploration or exploitation tradeoff can be more easily understood by examining patterns in heritability and phenotypic diversity. In conclusion, we show how heritability can be a useful tool to better understand the relationship between genotypes and phenotypes, especially helpful when designing more complicated systems where complex individuals and environments can adapt and influence each other.
TasNet: time-domain audio separation network for real-time, single-channel speech separation
Apr 18, 2018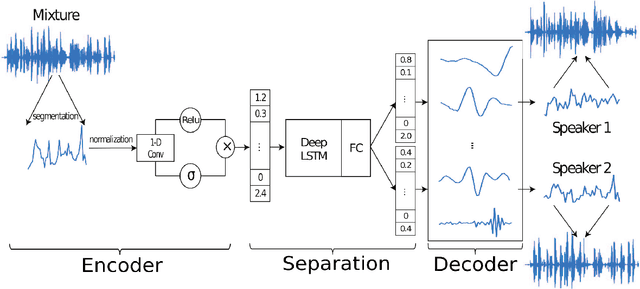
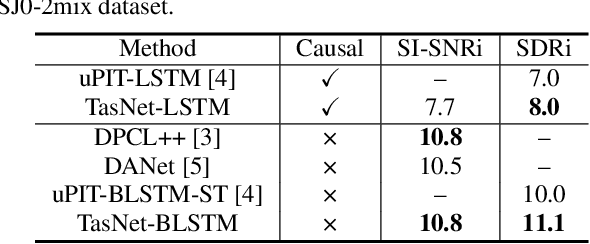
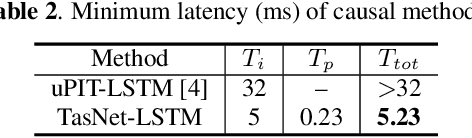
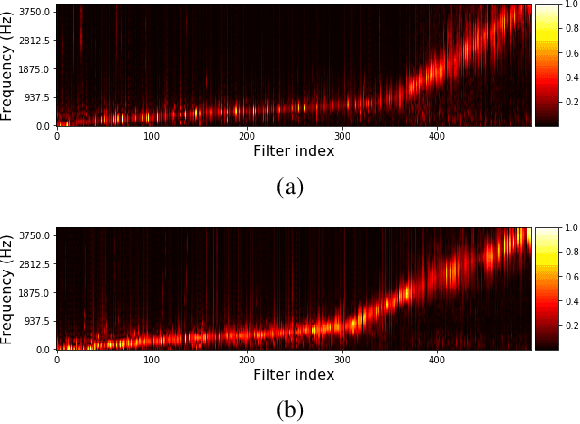
Robust speech processing in multi-talker environments requires effective speech separation. Recent deep learning systems have made significant progress toward solving this problem, yet it remains challenging particularly in real-time, short latency applications. Most methods attempt to construct a mask for each source in time-frequency representation of the mixture signal which is not necessarily an optimal representation for speech separation. In addition, time-frequency decomposition results in inherent problems such as phase/magnitude decoupling and long time window which is required to achieve sufficient frequency resolution. We propose Time-domain Audio Separation Network (TasNet) to overcome these limitations. We directly model the signal in the time-domain using an encoder-decoder framework and perform the source separation on nonnegative encoder outputs. This method removes the frequency decomposition step and reduces the separation problem to estimation of source masks on encoder outputs which is then synthesized by the decoder. Our system outperforms the current state-of-the-art causal and noncausal speech separation algorithms, reduces the computational cost of speech separation, and significantly reduces the minimum required latency of the output. This makes TasNet suitable for applications where low-power, real-time implementation is desirable such as in hearable and telecommunication devices.
Resilience from Diversity: Population-based approach to harden models against adversarial attacks
Nov 19, 2021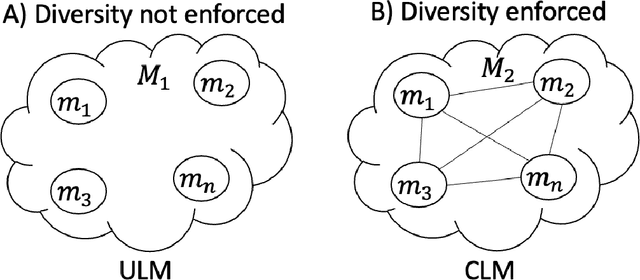

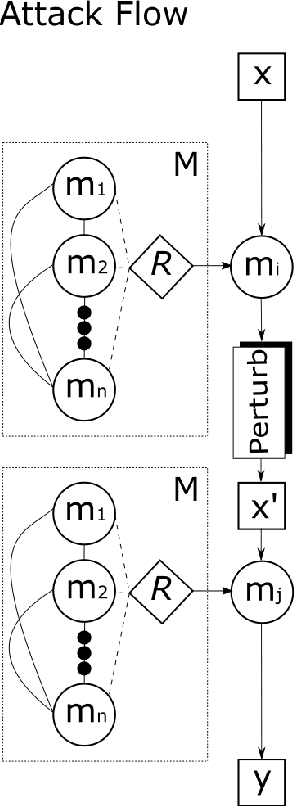
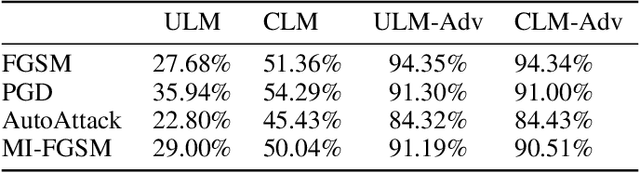
Traditional deep learning models exhibit intriguing vulnerabilities that allow an attacker to force them to fail at their task. Notorious attacks such as the Fast Gradient Sign Method (FGSM) and the more powerful Projected Gradient Descent (PGD) generate adversarial examples by adding a magnitude of perturbation $\epsilon$ to the input's computed gradient, resulting in a deterioration of the effectiveness of the model's classification. This work introduces a model that is resilient to adversarial attacks. Our model leverages a well established principle from biological sciences: population diversity produces resilience against environmental changes. More precisely, our model consists of a population of $n$ diverse submodels, each one of them trained to individually obtain a high accuracy for the task at hand, while forced to maintain meaningful differences in their weight tensors. Each time our model receives a classification query, it selects a submodel from its population at random to answer the query. To introduce and maintain diversity in population of submodels, we introduce the concept of counter linking weights. A Counter-Linked Model (CLM) consists of submodels of the same architecture where a periodic random similarity examination is conducted during the simultaneous training to guarantee diversity while maintaining accuracy. In our testing, CLM robustness got enhanced by around 20% when tested on the MNIST dataset and at least 15% when tested on the CIFAR-10 dataset. When implemented with adversarially trained submodels, this methodology achieves state-of-the-art robustness. On the MNIST dataset with $\epsilon=0.3$, it achieved 94.34% against FGSM and 91% against PGD. On the CIFAR-10 dataset with $\epsilon=8/255$, it achieved 62.97% against FGSM and 59.16% against PGD.
Qu-ANTI-zation: Exploiting Quantization Artifacts for Achieving Adversarial Outcomes
Nov 11, 2021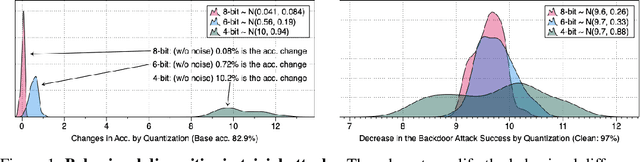
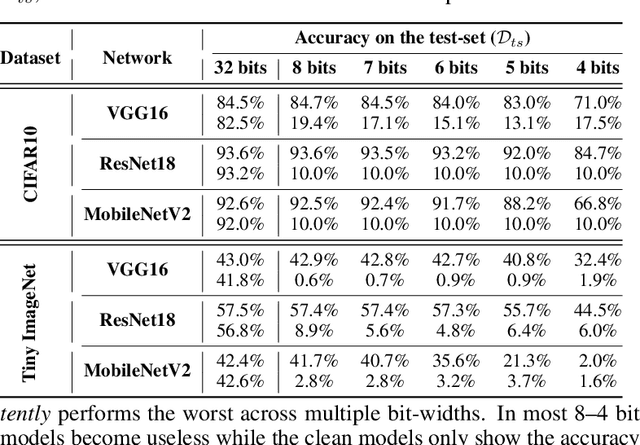
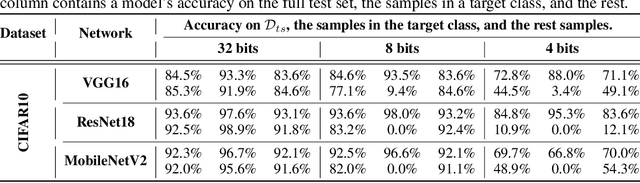
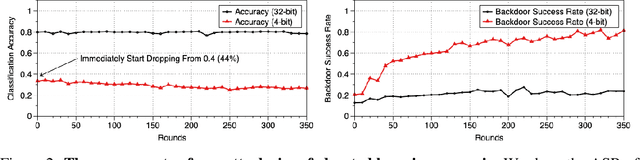
Quantization is a popular technique that $transforms$ the parameter representation of a neural network from floating-point numbers into lower-precision ones ($e.g.$, 8-bit integers). It reduces the memory footprint and the computational cost at inference, facilitating the deployment of resource-hungry models. However, the parameter perturbations caused by this transformation result in $behavioral$ $disparities$ between the model before and after quantization. For example, a quantized model can misclassify some test-time samples that are otherwise classified correctly. It is not known whether such differences lead to a new security vulnerability. We hypothesize that an adversary may control this disparity to introduce specific behaviors that activate upon quantization. To study this hypothesis, we weaponize quantization-aware training and propose a new training framework to implement adversarial quantization outcomes. Following this framework, we present three attacks we carry out with quantization: (i) an indiscriminate attack for significant accuracy loss; (ii) a targeted attack against specific samples; and (iii) a backdoor attack for controlling the model with an input trigger. We further show that a single compromised model defeats multiple quantization schemes, including robust quantization techniques. Moreover, in a federated learning scenario, we demonstrate that a set of malicious participants who conspire can inject our quantization-activated backdoor. Lastly, we discuss potential counter-measures and show that only re-training consistently removes the attack artifacts. Our code is available at https://github.com/Secure-AI-Systems-Group/Qu-ANTI-zation
As if by magic: self-supervised training of deep despeckling networks with MERLIN
Nov 15, 2021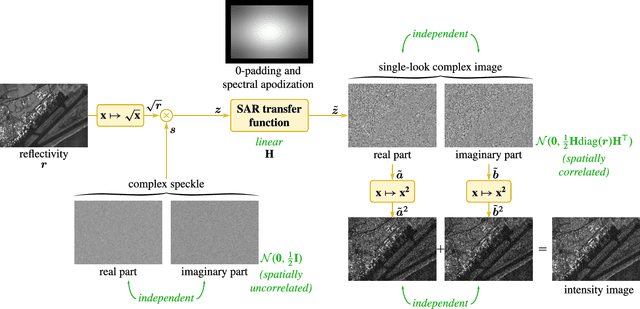
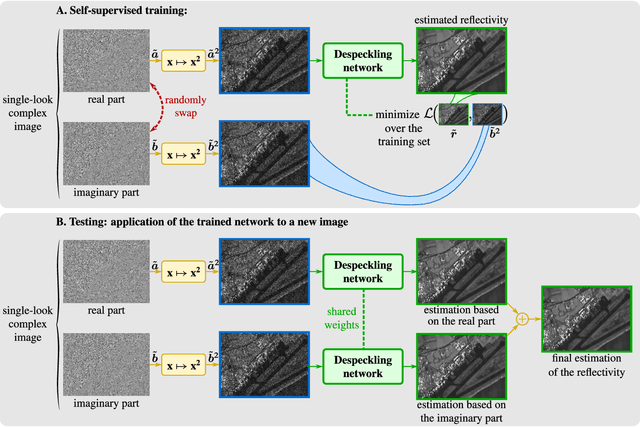


Speckle fluctuations seriously limit the interpretability of synthetic aperture radar (SAR) images. Speckle reduction has thus been the subject of numerous works spanning at least four decades. Techniques based on deep neural networks have recently achieved a new level of performance in terms of SAR image restoration quality. Beyond the design of suitable network architectures or the selection of adequate loss functions, the construction of training sets is of uttermost importance. So far, most approaches have considered a supervised training strategy: the networks are trained to produce outputs as close as possible to speckle-free reference images. Speckle-free images are generally not available, which requires resorting to natural or optical images or the selection of stable areas in long time series to circumvent the lack of ground truth. Self-supervision, on the other hand, avoids the use of speckle-free images. We introduce a self-supervised strategy based on the separation of the real and imaginary parts of single-look complex SAR images, called MERLIN (coMplex sElf-supeRvised despeckLINg), and show that it offers a straightforward way to train all kinds of deep despeckling networks. Networks trained with MERLIN take into account the spatial correlations due to the SAR transfer function specific to a given sensor and imaging mode. By requiring only a single image, and possibly exploiting large archives, MERLIN opens the door to hassle-free as well as large-scale training of despeckling networks. The code of the trained models is made freely available at https://gitlab.telecom-paris.fr/RING/MERLIN.
Logsig-RNN: a novel network for robust and efficient skeleton-based action recognition
Nov 01, 2021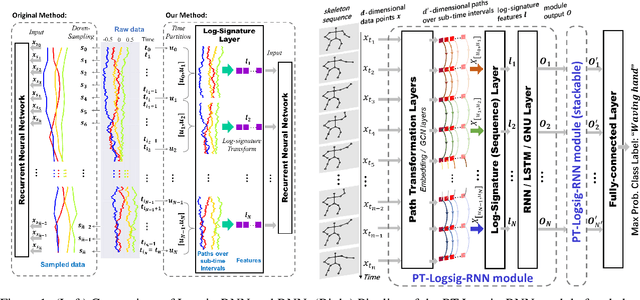
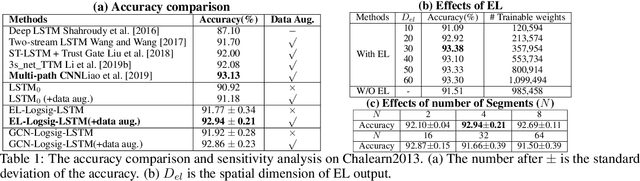


This paper contributes to the challenge of skeleton-based human action recognition in videos. The key step is to develop a generic network architecture to extract discriminative features for the spatio-temporal skeleton data. In this paper, we propose a novel module, namely Logsig-RNN, which is the combination of the log-signature layer and recurrent type neural networks (RNNs). The former one comes from the mathematically principled technology of signatures and log-signatures as representations for streamed data, which can manage high sample rate streams, non-uniform sampling and time series of variable length. It serves as an enhancement of the recurrent layer, which can be conveniently plugged into neural networks. Besides we propose two path transformation layers to significantly reduce path dimension while retaining the essential information fed into the Logsig-RNN module. Finally, numerical results demonstrate that replacing the RNN module by the Logsig-RNN module in SOTA networks consistently improves the performance on both Chalearn gesture data and NTU RGB+D 120 action data in terms of accuracy and robustness. In particular, we achieve the state-of-the-art accuracy on Chalearn2013 gesture data by combining simple path transformation layers with the Logsig-RNN. Codes are available at https://github.com/steveliao93/GCN_LogsigRNN.